基于遺傳算法的詞語語義相似度計(jì)算研究
2021-03-08 01:05:54楊泉
計(jì)算機(jī)技術(shù)與發(fā)展 2021年2期
關(guān)鍵詞:語義
楊 泉
(北京師范大學(xué),北京 100875)
0 引 言
語義相似度是對給定的語言對象間語義相似程度的衡量,通常用[0,1]之間的數(shù)值來表示。語義相似度計(jì)算就是計(jì)算語義相似度具體數(shù)值的過程。語義相似度計(jì)算對象的層級可分為詞、短語、句子、篇章,該文主要研究詞層級上兩個(gè)詞之間的語義相似度計(jì)算問題。
語義相似度計(jì)算目前在機(jī)器翻譯、人機(jī)問答、情感計(jì)算、信息提取等很多領(lǐng)域中都有著廣泛的應(yīng)用[1]。語義相似度計(jì)算方法主要分為兩類:一類是在大規(guī)模語料的基礎(chǔ)上直接統(tǒng)計(jì)和計(jì)算的方法;另一類是根據(jù)某種已有知識本體(ontology)或分類體系(taxonomy)來計(jì)算的方法[2-3]。基于語料庫的方法對語料的依賴性較大,需要在大規(guī)模精確標(biāo)注語料的基礎(chǔ)上進(jìn)行,但語料的規(guī)模、內(nèi)容、范圍以及標(biāo)注的標(biāo)準(zhǔn)和規(guī)范難以統(tǒng)一,而且可解釋性較差;而基于知識本體或分類體系的方法在這些方面就顯示出了其優(yōu)越性,越來越多的專家學(xué)者都進(jìn)行了有效的嘗試。
用于語義相似度計(jì)算的漢語知識本體目前主要有《知網(wǎng)》[4]和《同義詞詞林》[5]。前人研究中有很多利用《知網(wǎng)》的樹狀結(jié)構(gòu)或概念義原來進(jìn)行語義相似度計(jì)算,如文獻(xiàn)[6]介紹了一種基于《知網(wǎng)》樹狀結(jié)構(gòu)的語義相似度計(jì)算方法;文獻(xiàn)[7]在綜合考慮《知網(wǎng)》義原距離、義原深度、義原寬度、義原密度和義原重合度的基礎(chǔ)上,利用多特征結(jié)合的方法計(jì)算詞語相似度;文獻(xiàn)[8]基于對《知網(wǎng)》中詞語、義項(xiàng)和義原三個(gè)層次概念的研究,針對詞語相似度計(jì)算中結(jié)果合理性的問題,提出了一種結(jié)合信息論研究中熵的概念的新的詞語相似度計(jì)算方法。但是與《知網(wǎng)》相比較而言,《同義詞詞林》內(nèi)部結(jié)構(gòu)比較清楚,可以較為容易地轉(zhuǎn)化成樹形圖來計(jì)算詞語的深度和路徑,國內(nèi)也有很多研究人員利用《同義詞詞林》計(jì)算詞語之間的語義相似度,文獻(xiàn)[6,9]利用《詞林》的編碼及結(jié)構(gòu)特點(diǎn),結(jié)合詞語的相似性和相關(guān)性,計(jì)算語義相似度。文獻(xiàn)[10]提出了一種綜合《知網(wǎng)》與《同義詞詞林》的計(jì)算方法。《詞林》部分采用以詞語距離為主要因素、分支節(jié)點(diǎn)數(shù)和分支間隔數(shù)為微調(diào)節(jié)參數(shù)的方法計(jì)算語義相似度。文獻(xiàn)[11]根據(jù)《詞林》提出了一種基于路徑與深度的算法。該方法通過兩個(gè)詞語義項(xiàng)之間的最短路徑以及它們的最近公共父節(jié)點(diǎn)在層次樹中的深度計(jì)算出兩個(gè)詞語義項(xiàng)之間的相似度。在計(jì)算過程中為分類樹中不同層之間的邊賦予不同的權(quán)值,同時(shí)通過兩個(gè)義項(xiàng)在其最近公共父節(jié)點(diǎn)中的分支間距動(dòng)態(tài)調(diào)節(jié)詞語義項(xiàng)間的最短路徑。文獻(xiàn)[12]提出了一種基于路徑與《同義詞詞林》編碼相結(jié)合的語義相似度計(jì)算方法。該方法認(rèn)為《詞林》編碼體系是按從左到右依次遞增的關(guān)系排列分支,距離越近的概念分支間隔越小,編碼距離也越近,由此根據(jù)每個(gè)分類節(jié)點(diǎn)下面的分支節(jié)點(diǎn)順序及編碼規(guī)律設(shè)計(jì)了計(jì)算模型。
以上這些模型都是根據(jù)經(jīng)驗(yàn)建立語義相似度的函數(shù)表達(dá)式,主要從兩個(gè)方面提高計(jì)算語義相似度的準(zhǔn)確性:一是如何使用知識本體中的知識并進(jìn)行量化;二是如何選擇更合適的函數(shù)表達(dá)式。由于《同義詞詞林》的內(nèi)部結(jié)構(gòu)清晰簡潔,使用深度、距離和節(jié)點(diǎn)分支數(shù)作為基礎(chǔ)知識進(jìn)行相似度計(jì)算已經(jīng)成為共識。因此如何突破已有經(jīng)驗(yàn)的局限性,尋找并建立更加合理的相似度函數(shù)表達(dá)式是進(jìn)一步完善基于《同義詞詞林》的語義相似度計(jì)算方法的主要途徑。

1 《同義詞詞林》簡介
《同義詞詞林》是梅家駒等人1983年編撰的可計(jì)算漢語詞庫,后經(jīng)哈工大信息檢索研究室擴(kuò)展編輯為《哈工大信息檢索研究室同義詞詞林?jǐn)U展版》(下文簡稱《詞林》)。經(jīng)統(tǒng)計(jì)《詞林》共有77 456條詞語,分為12個(gè)大類;95個(gè)中類;1 428個(gè)小類;4 026個(gè)詞群和17 817個(gè)原子詞群。前面四個(gè)層級的節(jié)點(diǎn)都代表詞語的類別,第五層葉子節(jié)點(diǎn)上是原子詞群,每個(gè)原子詞群可用一個(gè)8位編碼唯一表示。表1展示了《詞林》中的義項(xiàng)編碼。

表1 《詞林》義項(xiàng)編碼
第八位編碼只有三種情況:其中“=”代表“相等、同義”關(guān)系;“#”代表“不等、同類”關(guān)系;“@”代表“唯一、獨(dú)立”關(guān)系。前七位編碼確定后就可以唯一確定一條編碼,不存在前七位編碼相同而第八位不同的情況。
在大類中A、B、C類多為名詞,D類多為數(shù)詞和量詞,E類多為形容詞,F(xiàn)、G、H、I、J類多為動(dòng)詞,K類多為虛詞,L類是難以被分到上述類別中的一些詞語,各大類編碼具體含義如表2所示。

表2 《詞林》大類編碼含義
《詞林》結(jié)構(gòu)安排中大類和中類的排序遵照從具體到抽象的原則[5],每個(gè)大類都可以轉(zhuǎn)化為一個(gè)樹形結(jié)構(gòu)圖,比如E大類下面分為6個(gè)中類,從“外形”到“境況”,詳見圖1。

圖1 《詞林》E大類語義場
通過上文對《詞林》整體架構(gòu)的分析,其義項(xiàng)編碼可以直接映射為一個(gè)樹形結(jié)構(gòu)圖,所有的詞語都可以對應(yīng)到葉子節(jié)點(diǎn)的詞群里。實(shí)際上這個(gè)樹形結(jié)構(gòu)圖就是使用的知識本體,而每個(gè)知識本體反映的都是作者對于世界知識的認(rèn)識,語義相似性是世界知識很重要的一個(gè)組成部分,作者在編著《同義詞詞林》時(shí)就已經(jīng)融入了語義相似信息,只是沒有把這種相似性信息數(shù)量化、數(shù)值化。因此基于《詞林》的兩個(gè)詞語之間的語義相似度計(jì)算,實(shí)際上就是解析蘊(yùn)含于知識本體中的語義相似信息,將其形式化后轉(zhuǎn)化為可計(jì)算的函數(shù)表達(dá)式,最終計(jì)算出量化的數(shù)值。
2 基于遺傳算法的語義相似度計(jì)算模型
表1說明《詞林》中共有五個(gè)層級,為便于計(jì)算,該文在第一層級上面再引入一個(gè)虛擬層級,稱為第0層,對應(yīng)樹形結(jié)構(gòu)圖中的根節(jié)點(diǎn),記為R。在此情況下《詞林》共有六層節(jié)點(diǎn)、五層邊,所有詞語都落在樹形結(jié)構(gòu)圖最底層的葉子節(jié)點(diǎn)上,所有葉子節(jié)點(diǎn)都是一個(gè)原子詞群。在該樹形結(jié)構(gòu)中將兩個(gè)節(jié)點(diǎn)之間最小的邊數(shù)稱為兩個(gè)節(jié)點(diǎn)之間的路徑長度或距離。將各非根節(jié)點(diǎn)到根節(jié)點(diǎn)R的距離稱為該節(jié)點(diǎn)的深度。
計(jì)算語義編碼分別對應(yīng)不同的葉子節(jié)點(diǎn)的詞語s1與s2的語義相似度S,根據(jù)《詞林》編碼規(guī)則,這兩個(gè)詞語在其最近公共父節(jié)點(diǎn)處分離,分屬不同類別。將其公共父節(jié)點(diǎn)記為F,將F的深度記為D。從《詞林》體系中可以直觀地看出,F(xiàn)在《詞林》體系中所處層級越高,則D的取值越小,此時(shí)s1與s2分離得越早,相似度就低;相反F在《詞林》中所處層級越低,D的取值越大,則s1和s2分開得越晚,其相似度就高。因此D的取值與S成正比關(guān)系;而F的位置與S成反比關(guān)系。這從語言學(xué)角度也很容易理解,當(dāng)兩個(gè)詞語所處的分支層的公共父節(jié)點(diǎn)越低,說明這兩個(gè)詞語所在的類別距離越近,兩個(gè)詞語的語義相似程度就越高;相反當(dāng)兩個(gè)詞語所處的分支層的公共父節(jié)點(diǎn)越高,說明這兩個(gè)詞語所在的類別距離越遠(yuǎn),兩個(gè)詞語的語義相似程度就越低。上述分析表明在《詞林》所表示的知識本體中,兩個(gè)詞語s1與s2的最近公共父節(jié)點(diǎn)的深度對其相似度起決定性作用。例如“我們”的語義編碼為“Aa02B01=”,“你”的語義編碼為“Aa03A01=”,“消毒劑”的語義編碼為“Br13D04#”。“我們”與“你”的語義類別在同一個(gè)大類A中,而“我們”與“消毒劑”的語義類別分別在A和B兩個(gè)大類中,因此前兩者的語義相似度一定高于后兩者。
在樹形結(jié)構(gòu)中還常用兩個(gè)節(jié)點(diǎn)間的路徑長度H來表示兩個(gè)節(jié)點(diǎn)之間的關(guān)系。任意兩個(gè)葉子節(jié)點(diǎn)之間的路徑長度H就是它們到其最近公共父節(jié)點(diǎn)路徑長度之和,根據(jù)《詞林》中樹形結(jié)構(gòu)的特點(diǎn):所有葉子節(jié)點(diǎn)到根節(jié)點(diǎn)R的路徑長度相同,在此記為常數(shù)C;葉子節(jié)點(diǎn)到其公共父節(jié)點(diǎn)的路徑長度也相同。而葉子節(jié)點(diǎn)到根節(jié)點(diǎn)的路徑長度等于葉子節(jié)點(diǎn)到其任意父節(jié)點(diǎn)的路徑長度與該父節(jié)點(diǎn)到根節(jié)點(diǎn)路徑長度之和。由此可以得出路徑長度與深度之間的關(guān)系式:

(1)
該結(jié)論說明路徑長度和深度是兩個(gè)能夠相互表示的量,該文在計(jì)算相似度時(shí)選擇將深度作為主要因素。文獻(xiàn)[2]在總結(jié)基于WordNet的英語語義相似度計(jì)算方法中有一類使用路徑和深度的計(jì)算方法,但由于WordNet與《詞林》的組織架構(gòu)不同,在WordNet中不同的詞語可能具有不同的深度,這種葉子節(jié)點(diǎn)深度不均勻,義項(xiàng)遍布所有節(jié)點(diǎn)的組織方式與《詞林》是截然不同的。
在《詞林》體系中,詞語按照類別逐級細(xì)分,在同一個(gè)類別中的排序遵照從具體到抽象的原則進(jìn)行排列(如圖1所示)。這說明在同一個(gè)類別層級中,意思接近的兩個(gè)分類其排列的位置也會(huì)接近,對應(yīng)到樹形結(jié)構(gòu)中,就是在同一個(gè)節(jié)點(diǎn)上排列的分支中,離得越近的分支其代表的意思也越接近。因此詞語s1與s2的語義相似度除由其最近公共父節(jié)點(diǎn)的深度決定外,也會(huì)受到該父節(jié)點(diǎn)處兩個(gè)葉子節(jié)點(diǎn)所在分支的位置關(guān)系以及最小公共父節(jié)點(diǎn)處分支總數(shù)的影響。將最近公共父節(jié)點(diǎn)所含分支總數(shù)記為N,將s1與s2所在分支的間隔數(shù)記為K。在《詞林》框架體系下,對s1與s2兩個(gè)待計(jì)算相似度的詞語,根據(jù)前面分析和相關(guān)文獻(xiàn)中的研究結(jié)果,整合為如下相似度關(guān)鍵信息x:
x=D+K/N
(2)
其中,D為最近公共父節(jié)點(diǎn)深度;N為最近公共父節(jié)點(diǎn)處分支總數(shù);K為詞語所在分支間隔數(shù)。則s1與s2之間的語義相似度y可以表示為關(guān)鍵信息x的函數(shù):
y=F(x)
(3)
目前所有基于《詞林》的語義相似度計(jì)算模型都屬于這個(gè)框架,只不過不同模型使用了不同的函數(shù)。如果把一些計(jì)算語義相似度的函數(shù)放在一起,然后再制定一個(gè)評價(jià)這些相似度計(jì)算函數(shù)的規(guī)則來評價(jià),則這些函數(shù)就可以看成是一個(gè)具有不同競爭優(yōu)勢的種群。借鑒遺傳算法的思想,對由相似度函數(shù)構(gòu)成種群進(jìn)行生物進(jìn)化方面的選擇、交叉和變異等操作來使種群進(jìn)行不斷繁衍,從而得到新的種群即新的相似度計(jì)算函數(shù)。根據(jù)自然選擇優(yōu)勝劣汰的規(guī)律,有理由相信能夠找到比單純通過經(jīng)驗(yàn)建立的更好的相似度計(jì)算函數(shù)。為實(shí)現(xiàn)這個(gè)目標(biāo),執(zhí)行以下操作:
(1)函數(shù)編碼。
首先需要將函數(shù)映射為便于使用遺傳算法的表示形式。該文將函數(shù)用樹的形式進(jìn)行編碼,目的是把函數(shù)轉(zhuǎn)化為利于計(jì)算機(jī)操作的形式。這種方法將函數(shù)中包含的四則運(yùn)算、復(fù)合運(yùn)算作為樹的中間節(jié)點(diǎn),將自變量x作為樹的葉子節(jié)點(diǎn)。例如對于具有如下形式的相似度計(jì)算函數(shù):
y=F(x)=w1x2+w2R+w3ex+w4sinx
本文的驗(yàn)證問題可描述為:給定系統(tǒng)狀態(tài)轉(zhuǎn)換模型TS,系統(tǒng)安全屬性φsafe以及系統(tǒng)運(yùn)行時(shí)的觀測序列o1,…,ot,目標(biāo)是 (1)計(jì)算在t時(shí)刻系統(tǒng)滿足安全屬性的概率Prt(TS φsafe|o1,…,ot;TS),(2)當(dāng)系統(tǒng)違背安全屬性時(shí),求解系統(tǒng)最大可能的執(zhí)行路徑作為系統(tǒng)違背安全屬性的反例.針對該問題,圖1給出了本文驗(yàn)證方法的框架.
(4)
其中,w1,w2,R,w3,w4為常數(shù),則可以表示為圖2所示的樹狀結(jié)構(gòu)。

圖2 函數(shù)編碼的樹狀結(jié)構(gòu)
根據(jù)這種思想,語義相似度計(jì)算函數(shù)的自變量就是上面的《詞林》信息x,將基本初等函數(shù)作為基本的函數(shù)集F={x,sinx,lnx,ex,arcsinx},取四則運(yùn)算為運(yùn)算集H={+,-,×,÷}。在生成函數(shù)種群時(shí),只需從不同集合中選取元素填入相應(yīng)節(jié)點(diǎn),就可以生成不同的函數(shù),反復(fù)操作2M次即可生成一個(gè)含有2M個(gè)函數(shù)的初始種群。
(2)適應(yīng)度函數(shù)。

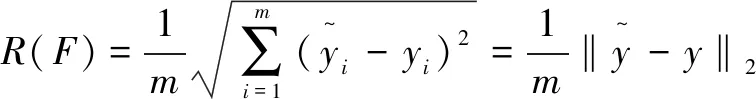
(5)
顯然R(F)越小,相似度函數(shù)F的計(jì)算結(jié)果與標(biāo)準(zhǔn)結(jié)果就越接近,該個(gè)體在種群中就越優(yōu)秀,具有更強(qiáng)的競爭力。
(3)選擇。
要完成種群的更新需要從父代群體中選取部分個(gè)體,以便生存和繁衍產(chǎn)生下一代群體,這種操作稱為選擇。該文采取優(yōu)者勝出的選擇方法,將當(dāng)前種群中的2M個(gè)函數(shù)按照適應(yīng)度R(F)從小到大進(jìn)行排序,然后將適應(yīng)度最好的M個(gè)函數(shù)保留,將較差的M個(gè)函數(shù)淘汰,以保留下來的M個(gè)函數(shù)為基礎(chǔ)進(jìn)行下面的操作形成下一代種群。
在遺傳算法中交叉是利用父代個(gè)體形成子代個(gè)體的過程,該文研究的個(gè)體是函數(shù),在將函數(shù)編碼后,隨機(jī)設(shè)置交叉點(diǎn),然后在交叉點(diǎn)處進(jìn)行斷開和重組,完成基因交換,生成新的個(gè)體。具體過程如圖3所示,左邊為選擇的兩個(gè)個(gè)體,圖中方框處為選擇作為斷點(diǎn)的節(jié)點(diǎn)位置,然后分別交換和重組后,得到右側(cè)兩個(gè)新生成的個(gè)體。

圖3 交叉生成新的個(gè)體
(5)變異。
遺傳算法中的變異,是指將個(gè)體編碼串中的某些基因用其他等位基因來替換,從而形成新個(gè)體的過程。例如圖4中,左側(cè)為選中的變異個(gè)體,其中方框處為選擇的變異位置,右側(cè)為該位置變異后生成的新個(gè)體。

圖4 變異生成新的個(gè)體
以上過程描述了一種基于遺傳算法的相似度函數(shù)構(gòu)建模型,該方法使用遺傳算法的思想,隨機(jī)生成一系列函數(shù)個(gè)體組成初始的“種群”,然后根據(jù)適應(yīng)度函數(shù)來評價(jià)個(gè)體的適應(yīng)度。若當(dāng)前種群中的函數(shù)所計(jì)算的語義相似度都不能滿足要求,則模擬生物進(jìn)化中的基因變異、復(fù)制、刪除等行為,繁衍生成新一代種群,經(jīng)過不斷迭代,尋找更好的語義相似度計(jì)算函數(shù)。下面根據(jù)遺傳算法的思想為《詞林》建立語義相似度計(jì)算模型,具體算法描述如下:
第1步:給定m組詞語的《詞林》信息{x1,x2,…,xm}和標(biāo)準(zhǔn)相似度結(jié)果{y1,y2,…,ym},基本函數(shù)集F={x,sinx,lnx,ex,arcsinx},運(yùn)算符號集H={+,-,×,÷},最大進(jìn)化代數(shù)T。
第2步:隨機(jī)生成包含2M個(gè)計(jì)算語義相似度的函數(shù)初始種群:{F1,F2,…,F2M}。
第3步:當(dāng)進(jìn)化代數(shù)小于最大進(jìn)化代數(shù)時(shí),生成新的計(jì)算語義相似度函數(shù)種群,完成種群繁衍迭代。具體方法如下:
①選擇:計(jì)算種群內(nèi)全部語義相似度函數(shù)個(gè)體{F1,F2,…,F2M}的適應(yīng)度,保留M個(gè)適應(yīng)度最好的語義相似度函數(shù)個(gè)體;
②交叉:隨機(jī)選擇兩個(gè)語義相似度函數(shù),通過交叉生成新的函數(shù),重復(fù)四分之三M次,生成復(fù)四分之三M個(gè)新的語義相似度函數(shù);
③變異:隨機(jī)選取四分之一M個(gè)語義相似度函數(shù),然后隨機(jī)選取節(jié)點(diǎn)進(jìn)行變異,生成四分之一M個(gè)新的語義相似度函數(shù);
第4步:回到第3步繼續(xù)進(jìn)化,直到達(dá)到最大進(jìn)化代數(shù);
第5步:計(jì)算最終得到的種群中M個(gè)語義相似度函數(shù)的適應(yīng)度,并將最優(yōu)個(gè)體作為最終相似度計(jì)算函數(shù)。
該方法中采取了優(yōu)者勝出的選擇方法,每一代中的最優(yōu)個(gè)體會(huì)保留到下一代中,隨著種群的繁衍,該方法會(huì)得到越來越優(yōu)秀的個(gè)體,即越來越好的相似度計(jì)算函數(shù)。如果達(dá)到最大繁衍代數(shù)后,得到的相似度計(jì)算函數(shù)還不夠理想,可以適當(dāng)增加種群大小,即增加迭代次數(shù),甚至反復(fù)執(zhí)行該方法,直到得到滿意的相似度計(jì)算函數(shù)為止。
3 實(shí)驗(yàn)及結(jié)果分析
目前國際上對語義相似度算法的評價(jià)標(biāo)準(zhǔn)普遍采用Miller & Charles發(fā)布的30組英語詞對集(簡稱MC30)的人工判定值作為比較或?qū)W習(xí)的標(biāo)準(zhǔn)[14-15]。該文首先根據(jù)《詞林》提供的關(guān)于這30組詞對的信息計(jì)算其相應(yīng)的詞對信息值x;然后使用遺傳算法模型尋找關(guān)于x的相似度函數(shù)表達(dá)式;最后,使用新找到的模型重新計(jì)算詞對相似度并與標(biāo)準(zhǔn)結(jié)果和相關(guān)結(jié)果進(jìn)行對比。在試驗(yàn)中設(shè)定函數(shù)構(gòu)成分量的長度為3;此時(shí)函數(shù)關(guān)系式可表示為:
F(x)=w1f1(x)+w2f2(x)+w3f3(x)
(6)
初始種群的數(shù)量為50,在遺傳算法開始時(shí)隨機(jī)產(chǎn)生50個(gè)函數(shù){Fi(x),I=1,2,…,50};此后每代種群的最大數(shù)量為100,即有100個(gè)候選函數(shù);種群的最大進(jìn)化代數(shù)為1 000代。若達(dá)到最大進(jìn)化代數(shù),則選取最后一代中最優(yōu)的函數(shù)作為相似度計(jì)算模型。經(jīng)過運(yùn)行模型算法,最終選定的函數(shù)模型為:
(7)
利用式(7)計(jì)算得到的語義相似度結(jié)果如表3所示。

表3 語義相似度計(jì)算結(jié)果

續(xù)表3
遺傳算法模型對MC30語義相似度的具體計(jì)算結(jié)果如表3所示,該文計(jì)算結(jié)果與皮爾遜相關(guān)系數(shù)為r=0.864 5。在實(shí)際應(yīng)用中一般認(rèn)為:當(dāng)r≥0.8時(shí),兩個(gè)變量間高度相關(guān);當(dāng)0.5≤r<0.8時(shí),兩個(gè)變量中度相關(guān)。以上結(jié)果說明,該文提出的語義相似度計(jì)算模型能夠表達(dá)《詞林》中包含的詞語相似度關(guān)系,與人工值有較強(qiáng)的相關(guān)性。從表3中的相似度計(jì)算值中可以看出,仍然存在該文計(jì)算結(jié)果與MC30的人工判定值有較大差異的詞對,比如第10個(gè)詞對“食物(Br03A01=)”與“水果(Bh07A01=)”;第14個(gè)詞對“兄弟(Aa02A07=)”與“和尚(Am01B04=)”。其差異的深層次主要原因是《詞林》中對該詞對的相似度判斷標(biāo)準(zhǔn)與MC30的判斷標(biāo)準(zhǔn)在語言學(xué)認(rèn)識上的差異。這種差異既有不同判定者主觀因素,也有不同語言之間在翻譯時(shí)所帶來的差異。
4 結(jié)束語
該文所提出的語義相似度計(jì)算方法是在《詞林》體系中詞語的深度、路徑和分支節(jié)點(diǎn)信息基礎(chǔ)上進(jìn)行的,充分利用了人工智能遺傳算法強(qiáng)大的搜索能力,所得相似度計(jì)算模型更為準(zhǔn)確合理。在此研究過程中發(fā)現(xiàn),已有的模型中有一些詞語無論使用哪種方法,其計(jì)算結(jié)果均不理想,這種情況一般既有知識本體中義項(xiàng)定義或者詞語分類不合理的原因,也有相似度計(jì)算模型不夠完善的原因。為了克服前人研究中的不足,在知識方面充分利用《詞林》已有的詞語信息;在算法方面利用遺傳算法從更大更廣的函數(shù)空間中尋找函數(shù)模型,因此所得結(jié)論中既能得到較為理想的計(jì)算結(jié)果,也能更好地反映出語言知識層面的關(guān)系。
猜你喜歡
小學(xué)時(shí)代·科學(xué)小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會(huì)歷史評論(2016年2期)2016-06-27 07:11:52
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
長江學(xué)術(shù)(2016年4期)2016-03-11 15:11:31
中學(xué)語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當(dāng)代修辭學(xué)(2011年6期)2011-01-29 02:49:50
 計(jì)算機(jī)技術(shù)與發(fā)展2021年2期
計(jì)算機(jī)技術(shù)與發(fā)展2021年2期
- 計(jì)算機(jī)技術(shù)與發(fā)展的其它文章
- 2020年CCF科學(xué)技術(shù)獎(jiǎng)-自然科學(xué)獎(jiǎng)獲獎(jiǎng)項(xiàng)目簡介
- 平行耦合微帶帶通濾波器的設(shè)計(jì)與仿真
- 2020年“CCF優(yōu)秀博士學(xué)位論文獎(jiǎng)”獲獎(jiǎng)名單
- 大數(shù)據(jù)環(huán)境下高校移動(dòng)學(xué)習(xí)平臺的設(shè)計(jì)與實(shí)現(xiàn)
- 基于初始化非負(fù)矩陣分解的光伏發(fā)電預(yù)測
- 基于多元經(jīng)驗(yàn)?zāi)J椒纸獾腟SVEP目標(biāo)識別研究