一種面向Mashup應(yīng)用的API推薦方法
2021-03-08 00:24:46李鑫
計算機技術(shù)與發(fā)展 2021年2期
李 鑫
(河南大學(xué) 計算機與信息工程學(xué)院,河南 開封 475000)
0 引 言
近年來,隨著Web2.0技術(shù)的興起,大量功能豐富的Web服務(wù)不斷涌現(xiàn)。Web服務(wù)基于互聯(lián)網(wǎng)提供一種端到端的解決方案,由于其低成本、簡單易用等優(yōu)點逐漸受到開發(fā)者們的青睞。為了滿足更復(fù)雜的場景和個性化需求,人們將多種功能不同的Web服務(wù)及其資源組合成Mashup服務(wù)。由于Web服務(wù)所處網(wǎng)絡(luò)環(huán)境動態(tài)變化,導(dǎo)致用戶選擇并調(diào)用的Web服務(wù)常常不可獲取(unavailable),即發(fā)生服務(wù)失效,這在一定程度上影響了用戶對服務(wù)的選擇,進而影響Mashup服務(wù)的應(yīng)用。因此,在Web服務(wù)出現(xiàn)失效或不可用的情況下,獲取(unavailable),即發(fā)生服務(wù)失效,這在一定程度上影響用戶對服務(wù)的選擇,進而影響Mashup服務(wù)的應(yīng)用。因此,在Web服務(wù)出現(xiàn)失效或不可用的情況下,如何為用戶推薦可替代的Web服務(wù),仍然是一個亟待解決的關(guān)鍵問題。
目前,國內(nèi)外研究人員針對失效服務(wù)無法調(diào)用的情形進行了相關(guān)研究。文獻[1]探討了服務(wù)描述文檔(WSDL)中無效文件格式、解析錯誤和調(diào)用目標(biāo)異常等造成服務(wù)失效的具體原因。文獻[2]采用基于WordNet的概念語義進行功能相似度匹配,然后根據(jù)服務(wù)的調(diào)用率,從Web服務(wù)描述文檔質(zhì)量角度構(gòu)建Web服務(wù)質(zhì)量評價模型,進而選取服務(wù)以替換無效的Web服務(wù)。文獻[3]在流程執(zhí)行前,通過查詢UDDI及QoS約束過濾,預(yù)先獲得各成員服務(wù)的候選服務(wù)集合,并引入面向切面技術(shù)擴展BPEL引擎,通過容錯代理切面攔截服務(wù)請求和調(diào)用服務(wù)實例,在服務(wù)失效時利用候選服務(wù)集合中的等價服務(wù)替代失效服務(wù)。但是,上述方法在為失效服務(wù)選擇可替代服務(wù)時沒有考慮到服務(wù)本身的規(guī)格信息,比如服務(wù)遵循的協(xié)議、服務(wù)的相應(yīng)格式等。
針對該問題,該文提出了一種面向Mashup應(yīng)用的API推薦方法。該方法首先從服務(wù)注冊網(wǎng)站Programmableweb上爬取了API描述信息及其規(guī)格(Specs)信息,并對API的描述信息和規(guī)格信息進行預(yù)處理;在此基礎(chǔ)上,通過LDA(latent Dirichlet allocation)主題模型對API描述信息進行主題聚類,然后從功能相似性角度出發(fā),識別失效API所屬的主題類簇,進而從API的規(guī)格信息方面通過Jaccard系數(shù)對失效API所屬的類簇內(nèi)的API進行篩選,將失效API與類簇內(nèi)篩選后的API進行描述相似度計算并將相似度從高到低排序,將前Top-n個API進行推薦。
1 相關(guān)研究
文獻[4]通過以Web API的描述文檔信息為語料庫,通過HDP模型訓(xùn)練每個Web API的主題分布向量,利用已生成的主題模型預(yù)測每個Mashup的主題分布向量,用于相似度計算,并將Mashup間的相似度、Web API間的相似度、Web API的流行度共現(xiàn)性作為模型的輸入信息,將得到的評分排序獲取用于推薦的Web APIs集合。文獻[5]通過用戶歷史記錄信息,獲得用戶對API服務(wù)的興趣值,從而得到用戶對API的評分,通過Mashup調(diào)用API次數(shù)可以獲得Mashup的評價貢獻和API訪問量,獲得API服務(wù)的信譽評價值,根據(jù)用戶對API服務(wù)的興趣值以及信譽評價值,獲取API服務(wù)的排名順序,從而實現(xiàn)推薦。文獻[6]針對API服務(wù)進行個性化推薦,其方法是通過Spark計算框架與改進的相似度計算相結(jié)合,解決了傳統(tǒng)算法中的數(shù)據(jù)稀疏問題,提高了推薦算法的執(zhí)行效率。
上述方法雖然考慮了API的表征能力以及API的流行度共現(xiàn)性,但是沒有考慮到API本身的規(guī)格信息,比如,Programmableweb網(wǎng)站中每個API都有相應(yīng)的Specs信息,具體包括Authentication Model、SSL Support、Supported Response Formats、Supported Request Formats等。在該研究中,首先對預(yù)處理后的API進行主題聚類,然后結(jié)合API的規(guī)格信息對特定主題類簇下的API進行過濾,在此基礎(chǔ)上進行相似度計算,將相似度排名Top-n的API推薦給用戶。
服務(wù)聚類是輔助服務(wù)發(fā)現(xiàn)的一種重要方法。目前基于相似度的服務(wù)聚類方法已有大量研究,具體描述如下:
(1)基于用戶自身偏好相似度的服務(wù)聚類。文獻[7]提出為用戶與物品之間定義了一層關(guān)系,這層關(guān)系是由用戶自身偏好的關(guān)鍵屬性決定的,由此來排除不符合這層關(guān)系的集合,并結(jié)合對各個不同屬性分配不同的權(quán)重來挑選出最符合的服務(wù)。文獻[8]提出了基于Web服務(wù)描述語言、服務(wù)本體描述語言和文本方法的Web服務(wù)聚類方法。
(2)基于服務(wù)文本相似性的服務(wù)聚類。文獻[9]提出一種可以分步驟的對服務(wù)進行聚類的方法,第一步,先是利用一個具有融合領(lǐng)域特性的支持向量機對一個服務(wù)進行分類的操作;第二步,對進行分類后得到領(lǐng)域內(nèi)服務(wù)的集合進行主題特性聚類。文獻[10]通過建立一個服務(wù)的融合領(lǐng)域特征和內(nèi)容支持向量,并通過使用T-LDA方法建立一個融合領(lǐng)域標(biāo)簽信息得到的隱含主題信息表示模型,用于同一融合領(lǐng)域服務(wù)進行聚類的操作。
(3)基于LDA的服務(wù)聚類。采用LDA的主題模型對其服務(wù)描述信息模型文檔進行了建模,并設(shè)計和分析其包含的主題描述信息的分布,挖掘潛在語義知識,有助于解決使用單一關(guān)鍵字引起的信息丟失問題。
該文基于Word2vec和LDA對API描述文檔進行主題聚類,在此基礎(chǔ)上,結(jié)合API本身的規(guī)格信息,有利于提高可替代API服務(wù)推薦的準(zhǔn)確率。
2 融合描述和Specs的API推薦方法
2.1 方法的框架研究
研究框架如圖1所示。首先通過網(wǎng)絡(luò)爬蟲技術(shù)爬取Programmableweb網(wǎng)站上的API描述信息和API Specs信息,然后對API描述信息和API Specs信息進行預(yù)處理。在此基礎(chǔ)上,基于Word2Vec和LDA主題模型對預(yù)處理后的API描述信息進行主題聚類;針對特定失效API,通過相似度計算識別該API所屬的主題類簇;進一步通過Jaccard系數(shù)計算該主題類簇下的API的規(guī)格信息與失效API的規(guī)格信息間的相似度,篩選出規(guī)格信息滿足要求的API集。最后將失效API與篩選后的API集合中的每個API進行相似度計算,將相似度較高的Top-n個API返回,從而實現(xiàn)失效API的推薦。
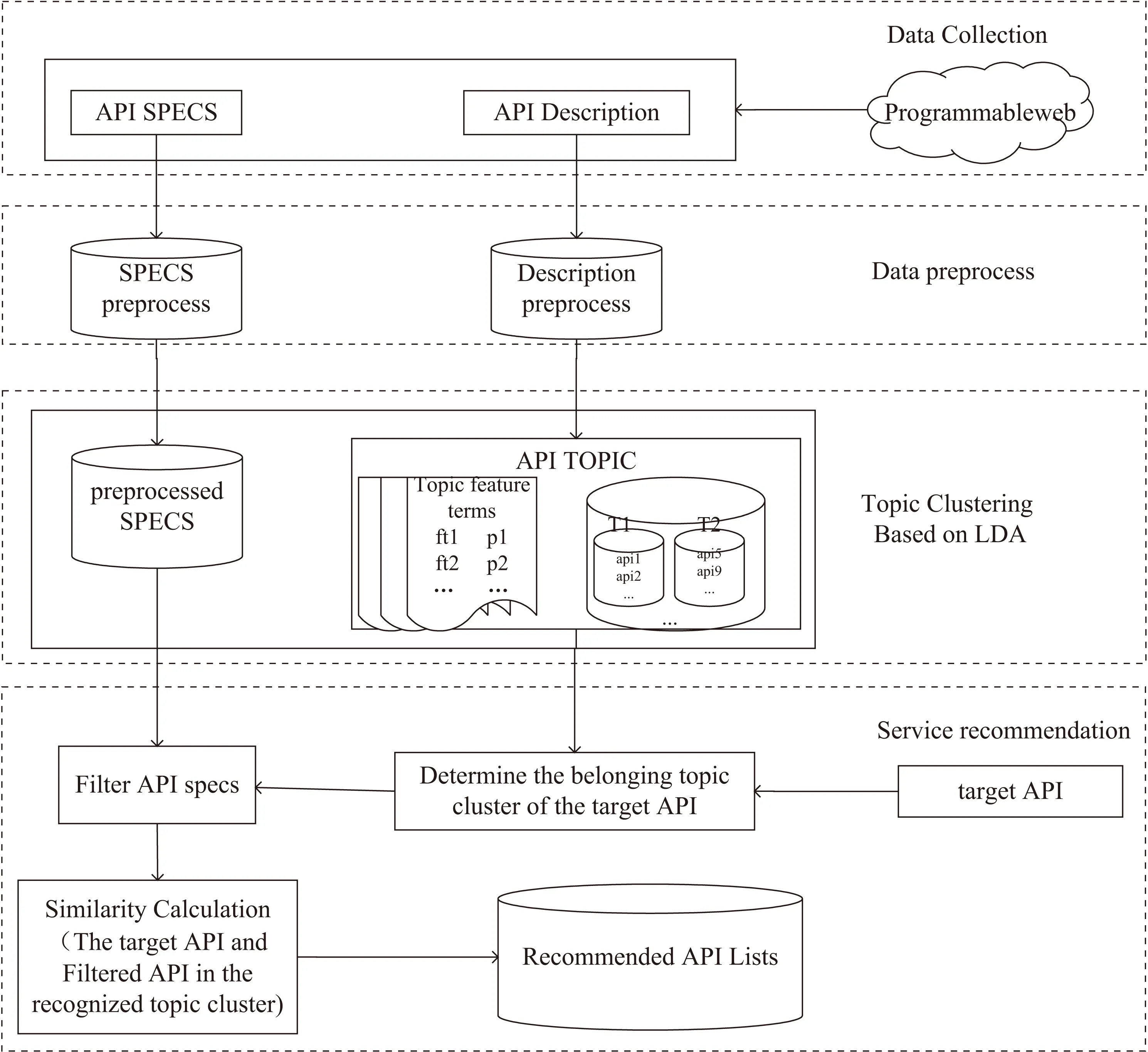
圖1 融合描述和Specs的API推薦框架
2.2 基于描述和Specs的API推薦
2.2.1 數(shù)據(jù)收集及預(yù)處理
實驗數(shù)據(jù)來自Programmableweb.com網(wǎng)站上的真實服務(wù)數(shù)據(jù)。該網(wǎng)站提供了大量的API服務(wù)數(shù)據(jù)。爬取了Programmableweb網(wǎng)站上包含API數(shù)目大于900的“category”中所有API的描述信息以及Specs信息,主要包括Authentication Model、SSL Support、Supported Response Formats、Supported Request Formats等。
接下來,需要對每個API描述信息和Specs信息進行預(yù)處理。首先對API描述中的句子進行過濾,去掉數(shù)字、標(biāo)點以及非字母符號,并將字母統(tǒng)一小寫;然后進行錯別單詞檢測,下一步建立停用詞表去除文本中的所有停用詞,例如“an”、“it”、“is”、“and”等等;最后將這些英文單詞全部進行了詞干化處理,主要解決方法包括將復(fù)數(shù)名詞變?yōu)閱螖?shù)和動詞時態(tài)形式變?yōu)樵嫉膭釉~形態(tài)等。
2.2.2 基于描述的API聚類
LDA是一種文檔主題生成模型,包含特征詞、隱含主題和文檔三層結(jié)構(gòu)[11]。LDA可以將文檔集中每篇文檔的主題以概率分布的形式給出,從而通過分析一些文檔抽取出它們的主題(分布),進而根據(jù)主題(分布)進行主題聚類或文本分類。該文使用LDA主題模型對預(yù)處理后的API描述進行聚類。LDA主題概率模型建模過程是一個通過文檔集合建立生成模型的反向過程。假設(shè)給定一個文檔集D,其包含M個文檔,主題數(shù)為k,即Nm為第m個文檔的單詞總數(shù),Zm,n為第m個文檔中第n個詞的主題;Wm,n為m個文檔中的第n個詞;α和β為它們的先驗參數(shù);隱含變量θm表示第m個文檔下的Topic分布;φk表示第k個主題下詞的分布D={d1,d2,…,dm},dm={wm1,wm2,…,wmn}表示第m篇文檔,zm={zm1,zm2,…,zmn}表示文檔dm中每個單詞對應(yīng)所屬主題的集合。
將API描述信息作為LDA模型的輸入,采用吉布斯抽樣(Gibbs sampling)方法,得到每個描述文檔的文檔主題矩陣和詞主題矩陣,根據(jù)每個API包含的不同主題的概率對API描述信息進行聚類。假設(shè)API的描述信息Di包含r個主題T1,T2,…,Tr,P(Di,Tr)表示API描述信息Di包含主題Tr的概率。如果一個API包含某個主題的概率越大,則該API屬于該主題的可能性就越大。因此,如果一個API包含某個主題的概率最大,認(rèn)為該API就屬于相應(yīng)的主題類簇;在此基礎(chǔ)上,得到聚類后的API類簇集以及每個主題包含的主題特征詞集。
Word2Vec算法是基于詞嵌入的新方法,可以將幾萬個詞特征縮減到幾百甚至幾十維度,可以解決文本分類維度災(zāi)難的問題[12]。由于一部分API的描述信息過短,直接利用LDA主題建模方法難以有效估計出API的隱含主題,而Word2ec能夠?qū)⒁粋€詞轉(zhuǎn)化為一個詞向量,所以該文采用Word2ec進行文本向量化。首先用維基百科的語料庫訓(xùn)練一個詞向量模型,然后用這個詞向量模型對LDA主題特征詞進行向量化,由于Word2Vec模型無法區(qū)分提取出的特征詞的重要程度,故將該特征詞的TF-IDF值作為權(quán)重,與Word2Vec模型相結(jié)合,得到最終的API描述文本向量[13]。
2.2.3 基于Specs和相似度計算的API推薦
(1)識別API所屬類簇。
特定失效API首先通過預(yù)處理,然后將預(yù)處理后的失效API和2.2.2節(jié)API聚類產(chǎn)生的主題特征詞通過Word2Vec進行向量化,進而采用余弦相似度計算失效API與聚類產(chǎn)生的主題類簇間的相似度,計算公式如下:
(1)
其中,sim(D,T)的取值范圍為[0,1]。如果sim(D,T)越大,表示失效API與該主題類簇內(nèi)的API越相似;因此,當(dāng)失效API與特定主題間得到的sim(D,T)最大時,就認(rèn)為給定的失效API屬于該主題類簇。
(2)通過Specs進行篩選。
識別失效API所屬主題類簇后,進一步通過API Specs信息對類簇內(nèi)的API進行篩選,以提高方法的性能。采用的API Specs信息主要包括Authentication Model、SSL Support、Supported Response Formats、Supported Request Formats等。通過Jaccard系數(shù)計算失效API與類簇內(nèi)每個API間Specs信息的相關(guān)度[14],如式(2)所示。
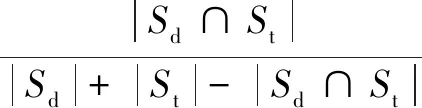
(2)
其中,Sd,St分別表示失效API規(guī)格信息集和主題類簇中相應(yīng)API的規(guī)格信息集,J(Sd,St)屬于[0,1]。當(dāng)J(Sd,St)大于特定閾值時,表示目標(biāo)API規(guī)格信息與主題類簇中API的規(guī)格信息間的相似度越高,從而得到篩選后的類簇中的API集合。
(3)相似度計算。
將篩選后的API集合通過Word2Vec進行向量化,然后采用余弦相似度計算失效API與篩選后的每個API間的描述相似度。
(4)排序。
將步驟3得到的相似度按照從大到小的順序進行排序,取前Top-n個API進行推薦。
算法:基于Specs和相似度計算的API推薦算法。
輸入:失效API的描述文檔Di,失效API的Specs信息Sd,主題特征詞集合T,每個主題類簇下API描述文檔集合Dt,每個主題類簇下API的Specs信息集合St,閾值th。
輸出:Top-n個API列表。
(a)通過Word2Vec將失效API的描述文檔Di和主題特征詞集合T中的詞進行向量化。
(b)根據(jù)式(1)計算失效API的描述Di與主題特征詞間的相似度。
(c)根據(jù)得到的相似度識別失效API所屬的主題類簇。
(d)在識別的主題類簇下,根據(jù)式(2)計算失效API的Specs信息與主題類簇下API的Specs信息間的Jaccard系數(shù)。
(e)遍歷得到的Jaccard系數(shù),統(tǒng)計系數(shù)大于閾值th的API集合Ds。
(f)將Ds中的每個API的描述信息通過Word2Vec進行向量化。
(g)通過余弦相似度計算失效API的描述信息Di與Ds中向量化后的每個API描述間的相似度。
(h)將得到的相似度按照從大到小排序,選擇Top-n個API作為推薦結(jié)果。
3 實驗結(jié)果分析
本節(jié)進行實驗驗證,通過Programmableweb網(wǎng)站上真實的API數(shù)據(jù)進行實驗,以驗證方法的有效性。
3.1 實驗準(zhǔn)備
所有實驗和算法均通過JAVA實現(xiàn),開發(fā)環(huán)境為Eclipse,所有實驗均運行在一臺具有Intel Core i5-8300 CPU,8 GB內(nèi)存,操作系統(tǒng)為Windows10的PC上。
從Programmableweb網(wǎng)站上收集“category”中API數(shù)目大于900的“category”中的API,并從中隨機選取Mapping、Financial、eCommerce、Data、Cloud、Analytics 7個領(lǐng)域包括7 600個API的描述信息以及Specs信息進行實驗。
3.2 評估指標(biāo)
該文采用聚類純度(purity)和F-measure兩個指標(biāo)評估聚類的結(jié)果。聚類純度采用式(3)進行計算,其中k是聚類的數(shù)目,m是整個聚類所涉及到的文本個數(shù),mi表示聚類i中所有成員個數(shù),pi表示聚類i中的成員屬于類的概率。P是精確率,R是召回率,計算公式分別如式(4)、式(5)所示,TP(true positives)表示正類判定為正類,F(xiàn)P(false positives)表示負(fù)類判定為正類,F(xiàn)N(false negatives)表示正類判定為負(fù)類,F(xiàn)-measure通過式(6)進行計算,其中β是參數(shù),一般取值為1。
(3)
(4)
(5)
(6)
采用準(zhǔn)確率和平均絕對誤差評估推薦方法的有效性。準(zhǔn)確率計算公式為式(7),其中Pre表示準(zhǔn)確率,Ni表示匹配成功的API的數(shù)目,Nj表示Top-n個API。平均絕對誤差計算公式如式(8),其中pm表示對Programmableweb網(wǎng)站上原有失效API的相似API的評分,tm表示實驗中不同方法得到的相似API的評分,n表示得到的相似API的個數(shù),評分取值為[0,1]。MAE值越小,表示得到的推薦結(jié)果越準(zhǔn)確。
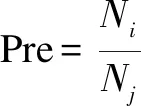
(7)
(8)
3.3 實驗結(jié)果
3.3.1 聚類結(jié)果分析
實驗中先確定LDA中主題個數(shù)k的不同取值對服務(wù)聚類效果的影響。為了客觀體現(xiàn)k的取值對聚類的影響,選取不同的k值進行實驗,然后對聚類結(jié)果取平均值。結(jié)果如表1所示。
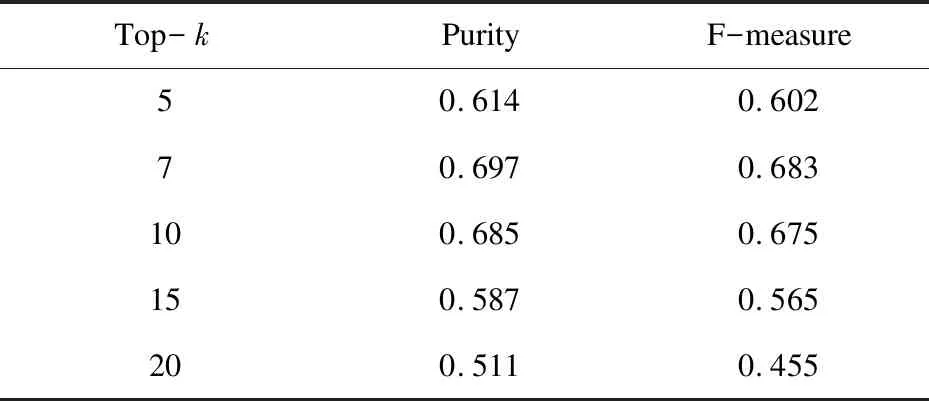
表1 k的取值對聚類效果的影響
實驗表明,當(dāng)主題個數(shù)為5,7,10的時候,聚類的實驗效果比主題個數(shù)為15,20時更好,可能是采取的實驗數(shù)據(jù)較小的原因,而當(dāng)主題數(shù)為7時的聚類效果最好,因為實驗數(shù)據(jù)是隨機選擇的7個領(lǐng)域的API數(shù)據(jù)的集合,所以主題數(shù)為7時效果最好。
聚類結(jié)果的好壞對推薦結(jié)果的準(zhǔn)確性會產(chǎn)生一定影響,因此,設(shè)計表2中的4種方法進行實驗,以驗證文中聚類方法的有效性。

表2 四種方法的描述
四種方法得到的聚類結(jié)果如圖2所示。
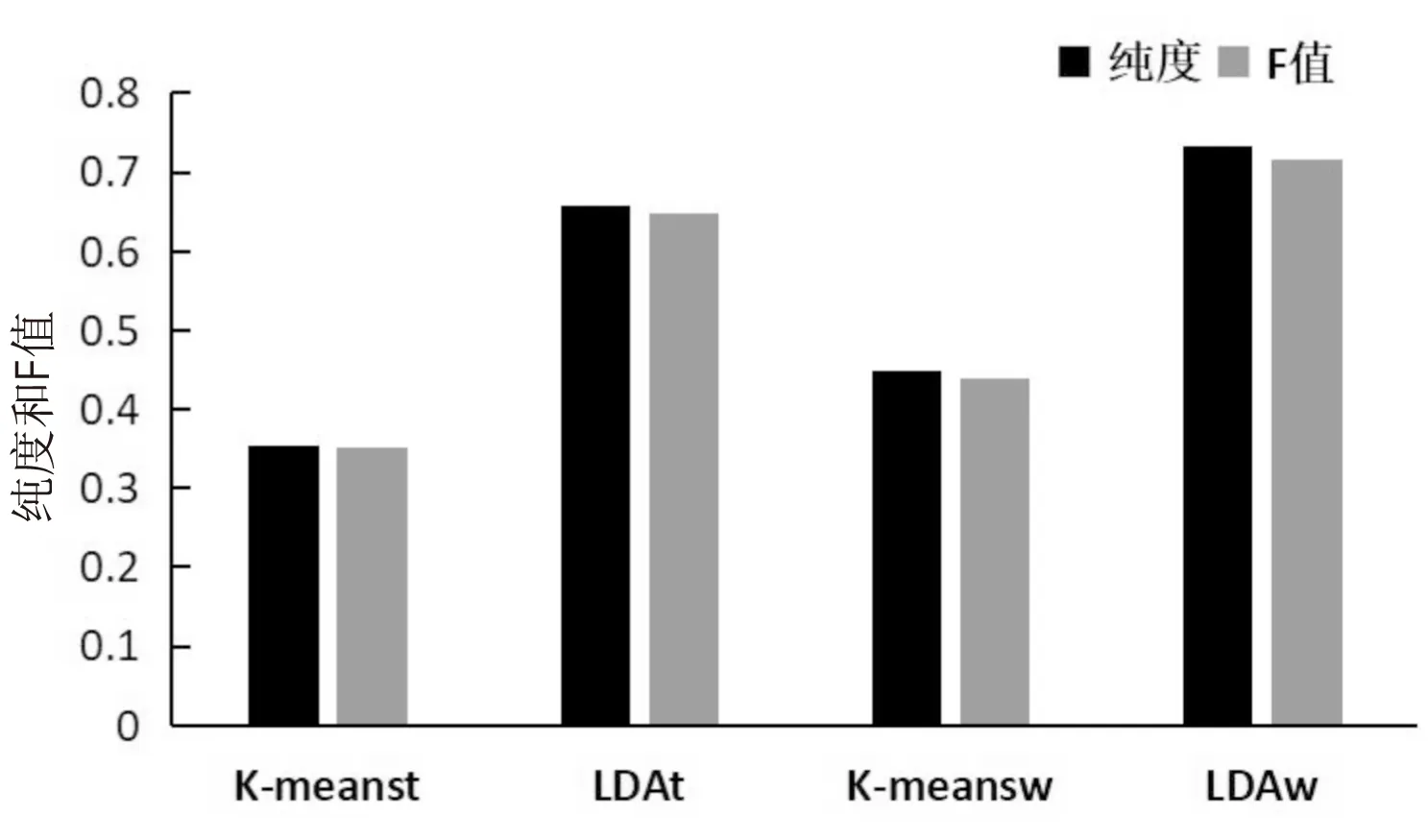
圖2 四種方法的純度和F-measure對比
從圖2中可以看出,通過基于Word2Vec和LDA主題模型的聚類方法LDAw得到的聚類效果更好。K-meanst算法聚類效果最差的原因可能是使用K-means算法有初始聚類中心選擇的任意性,使得每個類簇所包括的API信息相差較大,從而導(dǎo)致純度較低。
3.3.2 推薦結(jié)果分析
以“Google Cloud Inference API”為失效API,通過相似度計算識別出該API屬于Analytics主題類簇,進一步計算該API的Specs信息與Analytics主題類簇下每個API Specs信息間的Jaccard系數(shù),將閾值th設(shè)置為0.5,得到篩選后的658個API,進而計算該失效API與658個API間的相似度。表3為相似度top-10的API及相應(yīng)的相似度。
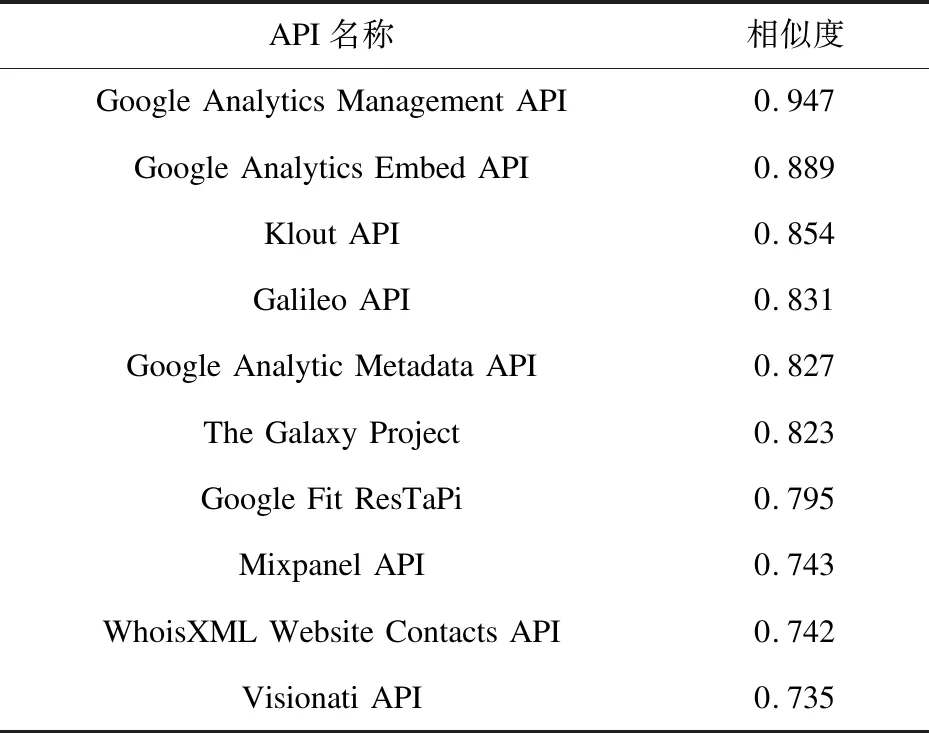
表3 top-10 API及相似度
為了體現(xiàn)文中推薦方法的有效性,設(shè)計表4所示的對比方法進行實驗驗證。
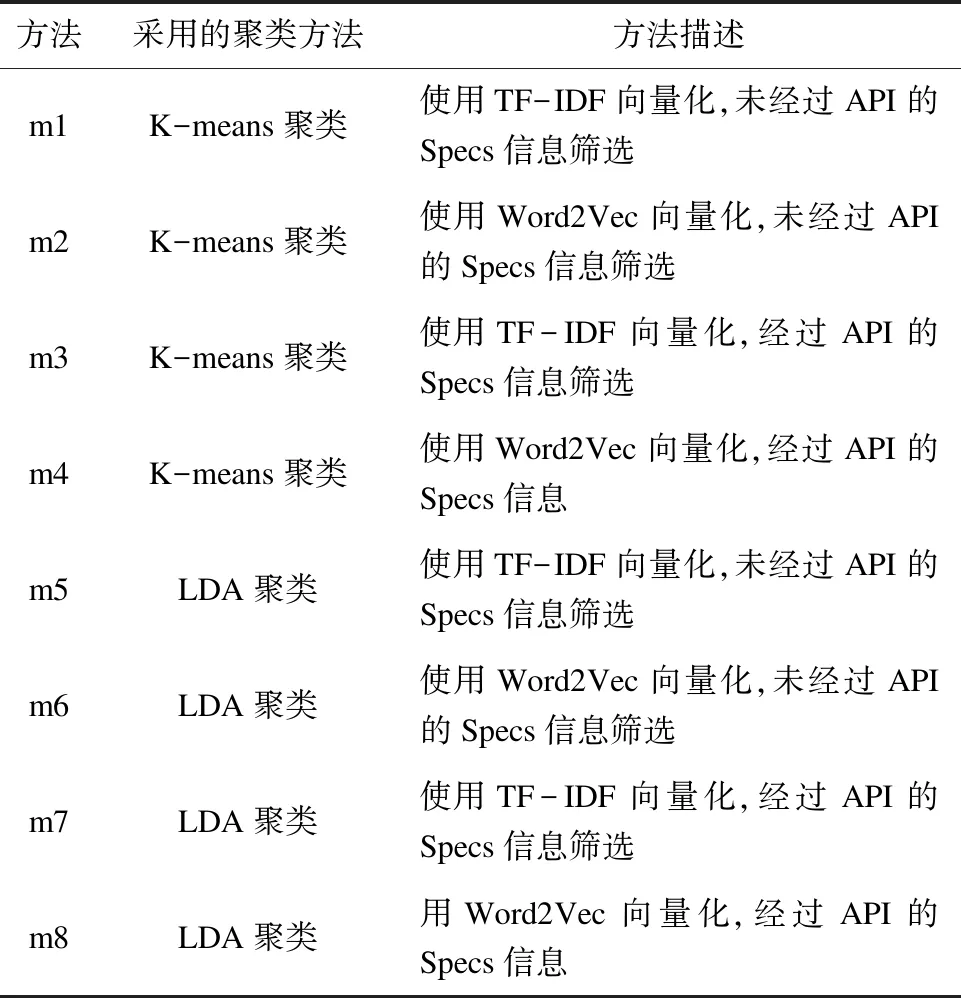
表4 八種方法的描述
表4中的8種方法得到的實驗結(jié)果分別如圖3、圖4所示。
從圖3、圖4中可以看出,m1,m3,m5,m7中采用了TF-IDF進行向量化,可能引起向量維度爆炸的問題且沒有考慮到語義相關(guān)性,沒有取得良好的推薦效果;m2,m4,m6,m8中采用了Word2Vec進行向量化[15],取得了較好的實驗結(jié)果,表明考慮API的Specs信息一定程度上可以提高推薦的準(zhǔn)確率,驗證了所提推薦方法的有效性。
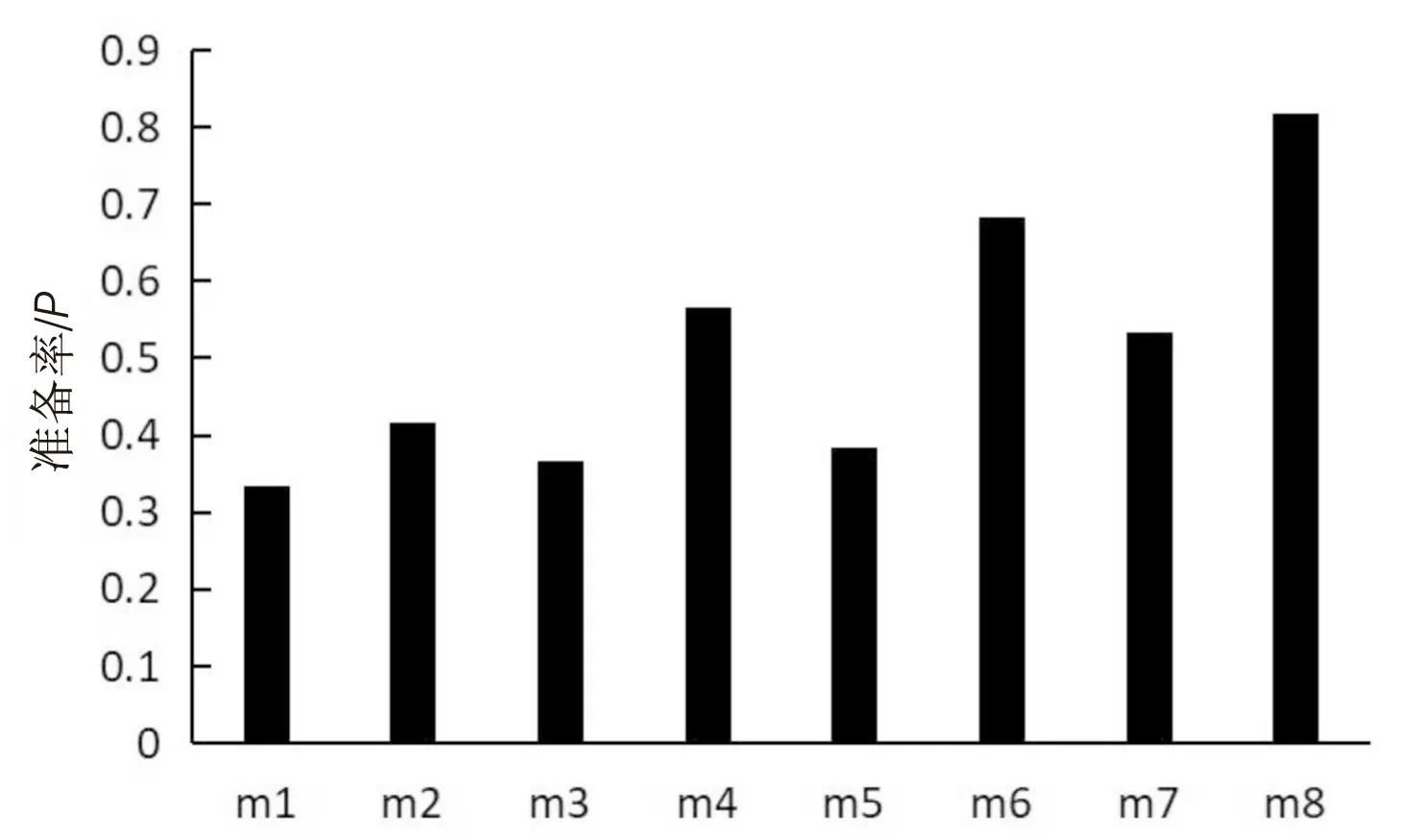
圖3 八種方法的準(zhǔn)確率對比
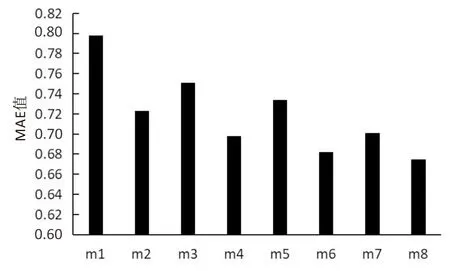
圖4 八種方法的平均絕對誤差對比
4 結(jié)束語
該文提出了一種面向Mashup應(yīng)用的API推薦方法,首先通過LDA主題模型對API描述進行聚類[16],然后通過失效API與類簇間的相似度計算,識別失效API所屬的主題類簇,并根據(jù)API的規(guī)格信息對識別類簇內(nèi)的API進行篩選,進一步計算失效API與篩選后的API間的相似度,將相似度較高的Top-n個API進行推薦。通過對真實服務(wù)集進行實驗表明,該方法推薦準(zhǔn)確率較高,驗證了該方法的可行性和有效性。
在未來工作中,還需要改進的地方如下:
(1)考慮到Programmableweb網(wǎng)站上API有標(biāo)簽[17]的存在,該文沒有考慮標(biāo)簽的因素,可能會造成一定誤差,下一步可以考慮加入Programmableweb網(wǎng)站上的標(biāo)簽信息。
(2)目前推薦的API僅來源于一個服務(wù)類簇,下一步可考慮主題類簇間的相關(guān)性,擴大推薦范圍,以更好地提高方法的性能。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
今日農(nóng)業(yè)(2019年12期)2019-08-15 00:56:32
今日農(nóng)業(yè)(2019年10期)2019-01-04 04:28:15
今日農(nóng)業(yè)(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
中華手工(2017年2期)2017-06-06 23:00:31
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
