基于動態記憶網絡的序列推薦模型
2021-03-07 12:58:50朱馨培
現代計算機 2021年1期
朱馨培
(哈爾濱陸軍預備役炮兵旅,哈爾濱150000)
0 引言
在推薦系統的發展歷史中,用戶的喜好在很長一段時間內都被看是靜態不變的。由此對用戶做出的推薦在層次上都會缺乏多樣性,即便能夠用神經網絡擬合更好的特征,也很難發現用戶的變化的潛在興趣。另一個更為合理的假設是用戶的興趣是由用戶的長期靜態喜好和短期動態興趣組成。用戶的長期喜好受自身成長因素、性格特征等因素的影響,這部分喜好可看作是靜止不變的。用戶的短期動態興趣隨時間而動態變化,受當前環境和用戶好友等周邊因素影響較大。要對用戶的短期動態喜好建模,需要將其與系統交互歷史中的時間作為特征考慮進數據集中,這就是序列化推薦模型。本文提出了基于動態記憶網絡的序列推薦模型,首先介紹序列推薦模型的范式,然后再對提出的模型結構進行詳細的介紹。
1 序列推薦模型的范式
形式上,序列化推薦模型的任務是通過給定用戶的歷史行為序列對未來行為進行預測的推薦模型。假設有一組用戶表示為用戶u的按時間順序排列的歷史行為(點擊或是購買)序列表示為是用戶u購買或點擊的第i個物品,然后模型在物品的全集I上預測物品的得分。用來表示用戶在所有物品上的得分,其中表示用戶在物品j上的預測分數或喜好程度。最后,模型在y中選擇得分最高的k個物品作為推薦。
2 序列推薦模型框架
在序列推薦中,我們從兩個角度對用戶進行表示,得到用戶的兩種表示方法。其中一種方法學習用戶的長期靜態偏好,另一種方法提取用戶的短期動態興趣。在實際場景中,可以認為用戶的靜態偏好是緩慢變化或基本不變的,而用戶的短期動態興趣則會根據所處情境或上下文而變化。因此,本文基于用戶的靜態偏好和動態興趣生成用戶的全面表示,并提出基于門控機制和動態記憶網絡的個性化序列推薦模型,模型的整體框架如圖1。
從圖1中可以看到,模型一共由4個獨立的部分組成,包括處理用戶輸入序列的輸入模塊、編碼用戶長期靜態喜好的用戶模塊、生成和更新用戶記憶的記憶模塊以及最后的結果輸出模塊。輸入模塊從輸入的序列中檢索出用戶的動態興趣,并保存每一時刻的狀態信息。用戶模塊負責學習用戶的靜態喜好,該模塊使用兩種不同的方式對用戶的靜態偏好進行編碼。然后,記憶模塊在用戶靜態偏好的啟發下,選擇在存儲的記憶中更新哪部分的信息。記憶模塊的主要結構類似于。本文與這兩篇論文不同在于,記憶模塊中嵌入門控結構,該結構借鑒了高速網絡(Highway Network)中的工作。所以,本文采用了一種比RNN更能有效記憶過去事實信息的方式來捕捉用戶的動態喜好,并且將其和所得到的用戶靜態表示相結合,通過計算在所有物品上的偏好程度來對用戶進行推薦。
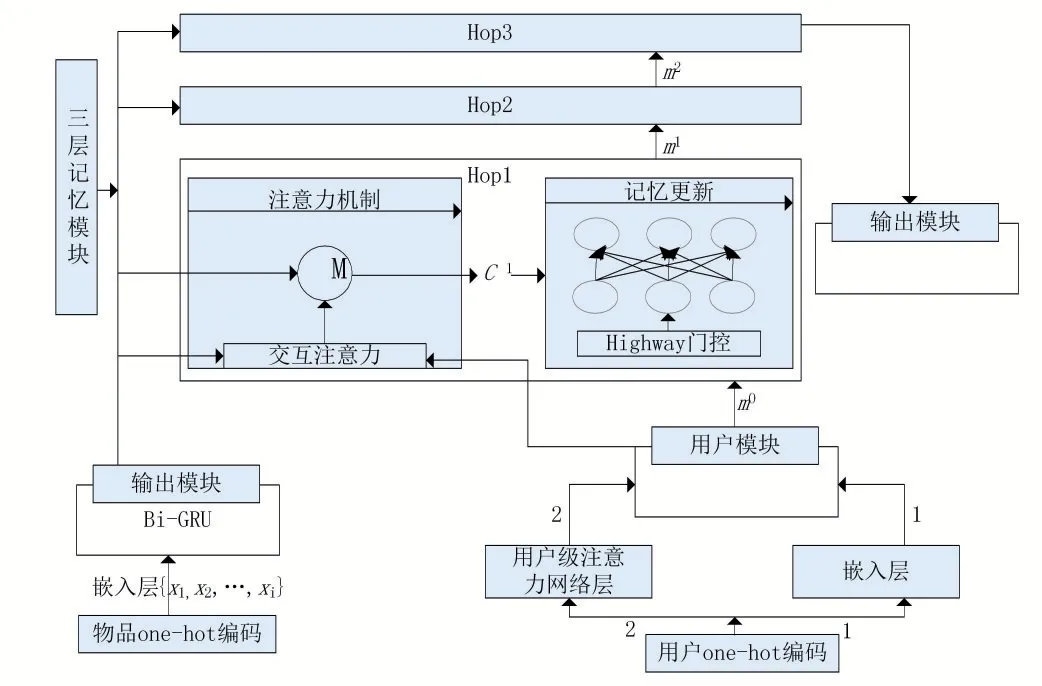
圖1 模型整體框架
2.1 輸入模塊

其中。表示向量間逐個元素的相乘,tanh(x)是神經網絡中的非線性激活函數。通過將當前時刻的輸入xt和保存了前t-1時刻的隱向量ht-1分別乘以不同的權重矩陣,再利用激活函數來將結果壓縮到0-1之間得到更新門zt和重置門rt。將向量的值壓縮到0-1之間,該單元格便能夠充當門的作用。更新門zt可幫助模型確定需要將多少過去信息(來自前一時間步驟)傳遞給未來,為1表示全部復制過去的信息,為0則表示將該信息全部阻隔。同樣地,在模型中使用重置門rt來決定忘記過去的信息量。候選狀態向量h?t利用重置門來得到當前的候選記憶,該候選記憶存儲了過去的相關記憶。最后的狀態向量ht需要用來保存當前時間戳的單元信息并將其傳遞到下游網絡。為了做到這點需要用到更新門zt。它確定候選記憶h?t和前一個時間步的隱狀態ht-1中有多少信息可以用于更新當前時刻的記憶。使用更新門和重置門,能夠消除RNN中存在的梯度消失問題。因為模型不是每次都清除新輸入,而是保留相關信息并將其傳遞到網絡的下一個時間步驟。
除此之外,由于文獻[3]已經驗證了雙向的循環神經網絡能夠同時有效地捕捉到過去和未來的消息,所以本模型采用雙向GRU,GRU層得到的最終的隱狀態表示為最后,我們將該模塊的輸出向量h填充進記憶模塊(2.3)來獲取用戶的整體興趣表示。
2.2 特征記憶網絡模塊
用戶模塊的作用是捕捉用戶長期的靜態喜好,常規的方法可以使用用戶id的one-hot編碼,再根據類似物品映射到低維向量的方式去表示用戶。但是,每個數據集下的用戶id只是系統隨機分配的一串獨特的字符,本身并沒有攜帶任何有關用戶喜好的信息。為了能夠更好地對用戶的長期內在興趣進行充分的挖掘,提出了另一種基于注意力機制的方法。用戶在平臺中的所有行為是在其內在興趣上的動態性波動的結果。要捕捉用戶的長期靜態偏好,可以全局考慮所有用戶的交互記錄,使用注意力機制選擇重要行為,并使用這些選擇的行為表示用戶的靜態偏好。
為了驗證本文提出的基于用戶級別的注意力機制在表示用戶長期偏好問題上的有效性,本文將同時實現上一段落中提到的兩種用戶表示方法。第一種onehot編碼的表示與物品相類似,在此不再多做介紹。第二種方法是采用用戶交互過的所有物品的加權和來表示該用戶的內在偏好:

其中權重因子α是用戶和隱狀態的函數,αj=q(ui,hj)。表示的是輸入中第j個位置的物品和用戶u的對齊程度。同時這個權重值也決定了在編碼用戶的內在偏好時,哪些物品比較重要,哪些物品可以忽略。α可以用多種方式學習得到,本文采用的方式受啟發于文獻[4]。具體做法是將用戶向量ui和物品向量hj映射在同一個空間中,然后對兩個向量求點積,最后把縮放后的向量進行歸一化便得到了用戶i的表示中輸入j位置的物品所占的權重:

其中,A1和A2是將兩個向饋映射到同一空間中的參數矩陣,<>符號表示向量的內積。從公式可以看出,點乘的結果再經過一次大小為dH的縮放才進行Soft?max歸一化。該步主要是為了得到一個soft attention,以便于求導和損失梯度的向前傳遞。
然后,把用戶模塊的輸出作為記憶模塊的其中一個輸入,在記憶模塊的每一層中觸發記憶模塊的注意力機制和門控機制來更新保存的記憶。
2.3 輸出模塊
記憶模塊的輸出,記作mu,是用戶u的全局表示,它集成了用戶的長期內在偏好和短期動態興趣。輸出模塊根據得到的全局用戶表示向量和物品的表示向量,采取類似于矩陣分解中的技術,將兩個向量的點積作為該用戶對物品的評分。最后,模型在所有物品評分上進行Softmax歸一化,得到的0,1之間的值表示用戶對該物品的喜好程度。
一般來說,序列預測模型采用全連接網絡層計算用戶在所有物品上的偏好分數。該計算方式下,這一步的待優化的參數是,其中是向量維度是待計算的物品的總數。因此,我們必須要保留足夠人的空間來存儲這些參數。為了降低空間使用成本,本文采用的計算方式是文獻[5]中提出的雙線性解碼方案。該方案可以在保證不丟失精度的情況下有效地降低空間復雜度。具體地,用戶u在候選物品i上的偏好得分計算如下:

最后,本文選擇交叉熵損失函數作為模型的損失函數。
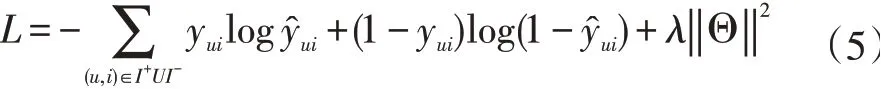
均方根平方誤差RMSE在該模型中并不適用,本文的目標是預測下一個用戶可能會消費的物品,類似于多分類問題。式(4)中,yui的值只有0和1,當用戶u購買過該物品時為1,否則為0。I+表示的是在訓練集中真實的下一個觀測物品,相對的,I-則表示集合中的其他作為負例的物品。‖Θ‖是模型中所有涉及的參數集合。在損失函數中加入L2正則,防止模型在訓練過程中發生過擬合。訓練過程中,最小化該目標函數,并且通過動量優化的方式學習模型中的參數。
3 帶輔助信息的模型
本文模型用到的信息是用戶的隱式交互序列,忽略了序列中用戶對每個物品的評分分數。在不變動模型其他部分的同時,加入數據集中的評分信息進行對比實驗。
眾所周知,評分系統廣泛存在于各大電商、視頻網站等平臺。一個用戶對某個物品的評分信息顯式的表明了其對該物品的好惡。如果模型使用的是用戶的歷史評論記錄,在某種意義上是把序列中的每一個物品都當成正例。
一般情況下,商品的評論數值為1-5或1-10的數值信息。想要使用該信息,必須首先把每個標量的數字向量化,每一個數字轉化為一個向量。對于每個用戶u來說,其歷史行為序列中的每個物品也對應了一個相應的評論序列,記作與其對應的物品向量為本文將使用疊加方式利用這兩個數據。每個時刻t輸入校塊對應的輸入為:ft=vt+rt。
4 結語
本文先從整體上介紹了序列推薦模型中各模塊的結構和具體作用,最后在模型中加入評分這一輔助信息驗證其對模型效果的作用。序列推薦由于使用的是動態記憶網絡,所以能夠記憶更多內容,在長序列上的表現也超過基于循環神經網絡的模型。模型還在記憶網絡的基礎上嵌入了注意力機制和門控機制,使得模型在理論上能夠聚焦在有用信息上,從而做出更為個性化的推薦。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
海外文摘(2016年4期)2016-04-15 22:28:55
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
