一種改進YOLOv3的手勢識別算法
2021-01-26 05:50:48睢丙東張湃王曉君
河北科技大學學報 2021年1期
睢丙東 張湃 王曉君


摘 要:為了解決YOLOv3算法在手勢識別中存在識別精度低及易受光照條件影響的問題,提出了一種改進的YOLOv3手勢識別算法。首先,在原來3個檢測尺度上新增加1個更小的檢測尺度,提高對小目標的檢測能力;其次,以DIoU代替原來的均方差損失函數作為坐標誤差損失函數,用改進后的Focal損失函數作為邊界框置信度損失函數,目標分類損失函數以交叉熵作為損失函數。結果表明,將改進的YOLOv3手勢識別算法用于手勢檢測中,mAP指標達到90.38%,較改進前提升了6.62%,FPS也提升了近2倍。采用改進的YOLOv3方法訓練得到的新模型,識別手勢精度更高,檢測速度更快,整體識別效率大幅提升,平衡了簡單樣本和困難樣本的損失權重,有效提高了模型的訓練質量和泛化能力。
關鍵詞:計算機神經網絡;YOLOv3;目標檢測;手勢識別;DIoU;Focal損失函數
中圖分類號:TP391.9?文獻標識碼:A
文章編號:1008-1542(2021)01-0022-08
YOLOv3是一種多目標檢測算法[1],具有識別速度快、準確率高等優點,廣泛用于目標檢測中[2]。手作為信息表達的重要組成部分,近年來成為人們研究的重點[3]。隨著人工智能技術的發展,越來越多的學者利用神經網絡進行手勢識別[4]。其中YOLOv3以其出色的檢測性能,被應用在手勢檢測領域。例如:羅小權等[5]采用改進的K-means聚類算法,提高了YOLOv3對火災的檢測能力;陳俊松等[6]利用改進的YOLOv3特征融合方法,實現了對筷子毛刺的檢測;張強[7]提出了基于YOLOv3的實時人手檢測方法,通過改進anchor參數,快速檢測出測試者擺出的手勢;毛騰飛等[8]通過改進的YOLOv3檢測尺度,實現了對人手功能的實時檢測。
本文提出一種基于改進YOLOv3的手勢識別算法,通過增加YOLOv3的檢測尺度、改進位置損失函數和邊界框置信度損失函數,得到檢測效果更好的算法,以解決手勢識別的相關問題。
1?YOLOv3算法介紹
1.1?YOLOv3模型
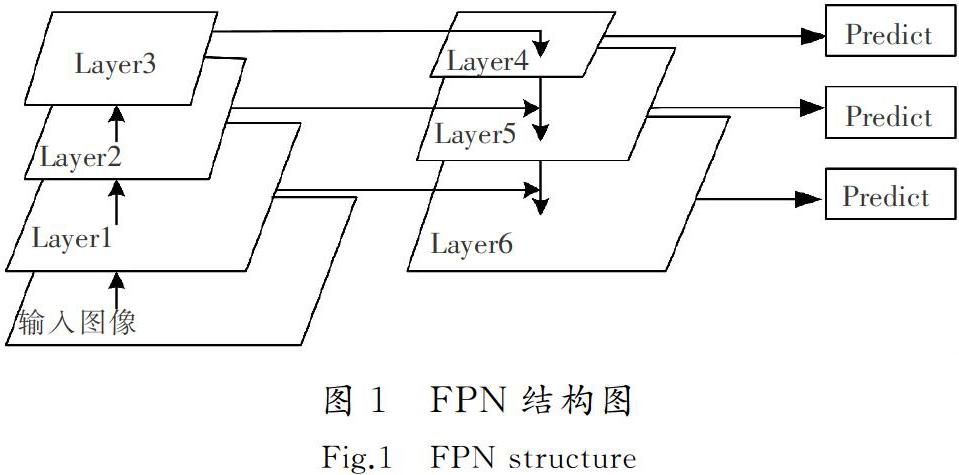
YOLOv3由卷積層(convolution layers)、批標準化層(batch normalization, BN)、激活層(leaky relu)組成[9],引入殘差塊結構,在很大程度上提升了網絡訓練速度和效率[10]。YOLOv3主體網絡為darknet-53,相比于ResNet-152和ResNet-101,具有更出色的特征提取能力。采用該神經網絡對輸入圖像進行特征提取,利用特征金字塔(feature pyramid networks,FPN)進行融合[11],采用步長為2的卷積進行降采樣,分別在32,16,8倍降采樣處檢測目標。
FPN架構如圖1所示。將圖像輸入到網絡模型后進行卷積操作,為了使Layer4和Layer2具有相同的尺度,對Layer2降低維度,接著對Layer4進行上采樣操作,然后將這2層的特征進行融合[12]。將融合后的結果輸入到Layer5中,這樣就會獲得一條更具表達力的語義信息。YOLOv3網絡按照FPN架構融合了淺層和深層的特征信息[13],可以獲得更多圖片特征,檢測效果更好。
運用該模型檢測手勢時,首先將手勢圖像按13×13,26×26,52×52網格大小進行劃分,每個網格分配3個候選框,然后計算候選框與真值框的重合程度及置信度大小,最后對比候選框的得分值,分值最高的候選框即為模型預測手勢結果。
1.2?損失函數
YOLOv3算法的損失函數[14]由3部分組成:均方差(mean square error, MSE)損失函數作為坐標誤差損失函數,交叉熵損失函數作為置信度和類別的損失函數,損失函數如式(1)所示:
2?改進的YOLOv3算法
2.1?增加模型檢測尺度
針對人手大小不一會導致檢測效果不佳的問題,在原來3個檢測尺度基礎上,結合FPN思想增加至4個檢測尺度,以此提高小目標人手的檢測能力。改進后的YOLOv3檢測尺度分別為13×13,26×26,52×52,104×104。
改進后的YOLOv3網絡結構如圖2所示,圖2中粗體標注的為104×104檢測尺度。在YOLOv3網絡中通過多卷積操作后,將52×52的特征層上采樣操作變換成104×104,使之與上一層具有相同的特征尺寸,然后將該層與104×104特征層進行融合,得到一個表達能力更強的語義信息。
改進后的YOLOv3網絡有4個檢測尺度,每個檢測尺度均融合了低層細節信息和深層語義信息,同時可以進行單獨預測,因此改進后的檢測網絡具有更為出色的檢測能力。
2.2?改進損失函數
在目標檢測中常用IoU(intersection over union)衡量預測框和真實框的重合程度[16]。一般認為,該值越大,兩框的重合程度越好,算法檢測精度越高,反之則越差[17]。
經大量實驗發現,以均方誤差作為坐標誤差損失函數存在以下缺點:一是IoU越大,并不一定代表預測框與真值框重合程度越好,通過圖3可以看出IoU相同時,2個框的重合程度并不一樣;二是損失函數沒有將檢測目標和錨框之間的中心距離、重疊率及尺度考慮進去。
2.2.1?改進坐標誤差損失函數
針對以上不足,本文采用DIoU作為坐標誤差損失函數[18],DIoU將預測框和真值框之間的距離、重疊率以及尺度均加以考慮。DIoU計算過程如下:
式中:R1,R2分別代表預測框中心和真值框中心;L為R1和R2間的歐氏距離;c,Ag,Ap,I分別代表預測框和真值框的最小閉包區域的對角線距離、真值框的面積、預測框的面積及重疊面積。
DIoU損失的計算如式(4)所示:
DIoU作為損失函數,一是可以直接最小化預測框和真值框之間的歸一化距離,使收斂速度更快;二是當預測框與真值框不重疊時,仍然可以為預測框提供移動方向;三是2個框在水平和垂直方向上時,DIoU回歸速度非常快;四是在非極大值抑制評估中,DIoU可以代替IoU,使NMS得到更加合理及有效的結果。
2.2.2?改進置信度損失函數
為了解決樣本不平衡問題,LIN等[19]提出了Focal損失函數。為進一步提高YOLOv3的檢測精度,本文采用改進的Focal損失函數作為置信度損失函數。Focal損失函數能夠在模型訓練過程中通過增大困難樣本權重的方法,有效解決樣本不平衡問題[20],使訓練模型具有更佳的檢測效果。Focal損失函數如式(5)所示:
式中:γ為聚焦參數,是一個大于0的超參數;αt為平衡參數,也是一個超參數,用來控制正負樣本對總損失的權重,平衡多類別樣本數量;pt為標簽預測概率。
式(5)中αt和γ這2個參數一般由人為規定,但是如果設定的數值不貼合數據集,訓練效果反而不好[21]。針對這一問題,本文根據數據集確定該參數,確定過程如下。
1) 確定平衡參數αt
本文樣本有5個類別,為了對困難樣本加大損失函數權重,同時減小容易樣本的損失權重,根據各類樣本數量來縮放分類損失大小。計算思路為權重設定的目標要使任意2個類別樣本數量和這2個類別的權重成反比,如式(6)所示:
式中:N為樣本類別總數;mi為第i類樣本數量;第i類的平衡參數αi等于類別權重值的大小。這樣平衡參數能夠較好地均衡樣本數量大小對應的損失值。
2) 確定聚焦參數γ
通過大量實驗發現,在模型訓練初期,使用Focal損失函數的模型訓練精度低于使用交叉熵損失函數時的精度[19]。為此本文采用每N輪訓練后調整1次γ值的方法,調整方式如式(7)所示:
綜上所述,本文以DIoU代替原來的均方差損失函數作為坐標誤差損失函數,用改進后的Focal損失函數作為邊界框置信度損失函數,目標分類損失函數以交叉熵作為損失函數。因此,YOLOv3損失函數如式(8)所示:
式中CE表示交叉熵損失函數。DIoU損失作為目標框坐標回歸損失,將預測框和真值框之間的距離、重疊率以及尺度均考慮進去,在很大程度上提高了目標框回歸速度。在邊界框置信度交叉熵損失函數的基礎上加入焦點損失函數,顯著平衡了簡單樣本和困難樣本的損失權重,有效提高了模型的訓練質量和泛化能力。
3?實驗及結果
3.1?數據集
為了使數據集更加豐富,本文在盡可能多的自然場景下采集手勢圖像,手勢1到手勢5各自采集500張圖片,采用Labelimg工具標記手勢目標制作數據集[23]。為了充分利用樣本圖片,對圖片進行30°,60°,90°,180°,270°旋轉、垂直和水平翻轉,并以0.4,0.6,0.8的因子縮小圖片[24]。對圖片隨機增強亮度,增強范圍為0.1~2,并對樣本圖片適當增加椒鹽噪聲,對樣本數據增強后獲得14 500張訓練圖片。
3.2?實驗平臺與評價指標
采用CPU為英特爾i7-7700HQ、英偉達GTX1060顯卡訓練模型,交互語言為python3.6,使用CUDA9.0和CUDNN7.4加速訓練過程。在訓練網絡模型階段,使用的部分參數batch size為16,圖片大小為416×416,迭代輪數20 000,IoU閾值為0.5。
目標檢測中常用以下指標衡量模型訓練效果:Precision(查準率)、Recall(召回率)、AP(平均精度)和mAP(平均精度均值)[25],如式(9)—式(12)所示:
式中:TP(ture positive)表示分類器正確預測的正樣本;FN(false negative)表示分類器錯誤預測的負樣本;FP(false positive)表示分類器錯誤預測的正樣本;n為采樣P-R對,k為樣本類別數(本文為5)。
3.3?結果分析
采用改進后的YOLOv3算法與傳統YOLOv3,SSD300,Faster R-CNN經典多尺度目標檢測算法[26]對每個類別AP值進行對比,結果如表1所示。同時,對比各算法的幀率(frames per second,FPS)、mAP和達到Loss閾值的迭代次數,結果如表2所示,各算法檢測手勢效果如圖4所示。
由表1和表2分析可知,改進后的YOLOv3算法mAP能夠達到90.38%,相對于傳統YOLOv3,SSD300,Faster R-CNN分別提高了6.62%,11.18%和0.28%,并且每個類別的檢測精度均大于傳統YOLOv3和SSD300算法。從檢測速度上分析,改進后的YOLOv3算法FPS比改進前提升近2倍,但和SSD300相比還有不少差距。分析迭代次數可知,改進后的算法在訓練時損失函數收斂速度更快。
從圖4可以看出,改進后的算法在檢測效果和檢測精度上表現更加出色,因為手勢1和手勢2可能存在遮擋問題,導致個別誤檢,但是整體識別效率有了大幅度提升,模型具有較高的泛化能力和魯棒性。
4?結?語
1)本文針對手勢檢測中存在精度和速度無法兼顧的問題,以YOLOv3為檢測框架,在原來檢測尺度上增加一個檢測尺度,提高小目標的檢測能力。采用DIoU作為坐標誤差損失函數,并用改進后的Focal損失函數代替交叉熵損失函數作為邊界框置信度損失函數。
2)實驗結果表明,本文改進的YOLOv3模型在檢測精度上有了明顯提升,并且檢測速度幾乎相同,能夠有效識別檢測者的手勢。但是增加一個檢測尺度后,模型的訓練速度會變慢,并且當真值框和目標框距離過遠時,DIoU無法為候選框提供移動方向。因此,未來將深入探究如何在增加檢測尺度時不減慢模型的訓練速度,同時嘗試采用CIoU代替DIoU作為損失函數。
參考文獻/Reference:
[1]?LIU Jun, WANG Xuewei. Early recognition of tomato gray leaf spot disease based on MobileNetv2-YOLOv3 model[J]. Plant Methods,2020, 16(11):612-231.
[2]?YU Yuan, REN Jinsheng, ZHANG Qi, et al. Research on tire marking point completeness evaluation based on K-means clustering image segmentation[J]. Sensor, 2020, 20(17):4687-4697.
[3]?WILLIAMS E H,LAURA B, DOWNING P E,et al. Examining the value of body gestures in social reward contexts[J]. Neurolmage,2020, 222:117276-117286.
[4]?HU Wei, ZHU Quanxin. Moment exponential stability of stochastic delay systems with delayed impulse effects at random times and applications in the stabilisation of stochastic neural networks[J].International Journal of Control, 2020, 93(10):2505-2515.
[5]?羅小權,潘善亮.改進YOLOv3的火災檢測方法[J].計算機工程與應用2020,56(17):187-196.
LUO Xiaoquan, PAN Shanliang. Improved YOLOv3 fire detection method[J].Computer Engineering and Applications, 2020, 56(17):187-196.
[6]?陳俊松,何自芬,張印輝.改進YOLOv3算法的筷子毛刺缺陷檢測方法[J].食品與機械,2020,36(3):133-138.
CHEN Junsong,HE Zifen,ZHANG Yinhui.Defect detection method of chopsticksbased on improved YOLOv3 algorithm[J].Food & Machinery,2020,36(3):133-138.
[7]?張強. 基于改進YOLOv3的手勢識別方法研究[D].合肥:合肥工業大學,2019.
ZHANG Qiang.Hand Gesture Recognition Approach Research Basedon Improved YOLOv3[D].Hefei:Hefei University of Technology,2019.
[8]?毛騰飛,趙曙光.基于改進YOLOv3的實時人手檢測算法[J].現代計算機,2020(5):57-60.
MAO Tengfei,ZHAO Shuguang.Real-time hand detection algorithm based on improved YOLOv3[J].Modern Computer,2020(5):57-60.
[9]?WILLIAMS A S, ORTEGA F R. Understanding multimodal user gesture and speech behavior for object manipulation in augmented reality using elicitation[J]. IEEE Transactions on Visualization and Computer Graphics, 2020,doi:10.1109/TVCG.2020.3023566.
[10]THOMSEN J L D, MARTY A P, SHIN W, et al. Barriers and aids to routine neuromuscular monitoring and consistent reversal practice:A qualitative study[J]. Acta Anaesthesiologica Scandinaviva, 2020, 64(8):1089-1099.
[11]LI Qiaoliang, LI Shiyu, LIU Xinyu, et al. FecalNet: Automated detection of visible components in human feces using deep learning[J]. Medical Physics, 2020, 47(9):4212-4222.
[12]LI Qiaoliang, YU Zhigang, QI Tao, et al. Inspection of visible components in urine based on deep learning[J]. Medical Physics, 2020, 47(7):2937-2949.
[13]NURI E O, KAPLAN G, ERDEM F, et al. Tree extraction from multi-scale UAV images using mask R-CNN with FPN[J]. Remote Sensing Letters, 2020, 11(9):847-856.
[14]LUO Ze, YU Huiling, ZHANG Yizhuo. Pine cone detection using boundary equilibrium generative adversarial networks and improved YOLOv3 model[J]. Sensors, 2020, 20(16):doi:10.3390/s20164430.
[15]ZHANG Xiaoguo, GAO Ye, WANG Huiqing, et al. Improve YOLOv3 using dilated spatial pyramid module for multi-scale object detection[J].International Journal of Advanced Robotic Systems, 2020, 17(4):doi:10.1177/1729881420936062.
[16]KUZNETSOVA A, MALEVA T, VLADIMIR S. Using YOLOv3 algorithm with pre-?and post-processing for apple detection in fruit-harvesting robot[J]. Agronomy, 2020, 10(7):doi:10.3390/agronomy10071016.
[17]HAN Fenglei, YAO Jingzheng, ZHU Haitao, et al. Underwater image processing and object detection based on deep CNN method[J]. Journal of Sensors, 2020,doi:10.1155/2020/6707328.
[18]WU Xiongwei, SAGOO D, ZHANG Daoxin, et al. Single-shot bidirectional pyramid networks for high-quality object detection[J]. Neurocomputing, 2020, 401:1-9.
[19] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. [S.l.]:[s.n.]:2017.2980-2988.
[20]AGHDASSI A, TRAN Q T, BULLA T, et al. Focal pancreatic lesions in autoimmune pancreatitis and weight loss[J].Gut, 2020,doi:10.1136/gutjnl-2020-321987.
[21]LI Dongdong, WEN Gongjian, KUAI Yangliu, et al. Robust visual tracking with channel attention and focal loss[J]. Neurocomputing, 2020, 401:295-307.
[22]PERSSON D, HEYDARI G, EDVINSSON C, et al. Depth-resolved FTIR focal plane array (FPA) spectroscopic imaging of the loss of melamine functionality of polyester melamine coating after accelerated and natural weathering[J]. Polymer Testing, 2020, doi:10.1016/j.polymertesting.2020.106500.
[23]YAO Shangjie, CHEN Yaowu, TIAN Xiang, et al. An improved algorithm for detecting pneumonia based on YOLOv3[J]. Applied Sciences, 2020, 10(5):doi:10.3390/app10051818.
[24]GERLACH S, CHRISTOPH F, HOFMANN T, et al. Multicriterial CNN based beam generation for robotic radiosurgery of the prostate[J].Current Directions in Biomedical Engineering, 2020, 6(1):doi:10.1515/cdbme-2020-0030.
[25]LI Min, ZHANG Zhijie, LEI Liping, et al. Agricultural greenhouses detection in high-resolution satellite images based on convolutional neural networks: Comparison of faster R-CNN, YOLOv3 and SSD[J]. Sensors, 2018, 10:131-152.
[26]王慧. 基于改進Faster R-CNN的安全帽檢測及身份識別[D]. 西安:西安科技大學, 2020.
WANG Hui. Safety Helmet Detection and Identification Based on Improved Faster R-CNN[D]. Xi′an: Xi′an University of Science and Technology, 2020.
