基于面向對象隨機森林方法的濱海濕地植被分類研究
2021-02-22 04:00:58李玉鳳劉紅玉
南京師范大學學報(工程技術版) 2021年4期
宗 影,李玉鳳,劉紅玉
(南京師范大學海洋科學與工程學院,江蘇 南京 210023)
遙感因其數據獲取方便、監測范圍廣被逐漸應用到農田濕地的分類研究中. 目前,利用遙感進行分類的方式包括基于像素和對象兩種[1]. 基于像素的分類以單個像素為最小單元,分類時只考慮到地物的光譜、大小與位置信息[2],但這種分類方式會產生椒鹽現象從而制約分類的精度. 而面向對象分類以合并之后的對象為基本處理單元,減少了分類破碎的現象,可以同時考慮地物的光譜、紋理等信息,分類精度更高、提取效果更好[3-5],目前被廣泛應用于植被的分類中. 如邵亞婷等[6]使用面向對象的分類方法對鹽城濱海濕地的植被進行分類,6個時期的影像分類精度均達到90%以上. 張蓉等[7]以Landsat多時相影像為數據源,用面向對象的分類方法對大珠江三角洲的紅樹林進行分類,分類精度均保持在85%以上. 隨著大量遙感衛星的發射和計算機技術的發展,神經網絡、決策樹與隨機森林等方法逐漸運用到地物分類中,并得到較高的分類精度[8-9]. 其中隨機森林分類方法能夠利用樣本之間存在的差異,并且可以更好的處理高維數據[10-11]. 隨機森林方法對農田、濕地植被的分類,都取得了較好的分類結果. 如張磊等[12]基于 Sentinel-2 數據利用不同的特征組合對黃河三角洲的植被進行提取,并用隨機森林模型進行分類,總體精度高達90.93%. 劉家福等[13]利用融合后的Landsat OLI影像在特征優選的基礎上構建隨機森林模型提取黃河口濱海濕地植被,取得了較好的分類效果. 谷曉天等[14]基于Landsat OLI影像數據、DEM數據,用多種分類方法對復雜地形的土地利用類型進行分類,研究表明隨機森林的分類效果最好. 目前已有部分學者使用隨機森林與面向對象分類方法相結合進行濱海濕地植被的分類[15-17],但是大部分研究都是以高分辨率影像為數據源包括GF-2、QuikBird與無人機影像,這些高分辨率的影像價格昂貴,應用于大尺度遙感提取的方法成本較高.
另外,當前濕地分類研究主要集中于內陸濕地,對濱海濕地遙感分類研究較少,且存在不足. 由于濱海濕地是海陸相互作用形成的特殊地理區域,濕地形成與演變處于高度動態變化中. 江蘇濱海濕地主要分布于鹽城海岸,是典型淤泥質潮間帶濕地,以草本濕地植被類型為主要特征,空間上動態演變十分明顯,各類型之間交錯帶植被分布較為復雜. 因此,如何利用遙感方法對其進行分類,成為區域濕地分布研究的重要科學問題. 因此本文以Sentinel-2影像為數據源,通過面向對象與隨機森林結合的算法,試驗不同的特征組合方案的分類精度,找出適合鹽城濱海濕地分類的最佳特征組合,以提高區域內植被的分類精度.
1 研究區概況與數據來源
1.1 研究區選擇
選擇江蘇典型濱海濕地分布區為研究對象. 該區位于江蘇鹽城國家級珍禽自然保護區核心區,北臨新洋港,南接斗龍港,面積1.92×104hm2(如圖1所示). 濕地植被類型以蘆葦、堿蓬和互花米草為優勢種群. 由于區域位于淤長型海岸地段,濕地以每年50~100 m速度向海淤進[18],在地形、地貌、土壤與水文等生態環境要素綜合作用下,濕地植被類型自陸向海呈帶狀分布格局,并且處于高度敏感和動態演變過程中,各類型之間交錯帶植被分布十分復雜.
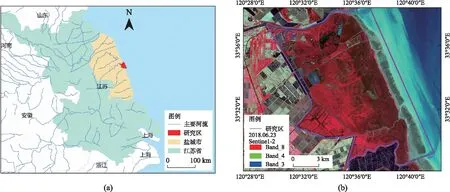
圖1 研究區地理位置圖Fig.1 Geographic location of the study area
1.2 數據來源與預處理
1.2.1 遙感數據
Sentinel-2遙感數據有13個波段,包括10 m、20 m和60 m 3種空間分辨率(如圖1(b))所示. 其中紅光波段(B4)、綠光波段(B3)、藍波段(B2)、近紅外波段(B8)分辨率為10 m;紅邊波段(B5、B6、B7)、近紅外波段(B8A)、短波紅外波段(B11、B12)分辨率為20 m;海岸波段(B1)、水汽波段(B9)、卷云波段(B10)分辨率為60 m. 此數據分辨率較高,且包含易于植被區分的紅邊波段. 因此為開展鹽城保護區核心區植被分類研究,選取2018年6月23日質量較好的Sentinel-2影像作為數據源. 數據從歐空局網站(https://scihub.copernicus.eu/)下載,數據級別為LIC級,此數據已經過幾何校正和輻射校正,因此使用SNAP軟件進行大氣校正,大氣校正后將所有波段分辨率重采樣成10 m.
1.2.2 樣本數據
本研究使用現場實測數據并結合2017年的GF-2影像(1m)采用目視解譯方式進行樣本點的選取. 2018年6月對研究區進行了現場采樣,利用GPS對不同的植被類型樣點進行定位,同時以GF-2影像為基礎影像選取樣本點以增加樣本數量. 綜合考慮影像的分辨率與前人研究內容,將研究區分為互花米草、蘆葦、堿蓬、光灘和水體5種類別.
2 研究方法
2.1 面向對象影像分割
面向對象影像處理先對影像進行分割,分割之后對影像進行分類. 分割算法有棋盤分割、多尺度分割等[19]. 本研究使用的是多尺度分割算法,它對相鄰像元或分割之后較小的對象進行合并,使對象內部像元之間的同質性最大[20],進行分割時分割尺度對分割的結果產生較大的影響. 本研究的分割尺度由eCognition9.0中的ESP2工具來確定,ESP2工具基于分割對象的局部方差(LV)及其變化率(ROC)度量尺度分割的合理性,ROC-LV曲線的峰值點所對應的尺度就是影像的最優分割尺度[21-22]. 本研究在ESP2分割結果的基礎上,選出3個較高的峰值,然后分別試驗峰值對應下3個尺度的分割效果. 由于本文研究植被的分類,形狀參數對其分類影響不大,因此采用默認參數,其中形狀因子為0.1,緊密度為0.5,各波段權重設為1,影像的分割結果如圖2所示,選取95、120與127分別進行分割,對比植被在3個尺度下的分割效果,選取的最終分割尺度為95.
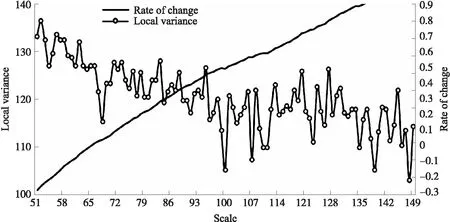
圖2 最優分割尺度估計結果Fig.2 Optimal segmentation scale estimation results
2.2 特征變量提取
研究區主要由水體和植被組成,因為水中含有泥沙,其反射率會在可見光波段增加[23]. 植被光譜特征在可見光、近紅外波段表現出雙峰和雙谷的特征,即在紅光波段吸收而近紅外波段高反射和高透射,常利用這兩個波段進行相關運算對植被進行分類,同時紋理特征也可以提高分類的精度. 因此本文選取灰度共生矩陣計算紋理特征,共選取植被指數、水體指數、光譜特征與紋理特征4種類型的特征變量. 具體特征指標如表1所示.

表1 影像對象的分類特征描述Table 1 Description of classification features of image objects

表2 不同試驗方案組合Table 2 Combination of different test scenarios
在eCognition9.0中分割的基礎上,計算表1所示的不同特征. 為了提高濕地植被的分類精度,并探究不同的特征對于分類的重要性,將表1所示的分類特征進行不同的組合,設計如表2所示的5種不同的組合進行試驗,研究適合本研究區植被分類的特征組合.
2.3 隨機森林分類算法
隨機森林于2001年首次提出,以決策樹為基本單元,將多棵決策樹集合在一起的一種算法[24-25]. 每個決策樹相當于一個分類器,隨機森林包括兩層的隨機選擇:隨機選擇樣本數據和隨機選擇分類特征,這使得隨機森林不易過擬合,具備很好的抗干擾能力[26].
隨機森林建立可分為以下三步:(1)在所有樣本中,采用隨機且有放回的方式進行抽樣,組成訓練樣本集,每個訓練樣本集的樣本數大約為總樣本數量的2/3. (2)對抽取的訓練樣本集進行訓練,在決策樹生長過程中,每棵樹的每個節點處任意抽取特征,每個決策樹根據輸入的樣本數據與特征進行分類. (3)重復(1)、(2),通過多次樣本抽取和訓練得到多個決策樹模型,最后根據不同的決策樹分類結果投票決定最終的分類結果.
2.4 特征優選方法
特征選擇可以在多維特征中篩選出最有利于分類的特征子集,進而提升隨機森林模型的效率和分類精度[27]. 選擇袋外數據(out-of-bag,OOB)誤差和Kappa系數進行模型評估以確定模型最優特征數量. 在模型訓練過程中,通常將訓練數據按7∶3的比例分為訓練集和測試集,對測試集的預測值與真實值計算得到Kappa系數[28]. 而OOB誤差是指在抽樣的過程中約有1/3的原始樣本數據未被選中. OOB誤差是隨機森林用未進行模型訓練的袋外數據計算得到的泛化誤差,可以表征特征的重要性(variable important,VI)[29]. 公式為
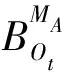
在特征重要性的基礎上,采用遞歸消除法進行特征選擇. 步驟如下:(1)計算所有特征的重要性并進行排序,選定要消除特征的比例. (2)以特征重要性為基礎消除排序靠后的特征,得到新的特征集. (3)用新的特征集再次進行隨機森林建模同時計算袋外誤差率,重復此步驟,最后剩下M個特征[31]. 通過以上方式得到不同特征集和每個特征集對應的袋外誤差率,選擇袋外誤差率較低和Kappa系數較高的特征作為最優特征集.
2.5 分類精度評價
以2017年9月14日經過融合后的GF-2影像數據為依據,在ArcGIS中生成500個均勻分布在整個研究區范圍內的隨機點作為驗證樣本. 通過對驗證樣本和分類結果的比較,得到混淆矩陣,從混淆矩陣中計算總體精度(OA)、制圖精度(PA)、用戶精度(UA)和Kappa系數對不同特征組合的分類結果進行評價.
制圖精度(生產者精度)指影像被分類為A的像元數與實際A的像元數之比. 用戶精度指影像正確分類為A的像元數和與分出的所有A類像元數之比. 總體精度指被正確分類的像元總和與總像元數之比. 而Kappa系數與總體分類精度相比,將漏分和錯分的像元也同時考慮進來[32].
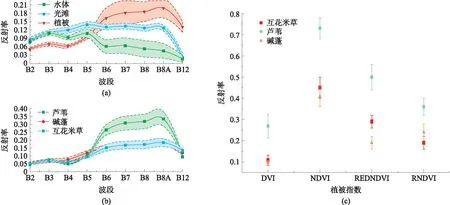
圖3 2018年不同地物光譜曲線與指數圖Fig.3 Spectral curves of different features and vegetation in 2018
3 結果與分析
3.1 地物光譜與特征優選分析
在ENVI5.3中以影像為基礎,選取不同地物的純凈樣本,統計不同地物類型的光譜反射率與部分植被指數值,組成數據集. 根據這些統計值做典型地物的光譜曲線,如圖3所示. 圖中地物的光譜特征存在差別,光灘、水體與植被單獨使用光譜特征便可以進行區分. 3種植被的光譜信息較為相近,其中蘆葦在紅邊波段至近紅外波段(B6-B8A)與其他2種植被的光譜差異較大,但互花米草與堿蓬的光譜值極為相近,使用光譜特征難以區分. 由圖3(c)可知,蘆葦的各種指數反射率值較高且與其他兩種植被差別較大,可以與其他2種植被進行區分,3種植被在REDNDVI的反射率有所差別,可以用來植被間的區分,而堿蓬與互花米草的另外3個指數的值十分相近,很難進行直接的區分. 雖然單波段與單指數可以實現個別地物的區分,但是區分效果不同且全部地物不能依靠單一特征進行有效區分,因此要對特征進行組合. 不同的植被指數、水體指數與光譜的組合對地物分類的作用不同,多個特征的組合會優于單個特征,但是特征數量過多又會增加數據的冗余度,因此找出合適地物分類的特征組合十分重要.
根據表1的分類特征與表2的實驗方案,本文采用R軟件實現隨機森林模型的構建. 在模型訓練中,需要對參數進行尋優,包括決策樹的數量、特征數量、樹的最大深度與葉節點最大數目等. 其中決策樹的數量與特征的數量對模型分類精度影響較大,因此對這兩個參數進行優化[33]. 首先采用逐一增加變量的方法建模,根據OOB誤差確定用于分類的特征數量. 在特征數量確定后,建立相應的模型,并對其進行可視化分析,繪制模型誤差與決策樹數量的關系圖,從而確定決策樹的數量. 如圖4為對所有的特征進行建模的決策樹的數量與誤差精度圖. 可見,當樹的數量大于700后,模型精度基本無變化,因此最終選取的決策樹的數量為700.
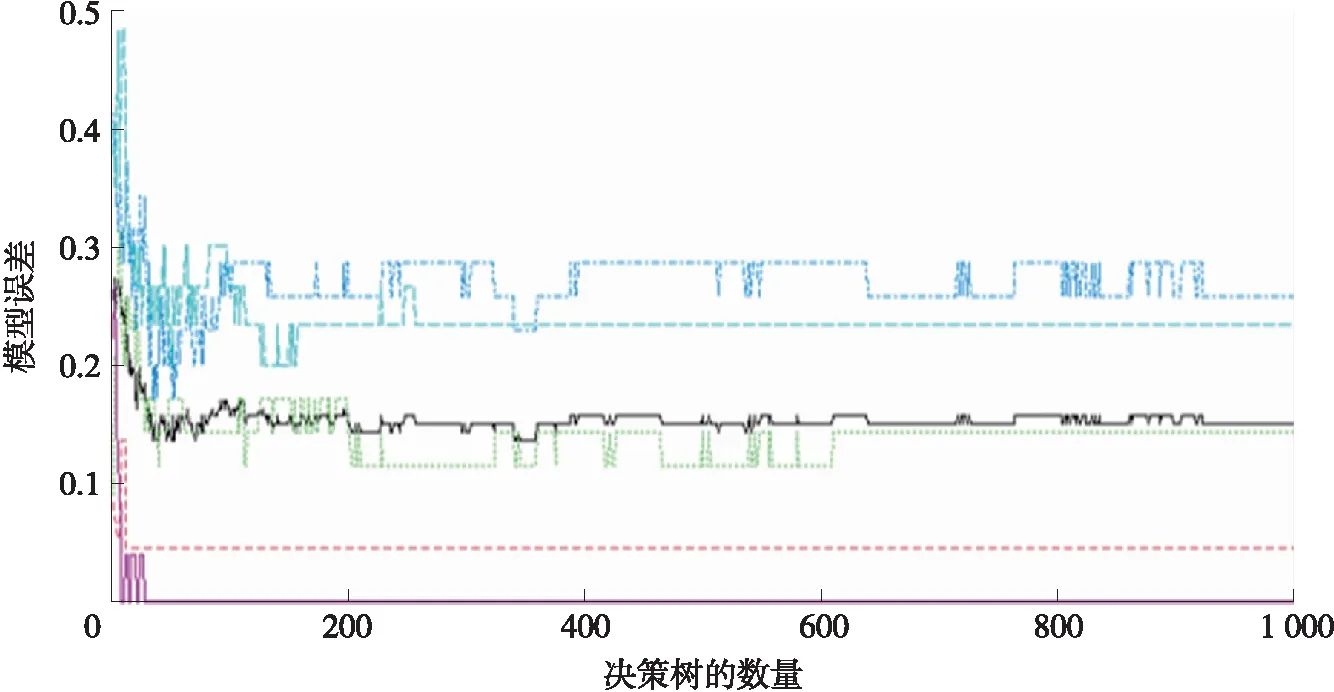
圖4 模型誤差與決策樹數量關系圖Fig.4 Plot of model error versus number of decision trees
本文首先使用所有的特征進行建模,并對特征重要性進行計算排序,每次去掉排序靠后的20%的特征,然后使用其余的特征再次進行隨機森林建模,在此基礎上共進行13次迭代消除. 每次迭代消除后計算OOB誤差與Kappa系數,根據OOB誤差與Kappa系數進行特征的優選.
由圖5可知,Kappa系數隨著分類特征數量的不斷減少呈現波動下降趨勢,當分類特征數量減少到25時,模型精度上升. 隨著特征數量的不斷減少,精度總體呈下降趨勢. 隨著分類特征數量減少,OOB誤差總體呈現較大的波動,可能是本研究選取的特征數量較少,因此每次迭代消除的數量也較少,使OOB缺乏規律. 最終,當剩余25個特征時Kappa系數最高為0.81,此時OOB誤差也較小,因此選擇重要性前25的特征作為最優特征集用于植被分類,選取的25個特征重要性排序如圖6所示. 在排序靠前的特征中,植被指數占得比例較大,且得分較高.
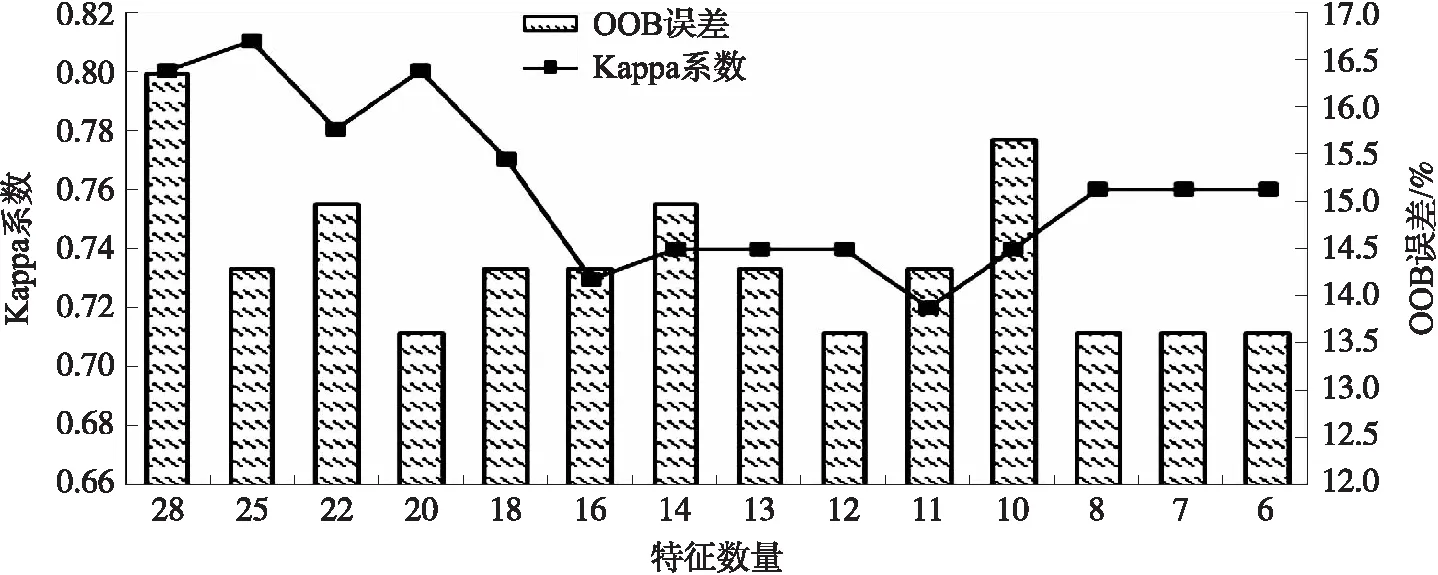
圖5 模型誤差與特征數量關系圖Fig.5 Map of relationship between model error and number of feature
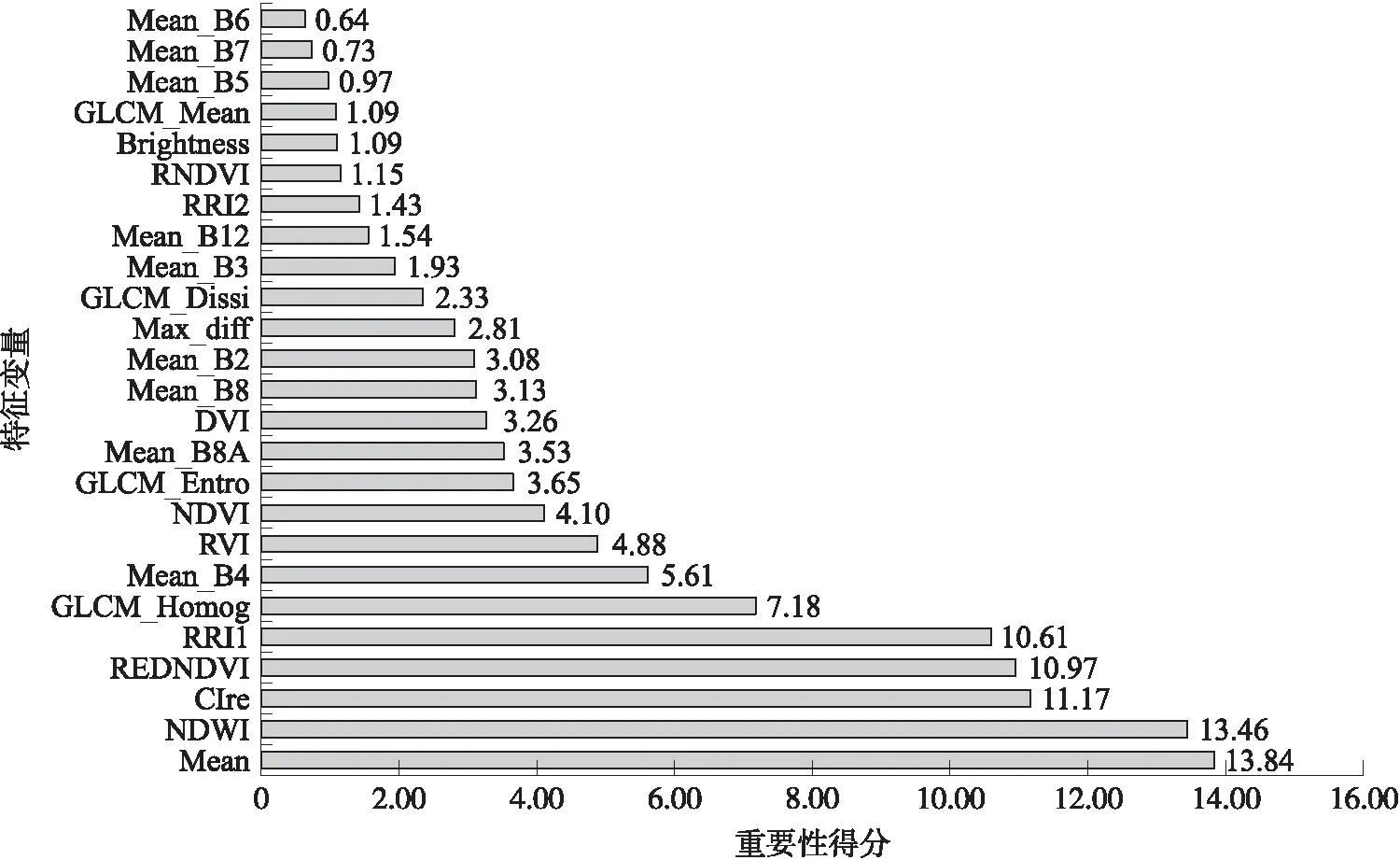
圖6 特征重要性得分圖Fig.6 Map of feature importance ranking chart
3.2 提取結果及精度評價
5種不同方案的分類結果如圖7所示,從分類圖中可以定性地判斷不同分類方案的分類效果. 方案1、方案2與方案3的分類效果較差,方案1中互花米草被錯分為堿蓬的較多,部分蘆葦也錯分為堿蓬,方案2中較多蘆葦被錯分為互花米草,方案3中堿蓬與互花米草的交錯帶被錯分為蘆葦,方案4與方案5的分類效果相比于前3種方案分類效果較好,但方案4中也有部分的蘆葦被錯分為互花米草. 在所有的分類方案中,蘆葦與互花米草交錯帶都出現了不同程度的錯分,分析原因可能是相鄰植被常常混生分布,之間沒有明確的界限,在中等分辨率的影像中常以混合像元形式存在,從而導致濕地類型的誤判斷.
對5種試驗方案的分類結果進行對比,由表3可知,方案1的總體精度為83%,Kappa系數為0.78,在所有方案里的分類精度最低. 方案2中植被指數與水體指數利用了波段之間的相互運算,分類精度有所提高. 方案3是光譜、植被指數與水體指數的綜合分類,總體精度達到了84.50%,Kappa系數提高到了0.80,分類效果進一步提升. 方案4中在方案3的基礎上加入了紋理特征,總體精度比方案3增高了0.1%. 方案5是按照特征重要性排序選出的優選組合,相比于前4種分類方案,總體精度為87.07,Kappa系數為0.84,在所有的分類方案中精度最高,分類效果較好.
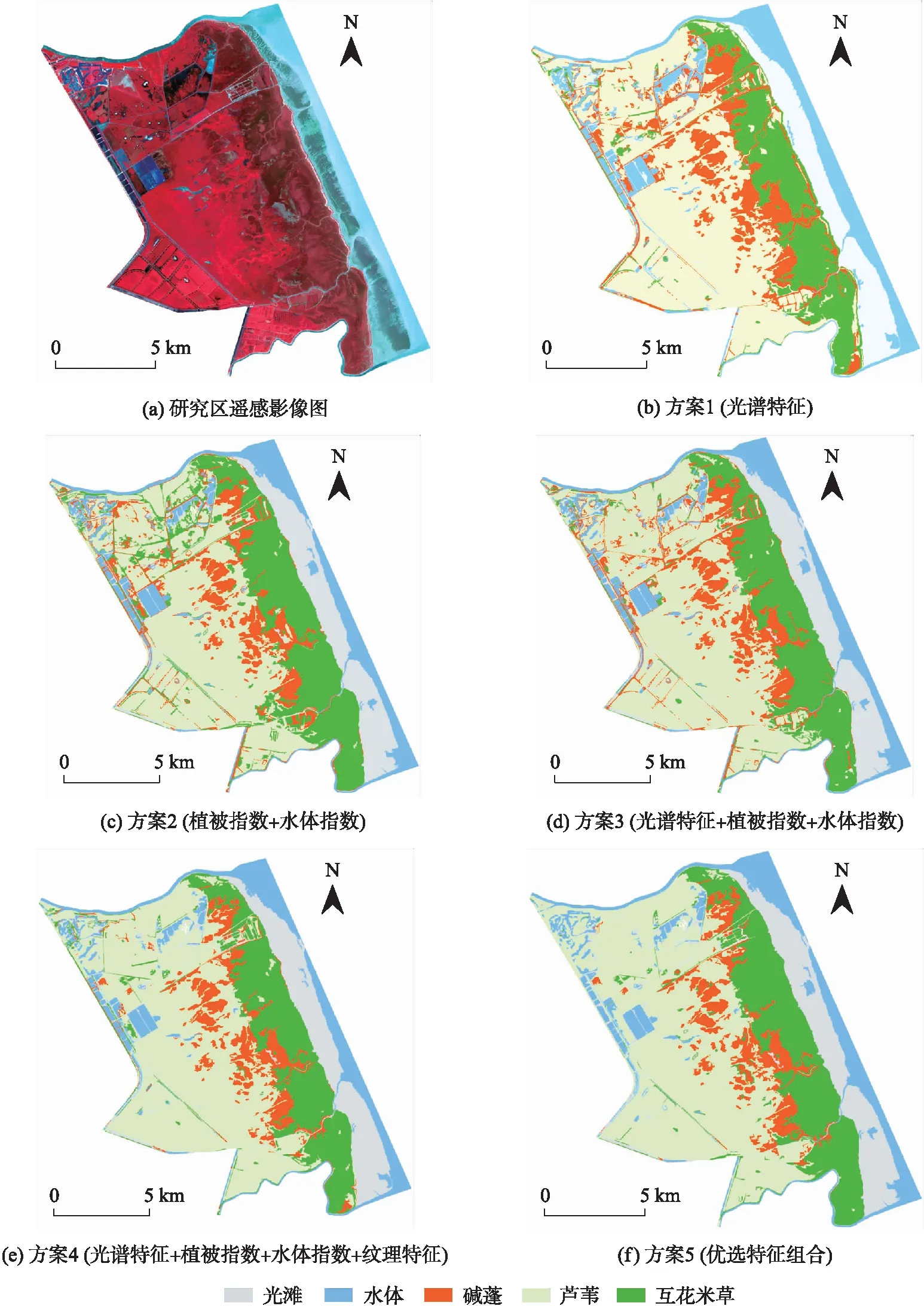
圖7 不同方案分類結果圖Fig.7 Classification results of different scenarios
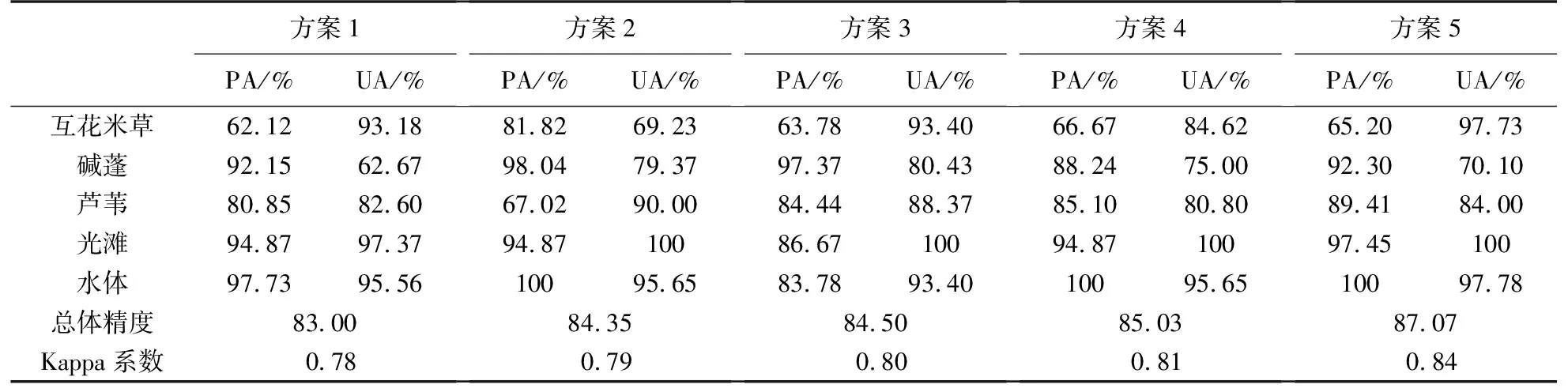
表3 分類結果精度統計Table 3 Classification results precision statistics
從植被的分類效果來看,5種分類方案中水體與光灘的分類精度均較高,這與分類圖中展現的一致. 對于植被分類精度,經過特征優選的方案5互花米草的用戶精度達到了97.73%,精度較高. 蘆葦的用戶分類精度為84%,而堿蓬分類精度較差. 本研究區內的3種植被的光譜特征較為相近,因此想通過增加分類特征進行區分,但是特征數量過多會增加數據的冗余,也不利于分類精度的提高. 通過特征優選對變量進行了部分篩選,通過分類圖來看,植被整體的分類效果較好,但對于3種植被類型交錯帶部分,因植被之間的混生分布,導致植被的分類精度有所下降.
4 結論
本研究以Sentinel-2遙感影像為數據源,通過面向對象方法進行分割,結合ESP2工具確定分割尺度為95. 在分割的基礎上計算光譜特征、植被指數、水體指數以及紋理特征4種基本特征變量,并且使用R構建隨機森林模型進行特征重要性的計算及植被分類研究. 為了研究不同特征變量的分類精度設計了 5種試驗方案,并用隨機森林算法對不同方案的分類精度進行分析. 結果表明:以光譜數據為基礎,增加不同特征變量對濕地分類的精度影響不同. 單獨以光譜數據進行分類,分類效果較差,Kappa系數為0.78. 使用植被指數與水體指數結合分類,相比于使用光譜特征分類的效果好,Kappa系數提升為0.79. 光譜特征、植被指數與水體指數共同參與分類,分類效果進一步提升. 通過特征重要性選擇出的特征優選組合相比于前4種方案,分類效果最好,總體精度為87.07%,Kappa系數為0.84. 說明基于特征優選的面向對象與隨機森林相結合的分類算法對濱海濕地植被的分類效果較好,可以用于濕地的植被分類研究.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
