C-V2X邊緣緩存中文件請求預測機制①
2021-01-21 06:48:44蔡嘉敏高楷蒙徐哲鑫
計算機系統應用 2020年12期
關鍵詞:模型
蔡嘉敏,高楷蒙,鄭 云,徐哲鑫
(福建師范大學 光電與信息工程學院,福州 350007)
將C-V2X 業務部署在MEC 平臺上,可以更好地降低數據傳輸時延,緩解基礎設施的計算與儲存壓力,降低大量數據回傳所造成的網絡負擔,提供高質量服務.然而,面對海量的數據和設備成本的考量,MEC 邊緣緩存節點的緩存容量有限,使得合理部署緩存內容成為亟需解決的問題.因此,準確預測用戶的內容需求將起重要作用.
據研究發現大部分用戶請求的都是流行的文件[1,2],少部分請求不流行的文件.這一文件請求分布與Breslau等觀察到的請求網頁相對頻率遵循Zipf 定律[3]極為相似.然而,這一請求分布描述的僅僅為某一時刻的靜態請求.事實上,大部分文件的熱度會隨著時間的推移逐漸減弱,新內容的出現也會影響分布規律.除此之外,用戶往往更加青睞于點擊請求自己感興趣的文件[4],所以流行度分布的影響面極廣,具有動態性[5,6].進一步的研究表明,網絡中用戶的前后訪問行為有一定的時間間隔[7],針對這一特點,科研人員在研究用戶請求部分中加入了請求生成時間間隔服從泊松分布或固定值.不可否認的是,這一改變增強了研究的可靠性,但在請求前后時間間隔方面,泊松分布的適用性還有待研究.
在預測用戶請求方面,線性回歸進行預測[8,9]的研究占據相當大的比例,但由于在預測過程中存在不可測因子的影響,使其實用性受到一定限制.考慮到偶然因素造成的影響,常運用短中長期預測的時間序列預測法.長短時記憶網絡(LSTM)是當前比較流行的深度學習模型之一,它類似于一個記憶器,模擬了人類的認知過程,能較好地運用于文件請求流行度的預測[10].
綜上,本文將針對C-V2X 的城市場景,以基站作為MEC 邊緣緩存節點,根據大量用戶請求,探索出基站處文件流行請求規律,實現流行文件在基站處的預測和緩存有效減少數據傳輸時延等阻塞問題.
1 基于SUMO 的城市場景交通流模型
以福州地圖為例,設定了四縱四橫的車聯網.為了更貼近實際交通情況,記錄了福州早晚高峰路口處紅綠燈時長、車流量和地面可行駛方向等相關數據,同時在福州交警軟件上進行實時觀測.最后,介紹輸出數據文件,并進行簡化處理.需要說明的是,預測模型是數據驅動,在不同的城市場景下,可通過重新構建請求的訓練數據提升預測模型的適應性,但并不影響本文所提出研究方法的通用性.另外,預測模型可部署為在線學習模式,在深夜等車流量很少的時段通過數據統計算法重構數據集并完成模型訓練.
1.1 網絡構建
為模擬早晚高峰時間段的交通流情況,設置兩個早高峰駛出口,兩個晚高峰駛出口.基站則布置在縱橫四條路段的中間位置,在基站數量最少的情況下覆蓋整個交通網絡.交通地圖如圖1所示,其中,L/R-2-*及U/D-*-2 為交通網的主干道,其余為輔道,各路段名稱、行駛方向、基站及基站覆蓋范圍均已標出.
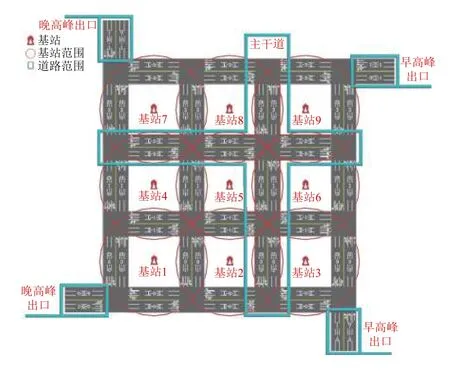
圖1 交通流網絡
1.2 車流軌跡建模
通過實地考察,對福州的上浦路口、浦上大道、南門兜附近路口和寶龍廣場附近路口等位置的早晚高峰紅綠燈時長、車道地標轉向和車流量進行了實時記錄.并且在周一至周五早晚高峰期間,參考福州交警軟件,觀察各路段的交通堵塞狀況和路口車流量狀況.在紅綠燈時長方面,對于車流量多的方向,信號燈通常設為80 s 到95 s;對于車流量較少的方向,信號燈通常設為30 s 到45 s;警示信號黃燈為3 s 到5 s.車流量部分記錄結果如表1所示.綜合以上考察,共同設定SUMO軟件[11]的仿真參數.
1.3 數據輸出及預處理
在SUMO 的輸出文件中,fcd.xml 文件包含時間、車輛名稱、車輛位置、車輛速度和車輛所在道路等重要數據,故最終選擇fcd.xml 文件作為輸出使用,并進行了數據預處理,如程序結構1 所示.由于fcd.xml 文件過大不能一次性讀入,則將fcd.xml 文件切分成32個62 MB 左右且與原文件結構一致的小文件,依次經過Matlab 處理,形成一個包含車輛名稱、坐標、速率及道路信息的TXT 文件.

表1 福州路口車流量記錄
2 文件請求模型及預測
文件流行度變化具有時變性,請求間隔也存在一定規律.為了改善分布模型中缺乏文件流行度實時性的弊端,對網易新聞進行實時數據采集.根據車流量趨勢來合理分配流行度分布,利用LSTM 模型能利用歷史信息較好預測的優勢,將其作為深度學習預測模型.
2.1 數據采集
考慮到文件流行度具有時變性和請求之間存在間斷性的特點,在請求間隔方面,本文通過統計用戶瀏覽文件的逗留時間,利用Matlab 擬合出請求間隔分布.在文件流行度方面,參考國內各大音樂、新聞、社交等網站,發現大部分網站存在一定的不適用性.例如,信息更新狀態時間跨度太長,信息數量較少、種類單一,大部分信息無法長期跟蹤統計,在統計播放量、閱讀量等可利用值時,無法精確到個位數乃至千位數,導致結果不準確,頁面復雜程度較高,數據在短時間內無法爬取完成,導致數據之間存在時間差,真實性下降.綜合評估后,本文采用八爪魚采集器收集網易新聞的數據集.網易新聞是國內第一新聞客戶端,具有實時性、分類合理性、數據量多和易采集的特性.數據采集過程中,自定義模板流程如圖2所示,詳細配置后,每個小時執行一次.
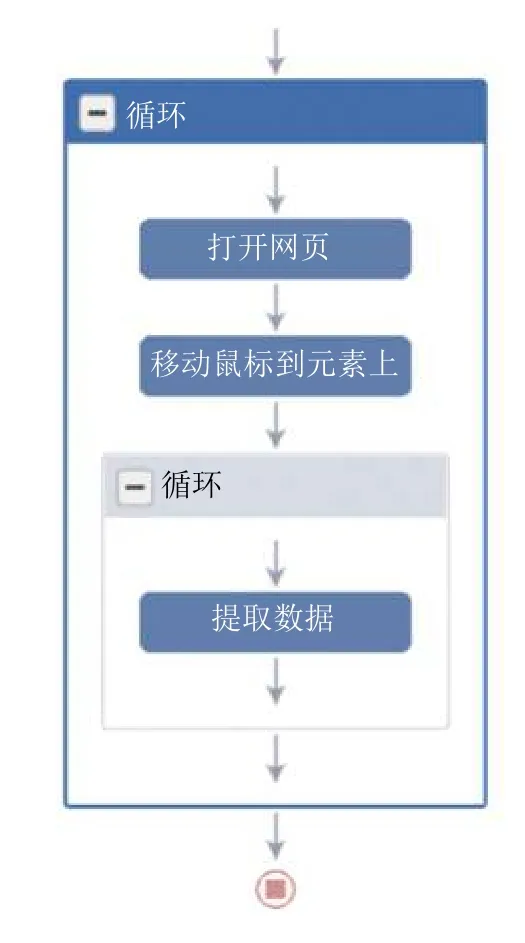
圖2 采集模板
在采集到的數據集中,有11 種類型,共2116 條內容.對于具體類型和內容,先篩選所有在24 小時內出現過的內容進行合并內容處理,其中某些時段因瀏覽量較少而無法進入排行榜的內容,對應時段的點擊量記為零.因日常生活車輛用戶請求與車流量變化密切相關,本文對兩者分別進行仿真統計,并對比趨勢進行相應數據集篩選匹配.仿真車流量如圖3所示,點擊量的統計結果如圖4所示.
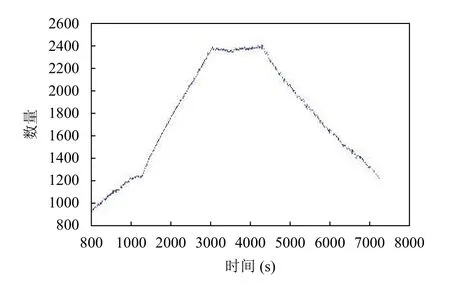
圖3 車流量
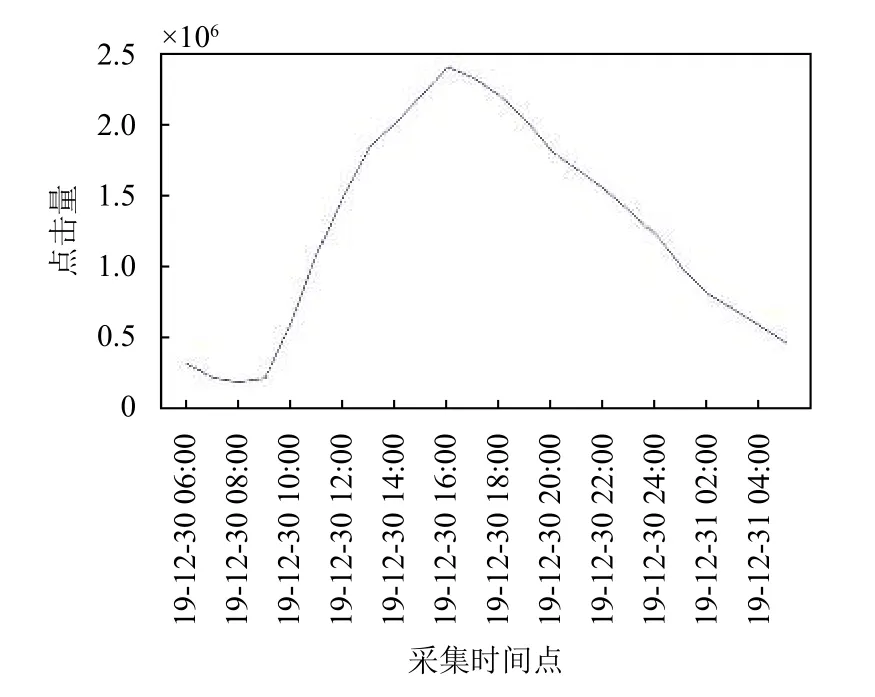
圖4 各時間段總點擊量
2.2 文件請求生成
車輛在運動過程中服從相應時段的請求分布,實現如算法2.在傳輸過程中,文件被切割為若干塊,塊之間傳輸需要一定的時間間隔,因此設定在請求間隔內,用戶對某個文件的請求是唯一不變的.具體請求生成方式如下,根據收集到的數據集,將流行度分為15 個時間段,而每一時間段的請求分為11 種不同的類型,每個類型包含若干文件.車輛生成請求時,根據其所在的時段對應的流行度分布,利用請求類別概率得到請求所屬類別,再根據該類別中各文件在該時刻的歷史平均請求概率生成最終請求.因此,將類別和文件的相關性以概率的方式呈現.為減少偶然性,采用每輛車請求20 次的平均值.

算法2.車輛文件請求及接收輸入:TXT 文件、文件流行度、請求間隔分布輸出:各基站各個時間點接收各文件的頻數1.BaseStationaddress←定義基站位置2.vehiclename←所有出現過的車輛名稱3.requestcount←車輛請求間隔計數器4.p←導入請求間隔分布

5.sort_p←導入類型文件流行度分布6.probability_n←導入流行度分布 (n 為類型編號)7.while T whil XT 文件讀取結束do 8.e 當前時刻結束 do 9.xArray(m)、yArray(m)、nameArray(m)←車輛位置及名字(m 為車輛數目)10.end while 11.popular_interval←當前時間對應的流行度分布12.request.count=request.count-1→計數器減一13.for m do (m 為車輛數目)14.tablepos←鎖定車輛在計數器中的位置15.if 車輛計數器等于0 或出現的新車輛 then 16.request(tablepos,2).count←按請求間隔分布生成請求間隔17.sortrequest,beforerequestsort←按類型流行度分布生成請求并記錄18.filerequest,beforerequestfile←按內容流行度分布生成請求并記錄19.BaseStationnum←車輛在幾號基站范圍20.if 在接收范圍 then 21.BaseStation←對應基站數組記錄22.else 23.contitune;24.end if 25.else 26.BaseStationnum←車輛在幾號基站范圍27.if 在接收范圍 then 28.BaseStation←對應基站數組記錄29.else 30.continue;31.end if 32.end if 33.end for 34.end while
2.3 基于LSTM 的文件請求預測
LSTM 是為了解決RNN 訓練過程中梯度消失問題而提出的,其中vanilla LSTM 是當前應用最為廣泛的一種LSTM 模型[12].在文中則直接利用基本的vanilla LSTM 來構建預測模型,算法3 實現.
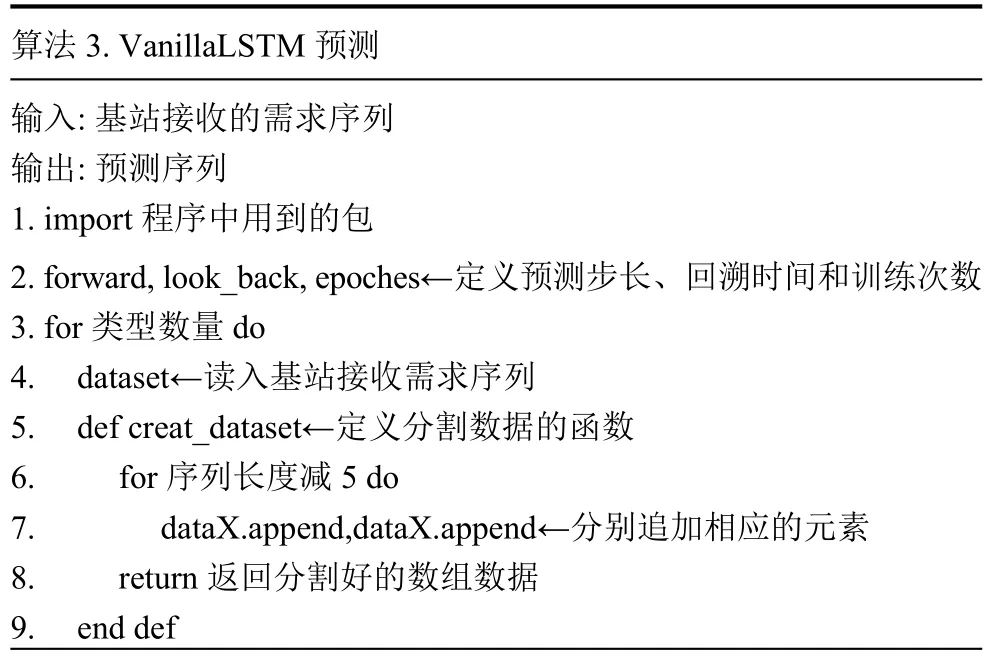
算法3.VanillaLSTM 預測輸入:基站接收的需求序列輸出:預測序列1.import 程序中用到的包2.forward,look_back,epoches←定義預測步長、回溯時間和訓練次數3.for 類型數量 do 4.dataset←讀入基站接收需求序列5.def creat_dataset←定義分割數據的函數6.for 序列長度減5 do 7.dataX.append,dataX.append←分別追加相應的元素8.return 返回分割好的數組數據9.end def

10.numpy.random.seed(7)(生成隨機種子)11.scaler.fit_transform←將數據縮小到0-1 之間12.train_size←定義訓練集大小13.train,test←將數據集切分為訓練集和測試集14.look_back←定義前瞻步長15.creat_dataset←分割訓練集和測試集16.trainX←重新設置數據格式17.model←構建LSTM 網絡18.model.fit←帶入訓練集進行訓練學習19.forward←定義預測步長20.for 預測步長 do 21.predict←預測一步22.result←累加記錄預測一步的結果23.train_pred←前一位剔除,補新預測結果24.end for 25.scaler.inverse_transform←將預測結果正則化26.rmse←計算真實值與預測值的誤差27.plot←預測效果可視化?
3 文件請求預測的仿真及分析
在前述車流信息基礎上,對實時采樣的交通網絡文件進行詳細的參數設置.根據車流量與用戶請求量的相關性,對數據集進行篩選處理,建立時變型類型流行度和文件流行度分布,作為用戶請求的依據.在預測方面,設置若干個回溯時間長度,通過均方根誤差的對比及分析,選擇出預測效果較好的參數值作為最終預測模型參數.
3.1 仿真參數設置
3.1.1 交通網絡參數設置
本文設置交通網如圖1所示.除出口路段外,每條道路長度為1 千米.道路的轉彎率規則則按照出口方向進行調整,再結合早高峰特點,則車輛向右行駛幾率更大,且在主干道行駛幾率更大.在路口中,綠燈的時長往往根據車流量進行設置,對于車流量較多的道路,綠燈時長更長,黃燈警示時間也相對略長.反之亦然,具體參數如表2所示.
在SUMO 中,根據表2進行參數設置,并在SUMOGUI 中運行.以節點11 為例,在仿真時間為25 分12 秒時的仿真畫面效果如圖5所示.
3.1.2 數據集篩選
由于文件流行度具有時變性,則按照不同時段內的文件流行度總點擊量與車流量趨勢進行對比排列.實際采樣中,以小時為單位進行流行度采樣,采樣時間為24 小時.
由于流行度變化和車流量趨勢的契合需要,則適當縮短文件流行度的持續時間,使其范圍為早晚高峰兩小時.最終篩選數據集時間為12月30 號早10 點到晚12 點.在早高峰最大車流量穩定階段,選取點擊量最大的數據集進行匹配,其余數據集匹配則盡可能均勻分布.將車流量和總點擊量歸一化處理后,進行對應排列的結果如圖6所示.
表2 SUMO 仿真參數
圖5 SUMO 仿真場景
為了生成不同時段的新聞類型流行度分布和文件流行度分布,分別求出不同類型不同時間段下的類型請求概率和文件請求概率,如式(1)所示.
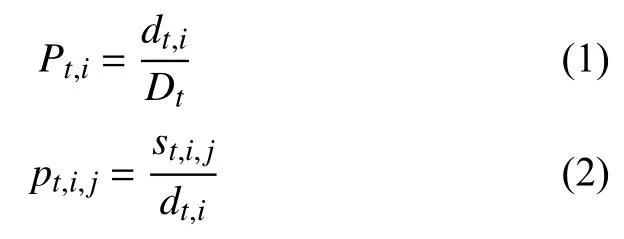
其中,Pt,i是第t個時間段,第i種類型的請求概率,pt,i,j是第t個時間段,第i種類型中第j條文件的請求概率,Dt是第t個時間段的總點擊量,dt,i是第t個時間段的第i種類型的點擊量,st,i,j是第t個時間段,第i種類型中第j中文件的點擊量.
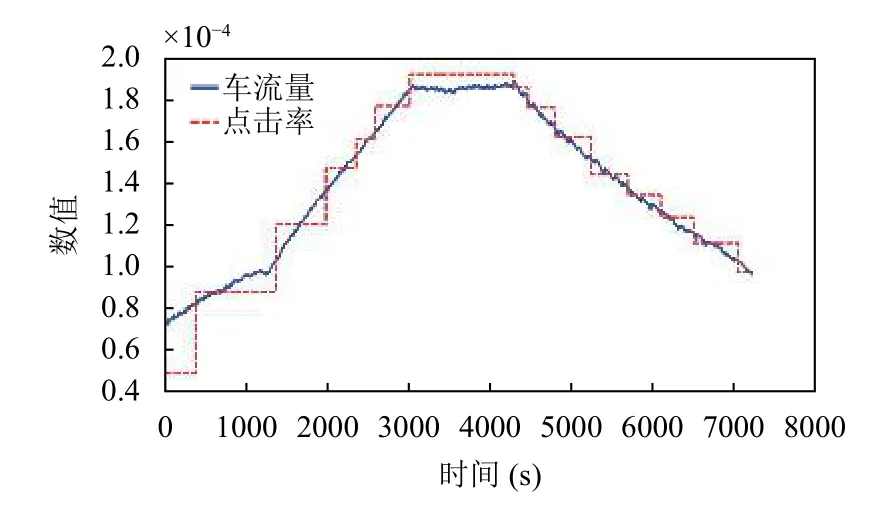
圖6 場景內全部車流量與點擊量的匹配
為了方便統計,將類型和文件分別進行編號處理.由于不同類型的請求概率變化細微,且在不同時間段下變化趨勢一致.選擇3 個時間段的請求概率進行展示,如圖7所示.其中新聞類型下,部分文件在各個時間段內的請求概率如圖8所示.由圖可得,文件流行度具有時變性.
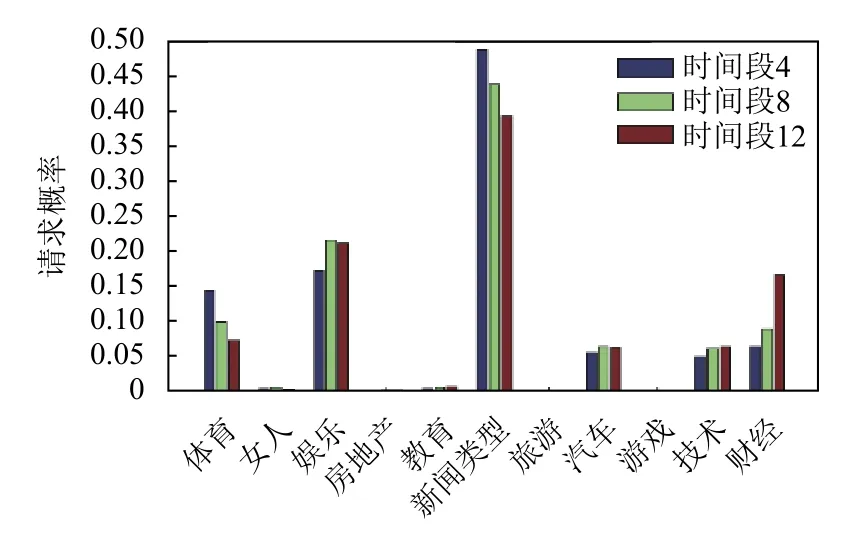
圖7 類型請求概率
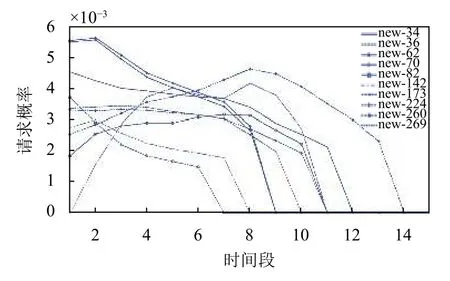
圖8 新聞類部分文件請求概率
3.2 仿真結果分析
3.2.1 SUMO 仿真結果
設置參數是否符合實際早高峰場景是我們要考量的問題之一,即主干道車流量與普通輔道車流量關系、出口處車流量與總體車流量、大部分路口峰值是否唯一等設置.為了可以直觀看出,對full.xml輸出文件進行數據處理,如圖3所示為總體車流量趨勢圖,通過觀察趨勢可了解到,總體仿真時間內只有一個峰值,且峰值有一定的持續時間,比較符合早高峰的趨勢.
如圖9所示,大部分向出口方向行駛的路段車流量相對較多,且有一個峰值.而對于主干道ER21 和EL21而言,是交通場景中擁堵最嚴重的地方,車流相對穩定且多,一定程度上模擬了極為擁堵的場景.如圖10所示,因主干道位置偏上,導致部分檢查路口向上車流量明顯多余向下,小部分交叉口反之.同時可明顯看出,曲線均有不同程度的波動,這是由路口紅綠燈導致的車流局部堆積與流動.
3.2.2 VanillaLSTM 模型預測及結果
這一部分中,本文基于vanillaLSTM 模型,采用多步預測的方式.在Keras 深度學習框架中,通過構建Keras Sequential 的順序模型進行預測分析.模型結構如圖11所示,由LSTM 層和全連接層兩個模型層堆疊而成.其中,LSTM 層返回維度為4 的向量序列,全連接層返回最后預測的單個結果.選擇均方誤差RMSE 為損失函數loss,adam 為優化器.在模型訓練中,由于數據量較少,將所有的樣本做為一個batch,epoch 設為30 次進行迭代,得到最優權重分布的模型.同時為了評估vanillaLSTM 模型的性能,本文選取67% 的訓練集供模型訓練,通過設置回溯時間長度為5 到150 的范圍,其中前30 的間隔差距為5,后120 的間隔差距為10,來預測未來20 秒平均請求次數.
基于以上參數設置,本文采用通過計算比較9 個基站預測均方根誤差的方式,篩選出預測效果較好的參數,得到的誤差是在概率意義下均方誤差最小.考慮到請求基數的大小會對均方根誤差的比較產生一定的影響,故本文只選取請求概率在所有類型中居中的娛樂類型計算所得的均方根誤差來作為比較標準,結果如圖12所示.其中,橫向為各個回溯時間長度,縱向為均方根誤差.
由圖12可以看出,當回溯時間長度為15 時,各基站間的均方根誤差較小,且整體水平處于較低的位置.且如圖13所示,基站一到基站九的預測loss 值收斂較快,故設置回溯時間長度為15,預測長度為20 對基站類型文件進行預測.對比下,二號基站具有位置優勢,則二號基站娛樂類型預測結果如圖14所示.其中,橫向顯示的是預測點前后共300 秒的范圍,縱向是類型請求頻數.
其他各基站各類型的預測結果均由計算統計均方根誤差的形式呈現.如圖15所示.以以基站為基準,統計類型均方根誤差的基站-類型統計時,會因請求基數大小產生一到兩個較大誤差值,如新聞和體育這類請求頻率較大的類型.整體誤差分布較為均勻.同理,以類型-基站統計時,請求基數會造成影響,與圖7相比,類型變化趨勢較為一致.
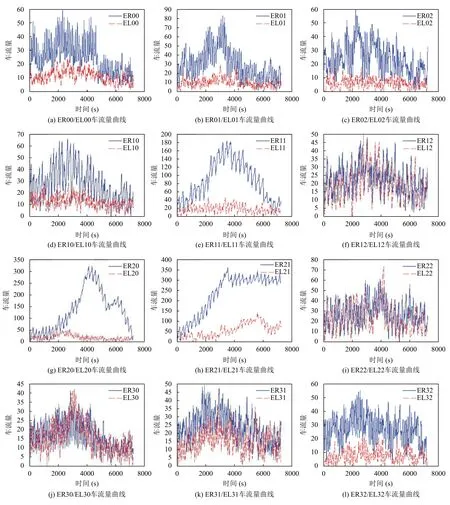
圖9 R/L 方向車流量
圖10 U/D 方向車流量
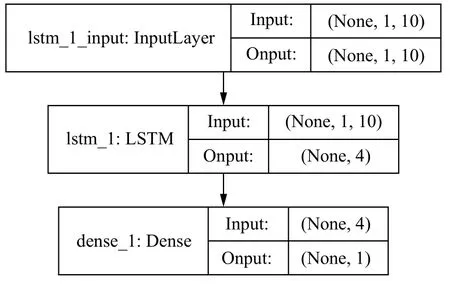
圖11 模型結構
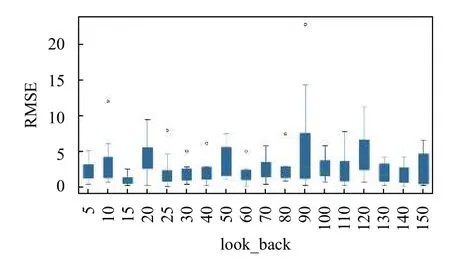
圖12 不同look_back 中娛樂類型的RMSE 值
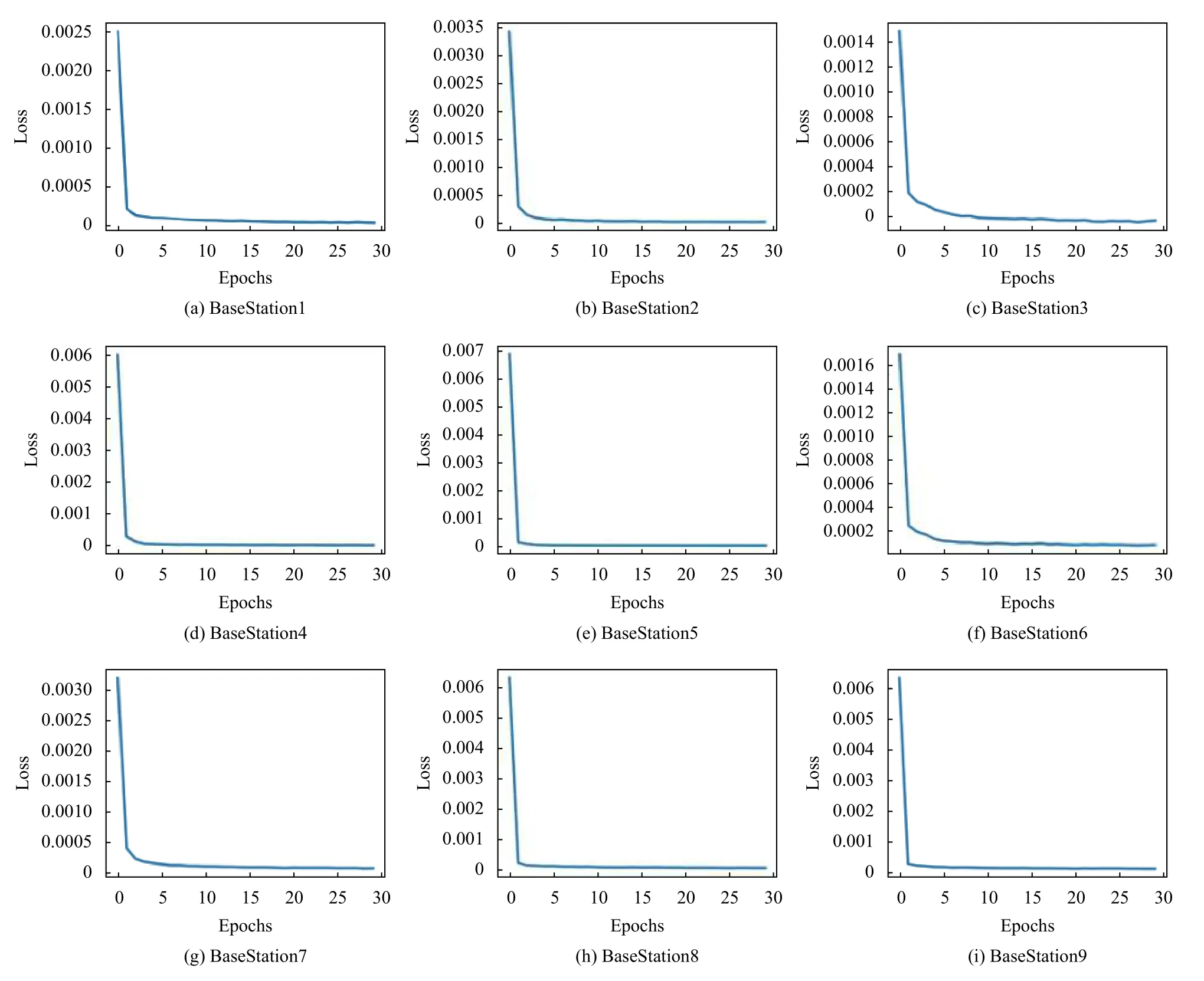
圖13 娛樂類型數據集訓練loss 曲線
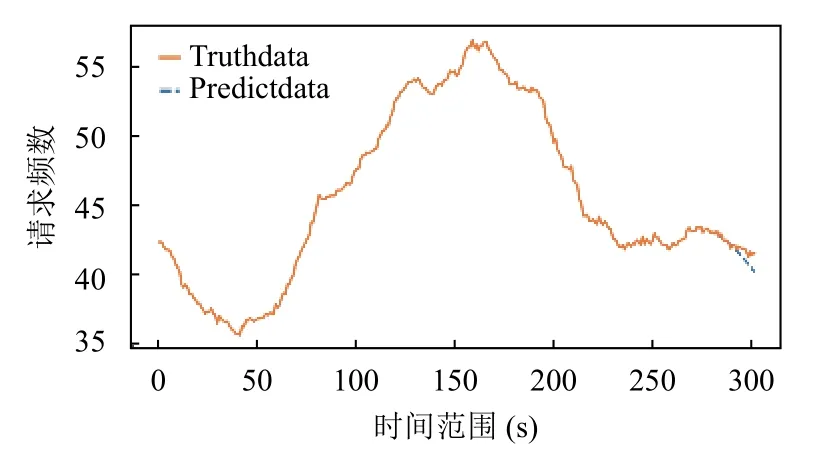
圖14 基站2 中娛樂類型的預測結果
4 總結
文章從文件請求的時變性和時間間斷性兩個角度出發.首先,通過實地考察記錄真實數據和參考權威軟件的探測值,利用SUMO 仿真平臺搭建出貼合現實的交通場景;其次,利用八爪魚采集網易新聞數據集,對數據處理后生成文件請求分布;最后,選取預測精度高且可以長期跟蹤內容的LSTM 深度學習模型進行預測.后續研究將進一步細化文件相關性的影響,并區分行人和車輛等不同用戶類型.
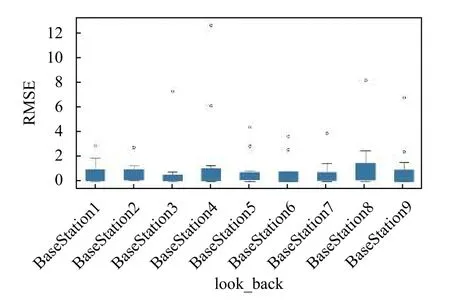
圖15 各基站中對所有類型預測的RMSE 值
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
