基于注意力與圖卷積網絡的關系抽取模型
2021-03-07 05:16:04王曉霞錢雪忠
計算機應用 2021年2期
王曉霞,錢雪忠,宋 威
(江南大學人工智能與計算機學院,江蘇無錫 214122)
(*通信作者電子郵箱17854265793@163.com)
0 引言
關系抽取(Relation Extraction,RE)是自然語言處理領域的一項重要子任務,是對非結構化文本進行大規模關系理解應用的基石,它在信息抽取、問答系統和知識圖譜等領域有著廣泛的應用[1]。關系抽取是根據預先定義的關系類型來識別文本中標記實體對之間的語義關系。例如,“The train <e1>crash</e1>was caused by terrorist <e2>attack</e2>.”,根據給定的句子以及標記的實體對判定“crash”與“attack”之間的關系為Cause-Effect(e1,e2)。
現有的關系抽取模型可以大致分為兩類:基于序列的模型和基于依賴關系的模型。基于序列的模型只對單詞序列進行編碼,使用卷積神經網絡(Convolutional Neural Network,CNN)或循環神經網絡(Recurrent Neural Network,RNN)將句子序列編碼為語境化的潛在特征;基于依賴關系的模型則將輸入語句的依存樹納入模型中,通過沿著依存樹形成的計算圖來構建句子的分布式表示。與基于序列的模型相比,基于依賴關系的模型能夠捕獲單獨從詞嵌入序列中無法學習到的長期句法關系。但是,依存樹中并不是所有信息都對關系抽取任務有用,為了能夠排除依存樹中的干擾信息,現有方法通過對依存樹進行剪枝操作,選取依存樹中的部分結構進行編碼以獲取句子的語義特征。這種基于硬剪枝的策略過于激進地修剪依存樹而忽略了相關信息,降低了依存樹中的信息利用率。其次,現有模型中的特征提取器效果不佳,無法同時提取依存樹中的局部與非局部依賴特征,從而不能有效學習到句子的高階語義特征。針對以上問題,本文所提出的基于注意力與圖卷積網絡(Graph Convolutional Network,GCN)的關系抽取模型能夠利用基于注意力機制的軟剪枝策略來挖掘依存樹中的有效信息,同時過濾無用信息;其次,通過門控感知圖卷積網絡作為特征提取器,能有效提取依存樹中的局部與非局部依賴特征,獲取句子中的高階語義特征。
1 相關工作
傳統的關系抽取主要是基于特征[2]或基于核函數[3]構造分類模型,這種方法確實可行且有效,但依賴于選擇的特征集或設計的核函數,容易引入人為誤差,很大程度上限制了關系抽取模型的性能。
目前,基于深度學習的方法被廣泛用于關系抽取任務中。文獻[4]和文獻[5]分別利用CNN 和RNN 提取句子序列特征,并通過Softmax 分類器實現關系分類;針對數據不平衡帶來的噪聲問題,文獻[6]提出了一種排序損失函數來替代交叉熵,對other 類進行特殊處理從而減少噪聲的影響;文獻[7]則將注意力機制引入關系抽取模型中,通過注意力機制重點關注句子中的有效信息,從而提高模型的性能;考慮到句子的局部特征和上下文特征對關系抽取任務具有一定貢獻,文獻[8]和文獻[9]利用聯合神經網絡的方法,將RNN 與CNN 結合來共同獲取句子的局部特征和上下文特征,進而改善模型關系抽取性能。上述工作中的模型,直接將原始語句作為輸入構建端到端的模型,取得了不錯的效果。
此外,研究者為充分挖掘句子中的深層語義信息,將句子的依存關系樹導入模型中,構建基于依賴關系的模型。為充分利用依存樹中的有效信息,排除干擾特征,研究者提出了多種剪枝策略來選取依存樹中的有利信息。文獻[10]通過剪枝選取實體之間的最短依賴路徑(Shortest Dependency Path,SDP),應用于長短期記憶(Long Short-Term Memory,LSTM)網絡,推廣了基于依賴關系的思想;文獻[11]在循環卷積神經網絡(Recurrent Convolutional Neural Network,RCNN)模型中加入基于最短依賴路徑的注意力機制來強化關鍵詞和句子特征;文獻[12]則應用剪枝策略將整棵樹縮減為實體最低公共祖先(Lowest Common Ancestor,LCA)下的子樹,并通過雙向樹狀結構的LSTM-RNN 捕獲子樹中的結構信息;文獻[13]在LCA 規則的基礎上提出改進,保留實體對的LCA 子樹上K距離內的節點,并引入圖卷積網絡進行關系抽取。以上研究表明依存樹中含有豐富的對關系抽取任務有利的信息,對于提高關系抽取模型的性能有一定作用;但基于規則的硬剪枝策略容易導致過剪枝或欠剪枝,從而降低依存樹中信息的利用率,并且大多數模型選取CNN 或RNN 作為特征提取器,無法充分學習到依存關系樹中的非局部依賴特征。
本文針對上述問題,提出一種基于注意力引導的門控感知圖卷積網絡(Attention-guided Gate preceptual Graph Convolutional Network,Att-Gate-GCN)關系抽取模型。首先,為了緩解硬剪枝策略帶來的信息丟失問題,利用一種基于注意力機制的軟剪枝策略,將原始依存樹轉化為一個完全連通的邊加權圖,每條邊的權重視為節點之間關系的強度,并通過自注意力機制[14]以端到端的方式學習。其次,為了更好地編碼上述得到的加權完全連通圖,本文在C-GCN(Contextualized Graph Convolutional Network)模型[13]的基礎上提出一種改進的門控感知圖卷積網絡結構用于提取句子的高階語義特征。C-GCN模型使用高效的圖卷積運算[15]對輸入語句的依賴圖進行編碼,但由于簡單的圖卷積網絡無法深度訓練[16],導致該模型中的圖卷積網絡結構不能有效提取依存樹中的非局部依賴特征。本文提出的門控感知圖卷積網絡結構則通過門控機制增加特征感知能力,能夠實現對模型的深度訓練,從而捕獲句子中豐富的局部與非局部依賴特征。本文將提出的模型在SemEval2010-Task8 和KBP37 數據集上進行實驗,取得了比現有模型更好的效果;為驗證本文所提出的基于注意力機制的軟剪枝策略與門控感知圖卷積網絡結構的有效性,還進行了消融實驗。
2 模型描述及實現
本章主要介紹基于注意力引導的門控感知圖卷積網絡(Att-Gate-GCN)關系抽取模型,該模型框架如圖1所示。
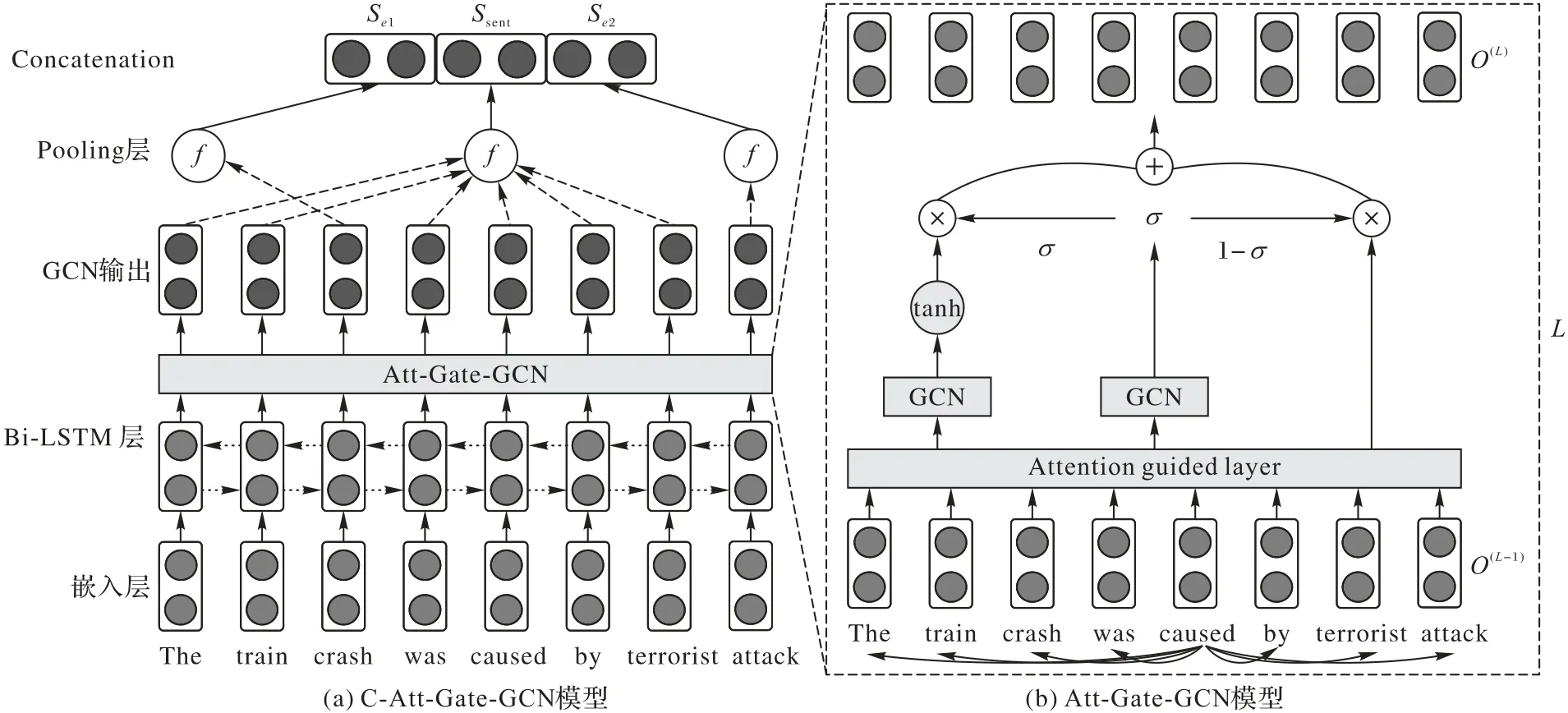
圖1 Att-Gate-GCN關系抽取模型框架Fig.1 Architecture of Att-Gate-GCN relation extraction model
在已有工作中,研究者證明了基于依賴關系的模型與基于序列的模型具有互補的優勢,因此本文參考C-GCN 模型,如圖1 中的(a)所示,在模型中添加雙向長短期記憶(Bidirectional Long Short-Term Memory,Bi-LSTM)網絡層,將詞嵌入向量首先輸入到Bi-LSTM 中,生成上下文化的詞嵌入表示,然后通過本文所提出的Att-Gate-GCN 進一步學習句子的高階語義特征。如圖1 中的(b)所示,首先通過注意力引導層學習依存樹中所有節點之間的權重信息,從而提高依存關系樹中有效信息的利用率;然后通過門控感知圖卷積網絡結構進一步提取句子的深層語義特征。
2.1 詞嵌入層
本文使用斯坦福大學開發的Stanford Parser 對句子進行依存分析,生成句子的依存樹。依存樹中的所有節點對應句子中的所有單詞,節點之間的關系通過鄰接矩陣表示。將句子通過詞嵌入層得到單詞的分布式表示,即單詞ci的詞向量wi由單詞ci的one-hot向量vi與預訓練的詞向量矩陣W相乘得到,如式(1)。

此外,考慮到句子中的實體位置能夠反映句子中各單詞與實體對之間的位置信息,引入Zeng等[4]提出的位置特征,通過隨機初始化位置嵌入矩陣得到位置嵌入表示,單詞ci相對于實體對的位置嵌入向量為。因此,單詞ci的詞向量最終表示為
2.2 Bi-LSTM層
將詞嵌入層得到的詞向量輸入到Bi-LSTM 層,通過兩層LSTM分別沿句子前向序列和反向序列進行編碼,生成上下文化的詞向量。LSTM在克服長期依賴性問題中,采用自適應門控機制,利用存儲單元記憶相關信息,遺忘無關內容,緩解了梯度消失與爆炸問題。LSTM 的隱藏層主要包含三個門控機制:輸入門it、遺忘門ft和輸出門ot(t表示時刻)。式(2)~(7)顯示了LSTM隱藏層的計算。
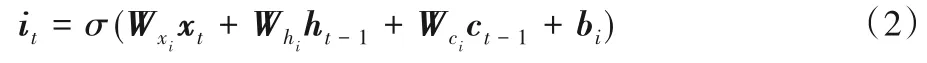
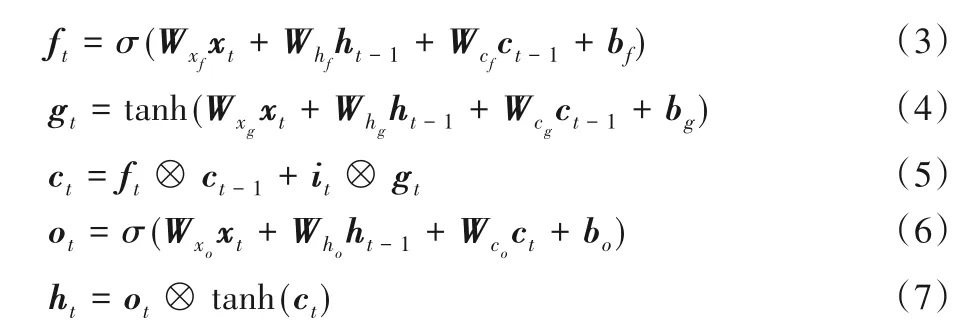
其中:σ代表sigmoid 激活函數;?代表向量元素相乘;xt表示時間t時刻的輸入向量;ht表示隱藏狀態;表示xt分別在不同門機制上的權重矩陣;表示ht分別在不同門機制上的權重矩陣;b代表偏差量。
在t時刻,Bi-LSTM 的前向輸出為,反向輸出為,將兩個方向的輸出拼接得到最終t時刻的輸出ht,如式(8)所示。

2.3 注意力引導層
依存樹中蘊含句子豐富的句法信息,對關系抽取任務有很大的價值。大多數基于依賴關系的模型并不利用完整的依存樹提取句子特征,而是應用硬性剪枝的策略直接將整棵樹剪枝成子樹。基于規則的硬剪枝策略會導致關鍵信息的丟失和性能下降,因此本文應用一種基于注意力機制的軟剪枝策略[17],為依存樹中所有的邊分配權重,這些權重可以通過自注意力機制以端到端的方式學習。通過構造一個注意力引導的鄰接矩陣,將原始依存樹轉化為一個完全連通的邊加權圖,每一個對應于一個完全連通的圖,其中表示節點i到節點j的邊的權重。如圖2所示,表示一個完全連通的邊加權連通圖G(1)。是由句子依存樹的鄰接矩陣通過自注意力(Selfattention)機制構建得到。Self-attention 是一種捕捉單個序列中兩個任意位置之間相互作用的注意力機制,首先利用線性函數將原始鄰接矩陣投影到兩個相似序列中,然后利用點乘得到每個節點與其他節點之間的相關性權重,得到之后,將其作為門控感知圖卷積網絡層計算的輸入。的大小與原始鄰接矩陣A相同,因此,不涉及額外的計算開銷。
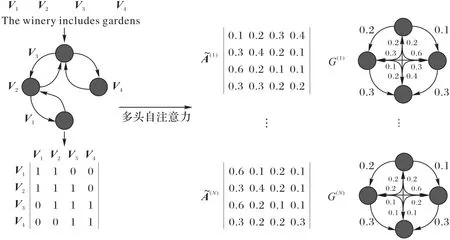
圖2 注意力引導層Fig.2 Attention guided layer
注意力引導層的核心思想是利用注意力機制來學習節點之間的關系,并賦予合適的權重,從而聚合依存樹中的有效信息。為了從多個方面捕捉不同的關系特征,如圖2 所示,采用Multi-head機制[18],使用單獨的規范化參數在相同的輸入上多次應用Self-attention,并將結果合并起來作為注意力引導層的輸出,這使得模型能夠共同關注來自N個不同表示子空間的信息。Self-attention計算如式(9)。
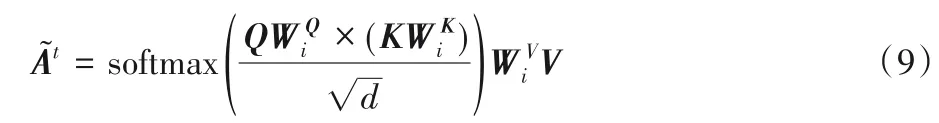
其中:Q、K和V均代表Gate-GCN 模型中第L-1 層的輸出表示是參數矩陣表示通過第t個頭注意力得到的鄰接矩陣。
2.4 門控感知圖卷積網絡層
為了更好地捕捉句子依存樹中的深層次語義依賴特征,本文提出一種門控感知圖卷積網絡結構,旨在通過門控機制同時捕獲局部與非局部依賴特征。本節首先介紹基本的圖卷積網絡以及引入注意力引導層后得到的新的圖卷積運算,然后詳細描述了門控感知圖卷積網絡結構。
圖卷積網絡[15]是卷積神經網絡的一種改編,用于編碼圖形結構。給定有n個節點的圖,可以得到一個n×n的鄰接矩陣A用以表示圖的結構信息。文獻[19]通過將邊的方向性引入模型來擴展GCN 編碼依存樹,例如,如果存在一條邊從節點i到節點j,則Aij=1,并且為樹中的每個節點添加一個自循環,即Aii=1。在L層GCN 中,如果用表示節點i輸入特征表示節點i的輸出特征,圖卷積網絡的計算如式(10)。
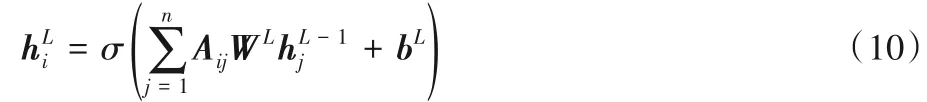
其中:WL是線性變換,bL是偏差項,σ代表一種非線性函數(如ReLU)。在此基礎上,本文通過應用注意力引導層,得到改進的鄰接矩陣,以此調整圖卷積運算建模依存關系樹。因此,基于注意力引導的圖卷積運算如式(11)。
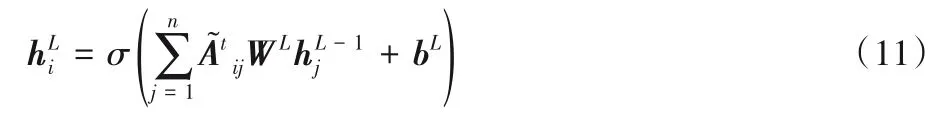
將這個運算疊加在L層的門控感知圖卷積網絡中,L為超參數。在第一層的計算中是由Bi-LSTM 層輸出得到的上下文的詞嵌入表示,在后續L-1 層中,將上一層的輸出作為下一層的輸入進行計算。
淺層的圖卷積網絡無法編碼依存樹中的長距離依賴特征,針對此問題,本文通過門控感知結構作用于圖卷積網絡,以實現模型的深度訓練,從而捕獲依存樹中的非局部相互作用。將門控感知結構加入到基于注意力引導的圖卷積網絡中,構成Att-Gate-GCN,其中門控感知圖卷積網絡(Gate-GCN)的每一層都包含兩個相同的圖卷積結構,分別記為GCN1和GCN2。因此,Gate-GCN 在第L-1 層的計算如式(12)、(13)所示。
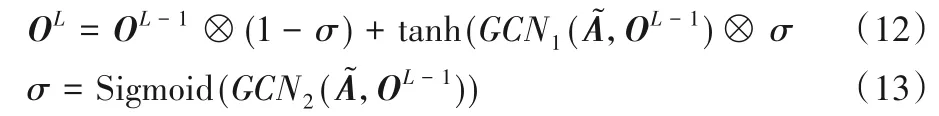
2.5 關系抽取
通過門控感知圖卷積網絡對依存樹進行編碼,得到句子中所有單詞的隱藏表示Osent。在此基礎上,采用與文獻[20]相同的處理方法,將句子表示Ssent與實體表示Sei拼接,并通過前饋神經網絡(Feed-Forward Neural Network,FFNN)得到最終的句子表示,如式(14)~(16)。
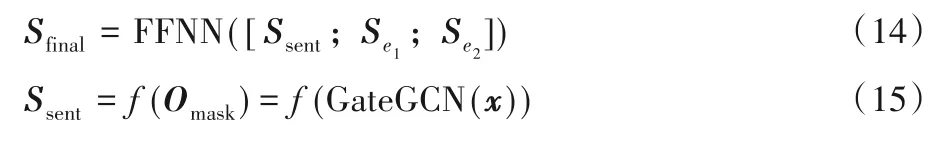

其中:Omask代表Osent中除實體對之外的隱藏表示則代表實體對的隱藏表示,f為最大池化函數。然后使用Softmax 分類器從關系集合Y中預測句子x的類別標簽。計算過程如式(17)、(18)。
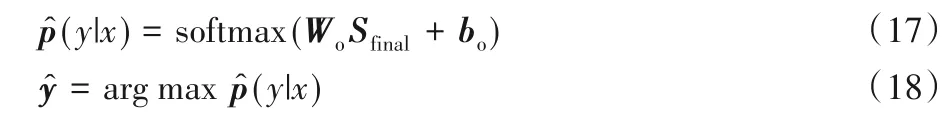
本文利用帶L2正則項的負對數似然函數作為代價函數,如式(19)所示。
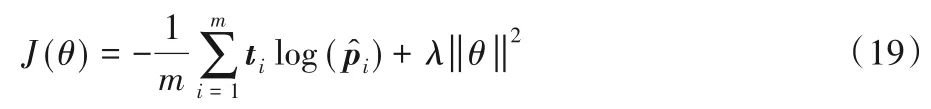
其中:m代表樣本的個數,t是關系類別的one-hot 向量是Softmax 的輸出類別概率向量,λ是正則化參數,θ是關系抽取模型的訓練參數。模型的算法流程如下:
算法1 模型算法流程。

3 實驗與結果分析
3.1 實驗數據與評估指標
本文在兩個標準關系抽取數據集上進行實驗,分別為:
1)SemEval2010-Task8 數據集。該數據集包含10 717 個句子實例,其包括8 000個訓練實例和2 717個測試實例,關系類型包括9類關系和1個other類,關系類別及數據分布如表1所示。
2)KBP37 數據集。該數據集使用了2013 年和2010 年的KBP文檔數據集,以及對2013年Wikipedia進行注釋的文本數據集,包括訓練實例15 917 個,測試實例3 405 個,包含19 種不同的關系,其中丟棄了低頻關系,每種關系的訓練實例超過100條。
在兩個數據集上本文均采用官方評價指標宏觀平均(Macro)F1值評估模型。Macro首先對每一個類計算F1值,然后對所有類求算數平均值。表2 為關系分類結果的混淆矩陣。
在計算F1 指標值之前,根據混淆矩陣求得查準率P和查全率R,計算如式(20)、(21)所示。
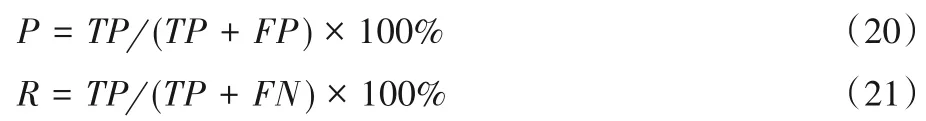
F1值定義為查準率和查全率的調和平均數,如式(22)。
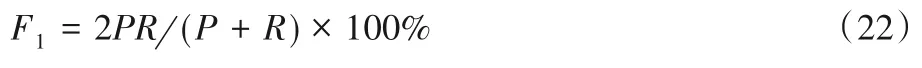

表1 SemEval2010-Task8數據集關系類型及語料分布Tab.1 SemEval2010-Task8 dataset relation types and corpus distribution

表2 分類結果混淆矩陣Tab.2 Confusion matrix of classification results
3.2 參數設置
為盡量公平地與基線模型進行對比實驗,本文采用文獻[13]實驗的大部分參數,與文獻[20]使用相同的預訓練的詞向量,在此基礎上通過交叉驗證的方法對訓練集上參數進行調優,獲得最終的模型參數,并應用于測試集,具體實驗參數如表3所示。
表3 實驗參數Tab.3 Experimental parameters
為緩解過擬合,分別在嵌入層、Bi-LSTM 層和Gate-GCN層引入Dropout 策略,丟碼率分別設置為0.5、0.5 和0.3。在兩個數據集中,以上參數設置相同。在注意力層,多頭機制中N的大小對于最終結果有明顯的影響,在SemEval2010-Task8數據集上,從N={1,2,3,4,5}中選擇效果最好的為N=3,N對F1 指標的影響如圖3 所示。在KBP37 數據集中,N為4 時效果最佳。
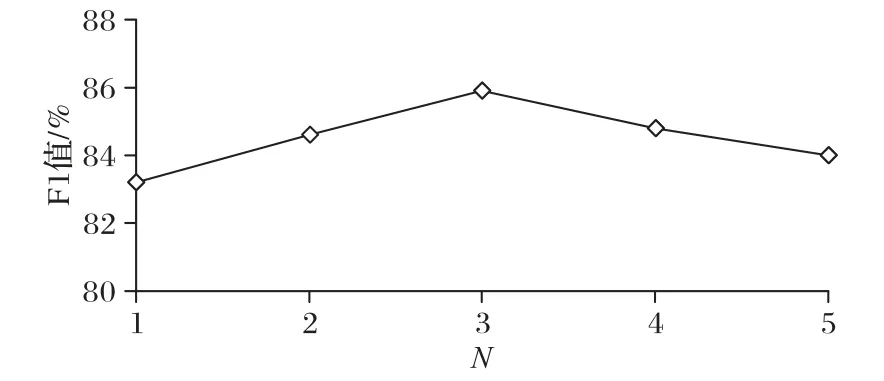
圖3 SemEval2010-Task8數據集上N對F1值的影響Fig.3 Influence of N on F1 value on SemEval2010-Task8 dataset
3.3 實驗結果分析
本文的實驗以C-GCN 為基線模型(Baseline),在SemEval2010-Task8 數據集和KBP37 數據集上復現的該模型F1值分別為83.7%和58.9%。
3.3.1 消融實驗與分析
為驗證本文所提出的基于注意力機制的軟剪枝策略與門控感知圖卷積網絡結構在關系抽取任務中的有效性,在兩個數據集上分別進行以下消融實驗:1)使用注意力引導層替換基線模型中的硬剪枝策略;2)在基線模型的圖卷積網絡層中添加門控感知結構,用以實現深層圖卷積網絡結構。實驗結果如表4所示。
從表4 實驗結果可以看出,在基線模型中添加注意力引導層,SemEval2010-Task8 數據集和KBP37 數據集上的F1 值分別提高了1.2個百分點和1.8個百分點。其原因在于,基于規則的硬剪枝技術在過濾無關信息的同時也將有利信息排除在外,而基于注意力機制的軟剪枝策略通過對完全依存樹中的信息進行加權,能夠充分利用依存樹中的有效特征,緩解了硬剪枝策略導致的過剪枝或欠剪枝的問題。對比表3中的F1值觀察到,注意力引導層在KBP37 數據集上性能提升更為明顯,F1 值提高了1.8 個百分點。原因在于KBP37 數據集中包含更多的長句子,而基于注意力機制的軟剪枝策略通過分析權重能夠有效識別長句子中的相關信息,從而在處理長句子時具有更明顯的優勢。此外,使用Gate-GCN 替換基線模型中的GCN 取得了更明顯的優勢,說明通過門控感知結構構成的深層圖卷積網絡能夠在提取局部依賴特征的同時,實現長距離依賴特征的學習,從而獲得更準確的句子表示,有效緩解了圖卷積網絡無法深度訓練的問題。
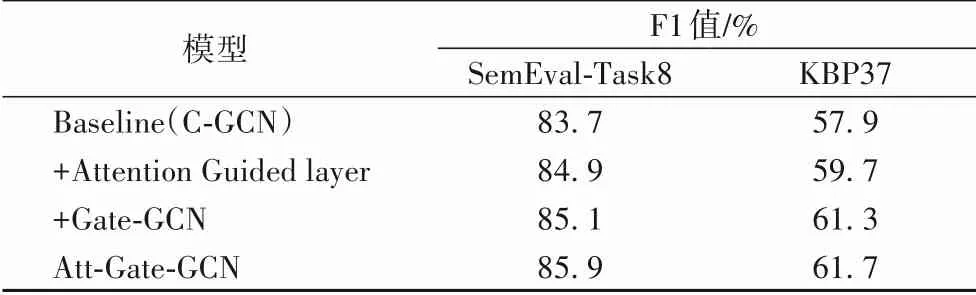
表4 基線模型上的消融實驗結果Tab.4 Results of ablation experiments on baseline model
綜合以上兩組實驗結果,本文組合利用注意力引導層和門控感知圖卷積網絡結構,在兩個基準數據集上進行實驗,并分別在SemEval-Task8 數據集和KBP37 數據集上詳細比較了基線模型與本文模型在每個類別下的評價指標,實驗結果如表5、6所示。
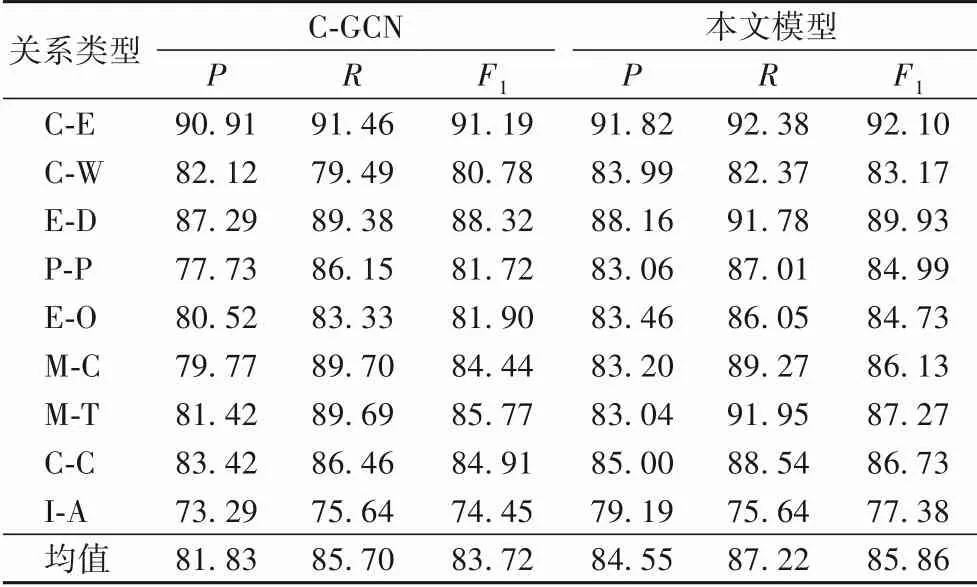
表5 C-GCN和本文模型在SemEval2010-Task8數據集不同類別下的結果對比 單位:%Tab.5 Comparison of results under different categories of G-GCN and the proposed model on SemEval2010-Task8 dataset unit:%

表6 C-GCN和本文模型在KBP37數據集不同類別下的結果對比 單位:%Tab.6 Comparison of results under different categories of G-GCN and the proposed model on KBP37 dataset unit:%
從表5、6 中可以看出,本文模型在SemEval-Task8 數據集和KBP37 數據集上相較基線模型在所有關系類別上均有一定的性能優勢,并且在KBP37 數據集上提升更加明顯。其中,多個關系類別的召回率有明顯提升,說明由基線模型預測的這些類別中存在被誤判為other 類的關系,而本文模型在改進的基礎上將其識別為了正確類別。并且觀察發現,本文模型在長句子預測的性能顯著優于基線模型,如例1 中的關系實例,基線模型將其判定為other 類別,而本文模型正確標識為Message-Topic類。
例1:The play reflects,among other things,questions about the nature of political power and the dilemmas facing royal families.
譯:該劇除其他外,反映了有關政治權力的性質和王室面臨的困境的問題。
實體1:play
實體2:question
關系:Message-Topic(e1,e2)
3.3.2 對比實驗與分析
最后選取當前主流的關系抽取模型與本文提出的Att-Gate-GCN模型在兩個數據集上進行對比,包括:
1)CNN+PF(CNN Position Feature)[4]:模型為基本的CNN,引入實體位置特征。
2)RNN+PF[5]:將CNN+PF中的CNN替換為基本的RNN。
3)Att-Bi-LSTM(Attention Bi-LSTM)[20]:利用注意力機制作用于LSTM輸出層捕獲句子中重要的語義特征。
4)SDP-LSTM[10]:通過剪枝策略,選取依存樹中的最短依賴路徑作為輸入,利用LSTM提取異構信息。
5)SPTree(Shortest Path Tree)[12]:應用剪枝策略,將整棵樹縮減為實體最低公共祖先下的子樹,并利用雙向樹狀結構的LSTM捕獲句子高階特征。
6)SA-Bi-LSTM-LET[21]:將實體感知注意力機制與潛在實體類型相結合,充分利用實體信息進行關系抽取。
7)BG-SAC[22]:將雙向門控循環單元(Bi-directional Gated Recurrent Unit,BGRU)與自注意力機制相結合提取基于上下文的語義信息,并利用膠囊網絡獲取實體潛在特征。
從表7 中可以看出,本文模型的F1 值均高于對比模型。本文模型與基于序列的模型相比,在輸入層進一步引入了依存樹包含的句法方面的信息,能充分學習到關系的有效特征,對于理解句子結構以及句子語義信息有明顯的效果;與基于依賴關系的模型相比,本文采用基于注意力的軟剪枝策略,相比SDP 或LCA 等硬剪枝策略,其能更好地利用依存樹中的有效特征,同時過濾無關特征;此外,相比LSTM、GRU 和原始的圖卷積運算,帶有門控機制的圖卷積網絡在提取句子特征方面表現更優,從而進一步提高了關系抽取任務的性能。
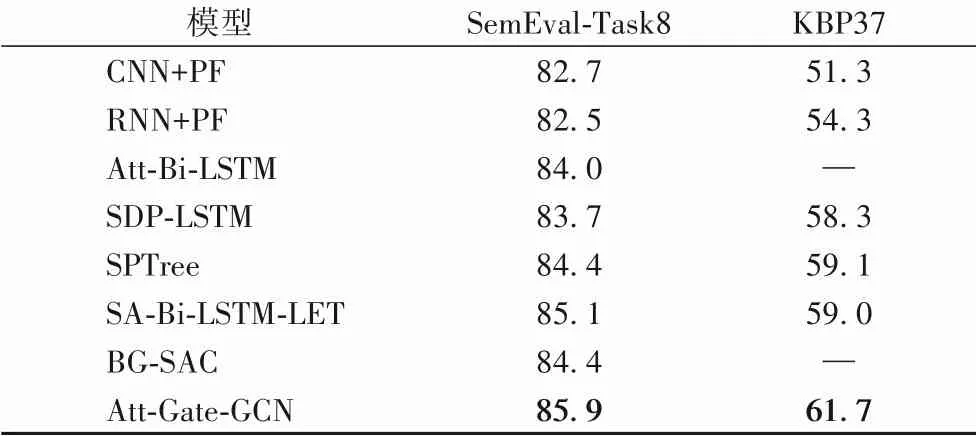
表7 不同模型的F1值對比 單位:%Tab.7 Comparison of F1 values of different models unit:%
4 結語
本文在關系抽取任務中,針對句子依存樹中的信息利用率低和特征提取器不佳的問題,提出了一種基于注意力引導的門控感知圖卷積網絡模型。其中,注意力引導層為完全依存樹賦予權重,從而聚合依存樹中的有效信息,過濾無關信息,為后續特征提取器提供更有效的輸入特征,提高了依存樹中的信息利用率;門控感知結構緩解了圖卷積網絡無法深層提取特征的問題,能夠實現利用深層圖卷積網絡提取長距離依賴特征,從而可以有效結合句子中的局部與非局部依賴特征,得到更準確的句子表示。本文將兩者分層組合共同完成關系抽取任務,實驗表明該模型能夠有效提升關系抽取的效果。本文模型的實驗是在英文數據集上進行的,之后的工作中,將進一步將模型擴展到中文語料數據集。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
