基于高速公路貨車收費數據庫的全息樣本遴選
2021-01-22 02:01:20黃秋實
重慶交通大學學報(社會科學版) 2021年1期
馬 暕, 黃秋實
(長安大學 經濟與管理學院,西安 710064)
一、引言
在統計學范疇,很多時候研究者無法選擇所有數據進行調查,一般采用從整體中抽取樣本進行調研。抽樣即為了得到總體的某些特征及分布信息,按照一定規則,從總體中抽取若干個體進行觀察實驗的方法,抽取的個體即樣本。定理表明,當樣本容量足夠大時,樣本分布函數依概率收斂于總體分布函數,這是用樣本推斷總體的理論依據。在目前的高速公路流量分析研究中,雖然大數據技術已不斷完善,但考慮到處理海量數據的冗繁性,大而全的數據并不一定比合理的樣本數據對流量分析研究更加方便,反而會在一定程度上造成人力、物力的浪費,這一點在下文處理國內某省全年的高速公路收費流水數據庫時就有所體現,因此抽樣仍是一種必不可少的研究手段。在目前的主流抽樣方式中,對樣本的選擇有一套傳統的方法,但這些選擇方法在實際高速公路流量分析中適用性不強,也很少有研究者能夠嚴格按照要求進行,樣本選擇存在一定的隨機性,導致分析結果存在一定程度的偶然性。針對此情況,從大數據角度出發,運用大數據的處理方法,壓縮全年數據,盡可能將完整的數據庫壓縮到一個可接受的最小樣本范圍,如果這個樣本能夠完整反映數據庫中的全部有用特征,壓縮后的樣本可認為是理想中的全息樣本。尋找到這個全息樣本,就可以在以后的高速公路流量分析中達到便于處理且真實反映全體特征的目的,有效節約人力、物力。
為了解決這個問題,本文主要論證如何選擇一個最能代表全年流量特征的全息樣本,以國內某省高速路網一年的完整數據來分析,利用Python、SPSS、Matlab等軟件,找出一個能夠代表全年趨勢與特點的全息樣本,作為日后高速公路流量分析的數據樣本。確定樣本容量時,考慮到實際工作中使用的便捷與分析的直觀,選擇自然月份這一時間范圍作為樣本容量,在此基礎上將全年十二個月的數據單獨提取整理。為能全面反映交通流量的多維度特征,從數據庫中將字段分類,建立基于時間結構、空間結構、軸型結構三個維度的相似評價體系,進而計算三種維度下的各月和周及天分時段車輛到達數據、OD分布數據、車軸組成數據與全年對應數據之間的距離接近度及形狀相似度,并通過熵值法賦予距離接近度和形狀相似度相應的權重,整合數據,定義出不同樣本與全年數據之間的離散度。根據計算出的離散度,對不同樣本與全年的相似性排序,離散度最低的樣本可認為是符合要求的全息樣本。
關于高速公路收費流水數據庫全息樣本的研究,有不少學者研究與探討了高速公路收費數據庫與數據相似性度量。在高速公路收費數據庫研究方面,有的學者分析與高速公路流量相關的數據指標類型,有的運用收費數據庫進行預測分析研究。王維鳳等研究與公路流量關聯度較高的主要指標,并進行預測[1-2]。袁長偉對高速公路中的貨車流提出收費車型結合軸型的組合分層統計方法[3]。楊潔等采用動態時間彎曲距離作為相似性度量指標,分析城市干道交通流量信息[4]。楊春霞等以短時交通流預測為切入點,分析了流量數據[5-11]。胡閏秀和李夢雪提出基于收費數據的車型數據轉換方法來計算斷面交通量[12]。
而針對高速公路收費數據庫中的數據,主流的定義更多是將其歸類到時間序列數據來討論,本文所探討的全息樣本遴選可認為是在高速公路收費數據庫中進行時間序列數據的相似性探究。自Agrawal等首次提出使用離散傅里葉變換將時間序列的時間域轉換為頻率域,并將其應用于時間序列相似性搜索開始,時間序列數據相似性度量的研究方法越來越豐富[13]。董曉莉等研究基于形態相似距離的時間序列相似性度量方法,并給出相應的距離公式,以度量時間序列的相似性[14-16]。弓晉麗針對城市道路交通流數據,討論5種模式相似性距離的聚類效果[17]。陳海燕等綜述了常用的相似性度量方法[18]。董建華等主要通過PAC來判斷水質相似度[19]。周永通過用戶簽到數據描繪用戶的軌跡路線,并對其興趣區域進行相似性度量[20]。Cha等為了獲得更多關于數據模式和特征的信息,考慮用一個帶冪的模糊測度來測算相似度[21]。李建勛等將時空數據趨勢狀態表征為圖像的結構信息,以趨勢面圖像之間的相似度來表征時空數據的相似度[22]。Clapper等通過控制兩個結構上可對齊的對象共享部分的比例,來確定相似性是否會對自由分類產生分級影響[23]。Liu Dong等基于相似性的偏好順序技術,提出基于加權馬氏距離和灰色關聯分析的理想解決方案評估模型[24]。王慧通過面板數據的接近性和相似性判斷關聯度的方法進行公理化的證明[25]。
通過相關文獻的分析可以發現,關于高速公路收費數據庫研究中,研究者多是直接運用數據庫或根據主觀判斷選擇樣本進行研究與分析,沒有學者系統討論樣本的選擇,這一現象在眾多的交通調查中非常普遍。關于時間序列數據相似性度量研究中,大多處于相似性證明方法的探究,屬于方法論的層面,未將時間序列數據相似性度量與具體的現實問題結合。針對這兩方面的問題,將時間序列數據的相似性探討運用到高速公路收費數據庫的樣本尋找中是本文擬討論的問題。通過現有較為成熟的距離接近度與形狀相似度兩種相似性度量方法,壓縮高速公路貨運收費流水數據庫,探尋能夠表示全年特征的最小全息樣本,從而為今后的交通流量分析研究提供一個合理的樣本選擇策略。
二、基礎概念
(一)全息樣本
全息片段概念用在高速公路交通流量分析領域,主要意在尋找一個可以代表全年交通流量特征的時間片段。尋找的這個時間片段要能代表這一年中交通流的各方面數據特征,例如到達時間分布、車軸結構、OD數據分布等。樣本若想代表全年的交通流量特征,僅憑某一維度的數據衡量是不夠的,本文討論的全息樣本應基于多個維度的數據支持之上。倘若這個時間段的數據均符合要求,就可以把這個時間段稱為“全息樣本”。全息樣本的確定可以使研究者選取樣本時,能夠盡可能地排除主觀因素的影響,且不用對整體冗繁的數據再次篩選分析,大大節約交通預測過程中的人力、物力。在具體分析過程中,出于現實預測便于使用需要,也為了使結果更直觀且易于檢測,分別以月份、周數、天數為樣本區間來劃分一年的數據,并以此求取分析離散度結果。
(二)形狀相似度與距離接近度
針對時間序列數據進行相似度分析,可采用灰色關聯分析基本思想中的兩大類方法:一是根據時間數據序列曲線幾何形狀的相似程度來判斷關聯程度的大小,二是根據時間數據序列的接近程度來判斷關聯程度的大小。對于空間中的向量而言,一方面向量夾角越小,表示相似程度越高,關聯程度越大;另一方面,兩向量之差的模長越小,表示兩組數據間的距離越小,關聯程度越大。因此,可以利用向量夾角和向量差的模長來描述相似性與接近性關聯度。
對兩組向量數據之間的夾角即形狀相似度可通過公式(1)計算
(1)
對兩組向量數據的模長即距離接近度可通過公式(2)計算
(2)
在上述公式中,
根據這些理論,對兩組面板數據之間的相似判斷分為數值接近度與形狀相似度兩個角度討論。對數值型數據主要根據歐氏距離討論兩組數據之間的接近程度,對比例型數據則主要根據向量夾角來討論兩組數據之間的形狀相似程度,并將得出的兩組結果進行熵值法加權,得出樣本評分加以對比。
(三)離散度
采用上述方式處理數據后,通過熵權法確定不同維度形狀相似度與距離接近度的權重,并加權得到修正后的樣本相似度評分。
由于各項指標的計量單位不統一,在計算綜合指標前,先進行標準化處理,即把指標的絕對值轉化為相對值,從而解決各項指標的同質化問題。考慮到Matlab進行熵值法運算時的適用性問題,選擇正向極值法作為標準化方法,如公式(3)所示
(3)
通過這種方法標準化的數據雖然一定程度上保留了原數據的差異化,但因為距離接近度與形狀相似度兩個數據屬于負向數據,數值越大,表示對應的關聯度越低,因此將相似度評分計算結果定義為離散度,這一數值與關聯度相對應,離散度數值越大,表示關聯度越低,反之亦然。
三、數據說明與相似評價指標體系構建
(一)數據說明
高速公路收費站數據以車輛在高速公路兩收費站間的一段行程作為一個體,數據中包括車輛的眾多運行信息,但其中有部分數據與流量分析相關性不強。整理與選擇數據庫中的可用數據,表1為一個體中的有用數據字段。

表1 國內某省高速收費公路數據字段說明
(二)相似評價指標體系構建
基于全息樣本的多特征要求,本文考慮根據收費公路數據庫中字段,選擇構建全息樣本相似評價指標體系。指標選擇方法主要根據分析中常用的“5W1H”法,即“Why、What、Where、When、Who、How”,并結合交通流量的實際特征與數據庫數據的具體內容,考慮到運輸目的、運送人員、運輸貨物內容等與本研究的契合度較低,且在收費數據庫中難以量化,選擇根據時間結構、空間結構、軸型結構三個維度來構建全息樣本相似評價指標體系。
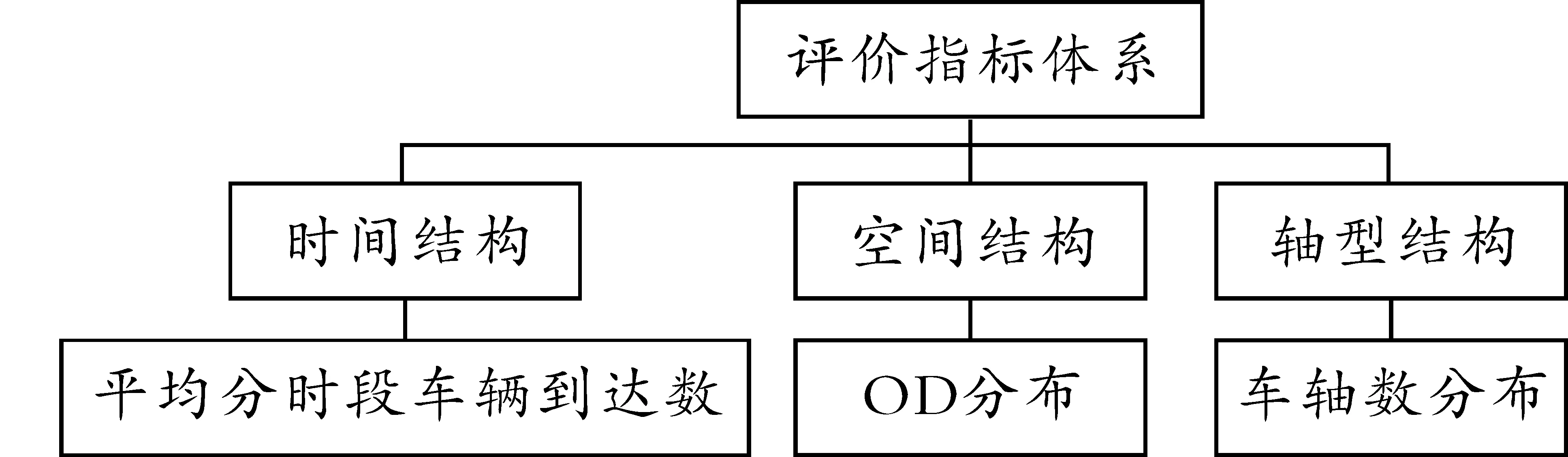
圖1 評價指標體系
其中,由入口時間整理出來的平均分時段車輛到達數可作為時間結構維度的主要考量數據,即何時車輛進入收費站;由入口站點與出口站點整理出來的OD分布數據可作為空間結構維度的主要考量數據,即車輛由哪來、到哪去的問題;針對車輛運行的多個要素,如車型、車軸、車重等,考慮到近期國家提出的將收費方式轉變為按軸型收費的政策,選擇車軸分布數據作為最后一個要素維度,也就是軸型結構維度的考量數據,這一評價指標在一定程度上能夠代表運送貨物的車輛自身信息與車重信息。根據相關指標,確定后的全息樣本相似評價指標體系如圖1所示。
若兩組高速公路收費流水數據在三個維度的數據分布上均表現為距離接近、角度相似,就可以認為兩組數據符合相似性的定義。
四、實例分析
全息樣本討論以國內某省2017年11月—2018年10月為期一年的27 330 513條高速公路貨運收費流水數據為依據進行分析。
(一)全息“月份”遴選
針對國內某省為期一年的高速公路貨運收費流水數據,排除一些錯誤數據后,運用SPSS軟件,以小時為單位,統計月平均分時段車輛到達數、月平均OD分布數據(175*156型矩陣)、月平均車軸構成數據。對數據進行比例處理,因篇幅有限,具體數值及處理結果略。依據公式(1)(2),求取三個維度各月份與全年數據之間的距離接近度和形狀相似度,兩者用角度與距離表示,結果見表2。
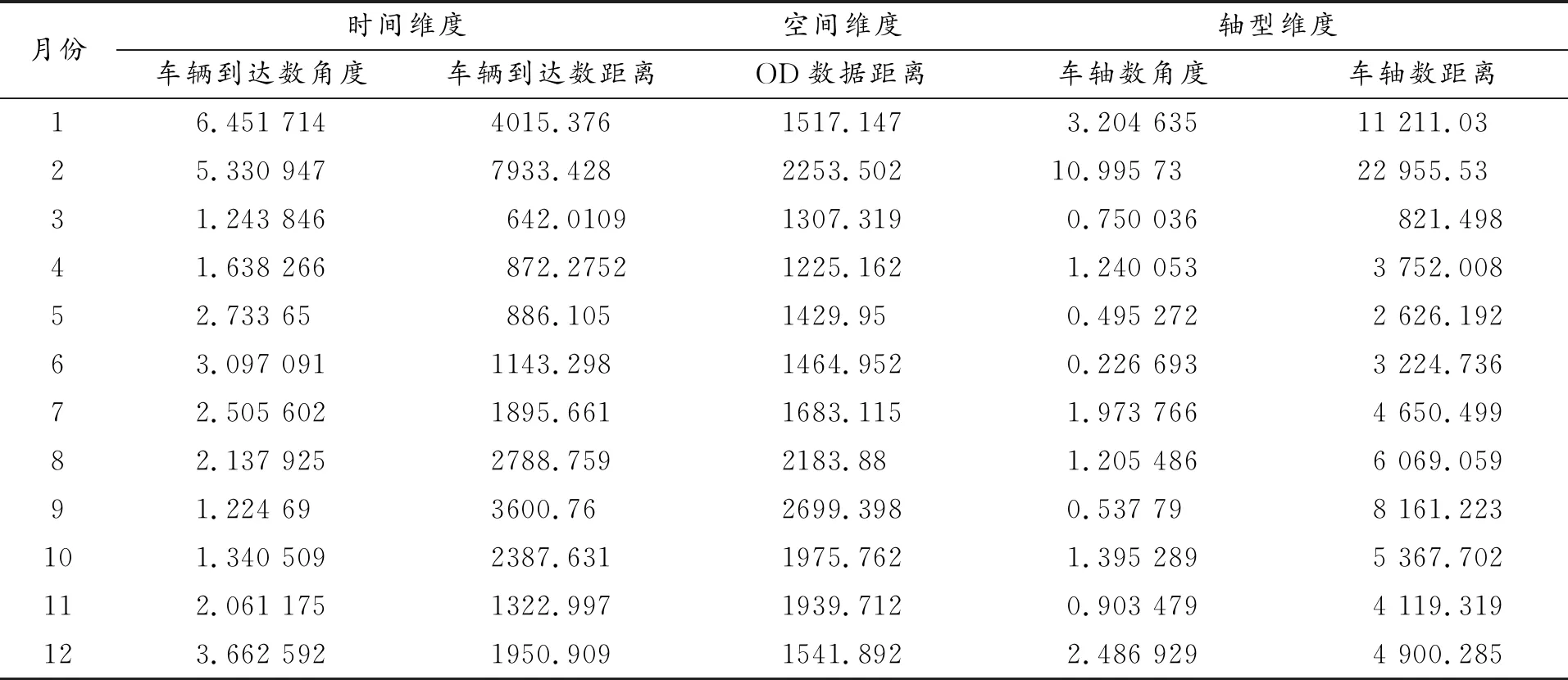
表2 三維度平均形狀相似度與距離接近度數據(月)
針對表2的數據,時間維度數據與結構維度數據采用熵值法,對角度與距離進行加權運算,得出對應維度離散度得分,空間維度因OD矩陣無法求取角度數據,故對OD數據距離結果進行歸一化處理,與其余兩維度保持統一度量。處理方式如下
(4)
處理后離散度得分見表3。
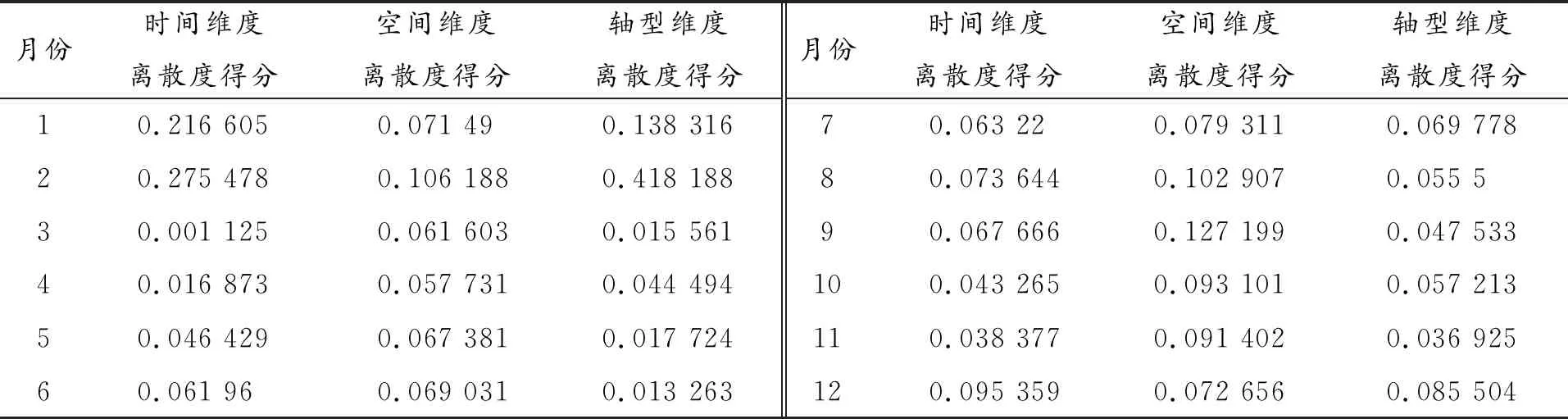
表3 三維度離散度得分(月)
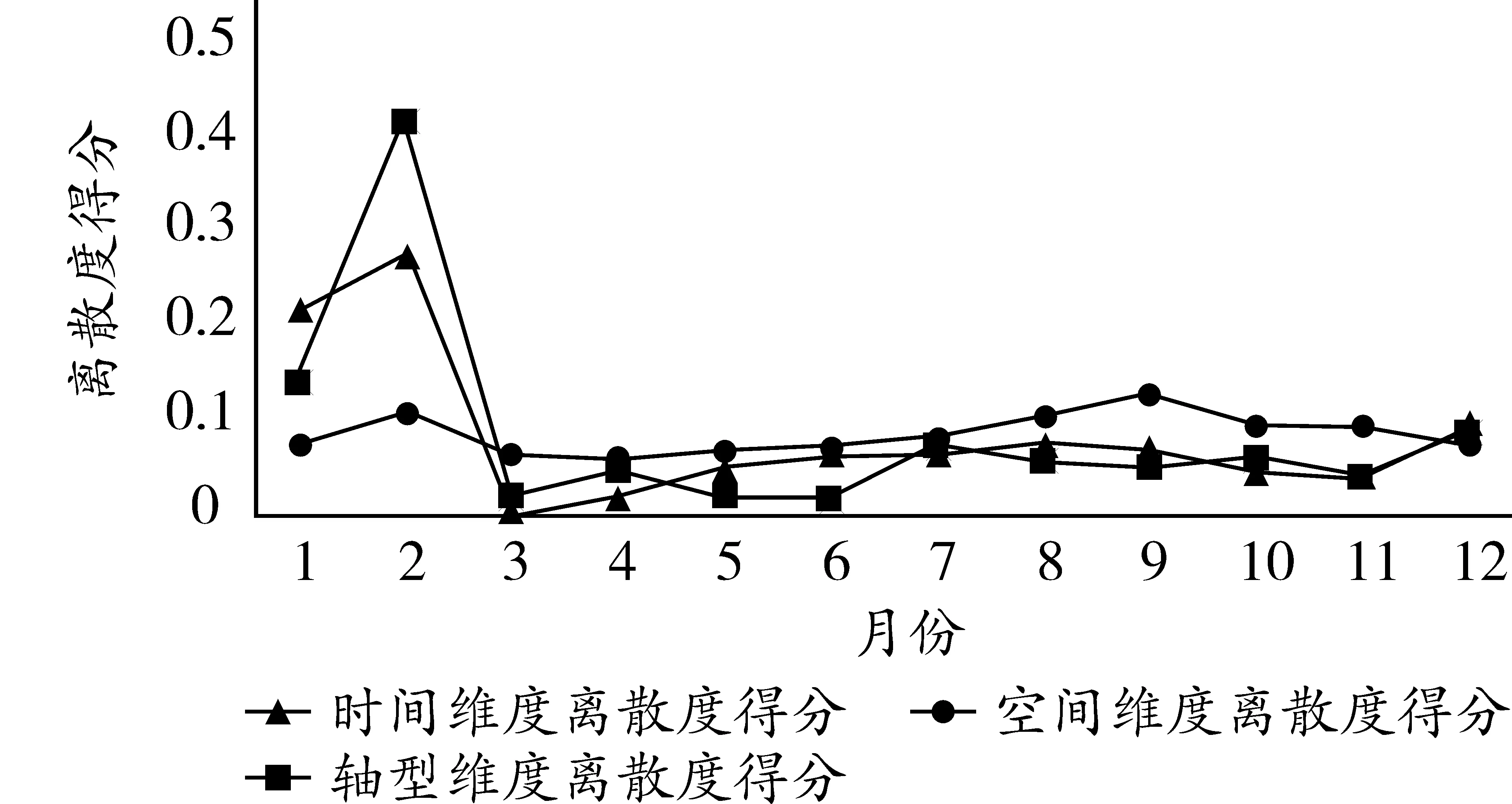
圖2 三維度月離散度得分
由圖2可以發現,三個維度雖然大致趨勢類似,但離散度最大和最小的月份有出入。其中,時間維度離散度最高的是二月,離散度最低的是三月;空間維度離散度最高的是九月,離散度最低的是四月;結構維度離散度最高的是二月,離散度最低的是六月。這說明如果不是特定的研究需要,任意單一維度對全年的代表性均有一定瑕疵,不能完整反映交通流量的所有特征。綜合考慮三個維度,進行全息樣本遴選。
針對這個問題,對表3中的三個維度數據進行熵權法賦權處理,得到表4和表5。

表4 各指標權重得分(月)

表5 綜合維度離散度得分(月)
將表5的離散度得分反映到圖3。
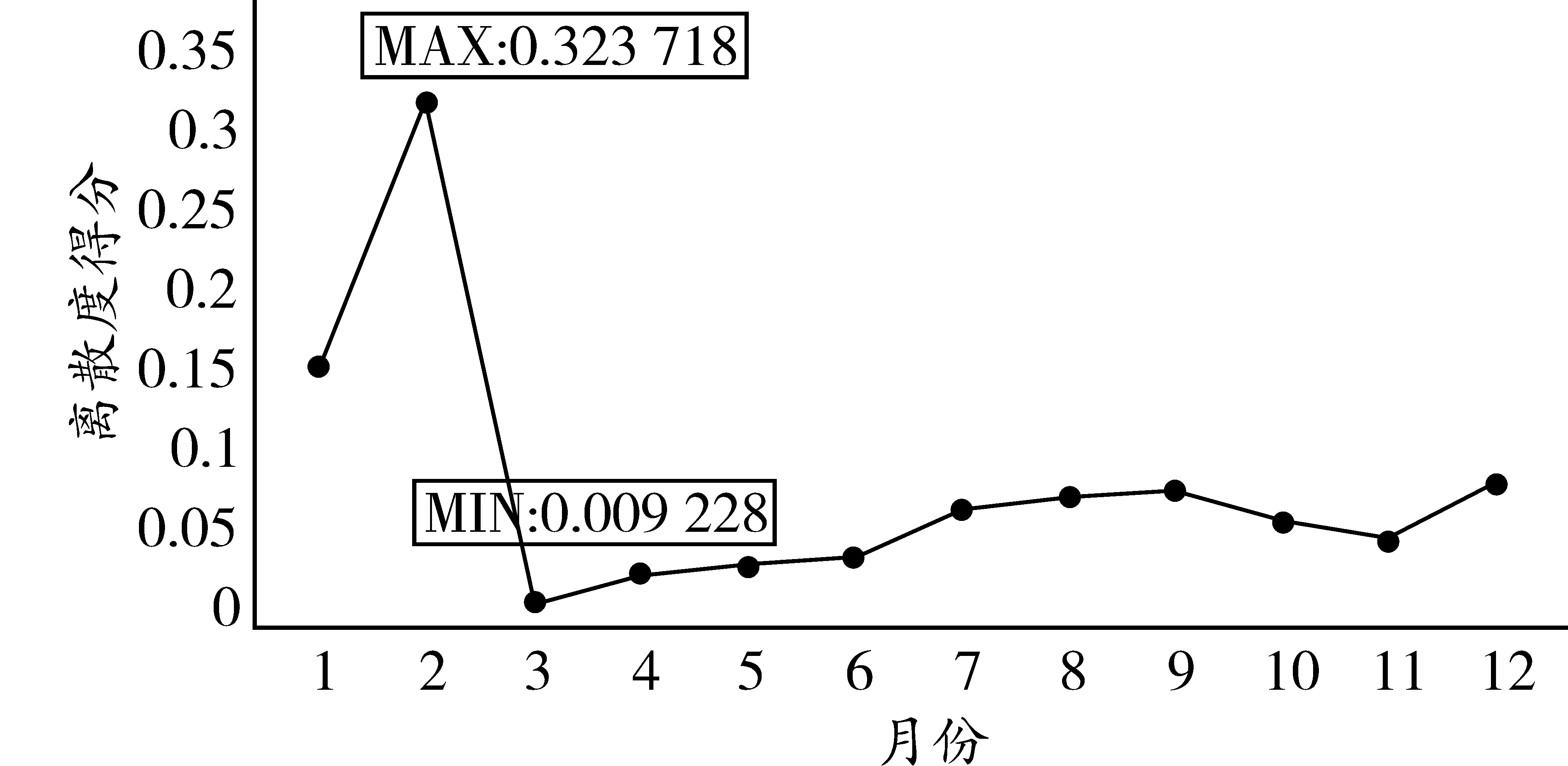
圖3 綜合維度月離散度得分
由圖3可以發現,三月是與全年離散度最低的月份,其次是四月與五月,而二月的數據則與全年數據有著較大的差別。在具體研究中,為了更精確的研究,可以采用三月的數據代表全年數據進行預測。
為驗證上文得出的結論,擬對幾個典型月份與全年數據進行圖表描述對比。通過分析全年各月份的離散度,決定選用一月、二月、三月、五月、九月、十一月的數據與全年對比,以便更直觀地體現全息月份的擬合度。可以發現,三月、五月與全年數據有較高擬合度,而離散度最高的二月則在數據量上差別較大,但趨勢均類似。
(二)全息“周”遴選
與全息月份遴選過程類似,繼續細分時間區間,根據常用日期所示的自然周進行相似度分析,即將2018年1月1—7日作為一周,結果見表6。
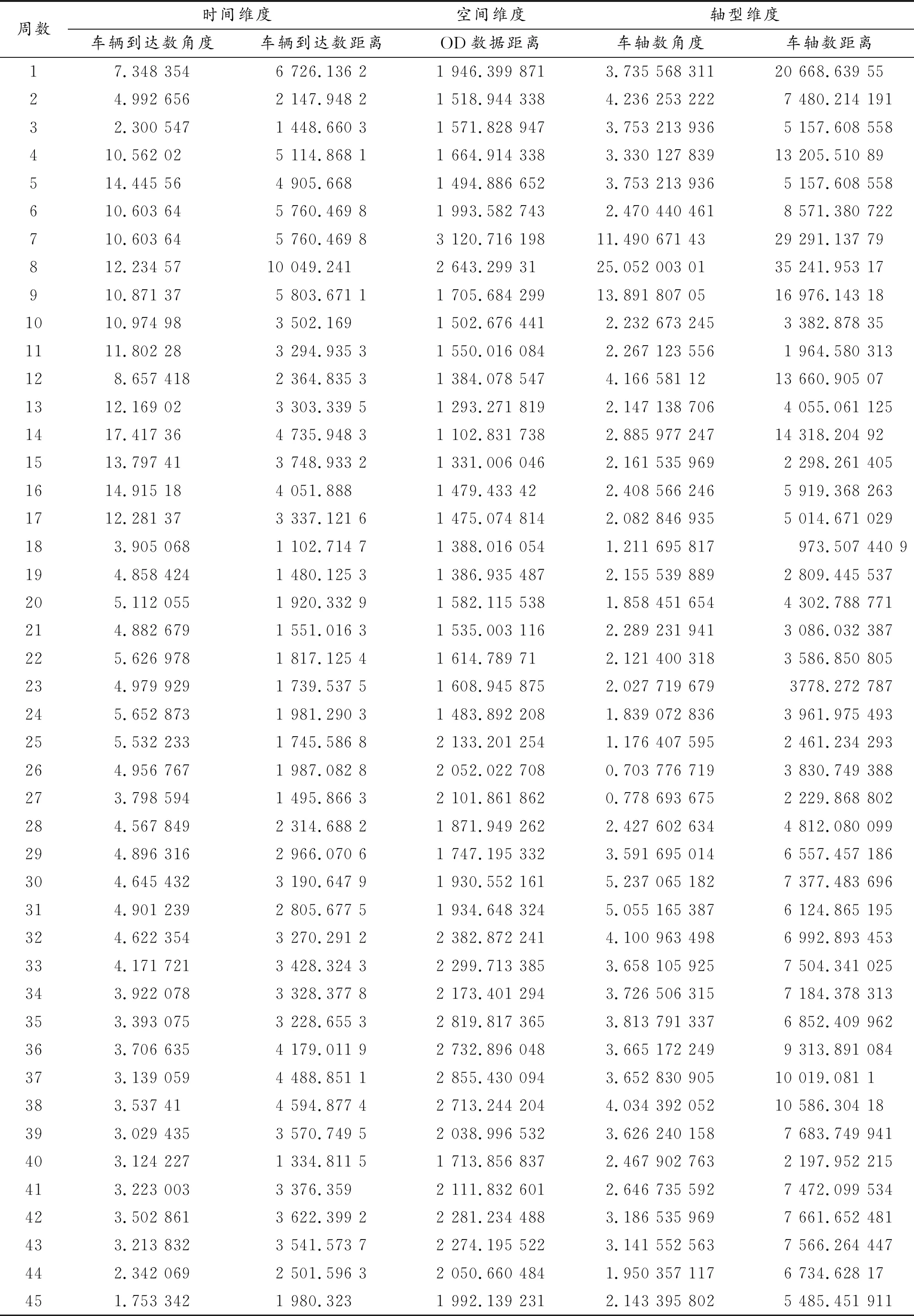
表6 三維度平均形狀相似度與距離接近度數據(周)
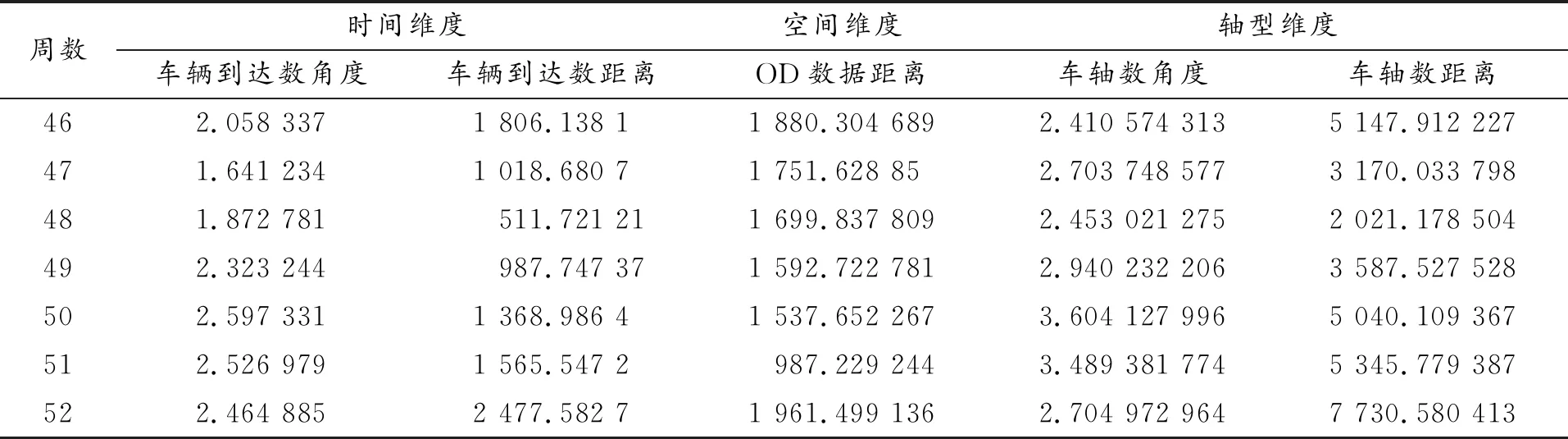
續表
針對表6的數據,通過熵值法確定權重,得到表7和表8。

表7 各指標權重得分(周)
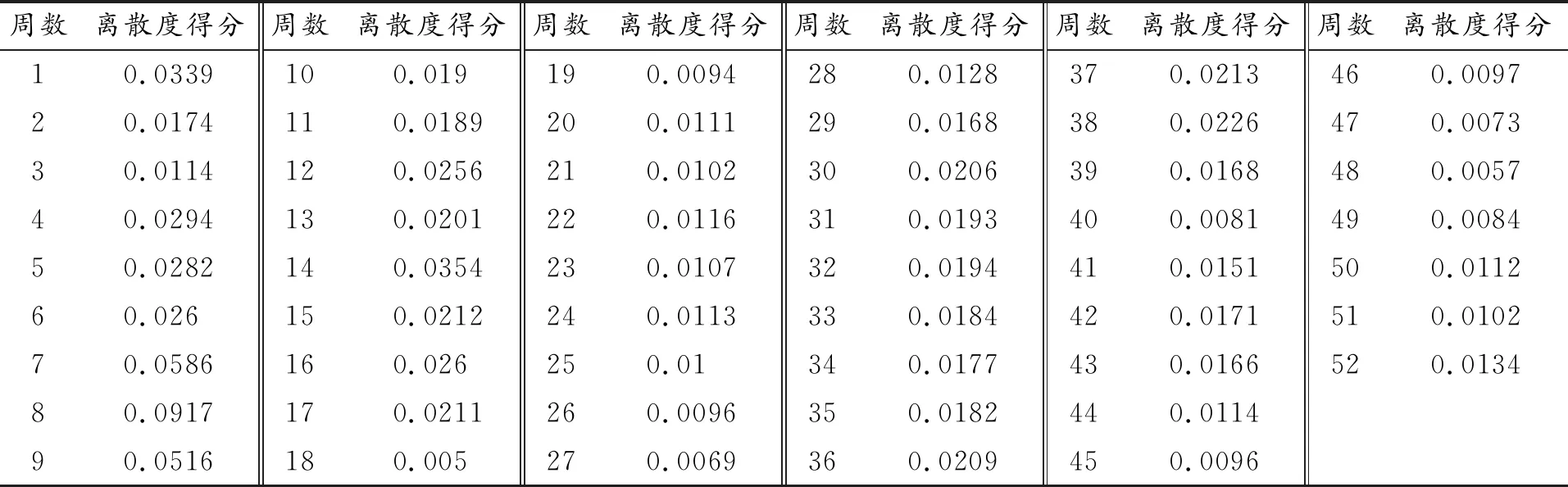
表8 綜合維度離散度得分(周)
考慮到周一級數據量較大,故將三維度獨自離散度數據整理,并結合表8,得到圖4所示離散度得分比較。
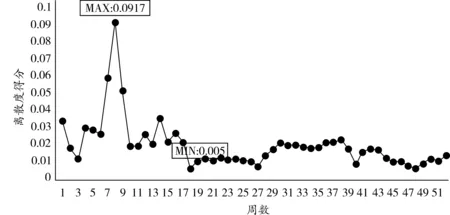
圖4 綜合維度周離散度得分
由表8可知,綜合維度下第8周離散度最大,第18周離散度最小,這一時間范圍的確定進一步佐證了全息月份遴選結果的可靠性,全息周樣本時間范圍與全息月樣本時間范圍出入不大。該全息樣本主要適用于可選數據區間較小時采用。在交通調查中,若只調查某一周數據來描述全年交通流狀態,應避開6—10周這一區間,著重考慮第18周附近數據。
(三)全息“天”遴選
除全息月份、全息周樣本外,交通調查中最常用的是抽一周內某一天去觀察交通流狀態。為了使樣本能夠更好地貼近顯示數據,選擇周幾是一個很重要的問題。主要對全年數據按周幾屬性歸類,分“周一、周二、周三、周四、周五、周六和周天”七天進行離散度分析。具體計算過程同上文所述。
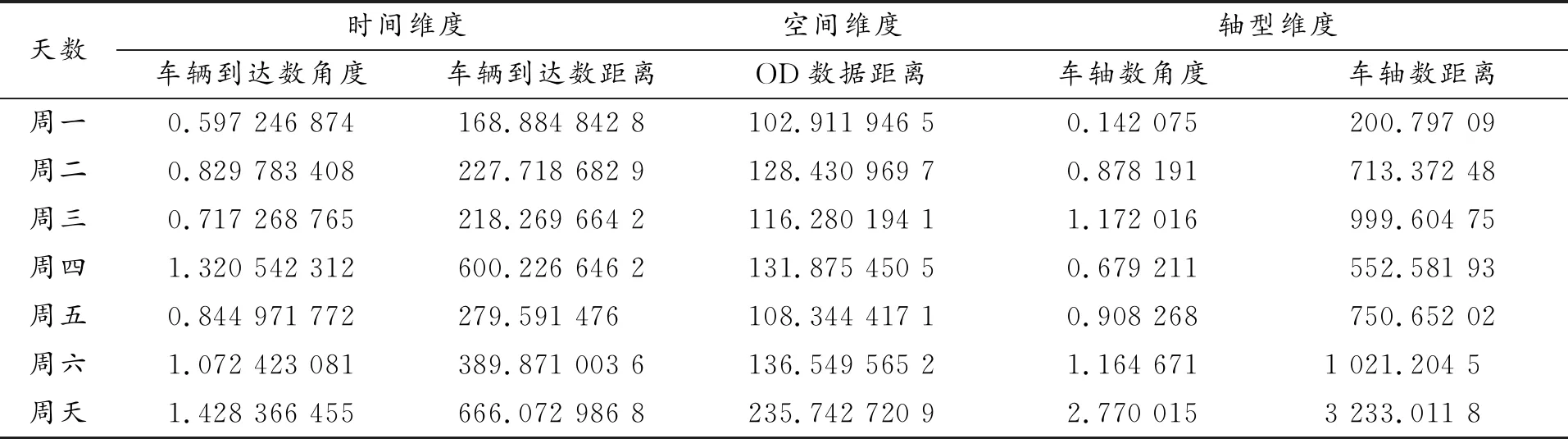
表9 三維度平均形狀相似度與距離接近度數據(天)
根據表9,通過熵值法確定權重,得到表10和表11。

表10 各指標權重得分(天)

表11 綜合維度離散度得分(天)
將表11計算的天離散度得分反映到圖5和圖6。
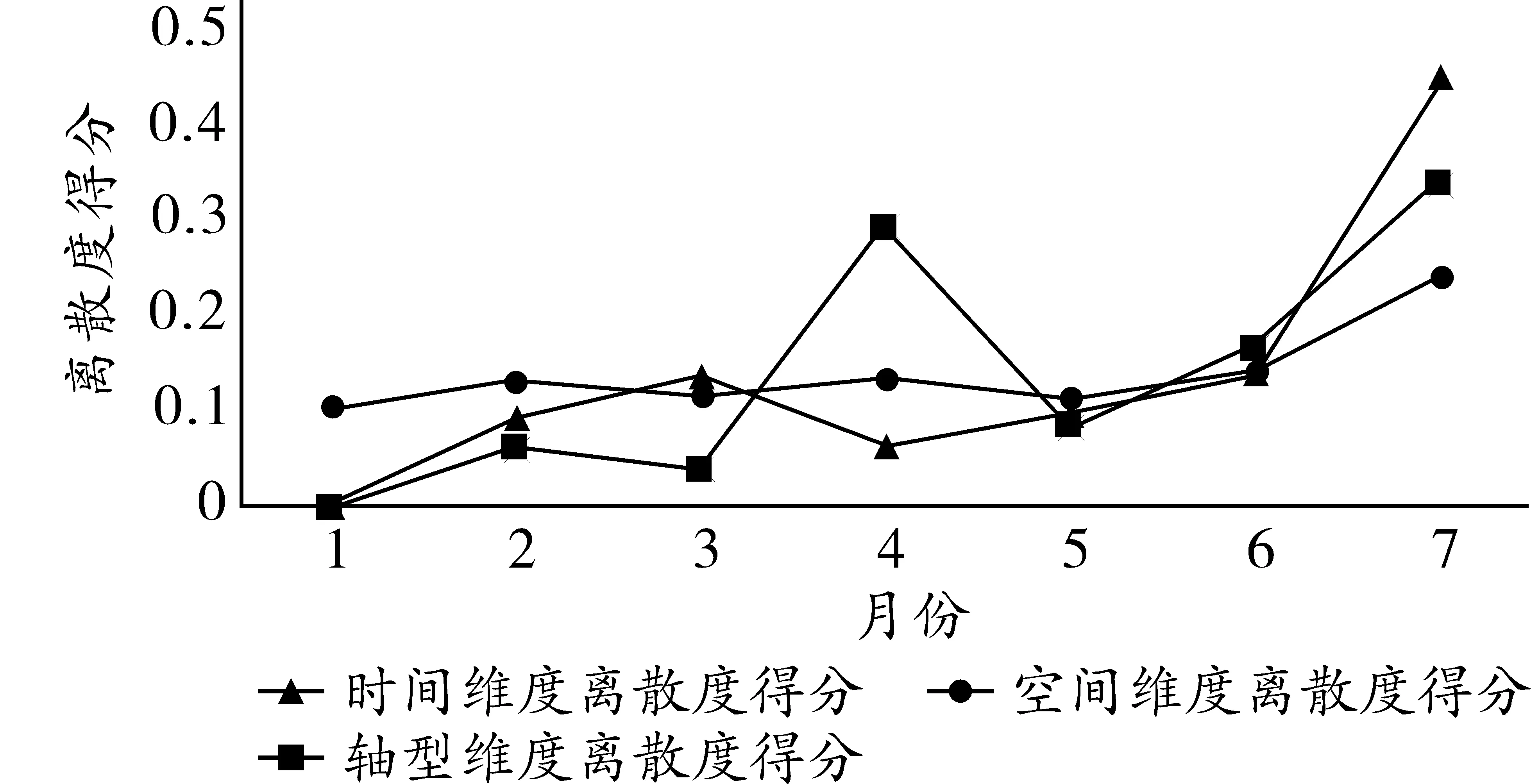
圖5 三維度天離散度得分
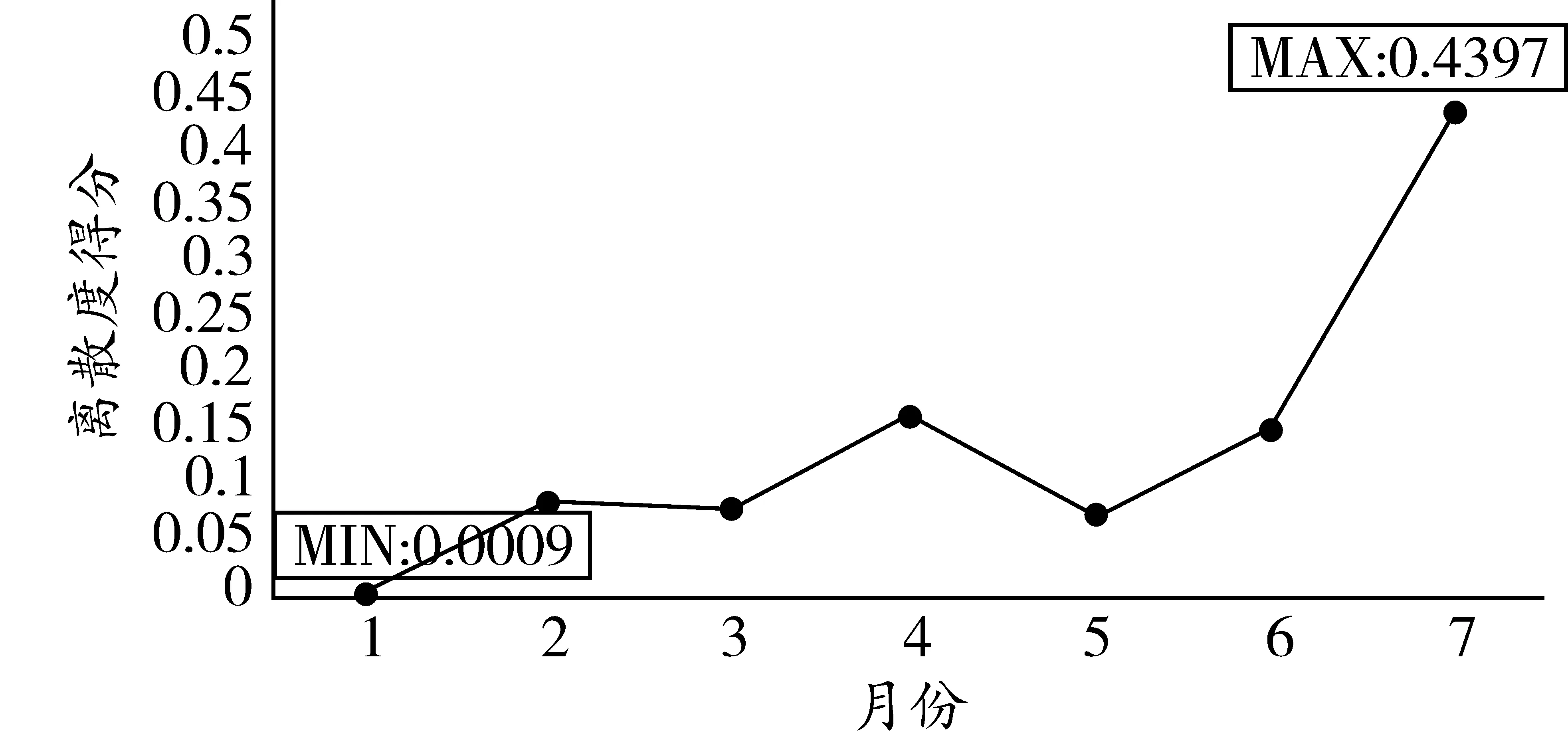
圖6 綜合維度天離散度得分
相較于全息月份與全息周,全息天的結果更明確。其中,在綜合維度下,周一是離散度最小的一天,周天的離散度則相對最大,與實際的認知相契合。故在實際交通調研全樣本中,若只能選取某一天的樣本進行交通流描述或預測,最好選取周一的數據。
五、結論與展望
(一)結論
通過對國內某省高速公路收費站流水數據庫貨車數據的分析,測算每月貨車流量數據與全年貨車流量數據之間的離散度值,對月份排序,得出一個較為符合事實的全息樣本。
第一,建立一個基于時間結構、空間結構、軸型結構三種維度的評價體系,并在高速公路收費站流水數據庫中,針對每個維度選擇一個較有代表性的字段作為分析比對字段。
第二,根據實際工作中的使用需要與可度量性,依次以自然月份、周、天為樣本時間區間,測算全息樣本離散度大小。
第三,探討不同維度下的全息樣本選擇方案,為特定目的的研究提供樣本選擇方案。并針對單維度衡量失真的情況,通過熵值法科學地對不同維度賦予權重,綜合得到各樣本在相似評價指標體系下的綜合離散度,為交通研究提供可靠的樣本選擇依據。
第四,綜合考慮評價體系中的三種維度后,在樣本區間為月份時,三月是作為全息樣本的最佳選擇,其次是四月、五月等離散度較低的月份,且其中離散度特別高的二月、一月不應作為樣本選取的考慮范圍。此外,在全息周的遴選過程中,第8周離散度最大,第18周離散度最小,這一時間范圍與以月份為樣本區間時遴選的結果出入不大。當著重考慮一周內的哪一天更適合作為樣本時,在測算結果中發現周一是離散度最小的一天,周天的離散度則相對最大。
(二)展望
通過系統討論與分析,對各月與全年的相似程度進行度量,仍存在一些繼續研究的方向。第一,在實例分析中主要數據是國內某省全年兩千萬余條數據,數據量充足,但作為時間序列數據方面,時間跨度僅一年,涉及區域僅一省,成果存在一定程度的偶然性,可尋找更多年份、更多省份數據對現有結論進行佐證,得到普適性的結論。第二,目前研究主要是針對貨運數據,若數據庫充足,可考慮分析客運數據,并比價討論客貨運的區別。第三,全息月份是基于實際需要確定的最佳樣本選擇,后續在學術研究方面可通過時間序列數據的遍歷算法,尋找與全年數據庫相似度最高的最短全息樣本。
猜你喜歡
法律方法(2021年4期)2021-03-16 05:35:10
考試與評價·八年級版(2018年7期)2018-12-31 00:00:00
中國交通信息化(2017年3期)2017-06-08 06:09:28
財經(2017年2期)2017-03-10 14:35:35
中國交通信息化(2016年9期)2016-06-06 07:42:10
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
小說月刊(2014年4期)2014-04-23 08:52:20
河南科技(2014年18期)2014-02-27 14:15:06
