數據中心網絡中基于ELM 的流簇大小推理機制
2021-02-05 18:10:44謝紫琪肖慶宇李曉歡
計算機與生活 2021年2期
葉 進,謝紫琪,肖慶宇,宋 玲,李曉歡
1.廣西多媒體通信與網絡技術重點實驗室(廣西大學計算機與電子信息學院),南寧 530004
2.桂林電子科技大學信息與通信學院,廣西桂林 541004
3.綜合交通大數據應用技術國家工程實驗室(廣西),南寧 530001
目前,社交網絡和網頁搜索等大規模網絡應用部署在數據中心,產生大量異構任務流。網絡測量數據表明,數據中心中任務流數據傳輸延時實際占應用完成時間的70%[1-2]。如何設計高效的混合任務流調度方法已經成為了提升數據中心應用性能的關鍵。
在數據中心分布式計算模式下,一個任務所傳輸的所有流應該被當作一個整體來實施調度。根據應用的語義,同一個任務內流的聚合為一個流簇(Coflow)[3]。從設計角度考慮,流簇調度器需要感知應用級的需求和特征,優化網絡的利用率以加速任務的傳輸。
在信息未知的流簇調度設計中,調度器缺乏流簇大小的先驗知識,而是采用推理機制來獲取任務信息,但流簇大小推理的精確度會極大地影響流簇調度的效率。例如,D-CLAS(discretized coflow-aware least-attained service)[4]通過統計已傳輸字節數推斷流簇的大小。但這種被動的方法只有當傳輸開始一段時間后才能檢測出流簇的字節數,而此時較小的流簇很可能已經被較大的流簇阻塞,導致了較大的平均任務完成時間。MCS(multiple-attributes-based Coflow scheduling)[5]在D-CLAS 的基礎上進行了改進,引入了流簇寬度(流簇內包含的子流數)和流簇長度(流簇內子流中最長子流的字節數)兩個特征,通過貝葉斯概率算法推理流簇的大小。然而,在分布式計算模式下調度器很難快速準確感知MCS 的方法所依賴的流簇寬度信息。此外,目前設計的流簇大小推理方法僅針對于其分析的數據集,沒有一種能廣泛適用的推理模型建模方法。
實際上數據中心執行的大部分任務都是重復的,可以從歷史日志中學習混合多任務的特征,進而對流簇大小等任務特征進行推理。因此本文提出了一種基于極限學習機的流簇大小推理方法(machine learning Coflow,MLcoflow),主要貢獻在于:
(1)基于FaceBook 數據中心日志的數據挖掘,進行各個特征的權重計算,建立了流簇大小的關聯特征集,利用極限學習機訓練獲得了多特征融合的推理模型。
(2)將MLcoflow 部署到最短任務優先(shortest job first,SJF)的流簇調度器中[6],和現有的流簇調度器相比,降低了20%的流簇平均完成時間。
(3)由于MLcoflow 使用的流簇特征可以從調度中得到,不需要大規模手動修改應用,因此它可以很容易地部署到各類數據并行框架中如MapReduce、Hadoop 和Spark 等。
本文給出了基于極限學習機的MLcoflow 分類器的詳細設計,實驗證明其在流簇大小推理的準確率、敏感度及適用性上均具有優勢,是一種基于數據驅動的流簇推理的高效機制。
1 相關工作
流簇調度通過給流簇分配適合的優先級和帶寬來提升網絡傳輸的效率。現有的流簇調度方法可以分為兩類:
(1)信息已知流簇調度
信息已知的流簇調度假設調度時所有關于流簇的先驗信息都可以被調度器獲取,因此這類調度器在模擬實驗中通常能表現出較為卓越的性能。如Varys[7]采用分布式調度算法來提高調度性能,通過一個集中式控制器基于最小效率瓶頸優先算法給網絡中的流簇分配速率。Sincronia[8]使用貪婪式的速率分配方法為網絡中的流簇分配不同優先級,它證明了在正確設置流簇優先級的情況下可以實現近似最優網絡設計。然而,Coflow 是一組來自不同源的并行流集合,這些流通常是異步的,這意味著它們不同時開始。因此在調度中獲取先驗信息在現有的并行計算框架中是難以實現的[9]。部署這類調度器通常需要對現有的應用進行大規模手動修改[10],這導致這類調度器難以廣泛使用。
(2)信息未知流簇調度
信息未知流簇調度器不需要任何先驗信息,它們通過調度中獲取的流簇特征來執行調度。其中比較經典的調度器設計包括:D-CLAS,它首個提出信息未知調度設計,通過設置已傳輸字節數閾值為流簇分配優先級;MCS 通過多種流簇特征及貝葉斯概率論來推測流簇的大小并基于最小最短流簇優先算法為流簇分配優先級。然而,現有的信息未知調度器大部分采用經典的SJF 策略,這種策略有兩個目標:一是從小流簇(總傳輸字節數較少的流簇)中把大流簇篩選出來;二是給小流簇高優先級。這兩個目標能保證調度器實現降低平均流簇完成時間的目的。為實現這個目標,調度器必須能準確地推理流簇的大小,不準確的推理可能會導致隊頭阻塞,從而降低傳輸效率。
此外,很多工作已經證明了機器學習算法在流大小推理應用中的有效性和可行性。例如,文獻[11]通過數據挖掘和機器學習算法,基于歷史數據和在線信息,使用一條流中前幾個包的特性(例如包大小和包頭信息)來預測每個流啟動時的大小,主要目的是為了檢測大象流。文獻[12]設計了一個可以事先估計流大小的框架FLUX,并通過機器學習方法預測流大小并標記數據包讓交換機可以感知流的大小信息,最后使用真實實驗驗證了FLUX 在真實環境中的可實現性和部署性。上述研究證明了機器學習方法在流大小預測中的可行性,這些研究也僅僅是針對流模型。雖然FLUX 將其方法用于流簇模型中,但是流簇是多條流的集合,這意味著這種方法只能通過流大小疊加來實現流簇大小推理,這會導致錯誤率的疊加從而大幅度降低推理精度。因此,設計了針對數據中心任務特征的流簇大小推理模型。
2 研究動機
流簇信息未知調度器應當同時考慮準確率和敏感度這兩方面。一般而言,準確率代表了有多少流簇能被準確推理出其所在大小的分類區間,而敏感度代表了準確推理流簇大小需要多少已知信息。流簇大小的準確率一直是關鍵指標,但現有的推理方法在設計中都忽略了敏感度的問題。式(1)給出了關注的流簇大小推理的敏感度。
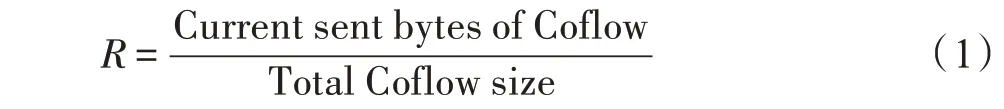
R表示推理器用來計算流簇特征使所使用的子流數占流簇總子流數的比例。本文將敏感度定義為準確率達到1.0 時R的取值,該值越小推理方法敏感度越高,該值為1.0 意味著推理方法完全失敗。
本章用一個例子揭示推理敏感度的重要性。圖1給出了基于SJF 策略的調度器在不同敏感度推理器下的流簇調度情況。圖1(a)和(b)描述了流簇傳輸場景和信息。為簡化問題,在這里只考慮流簇大小的相對關系,此例推理的結果只有優先級高、中、低三種情況。
假設:流簇大小≥4 units 時為低優先級,3 units≤流簇大小<4 units 時為中優先級,流簇大小<3 units時為高優先級。
圖1 描述了三種敏感度下的調度情形,圖1(c)描述了直到流簇傳輸結束后都無法完成推理,因此調度器無法發現三條流之間的優先級,只能按到達順序傳輸。圖1(d)描述在數據傳輸到一半時推理出優先級,因此推理器會在T=2.5 時推理出C1 屬于低優先級,暫停C1 轉而開始傳輸C2 ;在C2 傳輸一半的數據時推理出C2 屬于中優先級,轉而開始傳輸C3。圖1(e)描述了當流簇到達時就能進行區分的情形,當C2 到達時先傳輸C2,而當C1 達到時,先進行C1的傳輸。上述三種情況平均流簇完成時間分別為7.333、5.833 和4.667,最理想的情況平均流簇完成時間比最差情況的完成時間減少了近36%。可見推理敏感度將對平均流簇完成時間產生影響,在設計推理器時需要同時考慮準確率和敏感度。但推理器在真實的工作環境中只能利用不完全信息,實現較高敏感度的推理是一個挑戰。本文旨在結合任務特征,通過數據驅動式機器學習,設計考慮敏感度的推理機制及其調度算法。
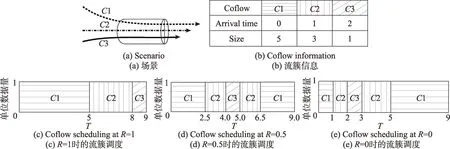
Fig.1 Impacts of inferring sensitivity圖1 推理敏感度的影響
3 總體思路
本文設計了MLcoflow 調度機制來對流簇實施調度,以降低平均任務的完成時間。圖2描述了MLcoflow的工作流程。
推理器的輸入是當前核心交換機采集的流簇信息,如當前包含子流數和到達時間等。推理器會首先處理這些信息,從中篩選強關聯的特征集,作為推理模型的輸入。離散化流簇大小能夠加快模型的訓練速度,并且使得推理器容易部署。因此將推理模型設計為一個多分類器,推理器將分類結果返回給調度器,據此執行優先級調度。
推理模型將周期性地基于數據中心網絡的歷史日志進行更新,更新后的模型會被發送至推理器進行在線應用。本文中的周期設定為流到達間隔的2至3 倍,符號為H。為了提高推理算法的敏感度,離線訓練中僅使用不完全信息,即流簇內一半的子流信息來挖掘流簇特征。
本文的推理器將基于FaceBook 數據中心發布的日志進行建模[5],在實際應用中它會通過采集數據中心網絡中任務執行的歷史日志,篩選與流簇大小相關的特征集合。MLcoflow 使用了極限學習機建立推理模型。本章詳細描述了基于數據挖掘的特征提取及流簇大小的多分類建模,最后給出了基于該推理器的調度算法。
3.1 特征提取
為了提升推理的準確性和敏感度,首先需要確定信息未知場景下的可用特征集合。然而,過多的特征信息可能會占用大量的存儲空間和計算時間,甚至影響訓練模型的收斂性。因此在建模前篩選并去除多余的特征是很重要的。
為簡化問題,數據中心的抽象模型為一個無阻塞交換機連接所有主機,調度器僅工作于交換機的出入端口處。因此流簇調度和帶寬分配也僅在交換機端口處進行,這是流簇相關研究中最常用的抽象模型[4-8]。
和傳統的流抽象模型不同,流簇是一組流的集合,每條流的特征由一個四元組表示。使用Multi-RELIEF[13]方法來篩選特征,它計算每個特征對于推理貢獻的權重,通過FaceBook 數據中心日志來分析計算各個特征的權重。為了更好地對比,特征的權重值被歸一化后列于表1 中。歸一化的權重值相當于該特征對正確推理的貢獻,值越大說明該特征越重要。選擇了歸一化權重值大于0.01 的特征(如表1中1 至6 行所示),最終選取的Coflow 特征集為一個六元組,如式(2)所示。

在實際應用中流簇特征由實時狀態確定,它們是累計值,將隨著流簇子流的到達率而改變。在表1中“~”用于定義實時值,如。
3.2 推理建模
這里考慮用極限學習機(extreme learning machine,ELM)[14]來生成推理模型,它是一個單隱層前饋神經網絡,不需要手動設置太多的參數,訓練速度快,泛化性能好,比較適用于數據中心這種實時性要求強的環境。
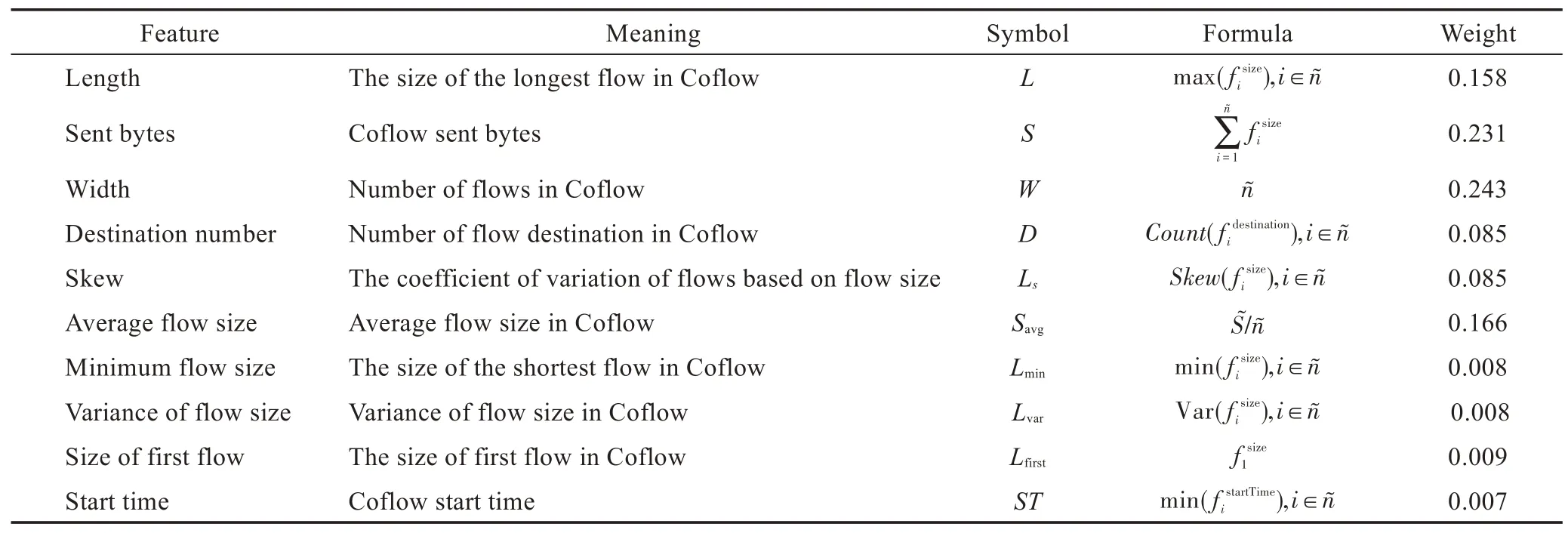
Table 1 Features and their normalized weighted values表1 特征及其歸一化權重值
在數據預處理階段,歷史流簇信息日志被分為兩個集合,訓練集和測試集。由于分類是由流簇大小確定的,不同分類之間存在邏輯聯系,因此訓練集的標簽使用Label-encoding 處理。此外,本文使用Zscore標準化方法處理
典型的ELM 結構包括了一個輸入層、輸出層和隱藏層。輸入層包含n個神經元,n的值為輸出層包含m個神經元,m相當于多分類的分類數。
隱含層包含了k個神經元,激活函數的初始化是隨機的,在本文的設計中,激活函數為Sigmoid,式(3)給出了該函數的定義,其中x為ELM 的輸入:
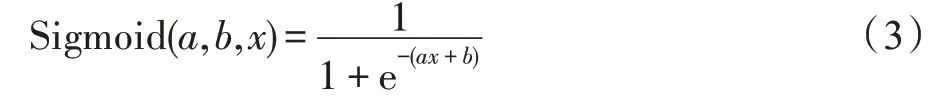
通過多個實驗驗證了參數a、b、k的最佳設置。圖3 給出了不同a、b和k下的模型測試錯誤率。
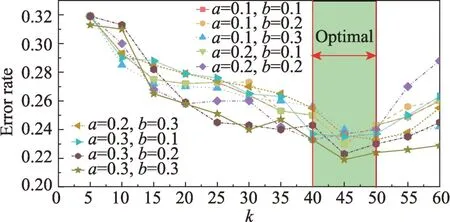
Fig.3 Parameters optimization experiment圖3 參數優化實驗
可以看到,當a和b值改變時,k的最佳參數設置總位于40 到50 之間,因此在本文的實驗中選擇將k值設置為45。同時可以發現,a和b值的改變對結果影響不大,通常為了保證模型泛化性能,它們在ELM中也是隨機設置的,因此設置a、b服從隨機分布N=(μ,σ2),μ=0,σ=1.0。
和其他工作類似,流簇大小可以離散成多個分類[4-6]。本文分析了來自FaceBook 數據中心Hive/MapReduce 數據倉庫真實的日志及其流簇大小的分布,圖4 給出了本文統計得出的流簇大小累積分布函數(cumulative distribution function,CDF)圖,圖中可見它近似于指數分布。

Fig.4 CDF of Coflow size and classification periods圖4 流簇大小的CDF 圖及分類區間
在這種分布中,如果使用平均分割法會導致某些分類中的流簇數目很少甚至沒有流簇,因此選擇了根據CDF 分布來進行流簇分類。
在調度中每個分類將被映射一個優先級隊列,假設存在有m個分類,那么優先級隊列集合就為Q={Q1,Q2,…,Qm},則有流簇C屬于某一隊列Qi(i∈[1,m])的條件為:

其中,CS代表流簇C的預測大小。本文假設流簇的大小分布服從函數y(x),如下所示:

通過擬合分布曲線得到c=1.5×106,a=-11,且本文中m設置為8。
3.3 流簇調度
基于MLcoflow 的調度器將根據推理結果給流簇分配優先級。算法執行過程中,Agent 從當前端口的流簇信息中提出流簇特征并將其發送給位于核心控制器處的Master,Master 通過使用MLcoflow 推理流簇的大小并將推理結果返回給Agent。收到結果后,部署在Agent 處的調度器會根據推理結果給流簇分配優先級隊列。
MLcoflow 調度算法如算法1 所示。新流簇到達交換機后調度器會提取該流簇的特征集并使用推理器推理流簇的實際大小及該大小的流簇所屬的分類,通過其大小所屬分類為流簇分配優先級隊列。對于n個流簇,該算法的時間復雜度為O(n)。
當前的數據中心流量大,且流量行為變化復雜[15],因此為了保證模型推理的準確性和對環境變化的適應性,算法中設置了觸發標志F作為定期更換新模型的觸發機制,當F為真時Agent 里的調度器會詢問本地存儲器是否存在新的模型,若存在則進行模型更新。F的值變化判斷條件由應用層決定。

4 仿真實驗
將MLcoflow 的性能評估分成兩部分:第一部分評估推理方法的準確性和敏感度;第二部分評估基于MLcoflow 調度器的性能。
4.1 推理算法的對比
本節對比了ELM算法和其他兩類機器學習算法,包括:
(1)CART(classification and regression trees)[16],一種常用的決策樹算法,使用基尼指數來分割數據。在CART 中樹的深度限制為6,典型設置為3~10 之間,發現設置為3 太淺導致準確率較低,而設置為10太深導致過擬合,因此選擇了一個中間值。
(2)XGBoost(extreme gradient Boosting)[17],一種基于梯度增強的集成學習算法。在XGBoost 中,設置了100 個分類器,每個分類器的深度限制為6。
數據預處理中,它們的標簽方式都和ELM 相同,而特征集在CART 和XGBoost 中保持原始數據。使用的數據集一部分取樣自FaceBook 數據中心的日志,用FB 表示。此外,另一部分由一個流簇日志生成器[18]生成,它通過分析FB 數據集的特征來生成新的日志,用Custom 表示,Custom 后的數字表示數據集包含的流簇數目。
由于本文的模型是一個多分類模型,一些傳統的模型評估基準(如F1score 和準確率)不再適用,因為它們不夠全面。本文采用Macro-F1score(MaF1)和Micro-F1score(MiF1)來評估本文的模型[19]。MaF1對所有分類的權重相等。而MiF1 對每個實例有相同的權重,因此數量較多的類別對該分數的影響更大。采用十折交叉驗證法測試數據。表2 給出了三種算法在不同測試集中的測試結果。
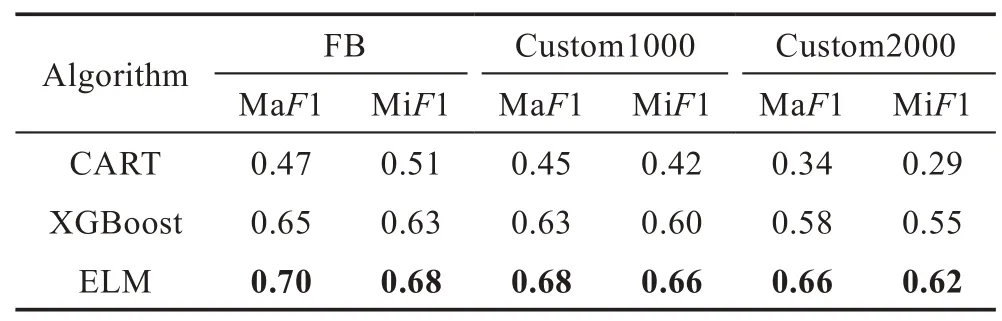
Table 2 Test results of MaF1 and MiF1表2 MaF1 和MiF1 測試結果
可以看到測試集上的結果與訓練集FB 的結果相比出現了變化,所有算法的評分都出現了不同程度的下降。總體而言,CART評分下降了35.4%,XGBoost的評分下降了11.7%,而ELM 的評分僅下降了7.3%,相比CART 和XGBoost,ELM 的平均分數分別提高37.6%和9.2%。和其他兩個算法相比,ELM 的兩個分數都表現最優,且分數變化最小證明其泛化能力較好。
本文使用FB 測試了三種算法生成模型的推理敏感度,結果如圖5 所示。R<0.7 時,ELM 具有明顯的優勢,從R=0.7 開始,XGBoost的敏感度才接近ELM,顯而易見CART 的敏感度是最差的。若以0.9 的準確率定義敏感度,則ELM 和XGBoost的敏感度相近,若以小于0.9 的準確率定義敏感度,則ELM 存在明顯的優勢。相比其他兩種算法,ELM 的敏感度平均提高了10.2%以上。

Fig.5 Inferring sensitivity of three algorithms圖5 三種算法的推理敏感度對比
圖6(a)給出了三種算法的訓練時間(樣本量100~1 000),圖6(b)給出了測試(推理)時間(樣本量1 000~10 000)。可以看出,ELM 的耗時低于XGBoost 高于CART,但是其訓練時間及測試時間都在100 ms 以內,能夠滿足絕大多數數據中心的處理需求。
綜上,CART、XGBoost 與ELM 均能夠在大多數數據中心的在線流簇調度中使用,因為它們準確、敏感,訓練和測試速度快。但是,CART 的準確率和敏感度均比較低,難以滿足要求較高的數據中心。而XGBoost作為Boost框架算法,其模型結構比較復雜,導致部署的復雜性高,開銷較大。因此認為ELM 具備更好的廣泛適用性。

Fig.6 Time cost comparisons of three algorithms圖6 三種算法的耗時對比
4.2 調度性能對比
本文使用日志驅動的仿真器[4]評估流簇調度的性能,該仿真器內置了許多傳統流簇調度器如DCLAS,它是流簇相關研究[5-8]中最常用的實驗工具。在這個模擬器上,實現了MCS、基于MLcoflow 的SJF策略調度器。實驗網絡拓撲如圖7 所示,它是一個廣泛應用于各類數據中心的Leaf-spine 結構[20],由144臺服務器組成。
本文將基于MLcoflow 的調度器與以下三個流簇調度器進行對比:
(1)先入先出(first in first out,FIFO)[4],最基礎的流簇調度方法,根據流簇的到達順序(即表1 中的ST)傳輸流簇。
(2)D-CLAS,根據已傳輸字節數S推理流簇的大小,優先傳輸小流簇。
(3)MCS,根據流簇寬度W、已傳輸字節數S和長度L來推理流簇的大小,優先傳輸最小最窄的流簇。

Fig.7 Network topology圖7 網絡拓撲
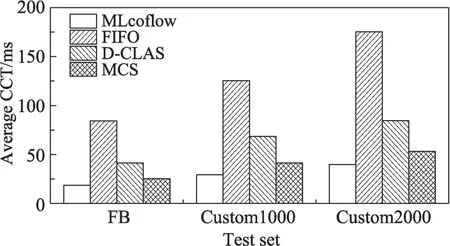
Fig.8 Average CCT of four coflow schedulers圖8 四種流簇調度器的平均流簇完成時間
圖8 顯示了它們在不同測試集中的平均流簇完成時間(average coflow completion time,Average CCT)。
從結果可以看出,MLcoflow 與MCS、D-CLAS 相比,平均降低了15~20 ms 的平均CCT。而且隨著測試集規模的增大,MLcoflow 的優勢變得更加明顯,因為同一時間需要調度的流簇增加了,同時也導致推理錯誤時產生的代價更大。性能最差的是FIFO,因為它的調度沒有基于流簇的整體特性進行優先級設置。
5 結束語
本文提出了一種基于ELM 的流簇大小推理模型,它利用多種特征推理流簇大小。該推理方法具有較高的準確率和敏感度,基于MLcoflow 的流簇調度器可以有效降低平均流簇完成時間。由于該模型不需要對應用程序進行大規模人工修改,僅基于數據中心網絡歷史日志即可建模,因此具備較好的可行性。通過同其他幾種機器學習算法的分析和比較,可以看到ELM 是一種具有廣泛適用性的推理算法。在未來的工作中,將考慮更多類型的機器學習算法,如無監督學習算法和增強學習算法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
