單目相機在無監督學習多任務場景理解中的應用
2021-02-28 06:49:54華東理工大學信息科學與工程學院童云斐陳俊詠李佳寧潘澤恩
電子世界 2021年22期
華東理工大學信息科學與工程學院 童云斐 陳俊詠 李佳寧 潘澤恩
為了解決場景理解在無標簽數據時難以適用的情況,以及無監督學習的場景理解存在的魯棒性差、未能滿足多任務需求等缺點,基于Mask R-CNN、struct2depth、SfMLearner模型,通過模型訓練、圖像預處理、多任務耦合等方法,用拍攝的實景視頻驗證模型效果,并和原模型處理結果作對比。實驗結果表明,進行預處理后的圖像結果前景輪廓更加清晰,我們的模型實現了多任務的場景理解,而原模型僅實現了單一任務。改進的無監督學習多任務場景理解算法不僅提升了魯棒性,而且直接反映了物體到相機的距離,同時提高了深度估計的精度。
隨著汽車行業的快速發展,為提供更便利安全的駕駛服務,無人駕駛技術開發已經成為汽車及信息行業的熱門研究對象。場景理解是輔助駕駛中關鍵性環節,常見的場景理解任務包括深度估計、目標識別、語義分割等。本課題擬對無監督單目相機場景理解技術的實現展開研究。基于無標簽圖像的場景理解算法無需價格高昂的標簽數據,應用范圍廣泛;除外,還可同時實現多種任務的耦合訓練,提高算法精度并降低訓練難度,有很好的研究前景。
1 場景理解
本文完成的場景理解任務包括目標識別、運動分割和深度估計。目標識別任務旨在檢測前景中的物體對象,并對其進行識別分類,得到對象的屬性信息。由于使用到分類算法,此部分網絡模型是有監督地訓練的。運動分割模塊是為了將前景中可能運動的物體分離出來,方便后續單獨進行深度估計,減小誤差。深度預測網絡使用卷積自編碼器,將原圖像經過編碼解碼得到深度信息圖。通過單目序列圖像前后幀間視差可以推導相機的運動情況,結合運動信息訓練深度估計網絡,得到好的估計模型。場景理解網絡結構圖如圖1所示。
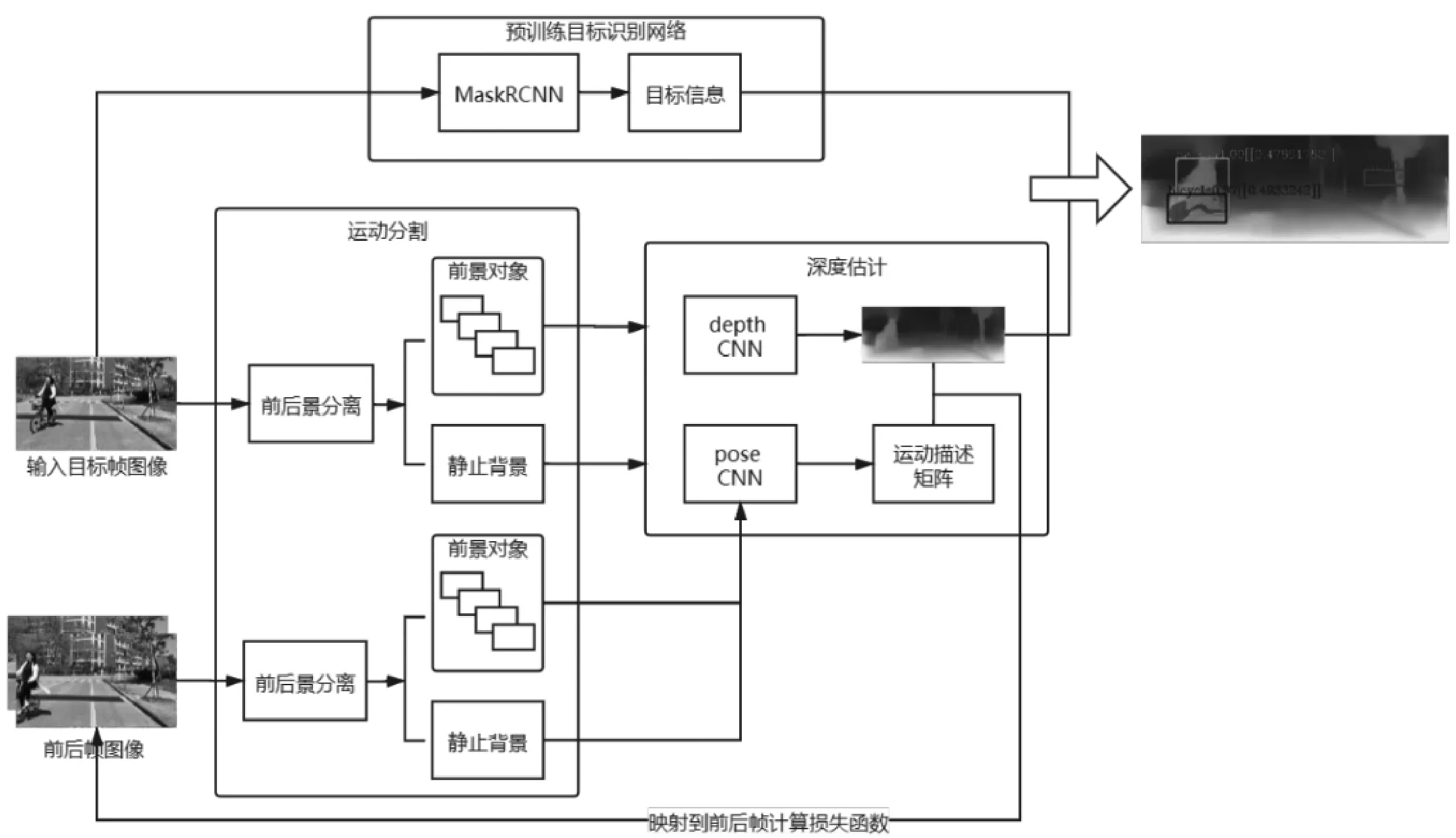
圖1 場景理解網絡結構圖
1.1 目標識別
對于目標識別任務,我們使用了一個預訓練的監督模型。參考Mask R-CNN的方法,此網絡預先進行單獨訓練,獨立于深度模型。在目標識別網絡訓練完成后,輸入圖片序列,該網絡會將圖片調整為神經網絡需要的大小并做歸一化處理,在上述操作完成后,目標識別網絡會對圖片中可能存在的對象做預測,提供識別出來的對象的掩膜信息、對象邊界框的位置及大小信息、對象類型的預測結果以及該預測結果的置信度。本文設置了顯示在圖像上的預測對象置信度的閾值,限制了只有置信度高于90%的預測結果,才會將相應的掩膜和邊界框添加到圖像上。
1.2 運動分割
本文使用的方法參考的是Casser等人提出的struct2depth模型。在圖像輸入深度網絡進行學習之前,分析圖像的結構信息,對場景中的單個對象建模,分離可能運動的前景物體和靜止背景。攝像機自我運動和物體運動都是通過單目圖像序列幀與幀之間的視差來進行學習的。對于場景中的任意一點,根據其與相機的相對運動關系,可以反推出該點的運動參數,由此可對前景中識別到的對象進行單獨的運動建模。
1.3 基于單目序列圖像的深度估計模型
與單目相機相比,雙目設備可以利用兩個視點的位置視差對圖像進行立體的理解。本文使用的方法參考了Zhou等人提出的SfMLearner模型,通過利用單目序列圖像前后幀由相機運動產生的視差對圖像場景進行深度估計。模型由兩個網絡組成,深度估計網絡Depth CNN以及用于得到相機自運動矩陣的Pose CNN。
深度估計網絡使用的是多尺度卷積自編碼器,其是一種常見無監督卷積神經網絡模型,也被多次應用到無監督深度估計任務中。模型由編碼器和解碼器組成,生成多尺度的目標圖像。Pose CNN以連續的2幀圖像作為輸入,生成相機位姿變換矩陣,描述相機在兩幀圖像前后的運動情況,包括視角旋轉和位置移動。將相機運動情況在世界坐標系中建模,可以將其在拍攝兩幀圖像時刻的前后位置變化分解成六自由度運動參數。
2 應用實驗
2.1 數據預處理
對于進行預處理后的圖像,其特征被增強,輪廓更加清晰,實驗效果更好。本項目中對圖像進行了自適應對比度增強(Adaptive Contrast Enhancement,ACE)。不同于全局的圖像增強,本項目對圖像對比度弱的部分做增強,得到的效果更好。
具體實現方法如下:
首先,計算圖像中每個點的局部均值M(i,j)和局部標準差σ(i,j)。像素值計算公式如式(1),其中,I(i,j)是增強后的像素值,f(i,j)是該點的像素值,M為全局均值,α是一個系數參數,一般取值在0到1之間。

對于彩色圖像,本方法將圖像轉到YUV色彩空間,增強Y通道明亮度后再轉回RGB空間。
2.2 實驗結果
將本文實驗結果與我們參考的深度估計鄰域的另外兩個模型進行對比。
如實驗結果圖如圖2所示,SfMLearner模型可以大致估計場景的深度前后關系,對前景物體有識別,但是不夠魯棒、準確。struct2depth模型可以識別前景中的對象,對前景中的行人和樹木都有實例分割的效果。我們在圖像進入模型推斷前加上特征增強的預處理過程,使得前景輪廓更加明確了。最后,加上預訓練的目標識別模塊,可以分割并識別前景中的對象類別。我們還在圖像中添加了方框和文本信息幫助理解,方框標出實例對象,文本標注其類別、置信度以及深度估計值。

圖2 結果對比圖
3 結語
本文針對目前無監督學習場景理解算法存在的模型魯棒性不足、未能滿足多任務需求等問題,提出改進的結合Mask R-CNN的無監督學習多任務場景理解方法。我們在結合相機自運動的深度理解模型基礎上,在數據預處理階段加入了自適應對比度增強算法以增強圖片對比度,在目標識別階段加入了掩膜以降低靜態物體或者場景對后續深度估計造成的干擾,并且更便于觀察深度預測圖中物體所在位置。實驗結果表明,本文方法在深度預估精度上有一定的提高,且對對象的識別更加準確。但目前存在一部分靜態目標或場景被錯誤識別為對象,如何改善模型以去除這些錯誤識別的對象是我們后續研究的方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
建材發展導向(2021年6期)2021-06-09 05:57:08
現代國際關系(2021年2期)2021-04-13 01:59:16
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國外匯(2019年11期)2019-08-27 02:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
