基于正則化理論的老人小孩高效SVM分類器的研究
2021-03-05 14:57:43王國慶李克祥鄭國華邵衛華夏文培
科技創新導報 2021年27期
關鍵詞:機器學習
王國慶 李克祥 鄭國華 邵衛華 夏文培



摘要:利用(基于保持稀疏重構的半監督字典學習)中學習得到的字典,得到區域的稀疏編碼系數,用該系數作為特征能夠有效地區分目標間的形狀差異。由于SVM在分類過程中需要計算測試樣本與所有支持向量之間的核函數,故實時性較差。所以采用基于正則化的集成線性SVM分類方法,既實現了快速分類,又能避免過擬合情況的發生,融合CNN深度學習算法更體現其良好性能。
關鍵詞:正則化 ?支持向量機 ?分類器 ?機器學習
Research on High-Efficiency SVM Classifier for the Elderly and Children Based on the Regularization Theory
WANG Guoqing ?LI Kexiang ?ZHENG Guohua ?SHAO Weihua
XIA Wenpei
(Zhejiang Sostech Co., Ltd., Wenzhou, Zhejiang Province, 325000 China)
Abstract: By using the dictionary learned in (Semi-supervised dictionary learning based on preserving sparse reconstruction), the sparse coding coefficients of the region are obtained.We can effectively distinguish the shape difference between the targets by using this coefficient as a feature. Since the SVM needs to calculate the kernel function between the test sample and all the support vectors during the classification process, the real-time performance is poor. Therefore, the integrated linear SVM classification method based on regularization not only achieves fast classification, but also avoids the occurrence of over-fitting. The fusion of CNN deep learning algorithm more reflects its good performance.
Key Words: Regularization; Support vector machine; Classifier; Machine learning
1. 基于正則化SVM分類器
對于提取的目標區域,需要對其進行快速判斷是否為檢測目標對象。SVM由于高準確率而成為目標識別分類的常用方法,然而其對新樣本進行預測判斷時,需要計算此樣本與所有支持向量之間的核函數,故實時性比較差。針對上述問題,本項目擬提出一種新型的SVM分類器,以實現快速、準確分類,具體可分為以下幾步。
1.1正則化理論
正則化[1](Regularization)是機器學習中對原始損失函數引入額外信息,以便防止過擬合和提高模型泛化性能的一類方法的統稱。也就是目標函數變成了原始損失函數+額外項,常用的額外項一般有兩種,英文稱作?1?norm?1?norm和?2?norm?2?norm,中文稱作L1正則化和L2正則化,或者L1范數和L2范數(實際是L2范數的平方)。正則化又稱為規則化、權重衰減技術,在不同的方向上有不同的叫法,在數學中叫作范數。以信號降噪為例公式(1-1):
(1-1)
其中,x(i)為原始信號,或者小波或者傅里葉等系數,R(x(i))為懲罰函數,λ是正則項,y(i)是噪聲的信號, 為降噪后的輸出。
范數,是衡量某個向量空間或矩陣中的每個向量長度或大小,范數的一般化定義為:對實數p>=1,范數定義如公式(1-2):
(1-2)
L1范數:當p=1時,是L1范數其表示某個向量中所有元素絕對值的和。
L2范數:當p=2時,是L2范數表示某個向量中所有元素平方和再開根,也就歐幾里得距離公式。
1.2 混合線性SVM分類器
對于提取的目標區域,需要對其進行快速判斷是否為目標對象。SVM由于高準確率而成為目標識別分類的常用方法,然而其對新樣本進行預測判斷時,需要計算此樣本與所有支持向量之間的核函數,故實時性比較差。針對上述問題,本項目擬提出一種新型的SVM分類器,以實現快速、準確分類。
混合線性模型(Mixed linear model)是方差分量模型中既含有固定效應,又含有隨機效應的模型。采用最大似然估計法(maximum likelihood,ML)和約束最大似然估計法原理計算協方差矩陣。
●總的混合線性模型(Mixed effect model,MLM)的模型方程為公式(1-3):
(1-3)
MLM在GLM基礎上引入隨機變量設計矩陣Z。式(1-3)中Y表示反應變量測量值的矩陣向量, 為固定效應參數設計矩陣向量,X為固定效應自變量設計矩陣向量, 為隨機效應參數設計矩陣向量,Z為隨機效應自變量設計矩陣向量,其中 服從均值向量為0,方差協方差矩陣向量為G的正態性分布,表示為 , 為隨機誤差設計矩陣向量,服從均值向量為0,方差/協方差矩陣向量為R的正態分布,即 。
●一種混合線性[2]的快速SVM分類器公式(1-4):
(1-4)
其中,x為輸入樣本, 和 分別為線性子分類器的權重系數和偏差,可以看出,分類器的輸出為 個子分類器群組的輸出之和,頁每個群組的輸出則是 個相互競爭的子分類器輸出的最大值。
根據上述優化問題,建立一個具有層次樹結構的SVM分類器,其基本思想是在盡可能小的函數復雜度下,用線性SVM不斷把錯分的正(負)類樣本從當前分類器所分得的負(正)類中分離出來再進行訓練。
2. 實驗與結果分析
2.1 線性SVM分類器實驗
實驗使用sklearn官網提供的Iris數據集,然后通過代碼片斷結合實驗結果進行分析。
步驟一,數據預處理,通過Iris數據集分為兩個數組,一組存放值,另一組存放標簽,以兩個特性為例,代碼如下所示:
iris_datas = datasets.load_iris()
x = iris_datas.data[:,:2] #value
x = iris_datas.target #label
步驟二,拆分數據集,將數據集拆分為訓練集和測試集驗證集,訓練集50%,驗證集20%,測試集30%。
步驟三SVC和擬合模型參數設置,選擇SVM參數,Kernel支持向量機的線性核函數,C控制誤分類訓練數據損失函數。Gamma控制模型中誤差和偏差之間誤差權衡函數,代碼如下所示:
clf = svm.SVC(kernel=’rbf’,C=c,gamma=g)
clf.fit(x_train,y_train)
接著在驗證集評估以上參數設置,并檢查相應的成功率,找到算法最優值,代碼如下所示:
clf_predictions = clf.predict(x_validate)
clf_sc = clf.score(x_validate,y_validate)
對于不同的C值訓練一個線性SVM,并繪制了數據和決策邊界。圖1中可看出1邊界變化是由C引起的通知SVM在每個訓練中避免出現多少錯誤分類。對于較大的C值,優化將選擇一個較小的邊界超平面,該超平面能更好地得到所有訓練點的正確分類。
相反,一個很小的C值將導致優化器尋找一個更大的邊界分隔超平面,即使這個超平面錯誤分類了更多的點。所以C值小的錯誤分辨率低,反之錯誤分辨率高。C=0.1時給出的最佳精度是77.77%。最后,選擇了C的最佳值,并在測試集上對模型進行了評估.通過將C調整最佳后,發現測試的準確率為83.333%為最高。
2.2 深度學習分類實驗
線性SVM分類器[3]在實驗中進行的二分類測試,經過幾輪的C值調整最后得到一個令人比較滿意的結果83.33%。但是,在實際復雜場景檢測中每次都是需要人工去干預,調整模型的參數值,這不是一個合適的方法。所以選擇一個可定制化的環境與CNN深度學習[4]一起工作,使用一個實際參數和神經元。為了簡化模型的構建項目中使用tensorflow下的輕型框架Keras,實驗步驟如下。
步驟一:獲取文件目錄里老人與兒童面部圖像數所存放目錄,將數據分成兩組,一組存放轉換后的二進制,另一存放二進制標簽值。然后將得到每一張圖像修改尺寸大小為64×64,最后存儲為npz文件。
步驟二:讀取npz文件獲取圖像值和標簽值,拆分數據集為訓練集和測試集,訓練集為80%,測試集為20%。
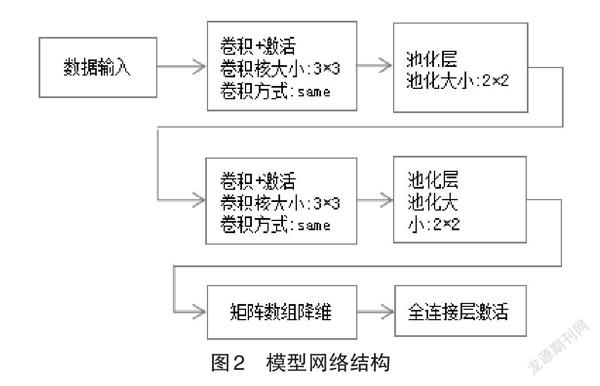
步驟三:構建網絡結構圖2分為卷積層、池化層、全連接層。網絡參數、訓練參數為Batch_size=32,num_class=2,epochs=30
Batch_size是一個重要參數,它是批大小,它定義了一次向前/向后傳播網絡的樣本數量。通常這意味著更高的批大小將為單次傳遞提供更多的示例,但也會增加內存使用。通常較小的批大小將導致更好的泛化[5-6]。
步驟四:模型訓練,通過創建的模型網絡結構(如圖2所示)和訓練參數設置,可以觀察到訓練過程中精確率,驗證正確率,訓練輪數,測試結果如圖3和圖4。
圖3的模型訓練過程精度為0.9967訓練30輪驗證率0.9868。
圖4的模型測試結果為label=0,predict=0表示為老人,label=1,predict=1表示兒童
3 ?結語
通過以上兩組實驗對比線性SVM分類器算法,調整C值過后精確度為83.333%,而選擇與深度學習CNN搭建網絡模型融合訓練得到結果0.9868%。采用這種算法雖然取得了比較好的效果,但仍然還有需要改進的地方。例如,年齡不在老年人階段,但面臉表情特征如老年人,兒童檢測也存在類似問題。后期,計劃在人臉特征提取,人臉數據多樣性方面進行優化和增強。
參考文獻
[1] 劉保成,樸燕,唐悅.基于時空正則化的視頻序列中行人的再識別[J].計算機應用,2019,39(11):3216-3220.
[2] 楊斌,王斌,吳宗敏.基于雙線性混合模型的高光譜圖像非線性光譜解混[J].紅外與毫米波學報,2018,37(5):631-641.
[3] 王福斌,潘興辰,王宜文.基于SVM的多核學習飛秒激光燒蝕光斑圖像分類[J].激光雜志,2020,41(4):86-91.
[4] 林景棟,吳欣怡,柴毅,等.卷積神經網絡結構優化綜述[J].自動化學報,2020,46(1):24-37.
[5] 葉俊賢.深度神經網絡數據并行訓練加速策略研究[D].成都:電子科技大學,2020.
[6] 王鐸. Relu網絡的一種新型自適應優化方法研究[D].北京:北京工業大學,2020.
2292501186223
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
