基于級聯特征網絡的人體姿態估計
2021-02-04 06:53:20
軟件導刊 2021年1期
(河北工業大學人工智能與數據科學學院,天津 300401)
0 引言
目前,多人姿態估計已成為人體姿態估計研究的熱點問題。現有的多人姿態估計方法分為兩類:自頂向下的方法和自底向上的方法。自頂向下的方法首先從圖像中定位人體位置,然后對每個人體目標使用單人姿態估計獲得最終姿態估計結果;自底向上的方法則首先直接檢測圖像中所有人體關鍵點,并根據圖像中的其它關聯信息將屬于同一人體目標的關鍵點組合成一個完整的人體姿態。
為了提高關鍵點檢測精度,本文提出級聯特征網絡(Cascaded High-resolution Representation Network,CHRN),該網絡以HRNet[1]網絡為基礎,通過構建主體網絡與微調網絡的結構定位人體關鍵點。主體網絡利用多通道、多階段模式提取深度特征,并以多尺度融合方式將多階段深度特征進行融合,獲得圖像中更加全面且綜合的信息;微調網絡級聯整合主體網絡提取的多階段深度特征,對主體網絡中識別率較低的人體關鍵點進行在線挖掘[2]。
本文主要貢獻為:①提出級聯特征網絡的高效網絡模型,通過級聯深度特征并結合在線關鍵點挖掘提高不易識別關鍵點的識別率,進而提升關鍵點整體識別率;②將本文方法與其它經典算法進行系統比較,在MPII[3]數據集上對人體姿態估計的直觀效果和識別精度進行評估。實驗結果證明,本文方法具有一定有效性和先進性。
1 研究現狀
隨著深度學習方法在計算機視覺領域的廣泛應用,卷積神經網絡(CNN Convolutional Neural Network)[4-5]在人體姿態估計方面得到了良好發展。最近研究[6-13]主要依賴于卷積神經網絡,韓金貴等[4]對此作了比較全面的研究綜述,本文主要關注基于卷積神經網絡的多人姿態估計方法。多人姿態估計方法可分為兩類:自頂向下的方法和自底向上的方法。
自頂向下的方法[2,14,16]通過將單人姿態估計與目標檢測相結合,以解決多人人體姿態估計問題。Fang 等[14]使用空間轉換網絡(Spatial Transformer Networks,STN)[15]處理不準確的邊界框,然后使用堆疊沙漏網絡完成關鍵點檢測;He 等[16]在Mask-RCNN 模型中結合實例分割和關鍵點檢測,將關鍵點附加在RoI 對齊的特征映射上,通過堆疊沙漏網絡獲得每個關鍵點的位置;Chen 等[2]在特征金字塔網絡[17]上開發GlobalNet 用于多尺度推理,并通過在線關鍵點挖掘重新預測。自頂向下的方法將關鍵點檢測模型的注意力集中到圖像中各人體目標上,這樣減少了圖像中其它冗余信息干擾,獲得了良好表現。
自底向上的方法首先直接預測所有關鍵點,并將它們組合成所有人的完整姿勢。在Ladicky 等[18]提出使用基于HOG[19]的特征和概率方法聯合預測人體部分分割和部分位置;Pishchulin 等[20]提出DeepCut 方法,該方法將圖像中的多人人體姿態估計問題轉換為整數線性編程(Integer Linear Program,ILP)問題;Insafutdinov 等[21]使用更深層次的ResNet[22]改進DeepCut 提出DeeperCut,并采用圖像條件成對匹配獲得更好性能;Cao 等[23]使用CPM(Convolu?tional Pose Machines)將關鍵點之間的關系映射到部分親和域(Part Affinity Fields,PAF),并將關鍵點組合成不同的人體姿態;Kocabas 等[24]提出MultiposeNet 在檢測人體關鍵點的同時,利用另一個分支檢測人體目標位置,為關鍵點聚類提供依據。由于目標不明確,關鍵點定位空間過大,目前自底向上的方法在精度上仍然低于自頂向下的方法。
為提高關鍵點檢測精度,本文提出級聯特征網絡(CHRN),將主體網絡與微調網絡相結合,增加對不易識別關鍵點的關注度,從而提高關鍵點檢測整體精度。
2 本文方法
CHRN 使用HRNet 提取圖像特征,并借鑒CPN 模型思想,包含主體和微調兩個分支子網絡。
在CHRN 中,主體網絡負責提取圖像特征并檢測容易檢測到的關鍵點,微調網絡使用瓶頸模塊和級聯整合主體網絡各階段特征,并通過關鍵點在線挖掘檢測不易識別的關鍵點。
2.1 主體網絡
主體網絡部分以HRNet 網絡模型為基礎,通過該模型結構中不同分辨率的深度特征輸出層構建而得。該網絡共有4 個并行的深度特征提取子網絡,網絡結構如式(1)所示。
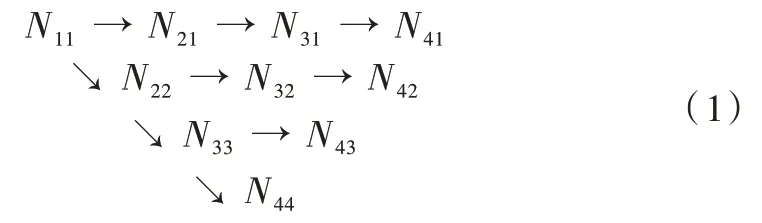
式(1)中,Nij為HRNet 網絡的基本處理單元,其中橫向為分支,包括4 個分支,分支數j=1,2,3,4,縱向為階段,包括4 個階段,階段數為i=1,2,3,4。
將4 個并行的深度特征提取子網中第i個階段的輸入記 為C={C1,C2,…,Ci},第i階段的輸出記為,輸出的分辨率和寬度與輸入的分辨率和寬度相同,在同一個階段的不同分支中,交換單元多尺度融合方式如式(2)所示。
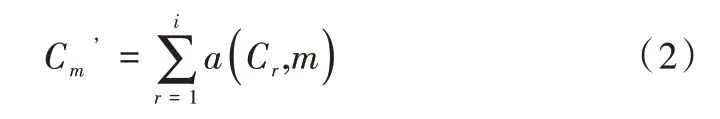
式(2)中,函數a(Cr,m)表示將Cr從分辨率r上采樣或下采樣到分辨率m,Cm’為C’包含的元素,上采樣使用最鄰近采樣,然后使用1×1 的卷積進行通道對齊,下采樣使用3×3 的卷積,當r=m,如式(3)所示。

2.2 微調網絡
本文在基于主體網絡生成的高分辨率特征圖上附加使用OHKM 的微調網絡分支,對主體網絡預測的關鍵點進行修正。微調網絡將上述構建的主體網絡各階段提取的深度特征:C111、C212、C313、C414以及人體關鍵點置信度熱圖H作進一步特征提取,具體結構如式(4)所示。
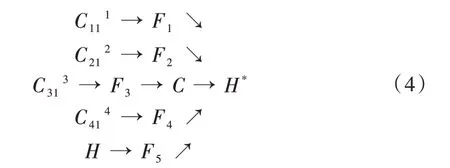
式(4)中,C111、C212、C313、C414、H經過進一步特征提取后分別生成F1、F2、F3、F4、F5,其中F1、F2、F3、F4、F5的寬度和分辨率都相同,C為F1、F2、F3、F4、F5的特征級聯,H*為經過人體關鍵點在線挖掘的人體關鍵點置信度熱圖。
3 實驗
為驗證本文方法的有效性,在公開的MPII 數據集上對本文方法進行評估,并與一些優秀方法進行對比。
3.1 數據集與實驗設置
MPII 數據集包含約25 000 張圖像,其中有5 000 張圖像用于測試,其余圖像用于訓練。評價指標為:頭部標準化概率(Percentage of Correct Keypoints According to Head Size,PCKh)。
3.2 級聯深度特征網絡實驗
為驗證級聯特征網絡關鍵點定位有效性,將該網絡應用于單人姿態估計,表1 展示了本文方法在MPII 測試集上進行單人姿態估計PCKh@0.5 獲得的定量性能。實驗表明,HRNet+RefineNet 模型結構加入微調網絡后,對于肩部、髖關節、膝關節和踝關節的平均精度比HRNet 均有所提升。加入OHKM 后的結果表明,本文提出的CHRN 人體姿態估計使HRNet 的平均精度由92.3% 提高至92.7%。
3.3 人體姿態估計實驗效果
為了證明級度特征網絡對多人姿態估計的有效性,在MPII 數據集中進行多人姿態估計對比實驗驗證。其中,對比方法相關數據來源于MPII 數據庫排行榜。實驗結果如表2 所示。

Table 1 Performance comparison of MPII test sets(PCKh@0.5)(single-person pose estimation)表1 MPII 測試集性能比較(PCKh@0.5)(單人姿態估計)
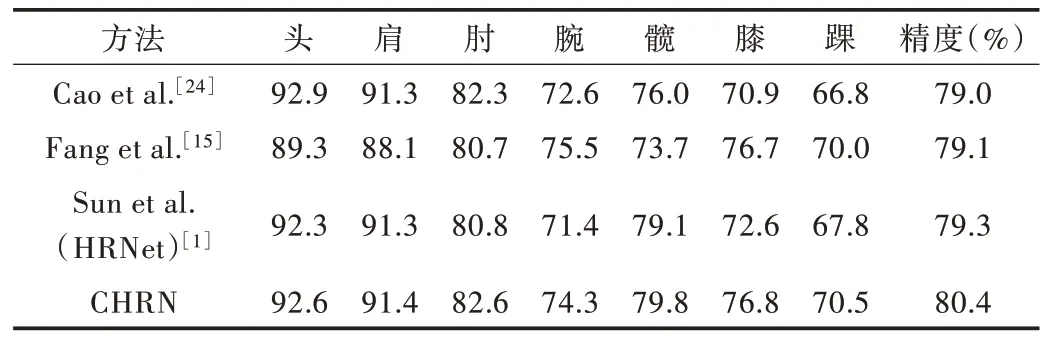
Table 2 Performance comparison of MPII test sets(PCKh@0.5)(multi-person pose estimation)表2 MPII 測試集性能比較(PCKh@0.5)(多人姿態估計)
表2 展示了本文方法在MPII 測試集上進行多人姿態估計的定量性能。表2 中的對比算法為MPII 數據集排行榜前3 名的識別精度。其中,“CHRN”表明,級聯深度特征網絡模型使用自頂向下方法得到平均精度為80.4%,高于其它算法。同時,CHRN 模型對于踝關節、膝關節和髖關節等較難識別關鍵點的識別精度有所提升,證明CHRN 對于較難識別的關鍵點有更強的定位能力。
4 結語
本文提出的級聯特征網絡通過提升不易識別關鍵點的識別精度以提高人體姿態估計準確率。研究表明,在人體姿態估計中由于關鍵點本身特性不同,關鍵點在模型訓練過程中應區別對待,即為不易識別的關鍵點分配更多計算資源。下一步工作主要是對關鍵點進行分類細化,具體到各類關鍵點應分配多少計算資源可達到最優結果。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國衛生(2014年2期)2014-11-12 13:00:16
