基于膠囊網絡在復雜場景下的行人識別
2021-03-08 00:24:46程換新劉文翰郭占廣張志浩
計算機技術與發展 2021年2期
程換新,劉文翰,郭占廣,張志浩
(青島科技大學 自動化與電子工程學院,山東 青島 266061)
0 引 言
隨著國家的各項城市工程建設,視頻監控攝像頭的數量也在不斷增長,隨之帶來的就是視頻信息的大數據化。因此,現如今開發視頻數據中的重要價值越來越受到人們的重視。比如公安部門可以通過視頻信息實現對目標人物的跟蹤、搜尋,亦可用來分析行人的種種行為是否存在異常[1],這無疑是保障社會安全的又一有力手段。
“深度學習”這一概念是在2006年被提出的,在這短短的十幾年間已經發展出了大量算法,但是將深度學習這一技術實際應用于圖片分析依然以卷積神經網絡(CNN)為主。然而因為卷積神經網絡的一些結構缺陷,例如無法充分地表明下層各對象之間的空間關系,而且在池化的過程中會將一些位置信息丟失[2],這使得卷積神經網絡在某些場景下的圖片識別并不能達到令人滿意的效果。
膠囊(capsule)[3]的概念是由Sabour S等人首次提出的,他們在文中創建了一個結構簡單的三層膠囊網絡(capsule network),并且利用該網絡實現對Mnist手寫數字識別,識別的準確率達到了97.5%,直接超越了LeNet-5模型[4]。Hinton等人在2018年發表的論文中對膠囊網絡中的動態路由迭代算法進行了介紹,并提出了一種新的EM路由算法,對膠囊網絡核心路由算法進行改進[5]。改進的膠囊網絡通過使用動態路由算法替代了CNN的池化操作[6-7],從而使得特征損失有所減小,能夠在一定程度上提高圖像識別的準確率。但是在目前復雜環境的應用場景下的識別研究還是少數。該文在原有Hinton提出的膠囊網絡的基礎上,對網絡的結構進行一定的改進,提出了基于改進膠囊網絡的行人識別算法PRM-ICN。并使用三個公開通用的數據集CUHK01[8]、CUHK03[9]和Market-1501[10]對該模型進行訓練及驗證。
1 改進膠囊網絡模型
經過改進后的膠囊網絡模型如圖1所示,共包含三層卷積層,一層多維Primary Capsule Layer,一層Intermediate Capsule Layer以及一層Advanced Capsule Layer。
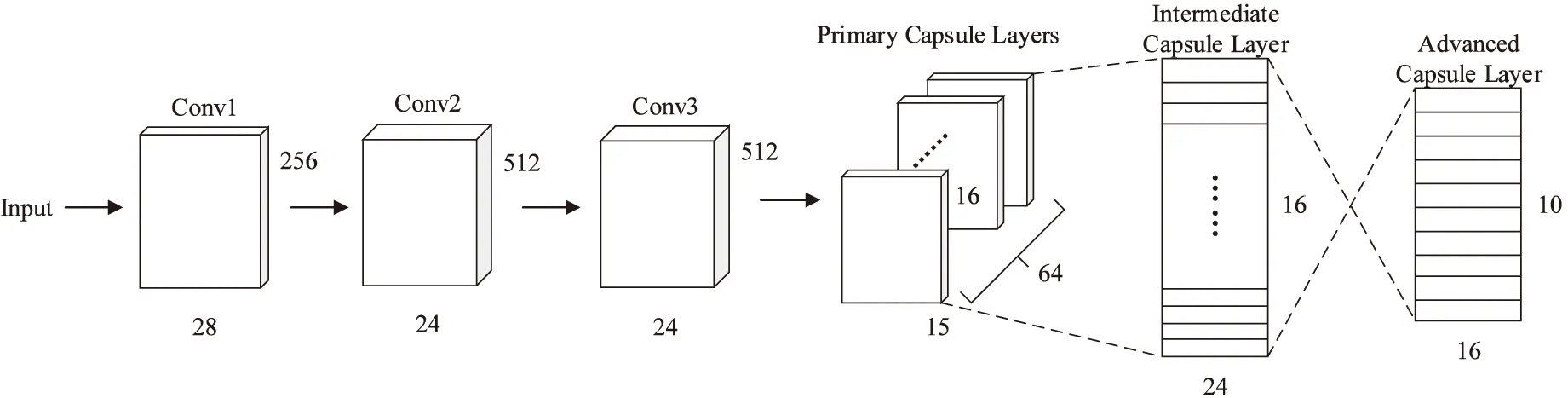
圖1 改進的膠囊網絡模型結構
1.1 增加卷積層
在復雜場景下的圖片所包含的信息量是巨大的,然而在圖片中存在著過多的干擾信息。為了能夠減少無用信息的干擾,充分聯系圖片中各特征的關系,并且可以在進入Primary Capsule Layer之前過濾一部分噪聲。該網絡在Conv 1層之后又額外增加了兩層卷積層Conv 2和Conv 3,從而可以減少復雜背景中多余信息對網絡產生的干擾。
1.2 膠囊維度擴展
經過三層的卷積網絡后,輸入圖片的大量有用特征被提取,經過Primary Capsule Layer和Intermediate Capsule Layer對信息進行處理后將其壓縮至膠囊中。該網絡中的典型結構是膠囊結構,膠囊是存儲信息的單元,膠囊結構的維度越大,就有充足的存儲單元對網絡中的有效信息進行保存。因此,在該網絡將其維度擴展至16D。
1.3 Intermediate Capsule Layer
在膠囊層的內部,底層的特征膠囊利用姿態關系來對高層特征進行預測,之后利用動態路由算法以及篩分決策機制對高層膠囊進行選擇性的激活,這就等同于篩選出了部分低層膠囊網絡的預測結果,并且使高層膠囊選擇性激活。
經過上述的改動之后,該網絡的運行情況如下:
Conv 1:先將輸入的彩色圖片用256個5×5大小的卷積核進行卷積操作,其卷積步長為1。并且在卷積操作過程中使用ReLu激活函數。
Conv 2:對Conv 1經過卷積得到的初步特征使用512個5×5的卷積核進行卷積操作,其卷積步長為1,進而得到Conv 2層的輸出結果。
Conv 3:進一步地將Conv 2層卷積得到的特征進行卷積操作,使用512個5×5大小的卷積核。
Primary Capsule Layer:對Conv 3層的輸出結果進行向量化操作。采用16組不同的卷積核,而每一組卷積核中又包含64個不同的15×15的卷積核,卷積的步長設置為1,該卷積操作的激活函數使用ReLu。經過該步操作后,得到低級特征Ui,該特征為1×16的向量。其過程如圖2所示。
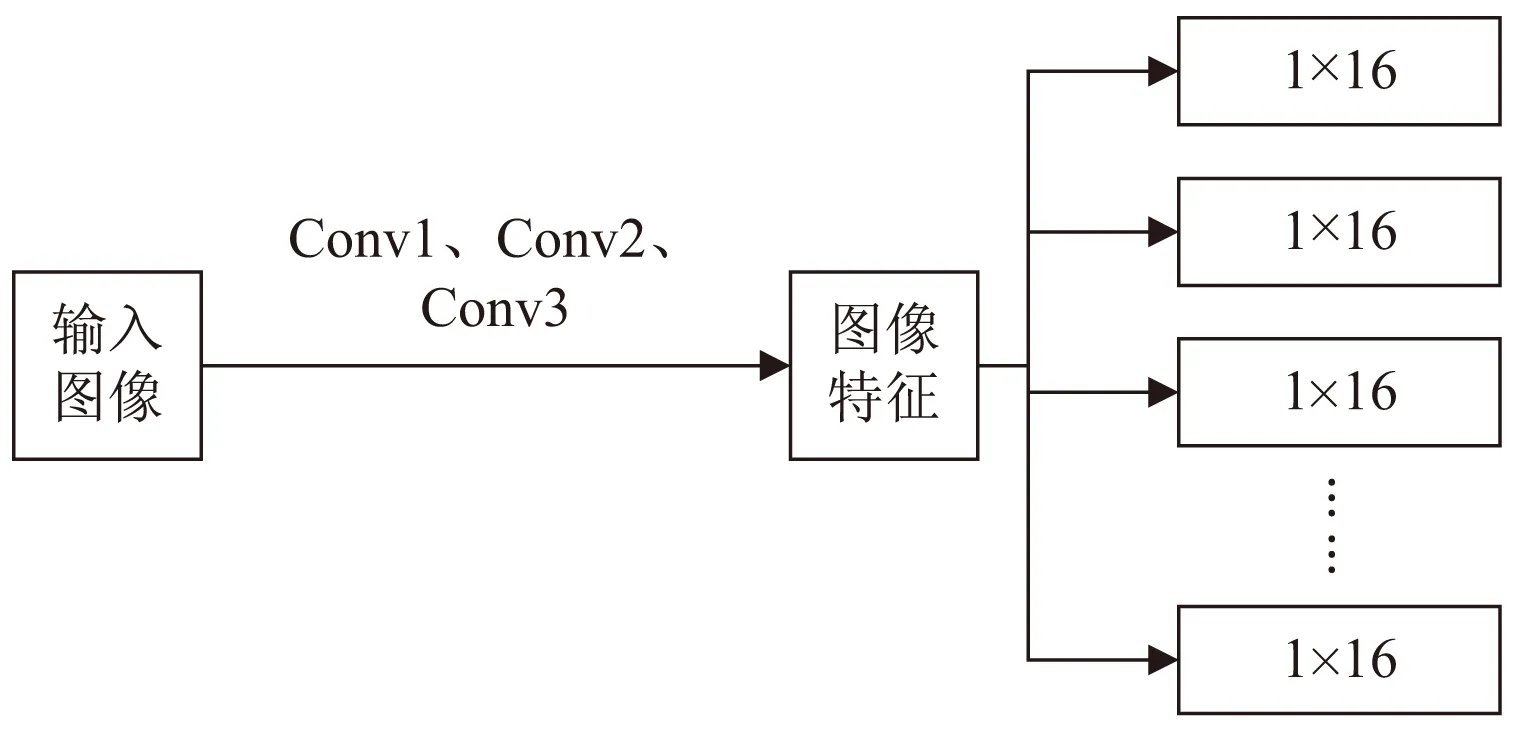
圖2 Primary Capsule Layer結構
Intermediate Capsule Layer:通過上一層得所到的低級特征Ui以及各膠囊層之間的姿態關系Wij來對高級特征Uj|i進行預測。即Uj|i=Ui·Wij。
Advanced Capsule Layer:利用得到的底層特征對高層特征進行預測,并利用動態路由算法以及篩分決策機制對高層特征膠囊進行選擇性激活,最終實現分類功能。
2 關鍵算法
2.1 向量神經元
在膠囊網絡中,每個膠囊包含著眾多神經元,每一個神經元存儲了從圖片中獲取的特征。與CNN不同,在膠囊網絡中采用向量神經元而非標量神經元,這就使得神經元可以表達的信息更豐富,從而能夠提高網絡的識別率。每一個向量神經元都有其自身的屬性,各種各樣的實例化參數都可以包含于其屬性當中,比如姿態、變形、速度等。除此之外,膠囊還存在一個特殊屬性,該屬性描述的是圖像中某一類別實例的存在與否。該屬性的值為概率,其大小又取決于該向量神經元的模長,模長越大則概率越大,反之亦然。向量神經元通過Squash()函數進行激活,該函數能夠對該向量的長度進行放大或縮小,而向量的長度又代表某一時間發生的可能性。經過該函數的激活后,能夠將特征顯著的向量進行放大,將特征不夠明顯的向量進行縮小,從而提高識別率。
2.2 姿態關系轉換
膠囊層中物體各部分之間的分層姿態關系通過姿態矩陣表現出來[11-12]。為了正確地識別物體,首先應當保持分層姿態關系。而姿態無非包括旋轉(rotation)、平移(translation)和縮放(scale)三種。若將某個物體姿態先逆時針旋轉60°,再將其向右平移3個單位,之后再縮放至原來的50%,那么可以通過以下矩陣連乘的方式得到。其中等式右邊前三個矩陣分別為R、T、S,而該三個矩陣相乘即為姿態矩陣M。
2.3 動態路由迭代算法
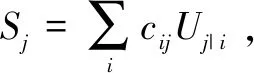

圖3 動態路由迭代算法
2.4 Squash函數
該函數能夠對該向量的長度進行放大或縮小,并且保證每個膠囊的長度都介于0到1之間。因此,每個事件發生的概率大小都可以使用每個膠囊的長度所替代,這就能提高大概率事件的可能性,而降低小概率事件的發生幾率,從而提高識別的準確度。該函數的表達式為:
其中,Vi是該函數的輸出,也就是長度在0到1之間的一個向量;Sj是輸入該函數的一個膠囊,而該膠囊是經過前述三層卷積運算后的結果。對于等式右邊的第一項,該項的作用僅為放縮膠囊的長度,使得長度大的膠囊更長、長度小的膠囊進一步縮小。對于等式右邊的第二項,該項的作用是保持原有的膠囊方向不變,也就是保持事件除概率外的各項特征不發生變化。
3 實驗與分析
為了驗證提出的基于膠囊網絡的復雜場景下行人識別模型(PRM-ICN)的性能,在三個流行的公開數據集CUHK01、CUHK03和Market-1501上進行了實驗,實驗的結果及分析見下文。
3.1 實驗設置
在本次實驗中,整個網絡的實現是在TensorFlow框架下完成的,編程語言使用的是Python,GPU型號為GTX 1080Ti。對于實驗結果的評價,采用常用的兩個指標,即累計匹配曲線(cumulative match curve,CMC)和平均精度均值(Mmean average precision,MAP)。在行人識別領域中,一個必不可少的對模型的重要評價指標就是CMC曲線,該指標能夠充分反映分類器的性能。MAP曲線即為平均AP值,是對多次查詢結果求平均AP值。
此外,為了驗證本網絡的有效性,還與另外兩個在該領域性能不錯的模型進行了對比,這兩個模型分別為基于AlexNet的行人識別方法(PRM-AlexNet)[14]和基于VGG-16的行人識別方法(PRM-VGG-16)[15]。其中AlexNet包含5個激活函數為ReLu的卷積層和3層全連接層。VGG-16網絡包含13個激活函數為ReLu的卷積層和3層全連接層。
3.2 數據集
本實驗采用了三個公開通用的數據集CUHK01、CUHK03和Market-1501對該模型進行訓練及驗證。數據集CUHK01中包括971人,其中每人都有包含正面、背面以及兩側的四張圖片,在實驗中選取前750人作為訓練集,剩余作為測試集;數據集CUHK03包含13 164張行人圖片,涵蓋了1 360個人,在實驗中選取前1 100人作為訓練集,剩余作為測試集;數據集Market-1501包括1 501個行人共32 668張圖片,在本次實驗中選取前1 300個人的圖片作為訓練集,剩余作為測試集。數據集中的部分圖片如圖4所示。

圖4 數據集中的部分圖片
3.3 實驗結果分析
在三個數據集上的實驗結果如表1所示。從表中可以看出,因為CUHK01中的圖片數據相對較少,而PRM-AlexNet和PRM-VGG-16網絡結構過于復雜超參數也較多,使得在訓練過程中極容易發生過擬合的現象,很難利用到其深層網絡的作用,從而導致兩者的CMC較低。在三個數據集上,提出的基于膠囊網絡的行人識別模型的CMC曲線值均高于上述兩種方法。
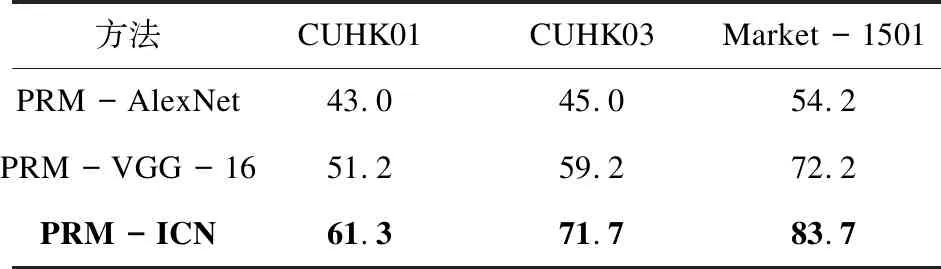
表1 不同方法的CMC比較
該文創建的模型PRM-ICN在三個數據集上的MAP值如圖5所示。從圖中可以看出,在三個數據集下,所提模型在MAP值上的表現都優于其他兩種網絡。在CUHK01數據集上,所提模型較其他兩種方法的MAP值分別提高了0.18和0.16;在CUHK03數據集上,所提模型較其他兩種方法的MAP值分別提高了0.22和0.20;在Market-1501數據集上,所提模型較其他兩種方法的MAP值分別提高了0.17和0.10。
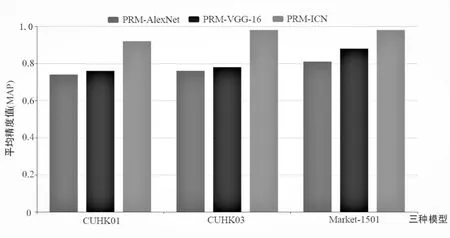
圖5 不同模型的MAP值
通過上述實驗表明,提出的基于膠囊網絡的復雜場景下行人識別模型的性能較好。因為其在對不同姿態和空間關系的識別對象進行處理時,可以通過姿態轉換來對圖像進行變換,提高了識別準確率。
4 結束語
針對復雜場景下行人識別難度大的問題,為了讓膠囊網絡能夠在復雜場景下對行人圖像進行更高準確度的識別,在原始的膠囊網絡基礎之上對網絡結構進行了優化,使之提高了在處理復雜場景中消除無用信息的能力,提出了基于改進膠囊網絡的行人識別模型,并與在該領域識別效果不錯的模型PRM-AlexNet和PRM-VGG-16進行了對比。所提出的模型在CMC曲線及MAP值上都優于前兩者。但是該模型的識別率還未達到預期,并且還存在一定的局限性,比如并未詳細考量光線變化較大的情況。未來會將更多的環境因素考慮在內,不斷地修改網絡結構、完善模型,使之識別準確率進一步提高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
