用于求解粗網有限差分方程的優化并行預處理算法
2021-02-10 08:59:52劉禮勛朱凱杰郝琛李富
哈爾濱工程大學學報 2021年12期
劉禮勛, 朱凱杰, 郝琛, 李富
(1.清華大學 核能與新能源技術研究院,北京 100084; 2.哈爾濱工程大學 核科學與技術學院,黑龍江 哈爾濱 150001)
進行全堆芯三維精細化中子輸運計算必須依賴于有效的加速手段,粗網有限差分 (coarse mesh finite difference, CMFD) 方法[1]因其便于實施、加速效果好,被廣泛地應用在全堆芯輸運計算的加速算法中。然而,三維全堆芯Pin尺度的CMFD是一個大型稀疏非對稱線性方程組,其系數矩陣的規模可達到上億級別,高效求解CMFD線性方程組對實現加速至關重要。廣義極小殘差算法是求解大型非對稱線性方程組的優秀方法,但該方法的優越性取決于良好預處理技術的應用,特別是針對條件數很大或者嚴重病態的線性方程組,高效的預處理技術尤為重要[2]。針對于串行計算,不完全LU分解(incomplete LU decomposition, ILU)、對稱超松弛(symmetric over-relaxation, SOR)、塊預處理、稀疏近似逆等是很好的預處理技術[3]。但是針對于并行計算,需要采用紅黑網格策略,才能充分發揮ILU、SOR的預處理效果[4],但同時帶來的問題就是引入不必要的計算等待時間,以及使得程序開發變得異常復雜。目前在核反應堆計算領域,Block-Jacobi不完全LU分解(block-jacobi incomplete LU decomposition, BJILU) 因其實施方便而得到了廣泛的應用,如美國的MPACT程序[5],但其僅對各自CPU中的元素進行了預處理,對不同核心間需要信息傳遞的元素并未做任何預處理。Xu[6]提出了一種簡化對稱超松弛預處理技術(reduced symmetric over-relaxation, RSOR) 與不完全LU分解的混合預處理方法(RSOR and ILU, RSILU),有效解決了上述問題,但在實際應用中發現該方法有待進一步優化。
本文采用以下2種方法對現有的RSILU預處理進行了優化:1)將不完全LU分解預處理子替換為修正不完全LU分解(modified incomplete LU decomposition, MILU)預處理子,以進一步提高RSILU的預處理效率;2)由嚴格計算對角塊矩陣的逆改為近似計算,以解決RSILU方法在復雜能群結構的多群CMFD問題中,預處理計算耗時過多的問題。利用C5G7-3D基準題和VERA Problem #4基準題搭建CMFD線性方程組對優化后的RSILU方法進行了測試分析。所有測試均基于MPI并行編程模型[7],采用空間區域分解的方式進行并行計算。
1 CMFD線性方程組與GMRES算法
1.1 三維多群CMFD線性方程組
建立在Pin尺度上的三維多群CMFD方程組為:
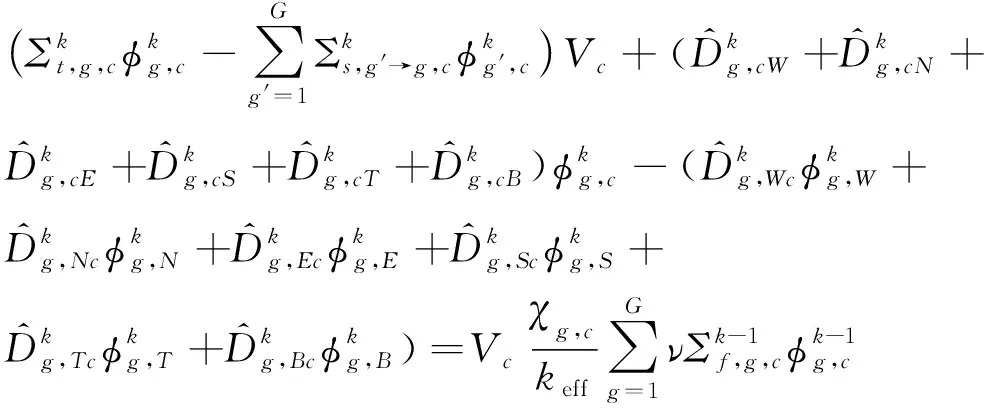
(1)
式中:φ、Σt、Σs、vΣf、χ、keff分別是中子通量密度、總截面、散射截面、吸收截面、裂變譜和有效增殖因子。式(1)在數學上可表示為線性方程組:
Ax=b
(2)
式中:未知量x即為待求的中子通量φ,按照“先能群、后空間”的順序進行排列;系數矩陣A∈Rn×n是七對角、稀疏、非對稱矩陣,其中主對角線的對角塊由能群散射矩陣構成:
(3)
式中:D為對角塊矩陣;LA和UA為嚴格非對角塊矩陣。對于能群、空間耦合求解的CMFD線性方程組;Di為G×G稠密矩陣(如圖1所示);G為能群數;LA,i和UA,i為稀疏矩陣。對幾何空間進行區域分解,并基于MPI進行分布式內存計算,此時系數矩陣A可進一步表示為:

圖1 對角塊中的散射矩陣(47群)Fig.1 The scattering matrix in diagonal block (47 groups)
A=LI+LP+D+UP+UI
(4)
式中:LP和UP是存儲在當前CPU內的嚴格非對角塊,LI和UI是存儲在不同CPU內的嚴格非對角塊,如圖2所示。
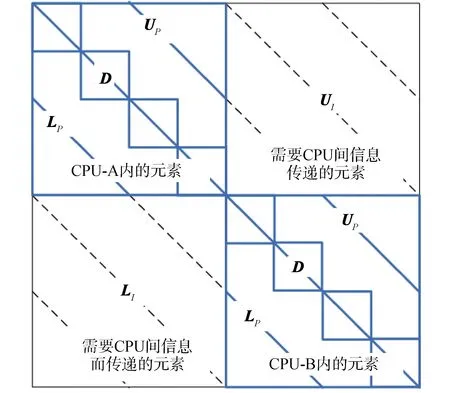
圖2 CMFD線性方程組系數矩陣Fig.2 Coefficient matrix of CMFD linear system
1.2 預處理GMRES算法
廣義極小殘差算法(generalized minimum residual method, GMRES)是求解非對稱線性方程組的有效方法,該方法是Krylov子空間法的一種,通過在子空間上進行投影以迭代的形式尋找近似解。記r0=b-Ax0為初始殘差向量,由r0生成的Krylov子空間可表示為:
Km(A,r0)=span{r0,Ar0,A2r0,…,Am-1r0}
(5)
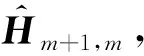
(6)
GMRES方法在Krylov子空間中產生一系列近似解,這些近似解逐步逼近于真解,同時這些近似解的殘差向量rm滿足二范數最小的性質。rm可表示為:
β=‖r0‖2
(7)
經過m步GMRES算法形成近似解xm滿足:
xm=x0+Vmym
(8)
其中ym∈Rn通過極小化式(9)得到,即:
(9)
GMRES方法的優越性取決于良好的預處理技術的應用,特別是針對條件數很大或者嚴重病態的線性方程組,高效的預處理技術尤為重要。預處理的本質是對線性方程組(2)作同解變換,以右預處理為例:
(10)
式中M為預處理子(預處理矩陣)。本文中采用右預處理GMRES算法求解CMFD線性方程組[8],右預處理GMRES算法如下:
算法1:右預處理GMRES算法
1) 選取初值x0∈Rn, 計算初始殘差r0=b-Ax0, 定義β=‖r0‖2,v1=r0/β
2) Forj=1, 2, …,mDo
3) 計算w:=AM-1vj
4) Fori= 1, 2, …,jDo

7) End Do
8) 計算hj+1,j=‖w‖2,vj+1=w/hj+1,j

10) End Do
12) 計算xm=x0+M-1(Vmym)
13) 如果滿足收斂標準則停止;否則置x0:=xm并轉向1。
2 RSILU預處理算法及其優化
2.1 RSILU預處理子
預處理矩陣M的選取對GMRES收斂速率影響極大。文獻[6]提出了高效的RSILU混合預處理方法,該方法由RSOR和ILU預處理子共同構成,不僅對各自CPU中的元素進行了預處理,還對不同CPU間需要信息傳遞的元素也進行了預處理,如圖3所示。其中,RSOR高效預處理不同CPU間需要信息傳遞的元素,RSOR預處理子為:
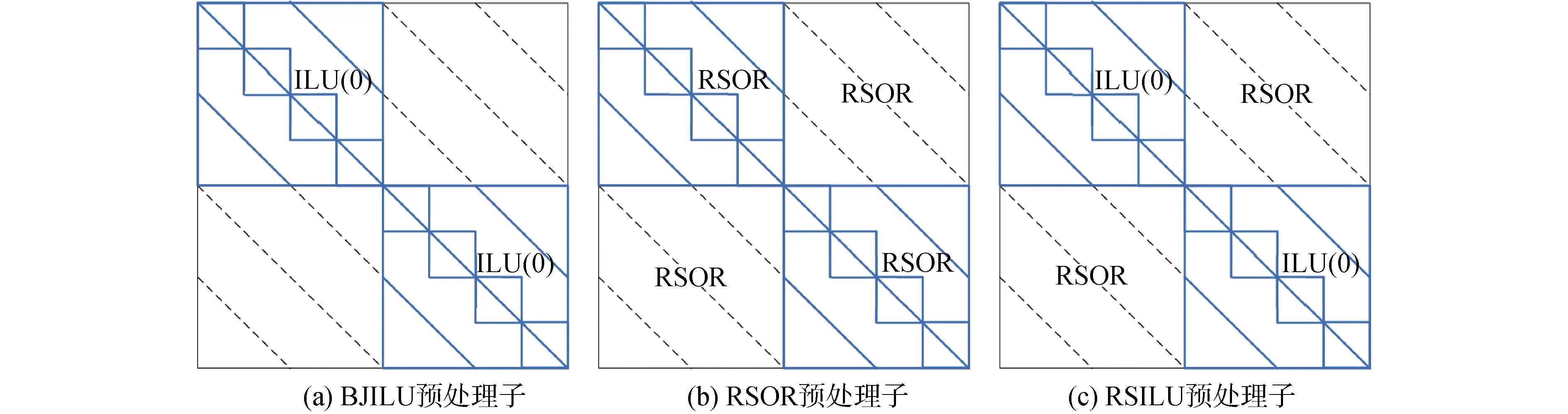
圖3 不同預處理算子示意Fig.3 Diagram of different preconditioner
(11)
式中ω為松弛因子。RSOR不需要紅黑網格技術,便于實施,并且當核數的增加時GMRES所需的迭代次數保持不變,同時還能保證解的對稱性,是一種簡單高效的并行預處理算法,更多詳細內容可參考文獻[6]。
ILU高效預處理各自CPU中的元素,ILU(0)預處理為:
(12)
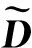
(13)
結合式(11)和式(12),RSILU預處理為:
ω(LI+UI)D-1]
(14)
為減少RSILU預處理實施過程中的存儲和計算負擔,使用DE替換上式中的D,D為DE的對角元素。最終RSILU預處理子可定義為:
ω(LI+UI)DE-1]
(15)
2.2 RSILU預處理算法的實施步驟
算法2:z=M-1v
2)將w1傳遞給其他CPU,以用于并行計算
3)計算w2=v-ω(LI+UI)w1

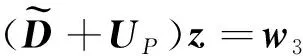
2.3 優化的RSILU預處理算法
2.3.1 MILU替換ILU
(16)
2.3.2 對角塊矩陣的近似求逆
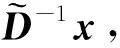
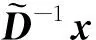
3 預處理效果驗證
為驗證優化后的RSILU算法的預處理效果,本文基于C語言開發了預處理GMRES求解器,并選用C5G7-3D基準題[9-11]和VERA Problem #4基準題[12]搭建pin尺度單群/多群CMFD線性方程組作為測試題(見表1),其中單群CMFD通過對多群CMFD進行能群歸并得到[9],單群CMFD方程組的系數矩陣沒有對角塊,是一個傳統的7對角矩陣。為了后續表述更簡便,優化前的RSILU算法用RSILU-old表示,優化后的RSILU算法用RSILU-new表示。

表1 CMFD線性方程組介紹Table 1 CMFD linear system information
預處理GMRES選用相對殘差10-8作為收斂標準。串行計算環境:Inter(R) Core(TM) i5-7200U CPU@2.71Hz, RAM 8.0GB;并行計算環境:“天河一號”超級計算機,采用商用InfiniteBand網絡連接,每個計算節點包含28個計算核心(14個2×Intel Xeon CPU E5-2690 v4 @2.60 GHz),RAM 128 GB。編譯器選用英特爾編譯器Intel-16.0.3;MPI編譯環境選用mvapich2-2.2。
3.1 C5G7-3D基準題
3.1.1 串行計算
圖4中給出了串行環境下,RSOR、RSILU-old和RSILU-new預處理GMRES求解一次C5G7-3D單群/多群CMFD線性方程組的迭代次數和計算時間。由圖4可知:
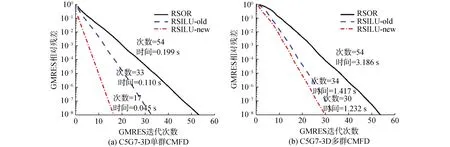
圖4 不同預處理算法下串行GMRES的收斂歷史Fig.4 Convergence history of serial GMRES method preconditioned by different preconditionor
1) 3種的預處理算子中,RSILU-new收斂最快,計算用時也最少,RSILU-old次之,最次是RSOR;
2) RSILU-new針對單群CMFD的預處理效果要優于多群CMFD。單群CMFD下RSILU-new預處理效果顯著優于RSILU-old;多群CMFD下RSILU-new的預處理效果略優于RSILU-old。
3.1.2 并行計算
圖5和圖6給出了不同核數下BJILU、RSILU-old和RSILU-new預處理GMRES求解C5G7-3D單群/多群CMFD線性方程組的迭代次數和計算時間。圖7和圖8分別給出了不同核數下RSOR、BJILU、RSILU-old、RSILU-new、和串行ILU(SILU)預處理GMRES求解C5G7-3D單群/多群CMFD線性方程組的殘差收斂歷史。其中,SILU是指GMRES在串行環境下用ILU(0)作預處理時的收斂結果,用作對照,以顯現出各種預處理算法在并行核數逐漸增加時的預處理效果的變化趨勢。
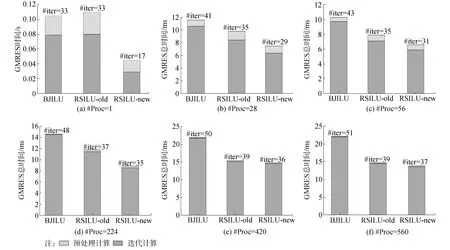
圖5 不同預處理算法下并行GMRES求解C5G7-3D單群CMFD計算時間比較Fig.5 Computing time of parallel GMRES preconditioned by different preconditionor for one-group CMFD of C5G7-3D

圖6 不同預處理算法下并行GMRES求解C5G7-3D多群CMFD計算時間比較Fig.6 Computing time of parallel GMRES preconditioned by different preconditionor for multigroup CMFD of C5G7-3D

圖7 不同預處理算法下并行GMRES求解C5G7-3D單群CMFD收斂歷史比較Fig.7 Convergence history of parallel GMRES preconditioned by different preconditionor for one-group CMFD of C5G7-3D

圖8 不同預處理算法下并行GMRES求解C5G7-3D多群CMFD收斂歷史比較Fig.8 Convergence history of parallel GMRES preconditioned by different preconditionor for multigroup CMFD of C5G7-3D
不同預處理算法比較如圖5~8所示,可知:
1) 隨著并行核數的增加,RSILU-old、RSILU-new和BJILU的預處理GMRES計算時間逐漸減少,GMRES迭代次數逐漸增加,但迭代次數隨核數的增長地很緩慢;
2) 隨著并行核數的增加,RSILU-old和RSILU-new的預處理效果的差距不斷縮小,但RSILU-new效果始終不差于RSILU-old,且始終優于BJILU;
3) RSILU-new針對單群CMFD的預處理效果要優于多群CMFD,且RSILU-new針對單群CMFD的預處理效果甚至可以超過SILU (如圖7中的(a)~(c)所示)。
3.2 VERA problem #4 基準題
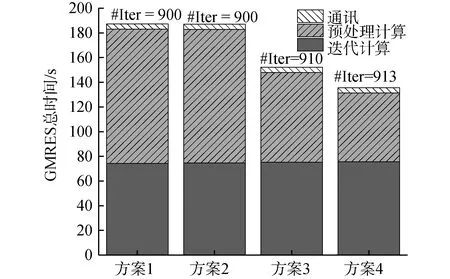
圖9 不同計算方案下的RSILU-new預處理并行GMRES用時Fig.9 The calculation time of RSILU-new preconditioned parallel GMRES method with different strategy
BJILU、RSILU-old和RSILU-new預處理效果的測試結果如表2和圖10所示。從結果中可以看出:不論是單群CMFD還是多群CMFD、BJILU和RSILU-old相比,RSILU-new預處理效果都是最優的,不僅GMRES的迭代次數是最少的,而且迭代計算和預處理計算的耗時也是最少的。其中,RSILU-new的預處理計算耗時僅是RSILU-old的1/2左右。整體GMRES的計算耗時相比于優化之前減少30%。
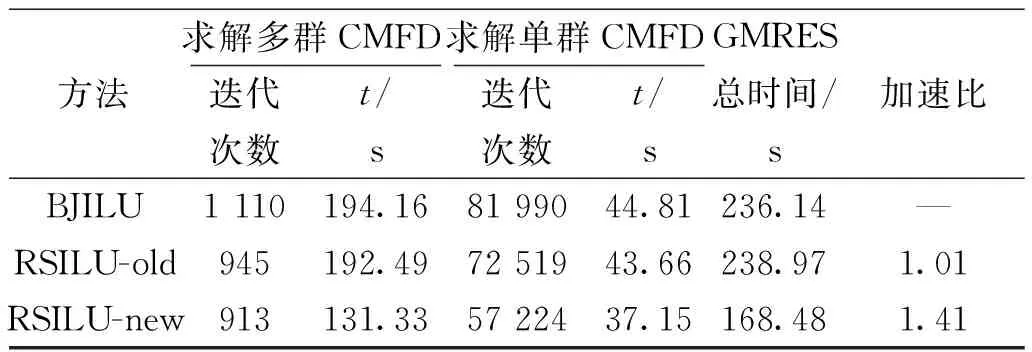
表2 BJILU、RSILU-old和RSILU-new預處理并行GMRES完整求解VERA problem #4基準題Table 2 BJILU, RSILU-old and RSILU-new preconditioned parallel GMRES for solving VERA problem #4 benchmark

圖10 BJILU、RSILU-old和RSILU-new預處理GMRES用時Fig.10 The calculation time of GMRES precoditioned by BJILU, RSILU-old and RSILU-new
3 結論
1)優化后的RSILU彌補了該方法之前的一些缺陷,進一步提高了RSILU預處理并行GMRES方法求解大規模CMFD線性方程組的計算效率。
2)本文中的并行GMRES算法僅基于MPI編程模型,未來可開發MPI和OpenMP混合并行編程技術進一步減少處理器間的通信時間,從而提高并行效率。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中老年保健(2021年12期)2021-11-30 02:58:01
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
