基于MOOC數據的學習行為分析與成績預測
2021-02-28 11:53:53陶利莎馬燕爨力源鄒富源田媛黃洪琳
電腦知識與技術 2021年35期
關鍵詞:數據處理
陶利莎 馬燕 爨力源 鄒富源 田媛 黃洪琳




摘要:近年來,線上教育的迅速發展給教育者提供了數據化的學習情況反饋,利用這些學習情況的反饋對學生進行成績預測便是一個新興研究點。該文記錄了研究過程中對學習者行為數據集的分析,對數據進行處理,利用Matlab進行聚類分析等方法進行分析并得出結論。利用數據分析的方法預測學習者成績在教育者的工作上有著很大幫助。
關鍵詞:數據處理;成績預測;聚類分析;學習行為
中圖分類號:TP399 ? ? ? ?文獻標識碼:A
文章編號:1009-3044(2021)35-0027-03
Analysis of Learning Behavior and Performance Prediction Based on MOOC Data
TAO Li-sha, MA Yan, CUAN Li-yuan, ZOU Fu-yuan, TIAN Yuan, HUANG Hong-lin
(The College of Information, Mechanical and Electrical Engineering, Shanghai Normal University, Shanghai 200234, China)
Abstract: In recent years, the rapid development of online courses has provided educators with data-based feedback on study situations. An emerging research focus is to use the feedback of these learning situations to predict the performance of the students. This paper records the analysis of the learner's behavior data set during the research process, processes the data, and uses Matlab to perform cluster analysis and other methods to analyze and draw conclusions. Using the method of data analysis to predict learners' performance is of great help to the work of educators.
Key words: data processing; performance prediction; cluster analysis; learning behavior
在全球化的大背景下,在線學習領域的全球化趨勢也越來越顯著。特別是由于疫情的原因,線上教育越來越普遍。隨著互聯網 Web2.0和云計算等技術越來越成熟,大型網絡教育平臺——慕課 (massive open online course ,MOOC)也正在快速興起,由于互聯網技術的記憶功能,學習者在慕課平臺上的所有學習活動和行為都會被以多種形式的數據形式記錄下來[1],基于數據挖掘和機器學習對學習者行為進行建模,分析慕課的發展趨勢和優化方案,吸引著越來越多研究人員的參與其中[2]。
由于慕課出現的時間還很短,目前為數不多的研究大致包括關于單維度數據的統計分析、對不同學科、不同線上學習平臺數據的綜合分析和研究學習者的退出率、論壇的活躍程度、課程完成率等模型[3]。本文在借鑒為數不多的模型,對學習者的學習行為數據進行分析。基于不同的分類模型,建立了預測學習者是否能獲得證書和預測學習者成績的模型,可為慕課課程的教學改進提供借鑒。
1開發思路
利用教育數據分析和挖掘技術,通過大量數據驅動的方式構建在線學習者學業成績預測模型是目前課題研究的熱點。然而,采用人工神經網絡、決策樹等算法訓練的單一預測模型的性能不穩定,由于數據變化導致預測結果誤差較大。
對MOOC學習者行為數據分析發現,學習者行為數據分布較為散亂,且成績分布在低分段的學習者較多。經統計分析發現,與傳統的教學模式相比,慕課學習者的學習目標和知識背景分布多種多樣,學習者利用平臺的方式也各不相同 ,大多數學習者并不是為了獲得證書而去學習。僅僅根據選擇相關性較強的特征向量對學習者成績進行預測無法得到較好的預測效果,因而基于學習者的多樣性將學習者聚類分析歸為不同的類別[4],再對每類進行線性回歸分析得到線性回歸方程,最后將測試集代入到預測模型中進行回歸方程的顯著性檢驗、擬合優度檢驗和回歸系數的顯著性檢驗[5]用于實際問題中。
此外,能否獲得證書也是平臺效用的一個重要體現,本文篩選重要影響變量,采用3種二元分類模型 :線性判別分析(linear discriminant analysis ,LDA )、邏輯回歸 (logistic regression ,LR)和線性核支持向量機(linear support vector machine ,l-SVM),進行是否能獲得證書的預測,準確率均較高。
2預測模型的介紹
2.1用于預測是否獲得證書的模型
預測是否獲得證書屬于典型的二分類問題,本文采用三種適用于該問題的分類模型。
2.1.1線性判別分析
線性判別分析,也稱作Fisher線性判別,是模式識別的經典算法。LDA的基本思想是想辦法將樣本數據投影到一條合適的直線上,使投影到直線上的同類樣本之間差異盡可能的小,使不同類樣本間的差異盡可能的大,這樣就可以直觀且簡便地判斷某個樣本數據屬于哪一類了。使用該種方法可以使投影后的模式樣本在新的空間中有最小的類內距離和最大的類間距離,即模式在空間中擁有最佳的可分離性。因此,它是一種有效的特征提取方法,采用該方法也能將學習者進行準確地分類。
2.1.2邏輯回歸
邏輯回歸模型是針對二分類問題的一種易于實現而且性能優異的分類模型。邏輯回歸目的是從特征學習出一個0/1分類模型,其中,用1表示獲得證書,0則反之。這個模型是將特性的線性組合作為自變量,即選擇學習者的特征向量數據作為自變量,由于自變量的取值范圍是負無窮到正無窮。因此,使用logistic函數(或稱作sigmoid函數)將自變量映射到(0,1)上,映射后的值被認為是屬于y=1的概率,也就是獲得證書的概率。然后將映射后的值在(0.5,1)的歸為一類,將處于(0,0.5)的歸為另一類,便完成了學習者的分類。
2.1.3線性核支持向量機
支持向量機(SVM)是一種監督式學習的方法,它廣泛地應用于統計分類以及回歸分析中,同樣也是解決分類問題的經典模型。考慮到學習者的特征向量數據是非線性的,本文的處理方法是選擇線性核函數,通過將數據映射到高維空間,來解決在原始空間中線性不可分的問題。在分開數據的超平面的兩邊建有兩個互相平行的超平面,分隔超平面使兩個平行超平面的距離最大化,可以對數據進行有效地劃分。
2.2用于預測成績的模型
2.2.1K-means聚類模型
聚類和回歸是兩類主要的預測問題,聚類是預測離散的值,形成的離散的“簇”對應著潛在的離散概念的劃分。回歸是預測連續的值,將兩者進行結合能得到適應性較強的預測模型。對于無標簽的學習者樣本,采取無監督的K-means聚類分析對學習者進行劃分,這種方法的主要缺點是隨機選擇初始質心,如果數據存在離群值,可能會收斂到一個不穩定的結果,采用LOF算法剔除離群值可以提高模型的準確率。
實現K-means算法主要包括以下四點:
(1)簇個數 k 的選擇;
(2)各個樣本點到“簇中心”的距離;
(3)根據新劃分的簇,更新“簇中心”;
(4)重復上述2、3過程,直至"簇中心"不再移動。
2.2.2線性回歸模型
主要包括以下幾個步驟:
(1)對K-means聚類后的各數據點求取線性回歸方程;
(2)測試集檢驗,將測試數據點歸到距“簇中心”距離最小的一類;
(3)代入該類的線性回歸方程中,得到預測值;
(4)方程通過回歸方程的擬合優度檢驗[5],評估預測模型確定最優回歸模型。
3具體實現
本文利用matlab及其工具箱進行應用程序的編寫,建立了一個分類預測模型,對在線學習的學習者是否獲得證書和學習成績進行預測。
3.1學習者是否獲得證書的預測
首先,導入與獲得證書相關的兩個特征向量數據:頁面訪問量和學習章節數。對數據進行異常值的剔除:
for i = 1:m
for j = 1:m
dist(i,j) = norm(K_train(i,:)-K_train(j,:));
end
end
lof = LOF(dist);
for i=1:m
if lof(i)>1
K_train(i,:)=NaN;
end
end
K_train = K_train(all(~isnan(K_train),2),:);
其次,對數據進行歸一化處理,歸一化代碼如下:
[x,y]=size(data);
tackledata=zeros(x,y);
maxd=max(data);
for i=1:y
for j=1:x
tackledata(j,i)=data(j,i)/maxd(i);
end
end
調用matlab的classification learner工具箱,選擇線性判別、邏輯回歸和線性支持向量機進行訓練。
其中,將模型導出后,可以通過如下語句檢驗模型:
trainModel.predictFcn(data);
3.2學習者成績的預測
首先,導入與學習者成績相關的三個特征向量數據:頁面訪問量、參與課程互動的天數和學習章節數。對數據進行異常值的剔除和歸一化處理。
其次,對數據進行K-means聚類分析,得到如表3所示的聚類中心,關鍵語句如下:
k=3; [cluster2,C,sumD,D]=kmeans(K_train(1:3),k,'Start','uniform','Distance','sqEuclidean','Replicates',5);
再通過如下代碼:
CoeMatrix=[];
for i=1:k
[m,n]=size(K_train(cluster==i,1:3));
linear = fitlm(K_train(cluster==i,1:3),K_train(cluster==i,4));
CoeMatrix=[CoeMatrix linear.CoefficientCovariance(:,1)];
end
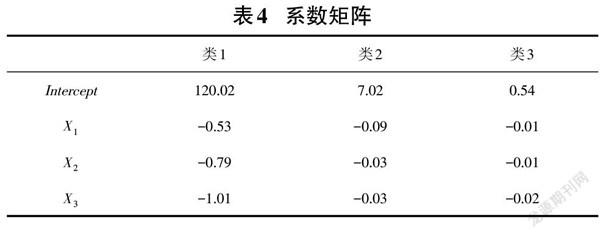
得到各類的線性回歸模型,其中,CoeMatrix為三類學習者特征向量的系數矩陣,如表4所示。
結果表達式:
[Y1=120.02-0.53X1-0.79X2-1.01X3]
[Y2=7.02-0.09X1-0.03X2-0.03X3]
[Y3=0.54-0.01X1-0.01X2-0.02X3]
最后,導入測試數據對模型的預測效果進行檢驗,代碼如下:
[Error1,Predition1,clunum]=prediction(CoeMatrix,K_test,C,k);
[allx,ally]=size(K_test);
grade=K_test(:,4);
MSE = sum((Predition1-grade).^2)./allx;
RMSE = sqrt(mean((Predition1-grade).^2));
MAE = mean(abs(Predition1-grade));
R2 = 1 - (sum((Predition1-grade).^2) / sum((grade - mean(grade)).^2));
其中,調用prediction函數,可以將測試數據劃分到不同的類同時得到預測值和誤差,MSE、RMSE、MAE、R2為線性回歸模型的評價指標。這是該模型最核心的代碼,其余代碼在此不做過多贅述。
決定系數R2越趨近于1表明擬合效果越好[5],實驗所得的R2為0.62,說明該模型具有較好的擬合效果。
4 結束語
在宏觀方面運用K-means聚類然后進行多元線性回歸分析,構建出一種適應性更強的成績預測模型,微觀方面依據判定系數 R2 和估計標準差來檢驗[5],具有不錯的實際應用效果,可以將需要進行預測的學習者學習行為數據導入,得到相應的預測值。預測結果為教師和管理者對教學計劃和教學模式的改進提供了可靠的數據保障,為后續學習行為分析及成績預測起到借鑒和促進作用。
參考文獻:
[1] Breslow L,Pritchard D,DeBoer J,et al.Studying learning in the worldwide classroom:Research into edX’s first MOOC[J].Research & Practice in Assessment,2013,8(1):13-25.
[2] Waldrop M M. Online learning:Campus 2.0[J].Nature,2013,495(7440):160-163
[3] 蔣卓軒,張巖,李曉明.基于MOOC數據的學習行為分析與預測[J]. 計算機研究與發展,2015,52(3):614-628.
[4] 張強. MOOC 學習者學習行為聚類分析[J].通化師范學院學報,2015,36(2):37-39.
[5] 郝巧龍,魏振鋼,林喜軍. MOOC學習行為分析及成績預測方法研究[J].電子技術與軟件工程2016(7):167-168.
【通聯編輯:王力】
猜你喜歡
中學生數理化·自主招生(2022年9期)2022-05-30 10:48:04
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
電子測試(2018年4期)2018-05-09 07:28:12
當代化工研究(2016年9期)2016-03-20 16:22:13
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
計算機工程(2015年4期)2015-07-05 08:28:04
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
聯合國青年技術培訓(2014年7期)2014-04-12 00:00:00
中國質量與標準導報(2014年7期)2014-02-28 22:24:35
