基于深度學習的圖像語義分割技術綜述
2021-02-04 06:54:04
軟件導刊 2021年1期
(廣東技術師范大學計算機科學學院,廣東廣州 510000)
0 引言
近年來,圖像在目標檢測、圖像分類、分割以及識別等方面的應用越來越廣,其中圖像分割技術是根據相似性原則將圖像分成若干個不同特性區域的過程。圖像分割方法大致可分為3 類:基于圖論的方法、基于像素聚類的方法與語義分割方法,而圖像語義分割是以像素共同點為分割依據,從像素級別處理圖像[1]。語義分割是場景理解的基礎性技術,對智能駕駛、機器人認知層面的自主導航、無人機著陸系統以及智慧安防監控等無人系統具有至關重要的作用。
1 傳統語義分割方法
傳統圖像分割是根據灰度、彩色、空間紋理等特征將圖像劃分成若干個互不相交的區域,使得這些特征在同一個區域內表現出一致性或者相似性,而在不同的區域間表現出明顯不同。其方法主要分為以下幾類:基于閾值的分割方法、基于區域的分割方法、基于邊緣的分割方法等。閾值分割方法是常用的分割技術之一,其實質是根據一定的標準自動確定最佳閾值,并根據灰度級使用這些像素以實現聚類。基于區域的分割方法是以直接尋找新區域為基礎的分割技術,可分為區域生長和區域分裂合并兩種基本提取方式。區域生長以單個像素點為基礎,將具有相似特征的像素點聚合到一起形成區域,其計算簡單,對于均勻分布的圖像具有良好效果。區域分裂合并從整體圖像出發,通過像素點之間的分裂得到各子區域,四叉樹分解法就是其典型代表方法。基于邊緣檢測的分割方法通過檢測不同區域邊緣分割圖片,最簡單的邊緣檢測方法是并行微分算子法,它利用相鄰區域的像素值不連續的性質,采用導數檢測邊緣點。傳統方法多數通過提取圖像的低級語義,如大小、紋理、顏色等。在復雜環境中,應對能力與精準度遠沒有達到要求。
2 深度學習與傳統方法相結合的圖像語義分割
隨著深度學習技術的發展,深度學習模型開始與傳統語義分割方法相結合,即在利用傳統方法分割出目標區域的基礎上,進一步采用卷積神經網絡等方法學習目標特征并訓練分類器,對目標區域進行分類,從而實現目標區域的語義標注[2]。卷積神經網絡模型的提出,為圖像語義分割與深度學習的結合奠定了基礎,使得圖像語義分割技術應用于多個應用領域。卷積神經網絡使用卷積層—激活函數—池化層—全連接層的運行結構,輸入圖像經卷積層聚攏不同局部區域特征,通過激活函數(Sigmoid、Relu、Tanh 等)部分激活,部分抑制從而強化特征。池化層在不改變目標對象的基礎上,使輸入圖片變小,減少訓練參數,最后使用全連接層神經元的前向傳播與反向傳導損失計算函數最優點,使輸入圖像的分類、分割等更加高效。訓練研究人員以卷積神經網絡為基礎提出AlexNet、VGGNet、GoogleNet、ResNet 等圖像分類網絡模型[3-6],其中AlexNet網絡為2012 年ILSVRC 大賽冠軍,GoogleNet 網絡、VGG?Net 網絡分別為2014 年ILSVRC 大賽中的冠亞軍,ResNet網絡為2015 年ILSVRC 大賽冠軍,其特點如表1 所示。
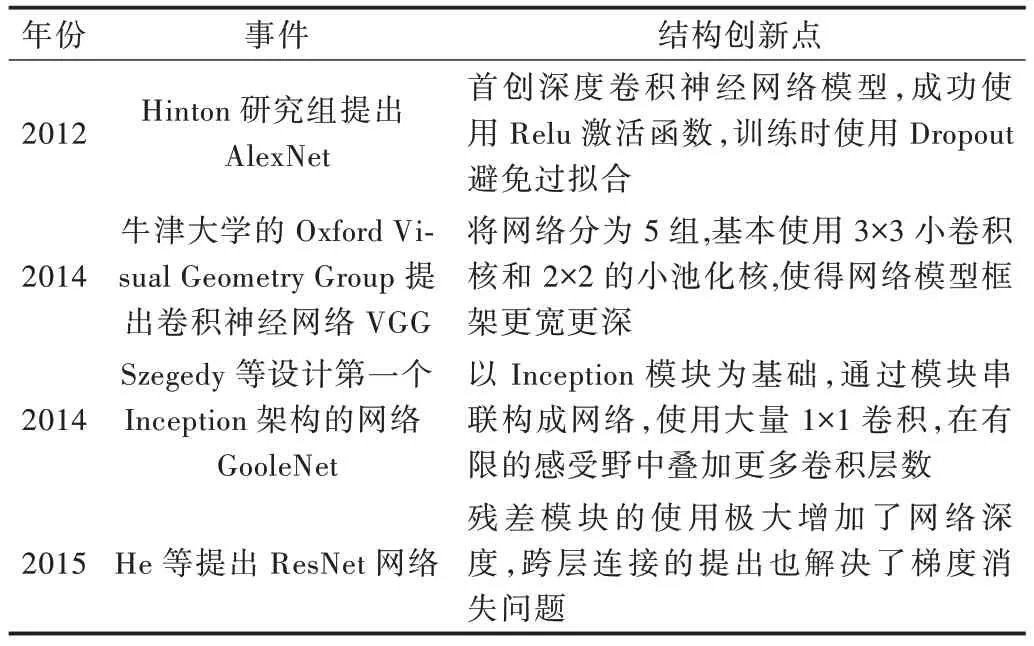
Table 1 Image semantic segmentation methods combined with deep learning and traditional methods表1 深度學習與傳統方法相結合的圖像語義分割方法
3 基于深度學習的語義分割方法
隨著全卷積神經網絡的提出,圖像語義分割技術進入新時期,計算機在視覺領域通過深度學習網絡進行全卷積后能夠極大提高圖像分類效率與識別準度,網絡框架與語義分割問題進入深度結合快速擴展的時代。全卷積網絡通過擴展普通卷積網絡模型,使其具有更多的參數特征和更好的空間層次。其結構可以分為全卷積和反卷積兩部分,全卷積借鑒卷積神經網絡模型,輸入圖像在參數減少與特征強化后,采用反卷積層對最后卷積層的特征圖進行上采樣,通過轉置卷積恢復輸入圖像尺寸,從而針對每個像素都產生一個預測,使輸入圖像達到語義級分割。全卷積網絡將卷積神經網絡對于圖像的識別精度從圖像級識別提升為全卷積神經網絡中像素級的識別。但是使用全卷積網絡的圖像分割仍存在分割結果不夠精準、輸出圖像模糊等問題。全卷積網絡為語義分割的未來發展指明了方向,研究人員以全卷積神經為基礎提出U-Net、SegNet、PSPNet、RefineNet、DeepLab、BiSeNet、Panoptic FPN[7-13]等圖像分割網絡結構模型。其特點如表2 所示。
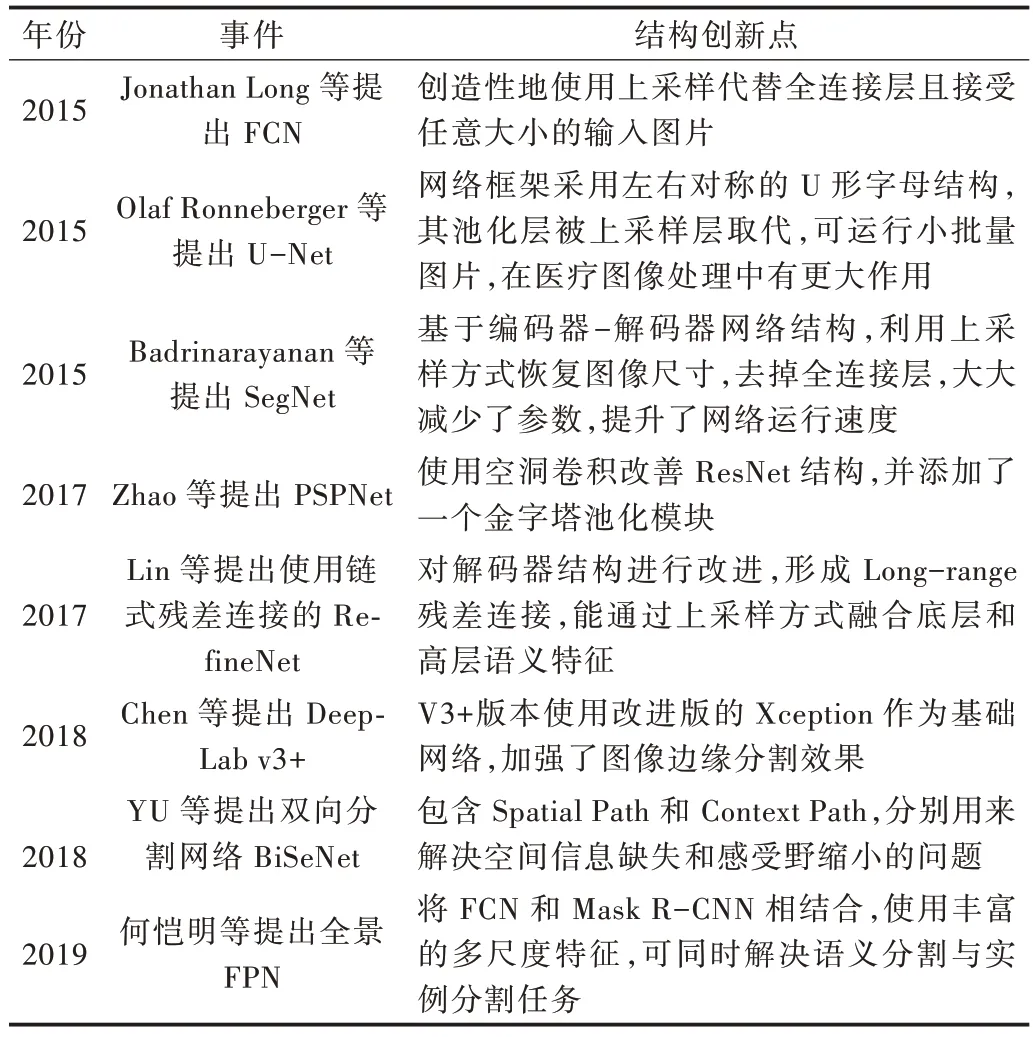
Table 2 Semantic segmentation methods based on deep learning表2 基于深度學習的語義分割方法
4 圖像語義分割分析與比較
評估基于深度學習的圖像語義分割算法性能的主要指標可歸納為:精確度、執行時間及內存占用等。處理速度或運行時間是重要的衡量指標,因為數據集一般較大,受到計算機硬件設施限制,更少的執行時間意味著更多的應用可能。內存是語義分割的另一個重要因素,不過內存在多數場景下是可以擴充的。精確度是最關鍵指標,圖像分割中通常依據許多標準衡量算法精度。這些標準通常是像素精度及圖像交并比衍變產生,如像素精度(Pixel Ac?curacy,PA=)、均像素精度(Mean Pixel Accuracy,MPA=)、均交并比(Mean Intersection over Union,MIOU=)等。像素精度是最簡單的度量,用以標記正確像素占總像素的比例。均像素精度是類別內像素正確分類概率的平均值。均交并比是公認的算法評估標準,其計算兩個集合的交集和并集之比,在語義分割領域中,真實值和預測值就是兩個集合的體現。FCN 網絡的提出打破了傳統分割方法,使用Caffe網絡框架,在PASCAL VOC 數據集上的分割精度(MIOU%)為62.2%。為解決FCN 分割精度不高等問題,SegNet 算法被提出,其使用Caffe 網絡框架,在CamVid 數據集上的分割精度為60.1%。隨后RefineNet 出現,使用Pytorch 網絡框架,在PASCAL VOC 數據集上的分割精度為83.4%。PSPNet 提出金字塔模塊,使用TensorFlow 網絡框架,在PASCAL VOC 數據集上的分割精度為85.4%。BiSeNet 和全景FCN 的提出使語義分割算法更加完善,它們在Cityscapes 數據集上的分割精度分別達68.4% 和79%。上述數據集匯總如表3 所示,網絡框架匯總如表4 所示。
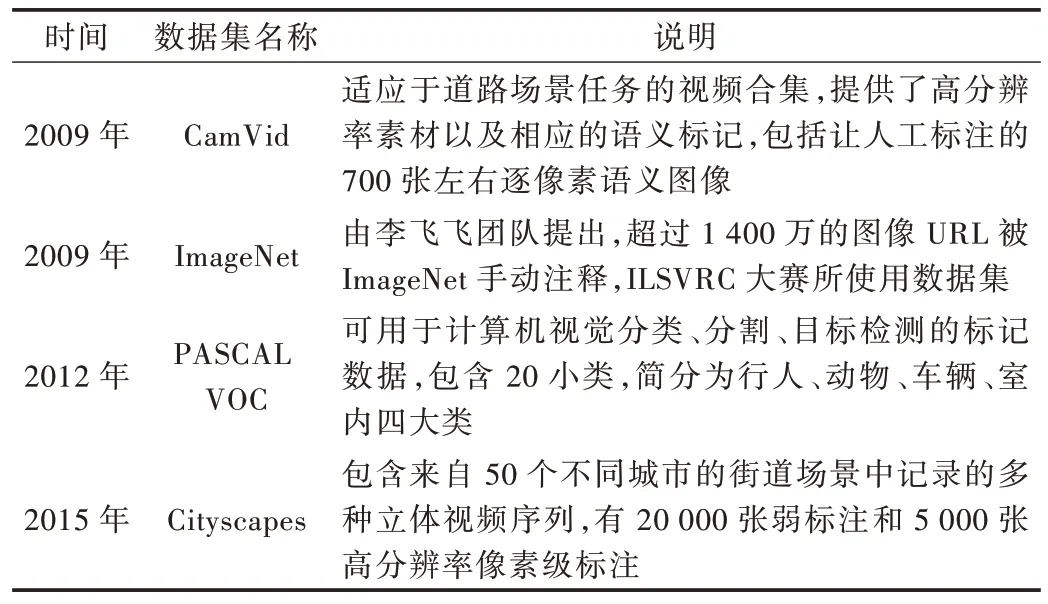
Table 3 Summary of data sets表3 數據集匯總
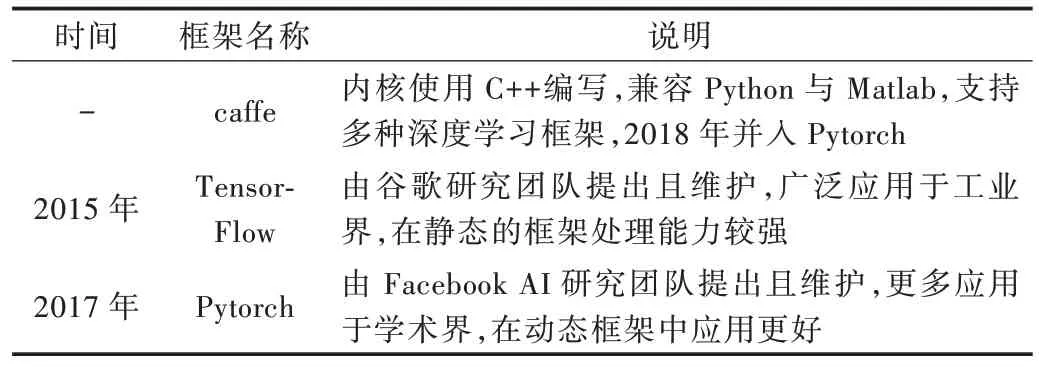
Table 4 Network frameworks表4 網絡框架匯總
5 結語
基于深度學習的圖像語義分割技術雖然取得了良好分割效果,但是其網絡訓練需要大量數據集,像素級別的圖像質量難以保證,原因是大量使用基于強監督的分割方法,依賴于人工數據標記,且對未知場景適應能力差。2014 年,DeepLab v1 結合深度卷積神經網絡和概率圖模型,形成完整端對端網絡模型,但是其空間分辨率低,存儲空間需求量大;2017 年,DeepLab v2 空洞金字塔的提出,提高了模型優化能力,但圖像細節模糊處理能力下降;同年,DeepLab v3 改進金字塔結構被提出,其使用1×1 小卷積核,但輸出圖效果不佳;2018 年,DeepLab v3+被提出,其使用編碼器解碼器結構,使用改進版的Xception 作為基礎網絡,彌補了之前版本網絡的缺陷性,但仍需繼續提高模型運行速度與性能,如隨著DeepLab 算法的發展,深度學習具有更新太快、周期較長、完善缺陷困難等問題。目前,還沒有一種通用算法適用于所有領域,基于深度學習的圖像語義分割尚有巨大發展潛力。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
現代語文(2016年21期)2016-05-25 13:13:44
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
大連民族大學學報(2015年2期)2015-02-27 08:28:11
