基于因子偏離度的GBDT 多因子選股模型
2021-02-04 06:53:28
軟件導刊 2021年1期
(上海工程技術大學數理與統計學院,上海 201620)
0 引言
實現資產配置的高收益率一直是理論研究和實際生活中的一大重要目標。10 多年來,量化投資成為市場發展的焦點,現階段中國股市多采用多因子選股模型。
一方面,多因子選股模型可以將基本面因子、技術面因子等多種研究成果應用于選股模型,具有一定包容性,能夠較為準確地刻畫金融市場運行規律。如國琳等[1]將盈利能力、償債能力、資產營運能力、成長能力4 方面財務因子運用于股票價格預測,用實證分析說明其研究的實際價值;王淑燕等[2]提出八因子選股模型,用隨機森林算法實現對股票漲跌的精確預測;李斌等[3]以19 個技術指標作為輸入變量;王云凱等[4]將33 個股票基本面多因子作為輸入變量,然后分別用不同的機器學習算法預測股票數日后的漲跌;Donaldson 等[5]驗證了多因子模型在印度股票市場的有效性。眾多研究表明,通過多因子選股模型選取并構建投資組合無疑是主流投資方式。
另一方面,多因子選股是構建支持向量機、隨機森林、神經網絡等復雜量化投資模型的基礎。如黃志輝[6]研究卷積神經網絡在量化選股中的應用,研究對象為滬深300 成分股,證明卷積神經網絡是一個有效的量化選股模型;李永康[7]利用Logistic 模型對多因子選股模型進行優化改進,對滬深300 指數成分股進行預測,獲得較高的超額收益;鄔春學等[8]將大盤走勢、K 線、MACD 線、成交量等技術指 標進行 處理,基于SVM 算法預測股票漲跌。各實證結果都證明,多因子量化投資模型能夠有效適用于A 股交易市場。
面對我國市場投資規模不斷擴大的現狀,市場發展驅動因素也復雜多變,而不同因子之間往往存在復雜關系,故因子選擇成為研究難點。
為了有效識別市場發展的驅動因素,賈秀娟[9]提出在建立選股模型前利用隨機森林模型篩選股票因子,提高機器學習模型識別精度;林娜娜等[10]在A 股股票漲跌預測中,首先選擇26 個指標作為初始因子,然后運用相關性分析對其進行篩選,最終確定13 個因子,通過實證對比證明,隨機森林算法比二元Logistic 回歸的性能穩定且優越;謝合亮等[11]發現Lasso 和ElasticNet 模型能夠有效篩選因子,構建有效的投資組合,從而幫助投資者獲得更高的超額收益。洪嘉灝[12]經過實證檢驗證明,GBDT 模型在股票價格趨勢預測中具有良好適用性,其策略盈利能力能夠大幅跑贏基準大盤收益率,對交易者的投資策略具有一定參考意義;陳子之[13]利用GBDT 模型進行地方政府債務風險預警,證明GBDT 的可行性和有效性;張瀟[14]提出梯度提升樹組合算法對股票價格趨勢追蹤具有明顯優勢;李佩琛[15]指出在量化投資中使用GBDT 模型,能夠帶來很高的超額收益。
此外,GBDT 模型也廣泛應用于其它實際案例。徐英杰等[16]提出一種基于多粒度級聯多層梯度提升樹對選票手寫字符進行準確、快速識別的算法;歐陽志友等[17]運用梯度提升模型進行人機行為識別;Su 等[18]提出一種基于梯度增強決策樹的GPS 信號接收分類算法;張紅斌等[19]用極端梯度提升樹算法完成圖像屬性標注。這都說明GBDT 模型具有很高的實用價值。
因此,本文提出一套基于因子偏離度和梯度提升樹(Gradient Boosted Decision Tree,GBDT)的量化選股模型。利用因子偏離度篩選有效因子,并結合梯度提升樹模型進行預測分析,建立有效的投資組合,從而給其它量化選股策略提供思路和借鑒。
1 模型建立
1.1 因子偏離度
因子偏離度(DEV)由董藝婷等[20]提出,能夠衡量因子強度,實現因子篩選。設股票池總數為N,X=(xij)n×p∈Rn×p,xij表示第i只股票某一時間的第j個因子。記xi=(xi1,xi2,…,xip)T,表示第i只股票的全部因子,則因子矩陣X為(x1,x2,…,xp);y為[y1,y2,…,yn]T,代表股票月收益率。其計算過程分為以下兩個步驟:①將股票池中所有股票按照收益率y從大到小排名,將收益率最高的20%股票組合記作SEThigh-R,收益率最低的后20%股票記作SETlow-R,得到SEThigh-R平均值和SETlow-R平均值之差;②將第i個因子按照因子值y進行從大到小排名,將因子值最高的20%股票組合記作SEThigh-F,收益率最低的后20% 股票記作SETlow-F,得到SEThigh-F平均值和SETlow-F平均值之差。得到第i個因子的因子偏離度如式(1)所示。

因子偏離度位于[0,1]區間,其絕對值越大代表因子強度越高,當絕對值為1 時,代表收益率排名的兩端恰好是因子值排名的兩端。
1.2 梯度提升樹
梯度提升樹(GBDT)是一種集成算法,其基分類器是決策樹,GBDT 算法的核心是在每一次迭代中,后一個弱分類器訓練的是前一個弱分類器的誤差,且沿著最大下降梯度方向。基于GBDT 算法,可以有效實現分類和回歸問題,而且不容易出現過擬合現象。
開展抗戰勝利紀念活動,目的就是為了挖掘抗戰紀念設施、遺址的歷史內涵和現實意義,使保存在博物館里的抗戰革命文物、陳列在廣闊大地上的抗戰遺產,記錄在抗戰歷史書籍里的文字都活起來,發揮其對內對外多重功能,彰顯抗戰精神的時代價值。
設因子矩陣為X,股票收益率為y。GBDT 算法在尋優過程中,GBDT 算法采用前向分段回歸,通過連續增加一個新的決策樹以減小誤差函數值,而不改變現有決策樹的參數,損失函數L(f)計算方式如式(2)所示。
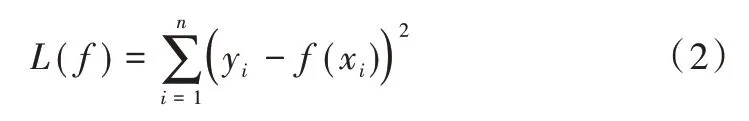
當算法迭代m次后,樣本的估計值是m次迭代的累計和,如式(3)所示。

在第m+1 次迭代時,損失函數的最大化下降方向是其梯度方向,如式(4)所示。

第m+1 次迭代,最優步長ρm+1的最優計算公式如式(5)所示。

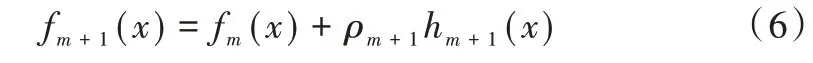
2 實證分析
2.1 數據來源與預處理
本文以滬深300 指數成分股數據進行實證分析,實驗區間 為2010 年1 月1 日—2019 年7 月31 日,將2010 年1 月1 日—2013 年12 月31 日作為訓練集、2014 年1 月1 日—2015 年12 月31 日作為測試集、2016 年1 月1 日—2019 年7月31 日作為回測區間。
同時,利用量化平臺優礦網站,在考慮成長性因子、盈利性因子、收益類因子以及市值類因子后,共選取36 個因子,初始股票因子說明如表1 所示。此外,由于所有因子的量綱存在差異,故將所有因子進行Z-score 標準化,如式(7)所示。


Table 1 Initial stock factor description表1 初始股票因子說明
將處理完成的數據利用式(1)計算每個因子的偏離度,結果如表2 所示。同時,將因子偏離度進行從大到小排序,取前5 個因子,分別為對數總資產(X31)、對數市值(X29)、對數流通市值(X30)、管理費用與營業總收入之比(X9)、市銷率(X35)。
2.2 模型評價指標
為了分析該模型效果,本文選取年化收益率、基準年化收益率、阿爾法、貝塔、夏普比率、波動率、信息比率、最大回撤、年化換手率作為評價指標,對模型進行綜合評價。這些評價指標均是聚寬、優礦等各大量化投資平臺的常見風險指標。
此外,累計收益率能直接反映在一定交易日內投資者按照預測方向投資能否帶來收益及帶來多大的收益。因此,它是一個具有很高實用性和參考價值的重要指標。
最后,在回測區間相同的條件下,將經過因子篩選的DEV-GBDT 選股模型和未經過因子篩選的GBDT 選股模型進行對比,驗證該模型應用效果。
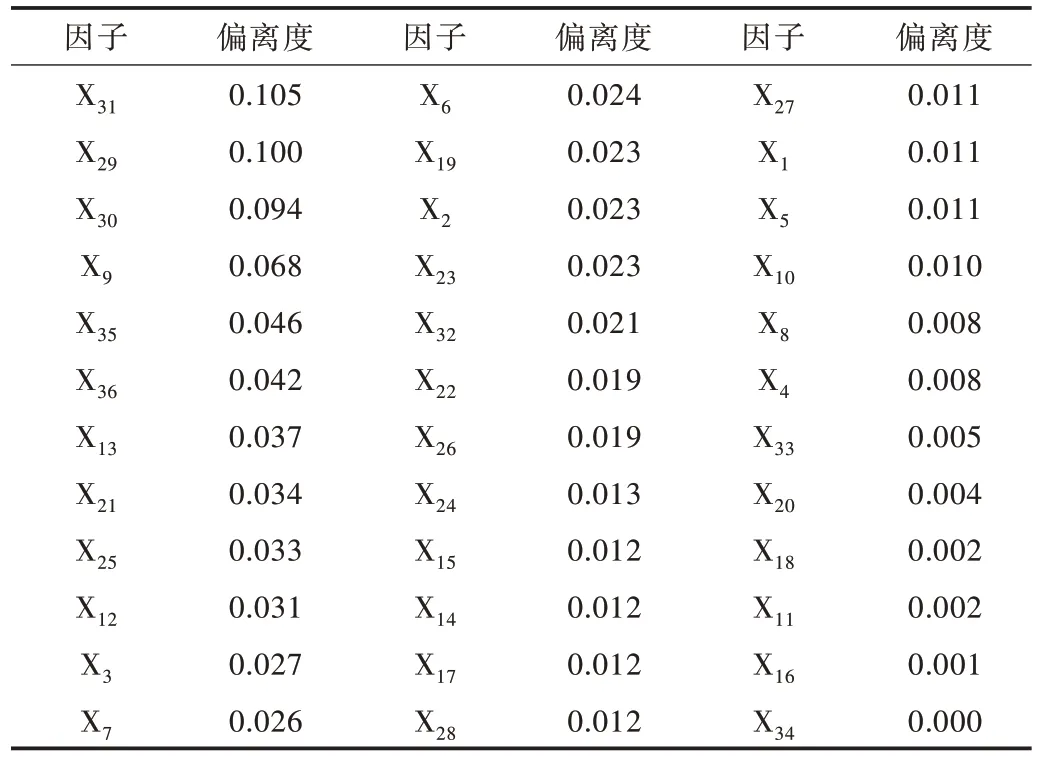
Table 2 Factor deviation degree表2 因子偏離度
2.3 模型預測結果
利用因子偏離度確定因子矩陣X,通過交叉驗證,在測試集上確定模型最佳參數。由于高頻率交易會帶來過高的手續費,因此,實驗采取每個月的最后一個交易日進行調倉操作,并在回測過程中去掉由于停牌或是還沒有上市等而不能交易的股票。實驗中設定的交易成本,如印花稅、手續費和滑點等采用優礦量化平臺的默認值。最后,將DEV-GBDT 策略和GBDT 策略進行回測,回測結果如表3 所示,DEV-GBDT 策略與GBDT 策略累計收益率如圖1所示。

Fig.1 Cumulative return rate of DEV-GBDT strategy and GBDT strategy圖1 DEV-GBDT 策略與GBDT 策略累計收益率
回測結果表明,同期以滬深300 指數的收益率為基準的年化收益率為0.74%,而DEV-GBDT 策略和GBDT 策略均顯著高于該水平,分別為26.14%和17.53%,而超額收益阿爾法值均在15%在以上。DEV-GBDT 策略不僅年化收益率高于GBDT 策略,而且夏普比率、信息比率、最大回測均優于GBDT 策略,說明前者投資組合方式相對較好,但存在一定風險。前者累計收益率也明顯較高,說明經過因子偏離度方法篩選因子能獲得更高的超額收益。

Table 3 Backtest results of DEV-GBDT and GBDT表3 DEV-GBDT 策略與GBDT 策略回測結果
3 結語
本文將因子偏離度與梯度提升樹相組合,建立DEVGBDT 多因子選股模型。研究結果表明,GBDT 策略的收益率遠超同期的滬深300 指數基準,能夠獲得很高的超額收益率。同時,DEV-GBDT 策略的年化收益率等各項評價指標均顯著高于GBDT 策略,說明GBDT 模型在量化投資中具有一定實用價值。通過對比DEV-GBDT 策略和GBDT策略在多因子量化選股中的效果發現,在量化交易市場上,可以通過因子偏離度判別因子強度,降低多因子選股模型中多個因子之間的復雜相關性,從而篩選出更為有效的因子,提高股票預測準確度,建立有效的投資組合。但因子偏離度的GBDT 多因子選股模型在偏離度因子選取以及梯度提升樹算法改進方面還存在不足,提高股票預測正確率,降低投資風險仍然是當前研究重點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
