集成算法在工程核心部件剩余壽命預測中的應用
2021-02-24 10:17:12龍勝平李錚偉陳建萍
設備管理與維修 2021年2期
龍勝平,袁 戟,李錚偉,陳建萍,寧 可,孫 奧
(1.華東師范大學工商學院,上海 200241;2.上海東方低碳科技產業股份有限公司,上海 200052;3.同濟大學機械與能源工程學院,上海 200092)
0 引言
工程核心部件RUL(Remaining Useful Life,剩余使用壽命)預測是設備全生命周期健康和運維的核心內容之一,基于數據驅動的算法,可在很大程度上克服試驗成本高、周期長的局限性,并逐漸成為剩余使用壽命預測和維護的重要而有效的解決方案。
由于預測的準確性對保障設備安全運行、降低維護成本意義重大,近年來樹模型強大的泛化性和魯棒性,尤其是XGB(極限梯度增強)、LGB(非對稱加密)等算法在工程應用中優勢凸顯,使得樹模型在研究領域備受重視。Li Fei等[1](2018)為了更充分地抓取退化信息,以時間序列窗口的原始數據和渦扇引擎運行時間為輸入項,應用LGB模型在C-MAPSS數據集上進行有效性驗證。Li Yiming[2](2019)采用了特征優化降維方法,并應用局部線性嵌入和LGB預測工具使用壽命。本文中選取LGB為基本模型,結合遺傳規劃的優勢,提升LGB算法的預測精度。
通過Stacking的算法集成方式提升模型精度,現正成為RUL預測領域的一大研究熱點。Shamaei Ehsan等[3](2016)通過對GP(Genetic programming,遺傳規劃)算法和模糊神經網絡進行算法集成(Stacking),提升單模型的預測精度,在泥沙沉積預測中進行了應用,并在實際數據集上做了有效性驗證。在調研中發現,GP算法是一種比較有效的非線性擬合算法,它能夠給出具體的預測值對應的解析表達式,相比其他算法,有較強的解釋性[4]。Liao Linxia等[5](2014)通過GP算法對原數據集進行預兆特征挖掘,從而提升剩余使用壽命計算精度。Qin Aisong等[6](2017)基于首次預測時間,應用GP算法找尋更佳退化因子,并結合維納過程退化模型預測旋轉機器的剩余使用壽命。
在調研過程中發現通過Bagging的抽樣和樣本匹配,也能實現模型精度的提升[7]。Wang Tianyi等[8](2008)通過找尋疲勞裂紋擴展測試集相似的訓練集樣本,對樣本的剩余使用壽命(RUL)進行了估計,改進的模型有更好的預測精度。李勁松等[9](2016)提出一種基于K-Means的聚類匹配曲線相似性的方法,估計航空渦扇發動機剩余使用壽命,并驗證了方法的有效性。武斌等[10](2016)提出了基于相似性的軸承剩余使用壽命預測方法,準確率高達81.8%。
本文考慮訓練集到測試集之間的匹配性,選取特征相似的樣本,應用Bagging采樣方式保證模型精度提升。并通過GP算法實現強特征的提取,采用和LGB算法Stacking的集成方式,提升單模型的預測精度。本文在競賽數據集上對模型的有效性進行了驗證,對相關研究具有一定的借鑒意義。
1 基本原理
1.1 預測模型
本節重點介紹LGB和GP算法。其中,LGB是微軟開發的基于梯度下降的Boosting算法。LGB通過基于梯度的單邊采樣和互斥特征捆綁,有效地降低處理樣本的時間復雜度。此外,在大量的數據實驗和實踐應用中都證明LGB在計算精度上有明顯優勢,特別適用于大型數據集的情況。
假設訓練集(xs,ys)和測試集(xt,yt),其中xs和xt分別表示訓練集和測試集特征,ys和yt分別表示訓練集和測試集的部件真實的剩余使用壽命(RUL)。通過LGB對測試集的RUL進行估計,可表示為[1]:


GP算法是一種基于遺傳算法原理構建的非線性擬合算法,有著明顯的設置參數少、模型適應性強、運算效率高、模型可解釋性強等特點[5]。由于GP算法中應用了遺傳算法的基本原理,解析表達式會隨遺傳的代數會發生變異,通常迭代更新20~50代后結果較為穩定。
本文采用Stacking算法集成方式來實現LGB和GP算法的集成。首先通過GP算法從原特征數據抽取得到新的特征,即g(xt)=xt+,將變換后的訓練集和測試集({xs;xs+},ys)和({xt;xt+},yt),應用LGB進行RUL預測,代入式(1)可得:

其中,fk(·)通過訓練集數據({xs;xs+},ys)確定。
1.2 特征匹配和采樣
由于LGB中通過互斥特征捆綁(EPB)的方式來實現特征的選取,是通過訓練集樣本特征來實現的,未考慮測試集和訓練集樣本特征的相似性和匹配性問題。
訓練集特征xs和測試集特征xt樣本總計分別為M和N,且M>>N。計算每個訓練集樣本xtj(j=1,2,…,N)到訓練集特征的距離,并以最小距離對應的訓練樣本重新構建M個訓練樣本集{xs'}:

其中,dj(·,·)表示距離算子,可表示為:

為確保通過若干弱學習器集成后降低原模型的預測誤差[7],本文采用Bagging方式隨機采樣,將訓練集(xs,ys)抽樣為n個訓練子集,即(xsi,ysi),i=1,2,…,n,然后再進行特征匹配計算,重構新的訓練子集。
2 算法設計
為了簡化表達,本文以下忽略剩余使用壽命的標簽子集ysi,用xsi表示訓練集子集,其他表達式以此類推。根據上一章所述,通過選取特征集中的若干特征作為特征子集,并以此為基礎計算和測試集最為匹配的訓練集樣本作為訓練樣本{xsi'}。然后通過GP算法進行新特征提取,得到計算結果{xsi+},同樣操作可應用于測試集特征{xt},獲得新的特征{xt+}。將新特征和原特征匹配后的子集合并,即{xsi';xsi+},代入LGB進行模型訓練,得到對應的k輪迭代的決策樹模型fki。在n個訓練新子集上獲得的模型,可應用于測試集對應的新特征,并代入式(3)預測部件的剩余使用壽命:

經過若干個弱學習器的學習,取得期望值,根據Bagging算法的基本原理,得到的計算結果誤差應當小于原有單個LGB模型的計算結果誤差,圖1為算法的大致架構和計算流程。
3 案例分析
3.1 背景信息
研究案例源自2019科大訊飛工程核心部件剩余壽命預測賽題。已知某類工程機械設備的核心耗損性部件的特征數據字段包括:部件工作時長、累計量參數1和2、轉速信號1和2、壓力信號1和2、溫度信號、流量信號、電流信號、開關信號1和2、告警信號1,以及設備類型。訓練和測試數據文件分別為1100個和890個,每個文件對應一個工程部件的分時監測數據,需要預測測試部件的剩余使用壽命。預測準確性的評估函數定義如下:


圖1 算法流程架構
其中,yt和分別表示樣本真實的使用壽命和預測值;N表示測試集樣本數量,即N=890。
3.2 特征提取和匹配
本文主要是在原有的特征的基礎上,通過總使用壽命0.35~0.85每隔0.01的比例進行切片,并提取對應時間切片中的最大值、最小值、中位數、均值、25%分位數(下分位數)、75%分位數(上分位數)、complexity、標準差、偏度、峰度等統計學特征。此外,提取觀測時序中的突變點作為特征,即時間序列中變化超過±20%的數據點。
此時特征已將近1200維,考慮到占用的計算資源,且并非所有的特征都是有效的,根據缺失值和零值所占的比例,剔除占比超過50%的特征,并對非開關信號1、告警信號1進行差分處理,變換為one-hot形式的數據格式,這兩種方式提升預測精度3%以上。隨后采用Bagging的方式對50%的訓練集樣本進行隨機抽樣,隨機抽取其中若干條特征進行匹配(20~50維效果最佳),其中部件當前使用壽命為非常重要的參考特征。
3.3 結果分析
LGB算法在訓練集上用2折交叉驗證,迭代次數為800,早停迭代次數為200,學習率為0.01,最大葉子數量為250,最大樹深為5,boosting方式選擇gbdt,損失函數選擇regression,隨機種子選取1024。GP算法繁衍代數為50,提取新特征時繁衍代數為20,其他參數遵循默認設置[12]。
在Bagging算法獲取的訓練子集{xsi}上,GP和LGB算法得到的最終分數略有差異,約為0.008。而在通過特征匹配的訓練子集{xsi'}上兩種算法分別有0.024和0.03的精度提升。通過特征匹配和GP+LGB算法集成,預測壽命的精度相比只是基于Bagging訓練集{xsi} 的模型效果有將近0.025~0.03的精度提升(表1)。
部件當前使用壽命對剩余使用壽命預測的影響較為顯著。圖2所示為實驗5部件當前使用時長和剩余壽命之間的分布關系,可觀察到部件當前使用壽命約為4000以下時,剩余和當前使用壽命存在一定線性比例關系,而當前壽命大于4000時,剩余使用壽命類似于漸近線,但分布較為發散。這可能是由于測試集給出的部件當前使用壽命時間越短,預測的不確定性越大。在實驗過程中發現當前使用壽命已大于4000時,通過Bagging、特征匹配、Stacking方式生成的預測模型,預測得到結果的離散程度越大,而實際精度也越高。

表1 基于訓練集和算法的反饋結果
4 結語
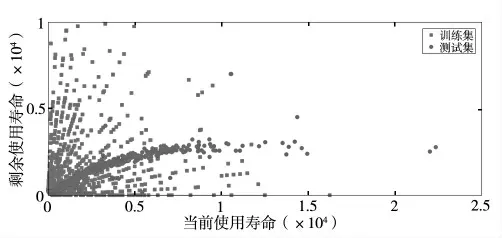
圖2 部件當前和剩余使用壽命分布
工程核心部件壽命預測對于預測性維護意義重大,本文在GP和LGB的Stacking集成算法的基礎上應用Bagging以及特征匹配算法,通過數據實驗論證該方法在的有效性,對相似工程問題能夠提供較好的解決方案。運用該方法和一些數據預處理技術,東方低碳算法團隊在2019科大訊飛比賽工程機械核心部件壽命預測挑戰賽決賽中取得了團隊第四名的成績,并榮獲了算法菁英獎。
感謝在2019科大訊飛比賽工程機械核心部件壽命預測挑戰賽中孫奧、袁戟、王尉同、熊喬楓、李敬杰等參賽選手的努力付出和出色表現。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
