基于圖像序列的運動目標檢測識別關鍵技術研究
2021-01-19 12:56:34于蓮芝胡嬋娟
計量學報 2020年12期
薛 震, 于蓮芝, 胡嬋娟
(上海理工大學 光電信息與計算機工程學院,上海 200093)
1 引 言
隨著計算機技術、算法理論以及硬件的不斷完善升級,對視頻圖像的運動目標檢測與識別的研究也在不斷深入。運動目標檢測與識別是指對輸入的圖像序列進行圖像處理、目標檢測、特征提取和目標識別[1]。其中目標檢測是從圖像序列中檢測出運動物體的位置,而目標分類識別是指判斷提取出的目標屬于哪種類別。
運動目標檢測的常用方法包括幀間差分法、背景減除法、光流法等。幀間差分法是基于運動目標在視頻中可以直觀地體現動態變化的這一前提下,通過對比圖像序列中相鄰或相近幀的相對變化來進行的一種檢測方法[2]。該方法的主要優點是算法實現較為簡單,運算量較小,光線因素影響較小;缺點是易受到干擾,且目標檢測的有效性難以保證,只在目標運動速度較快的情況下具有比較好的魯棒性。背景減除法則先通過訓練圖像幀得到模型參數,建立背景模型,將每一幅待處理的圖像與當前背景進行比較來檢測目標的運動,然后根據場景的變化對模型參數進行更新;背景減除法在低速狀態下的檢測效果明顯,但在目標移動速度較快的場合檢測效果會大大降低。光流法則避免了提前了解場景信息,它既可以應用于背景運動的情況,也適用于背景不動的場合;但其條件苛刻,不僅對光照和噪聲比較敏感,而且計算復雜度高,難以滿足實時性的要求。光流法由于其條件的苛刻不予考慮,但幀間差法和背景減除法各有其長處以及局限性。
本文綜合幀間差分法在高速運動目標的良好魯棒性以及背景減除法在低速運動目標的準確性來考慮,將兩者同時應用于目標檢測中,并對檢測結果進行實時比較,選取相對較優的結果。通過運動目標檢測提取出圖像序列中的運動目標的掩膜,然后將提取到的運動目標區域進行分類識別,提取HOG特征送入SVM分類器完成分類任務,最終得到實驗結果。
2 幀間差分法原理及改進
幀間差分法是基于運動目標在視頻中可以直觀的體現動態變化的這一前提下,通過對比圖像序列中相鄰或相近幀的相對變化來進行的一種檢測方法[3]。該方法用當前幀與相鄰幀對應像素點的差值,通過設定的閾值T來判斷運動區域。基本原理由式(1)體現:
(1)
式中:D(x,y)表示二值化后的差分圖像,差分圖像D(x,y)取值為1的像素點被認為是運動目標的像素點;fk(x,y),fk+1(x,y)分別為第k幀、第k+1幀坐標為(x,y)像素點的像素值;T為閾值。幀間差法示意圖如圖1。

圖1 幀差法示意圖Fig.1 Frame difference method
其中閾值的選擇十分重要。閾值過小,則不能有效抑制圖像中的噪聲;閾值過大,又可能會抑制有效的運動區域。針對這一問題的解決方法有全局固定閾值、全局自適應閾值和局部自適應閾值。
2.1 全局固定閾值
全局固定閾值是在整個差分圖像的二值化過程中采用事先預定好的閾值[4]。優點在于運算簡單、速度快,但在抑制噪聲和魯棒性上較差。通過實驗采用不同閾值對同一幅灰度圖像進行二值化分割,結果見圖2所示。

圖2 不同固定閾值分割結果Fig.2 Different fixed threshold segmentation results
2.2 全局自適應閾值
當場景中的環境變化時,手動選取的固定閾值往往不能達到很好的分割效果,通過自適應全局閾值算法可以改善對變化環境場合的效果。本文主要研究最大類間方差法(Otsu)[5]。
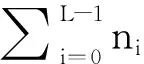
C0的概率ω0為:
(2)
C1的概率ω1為:
(3)
C0的平均值用u0表示:
(4)
C1的平均值用u1表示:
(5)
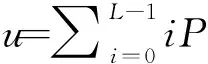
所以,全部采樣的灰度平均值為:
u=ω0u0+ω1u1
(6)
則兩組間的方差為:
δ2(T)=ω0(u0-u)2+ω1(u1-u)2
(7)
δ2(0)=ω0ω1(u1-u0)2
(8)
從0~(L-1)遍歷T,當δ2(T)最大時即為所求的閾值T。圖3為用此方法對某一灰度圖像進行仿真的實驗結果。從直方圖4能夠直觀地看出Otsu閾值為146[6]。

圖3 Otsu二值化Fig.3 Otsu binarization
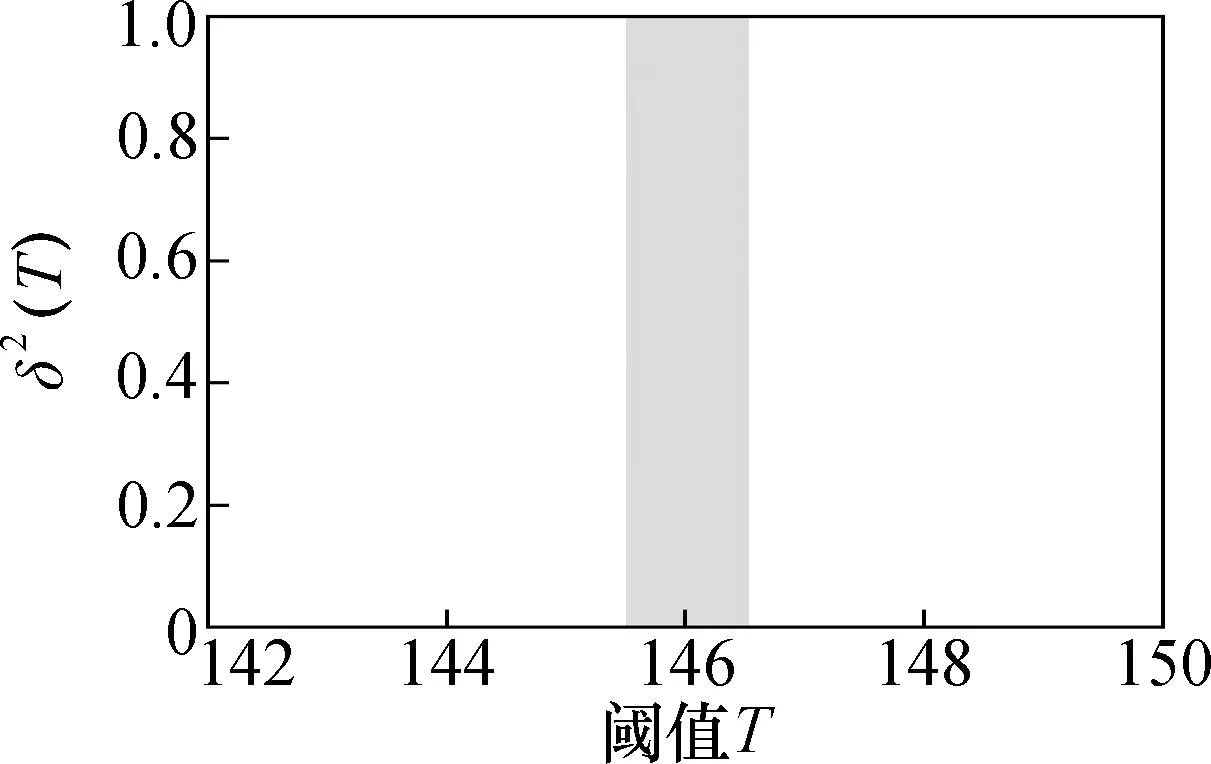
圖4 Otsu閾值選取Fig.4 Otsu threshold selection
2.3 實驗測試分析
本文用3種方法分別針對車輛和行人進行檢測來驗證其有效性。從圖5可以看出:固定閾值的平均FPS在80左右,全局自適應閾值平均FPS為70左右,局部自適應閾值在60左右,檢測速度相差不多。但從效果來說,行人移動速度較慢,目標內部變化不夠明顯,所以檢測結果產生了空洞現象。而針對速度較快的車輛來說,局部自適應閾值更注重在邊界的分割上,對于慢速行人和快速車輛的檢測效果均不理想,且FPS相對較低;固定閾值由于實際檢測過程中運動目標的運動會使得其最優閾值產生漂移,從而使得檢測結果的準確率變得較低,所以也不適合檢測。因此,Otsu法的幀差法比較適合運動目標檢測。
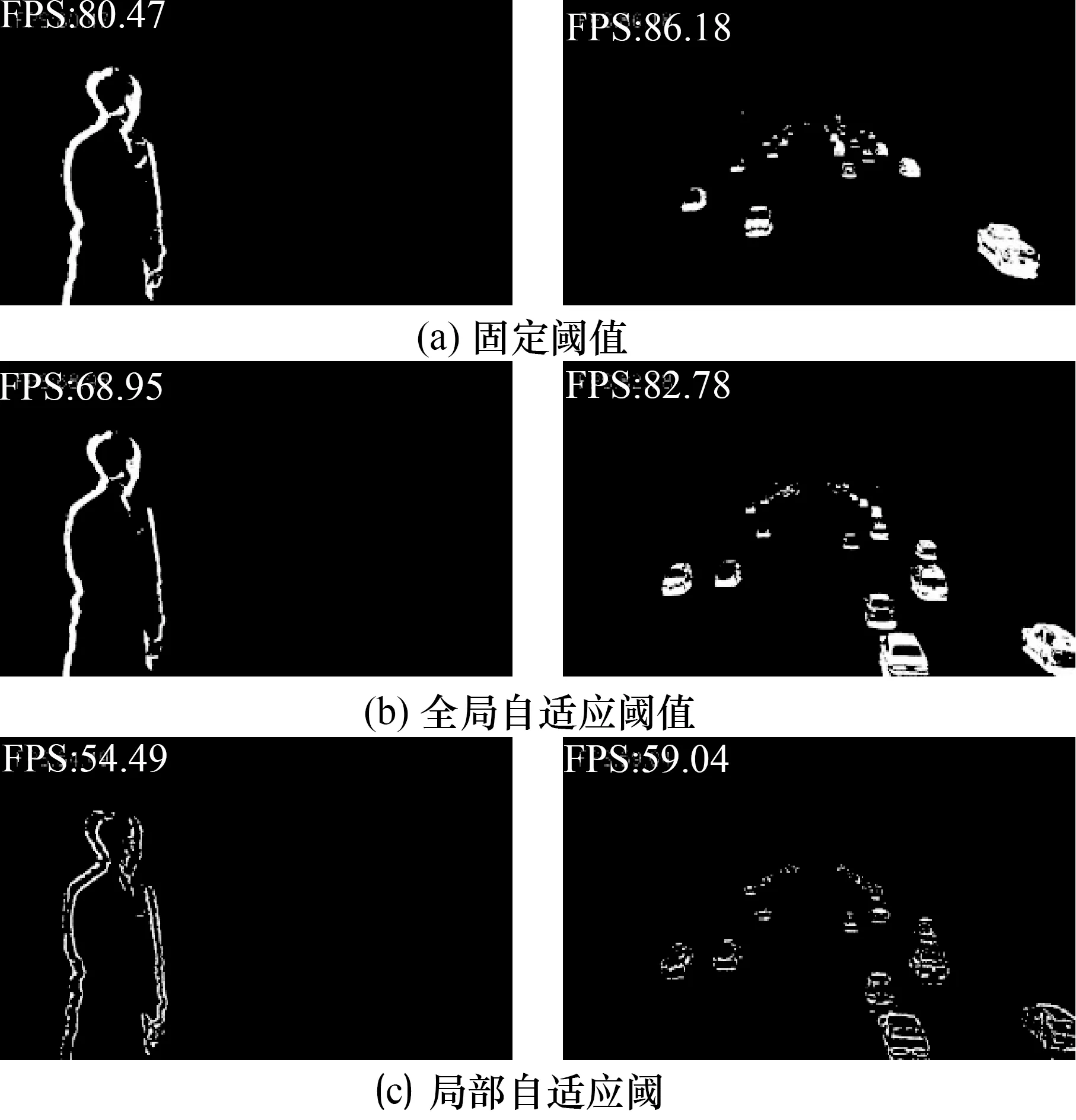
圖5 3種方法的檢測結果Fig.5 The detection results of three methods
3 背景減除法原理及改進
背景減除法是通過預先建立背景模型,利用圖像幀的訓練獲得模型的參數,再將每一幅待處理圖像與當前背景模型進行比較來檢測目標的運動[7],并根據場景的變化動態對模型參數進行更新。背景減除法對背景的更新速度具有嚴格的要求:更新速度較慢會使背景減除法對場景變化的適應能力較弱,當場景發生變化時因背景更新的不及時而產生較多的虛假目標;更新速度較快雖然能夠較快地適應場景的變化,但同時也加大了將運動目標更新為背景的概率,尤其是當運動目標變化較小時,容易發生漏檢的現象。背景減除法的流程圖如圖6所示。
本文基于混合高斯模型和碼本模型的背景減除法進行實驗分析,以尋找最適合的方法進行目標檢測。
3.1 混合高斯模型
混合高斯模型(Gaussian mixture model,GMM)[8]是指根據每個像素在時域上的分布情況用多個高斯模型構建各個像素的顏色分布模型,從而有效的描述圖像直方圖存在多峰的情況,改善單高斯模型在快速運動場景無法準確描述背景的缺陷。
在混合高斯模型中,對圖像的每個像素點進行多個權值不同高斯分布的疊加建模,每種高斯分布對應于一個像素點可能呈現顏色的狀態、權值和參數隨時間推進而更新。在處理彩色圖像時,假設圖像像素點RGB三通道相互獨立且方差相同,對于觀測集(X1,X2,…,Xb),Xb為b時刻的像素樣本,該樣本服從混合高斯分布概率密度函數:
(9)
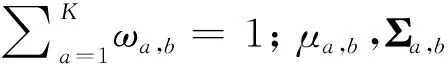
(10)
(11)
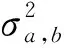
混合高斯模型雖然能解決單高斯模型的問題,但是也有如下缺點:通過少量的高斯模型來對快速變化的背景建模并不容易;學習速率太低,GMM模型會很寬泛,在模型突然改變時會很困難;學習速率過高,背景適應過快,緩慢移動前景又會被整合到背景模型中,最終導致較高的錯誤率。
3.2 碼本模型
碼本模型(codebook)背景減除法試圖在不進行參數估計的情況下進行長時間采樣,通過多個碼元(code_element)對背景進行建模[9],該算法特點有:
(1)自適應緊湊的背景模型,能長時間獲取結構化背景運動,對運動或多重變化的背景進行編碼。
(2)具有處理全局或局部光照變化的能力。
(3)訓練過程沒有制約,運動全景可在最開始的地方。
(4)通過分層建模來表示不同的背景層次。
碼本采用量化、聚類的技術,從視頻開始的多幀圖片中建立背景模型,為當前背景的每個像素建立codebook(CB)結構,每個codebook結構又由多個code_element(CE)組成,CB和CE形式為:
CB={CE1,CE2,…,CEr,T}
(12)
CE={LH,LL,Xmax,Xmin,tlast,tstale}
(13)
式中:r為一個CB中所包含的CE的數目,當r比較小時,能夠表示簡單背景,當r較大時可以對復雜背景進行建模;T為CB更新的次數;CE是1個6元組,其中LH,LL作為更新時的學習上下界,Xmax和Xmin記錄當前像素的最大值,tlast是上次更新的時間,tstale是陳舊時間(記錄該CE多久未被訪問),用來刪除很少使用的code_element。
采用CB算法檢測運動目標的流程為:
(1)在視頻開始選擇一幀或多幀使用更新算法建立CB背景模型;
(2)通過CB模型檢測前景;
(3)間隔一定時間使用更新模型,以適應場景的變化;
(4)若檢測結束,轉步驟(2),否則結束。
3.3 實驗測試分析
為了驗證上述算法的有效性,本文對行人和車輛進行實驗對比,圖7是2種模型下的背景減除法在不同的幀數下的檢測結果。由圖可以看出:無論是混合高斯模型還是碼本模型,在行人檢測上的效果均較好,沒有出現空洞;但是在移動速度較快的車輛檢測上都出現了相同的問題,不能迅速地檢測出移動目標,體現出背景減除法在對于高速目標檢測上的局限性。通過2種模式檢測結果的觀察,本文選擇相對而言效果更好的基于碼本模型的背景減除法來檢測低速物體。

圖7 混合高斯模型和碼本模型檢測結果Fig.7 GMM and codebook model test results
4 本文改進運動目標檢測方法
針對上述實驗得出結論:在運動目標移速較慢的場合,背景減除法發揮較好;在目標移動較快的場合,幀間差分法相對較好。因此本文融合2種算法,并做出如下改進:基于全局自適應閾值幀間差分法和基于碼本模型的背景減除法,同時對同一運動目標進行檢測,通過2種方法相或得出最終結果。運動目標較大時幀間差分法起主要作用,較小時背景減除法起主要作用[10]。算法的流程圖見圖8。
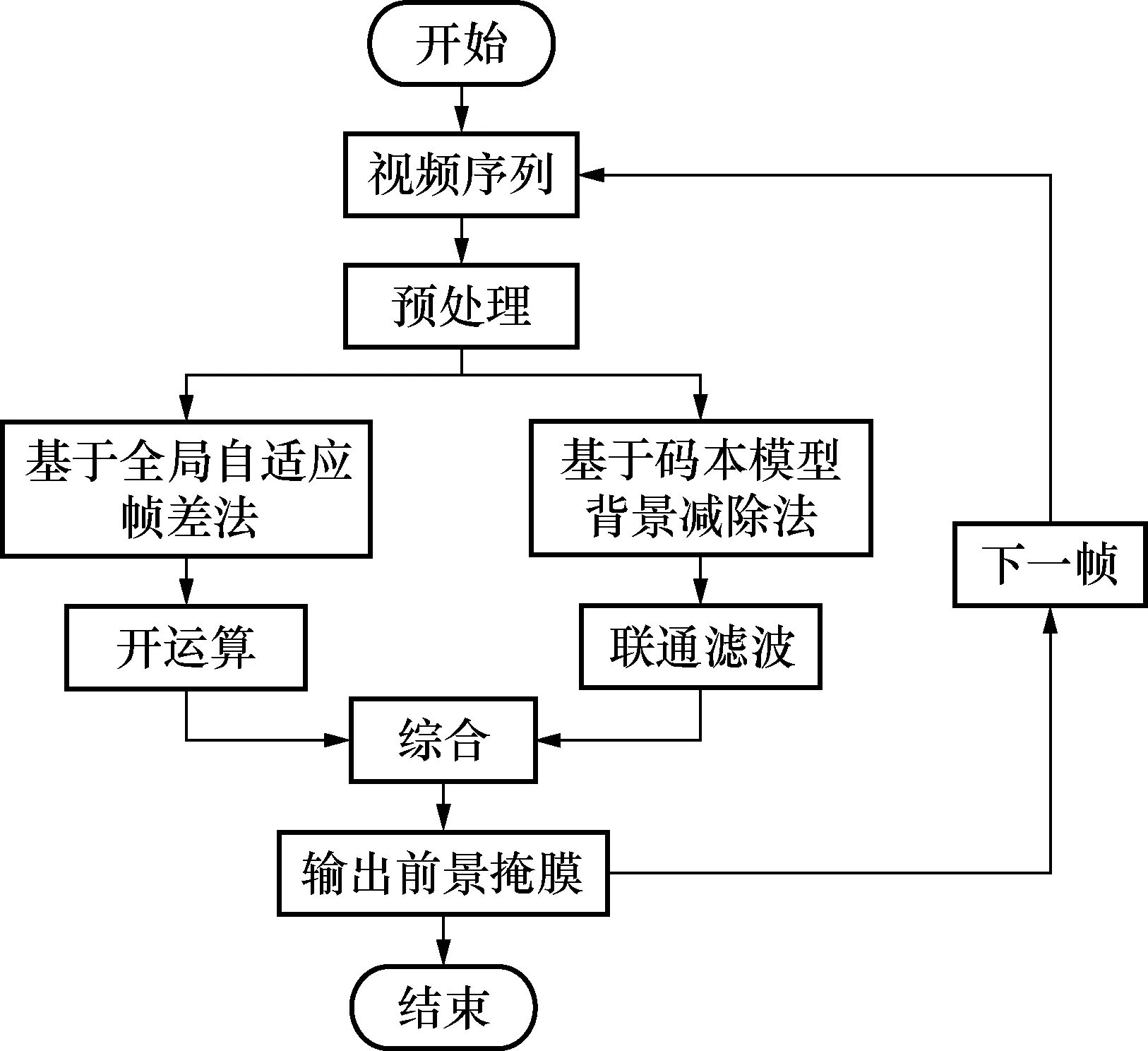
圖8 本文改進運動目標檢測流程圖Fig.8 The improved flow chart of moving target detection
通過本文方法分別對車輛和行人進行檢測,圖9為檢測結果。由圖9分析可得出:目標在2種運動狀態中均能取得較好的檢測結果,行人檢測和車輛檢測的FPS穩定在30左右,且都沒有出現空洞現象。證明了本文提出方法的有效性,該方法為目標識別的準確率提升帶來了積極的作用。

圖9 本文方法檢測結果Fig.9 Test results of the proposed method
5 目標識別方法
通過對運動目標的檢測提取到了運動目標的掩膜[11],然后對掩膜進行外界矩形分析,得到包圍運動目標的矩形框;再將矩形框內的圖片截取出來,并調整圖片的大小,提取出圖片的特征;通過訓練好的SVM分類器對檢測目標進行分類。識別系統框圖見圖10。
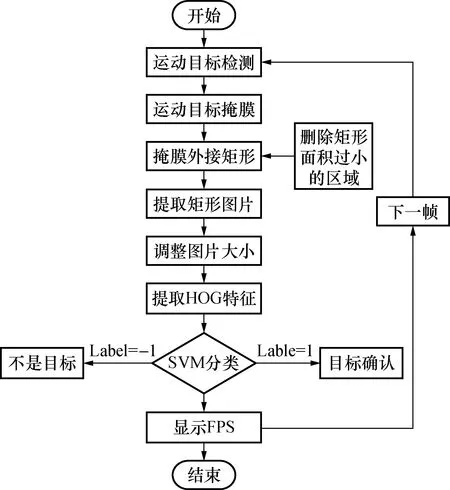
圖10 本文目標識別方法Fig.10 Target recognition of the proposed method
5.1 分類方法
本文通過運動目標檢測提取出運動目標的掩膜,用矩形框架選取目標,提取特征后送進SVM分類器進行識別[12~14]。相對于傳統的多尺度滑動窗口檢索,該方法在實時性上具有顯著提高。在提取特征的部分上,本文擬采用HOG特征,但是HOG特征具有維度大的特點,對目標檢測的實時性有加大的影響[13]。所以本文在HOG特征的基礎上,通過線性插值對每個cell中的梯度方向進行投票,并用多種尺度的block調整HOG結構,最后對生成的block進行特征挑選,最終組成多尺度的block。
5.2 自舉法
用訓練好的分類器進行實驗在識別出車輛的同時也會造成很多的誤檢,將收集的負樣本原圖送SVM分類器[15]識別,會在多張圖片上出現難例,如圖11所示。

圖11 負樣本誤檢圖Fig.11 Negative sample misdiagnosis
為減少難例的數量,可通過自舉法解決相似問題:將檢測為難例中的矩形框內容截取出來放入到初始的負樣本集合中,再重新進行SVM分類器的訓練。經試驗驗證,此類方法可有效減少誤報。
6 仿真實驗及結果
為驗證本文算法的有效性,借助OpenCV計算機視覺庫[16],實現車輛的未分類目標識別,并與傳統的HOG+SVM多尺度檢測算法就實時性和準確率進行對比。本次實驗的硬件為CPU Core(TM)i7 6700HQ,顯卡GTX1050Ti,8G內存。軟件平臺則是使用Visual Studio 2013開發環境以及開源計算機視覺庫OpenCV2.4.11。
圖12、圖13是分別用傳統的HOG+SVM多尺度檢測算法和本文的運動目標檢測識別算法對運動車輛的檢測識別結果[17]。從實時性上來看,本文提出的檢測識別算法平均FPS在20左右,傳統算法在4~5,在實時性上本文提出的算法具有明顯提升。

圖12 車輛檢測識別算法比較Fig.12 Comparison of vehicle detection and recognition algorithms
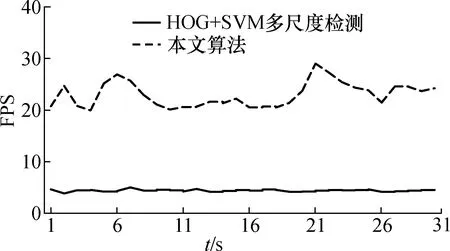
圖13 2種算法視頻監測實時性比較Fig.13 Real-time comparison of two algorithms
為了驗證算法的實用性,本文在不同場景下對運動車輛進行檢測,實驗結果如圖14所示。依據圖中結果顯示:在不同場景下依照本文算法都可將運動車輛很好地識別出來。證明本文算法具有普遍適用性。檢測準確性和其他比較參數如表1所示。

圖14 不同場景下車輛檢測識別Fig.14 Vehicle detection and recognition under different scenes
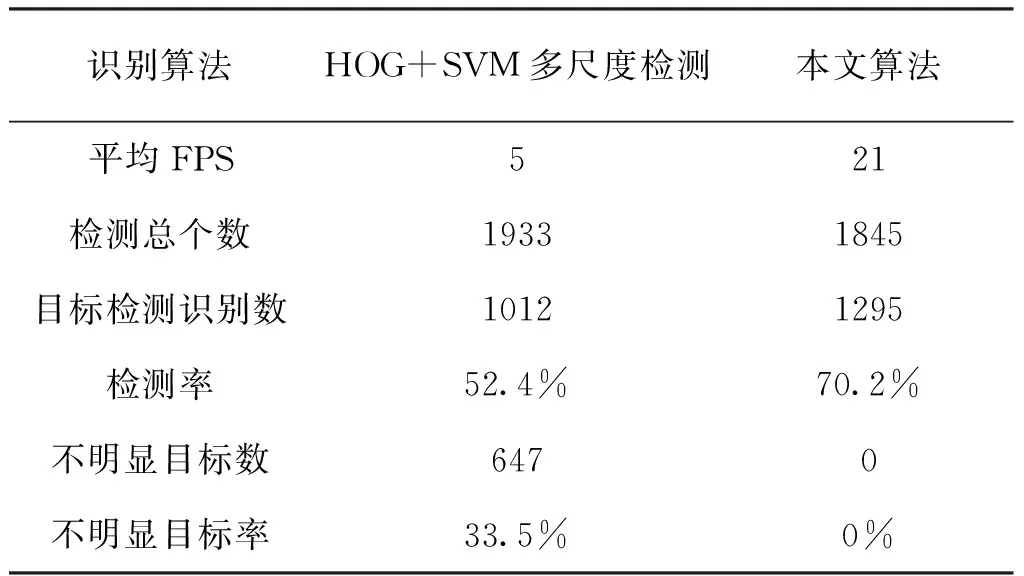
表1 2種算法檢測識別效果對比Tab.1 Comparison of detection and recognition effects
表1中不明顯目標率是指檢測邊界框中雖然有目標,但不是主要部分的概率,可能是誤檢,或是不確定的部分。這種情況在多尺度檢測中會發生,但本文檢測識別算法不存在這種情況。由表1可以看出:對于傳統目標檢測算法,本文識別算法提升了近20%。說明本文算法在準確性上相對是有提升的。
7 結束語
本文研究了基于視頻的運動目標檢測與分類識別,提出一種運動目標檢測提取前景,送入SVM分類器的算法。該算法先對運動目標同時使用基于全局自適應閾值的幀間差分法和基于碼本模型的背景減除法來進行檢測,提取出運動目標的掩膜,然后通過掩膜外接矩形來提取目標矩形圖片,通過多block調整HOG結構提取矩形圖片的特征,最終放入SVM分類器進行分類識別。在檢測過程中針對難例問題使用自舉法成功解決。實驗結果表明,本文算法在實時性和準確率上均優于傳統的目標檢測識別算法。但是本文算法在識別相互遮擋的運動目標時,由于目標區域不全,SVM分類器往往不能正確識別出車輛目標,從而影響了準確性。所以遮擋物體的運動目標檢測與識別是一個值得研究和解決的發展方向。當前,高效的深度學習檢測識別算法已成為主流和發展趨勢,但是就學術研究而言,傳統的目標檢測方法作為基礎仍然具有研究和學習的意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車工程師(2021年12期)2022-01-17 02:29:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
當代陜西(2020年14期)2021-01-08 09:30:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
光學精密工程(2016年6期)2016-11-07 09:07:19
