一種針對時間局部性訪問的固態硬盤緩存算法*
2021-01-19 11:01:58吳崇建閔紹榮楊子晨
計算機與數字工程 2020年12期
張 劍 吳崇建 閔紹榮 楊子晨
(中國艦船研究設計中心 武漢 430064)
1 引言
隨著人類對自然界了解的不斷深入,以及建模技術、信息技術的不斷發展,人類用數據抽象自然界中客觀事物的能力逐漸增強,從而使得積累的數據呈現出領域越來越廣、數量越來越多、類型越來越豐富的趨勢。由于這些數據表現出不同的特點,因此在使用這些數據的過程中,存儲系統的數據訪問模式會不斷變化。其中的一種典型數據訪問模式就是時間局部性[1]。時間局部性訪問有兩個顯著的特點:1)熱點遷移[2]。隨著時間的變化,數據熱點區域會發生變化,在不同的時間段內不同存儲區域的數據分別被頻繁訪問。2)訪問頻率變化。某段時間內特定的數據被高頻次訪問,而過了這段時間后該數據被訪問的可能性大大降低甚至不再被訪問。
為了有效應對存儲系統中的時間局部性訪問,本文針對內存、固態硬盤、機械硬盤構成的混合存儲系統,設計了一種基于變化替換代價[3~4]的動態緩存算法DRCC,并將DRCC算法與多種主流緩存算法進行了測試對比。測試結果表明,與其他緩存算法相比,DRCC算法具有更高的讀寫效率。
2 相關研究
緩存算法主要解決數據的組織方式和容量滿時數據的淘汰機制。國內外對于緩存算法開展了廣泛研究。其中,比較經典的算法為LRU[5~6]算法、LFU[7]算法。由于固態硬盤具有區別于內存的特點,于是一些針對固態硬盤的緩存算法被提出,其中的典型代表就是CFLRU(Clean-First LRU)緩存算法[8]和LRU-WSR(LRU-Write Sequence Reordering)算法[9~10]。
LRU算法著重考慮數據是否最近被訪問,通過一個隊列來保留緩存頁的訪問時間信息,優先淘汰最久沒有被訪問的數據。如圖1所示。
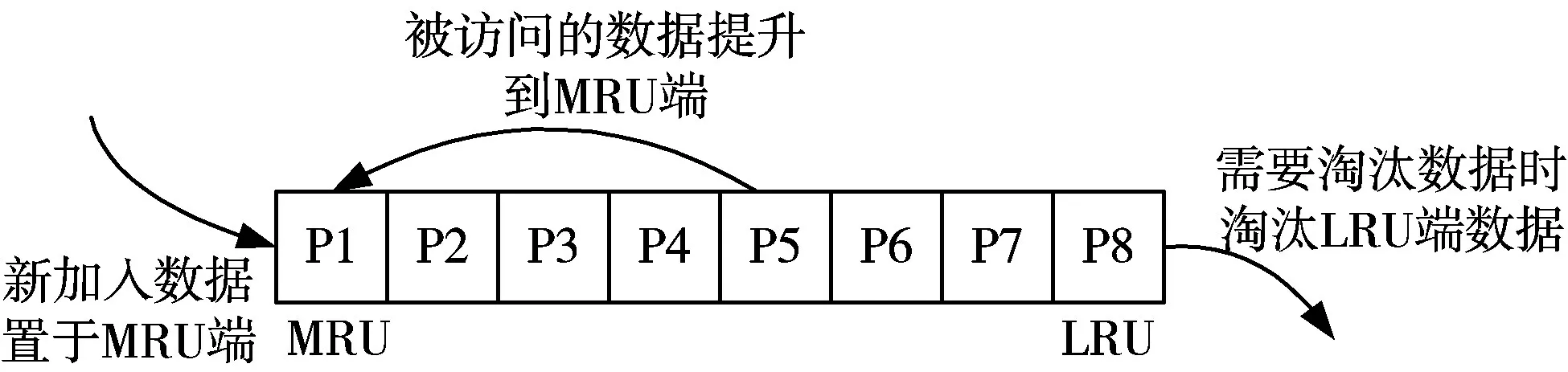
圖1 LRU算法示意圖
LFU算法著重考慮數據的訪問頻次,認為訪問頻次最低的頁最不可能被再次訪問,按照訪問頻次從大到小對緩存頁進行排序,容量滿時優先淘汰訪問頻次最低的數據。如圖2所示。
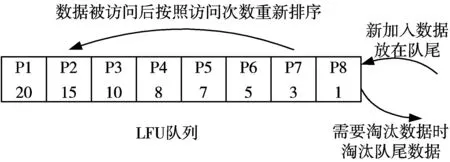
圖2 LFU算法示意圖
CFLRU算法將鏈表分為工作區和淘汰區兩個區域,工作區管理最近被訪問的頁,淘汰區管理即將被淘汰的頁。當發生替換操作時,算法會在淘汰區中優先選擇干凈的頁進行淘汰,如果淘汰區不存在干凈的頁,那么就把LRU端的臟頁作為替換頁。如圖3所示。
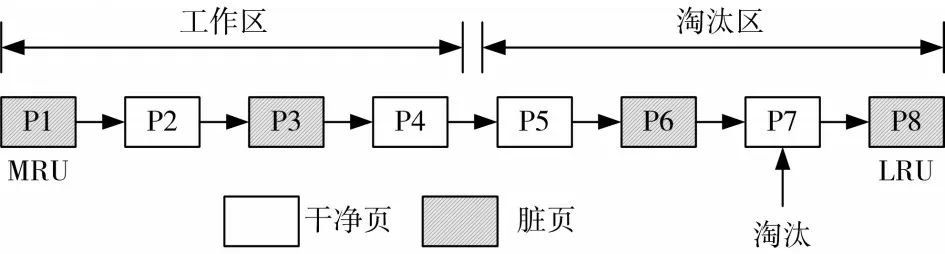
圖3 CFLRU緩存算法示意圖
LRU-WSR算法將緩存頁劃分為三種類型:干凈頁,冷臟頁和熱臟頁。臟頁通過一個冷熱標識進行冷熱劃分。發生淘汰時,判別LRU端的頁類型:若為干凈頁或冷臟頁,直接淘汰;若為熱臟頁,則將標記為冷臟頁,并把該頁插入MRU端,給熱臟頁一次被保留的機會。如圖4所示。
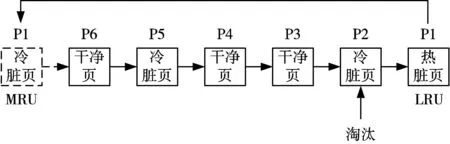
圖4 LRU-WSR緩存算法示意圖
3 DRCC算法設計
3.1 數據記錄結構
使用DRCC算法時,固態硬盤的數據按照兩個隊列進行組織:預約隊列和最小代價優先隊列,如圖5所示。
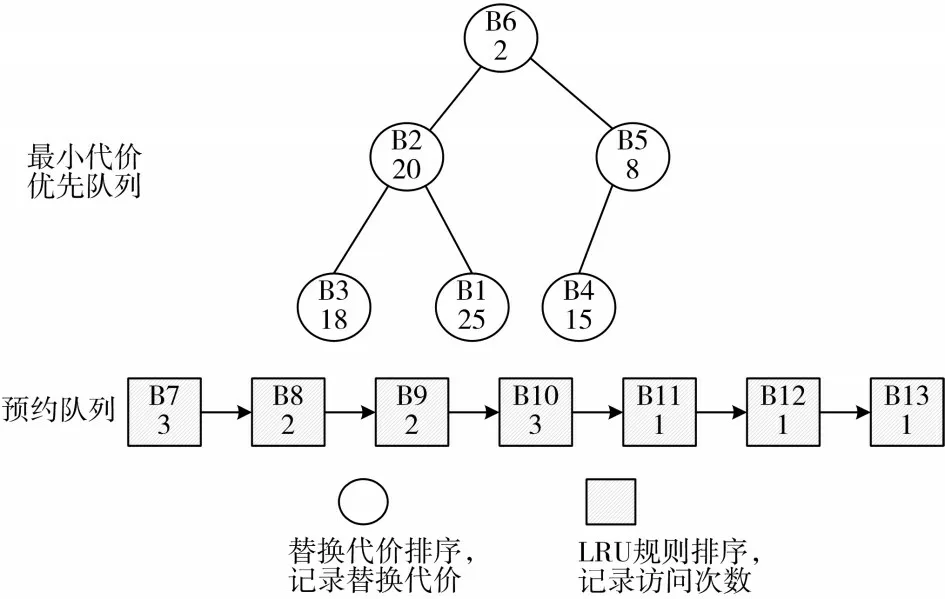
圖5 預約隊列和最小代價優先隊列示意圖
兩個隊列的內涵分別如下:
1)預約隊列
預約隊列記錄剛被訪問不久的數據塊。當數據塊初次被訪問加入到固態硬盤中時,先將其加入固態硬盤的預約隊列中,預約隊列使用LRU算法排序。
2)最小代價優先隊列。
最小代價優先隊列記錄從預約隊列中篩選出來的達到一定訪問次數閾值的數據塊。最小代價優先隊列以替換代價為標準進行排序。最小代價優先隊列中的數據被訪問會重新計算其替換代價,根據替換代價插入到隊列的相應位置。
計算數據塊的替換代價以及對最小代價優先隊列進行排序會帶來較大的開銷,一定程度上會影響整個存儲系統的性能。為此通過降低代價計算復雜度和排序復雜度,在不影響命中率的前提下,犧牲部分熱數據的排序精確度來降低系統開銷,從而獲得性能的提升。最小代價優先隊列采用最小堆[11~12]的形式進行不完全排序,以完全二叉樹的形式,每次只確定最小代價的根節點位置。
最小代價優先隊列的長度設置要適中,才能使得算法更能適應時間局部性的數據訪問特點。最小代價優先隊列的長度設置過大,會使很多變冷的數據污染固態硬盤緩存空間;最小代價優先隊列的長度設置過小,則會造成熱數據的頻繁替換,增大替換開銷和對底層存儲的讀寫次數。因此,需要給最小代價優先隊列設置一個合適的長度。假設固態硬盤的容量為V,默認設置最小代價優先隊列的最大長度為,具體取值可以根據實際情況動態調整。
3.2 替換代價計算
替換代價計算方法如式(1)所示:

式(1)中各變量的含義如下:
CR代表最小代價優先隊列中數據塊的替換代價;dircost代表寫操作和讀操作的時間開銷比;accenum代表數據塊訪問次數;accedis代表數據塊最近一次訪問到現在的時間間隔。
在計算替換代價時,對于緩存中的臟數據,需要乘上寫讀操作的開銷比dircost,給臟數據塊更多保留在緩存中的機會。
具體實施時,由于熱數據會隨著時間遷移,所以將最小代價優先隊列中的數據塊訪問次數計算考慮時間間隔的因素,同時設置老化周期定時將數據訪問次數右移一位,避免在過去時間內訪問次數積累較多而現在已經變冷較少被訪問的數據塊一直占據緩存空間,造成新加入的較低訪問次數熱數據被替換的情況。
3.3 數據組織方法
當數據被訪問時,根據被訪問的數據是否已經存在于固態硬盤中,存在兩種情況。不同的情況會有不同的數據組織流程。
1)當被訪問數據不在固態硬盤時,數據組織流程如圖6所示。數據被訪問后,將其提取到固態硬盤的預約隊列中,并按照LRU算法進行數據的組織。
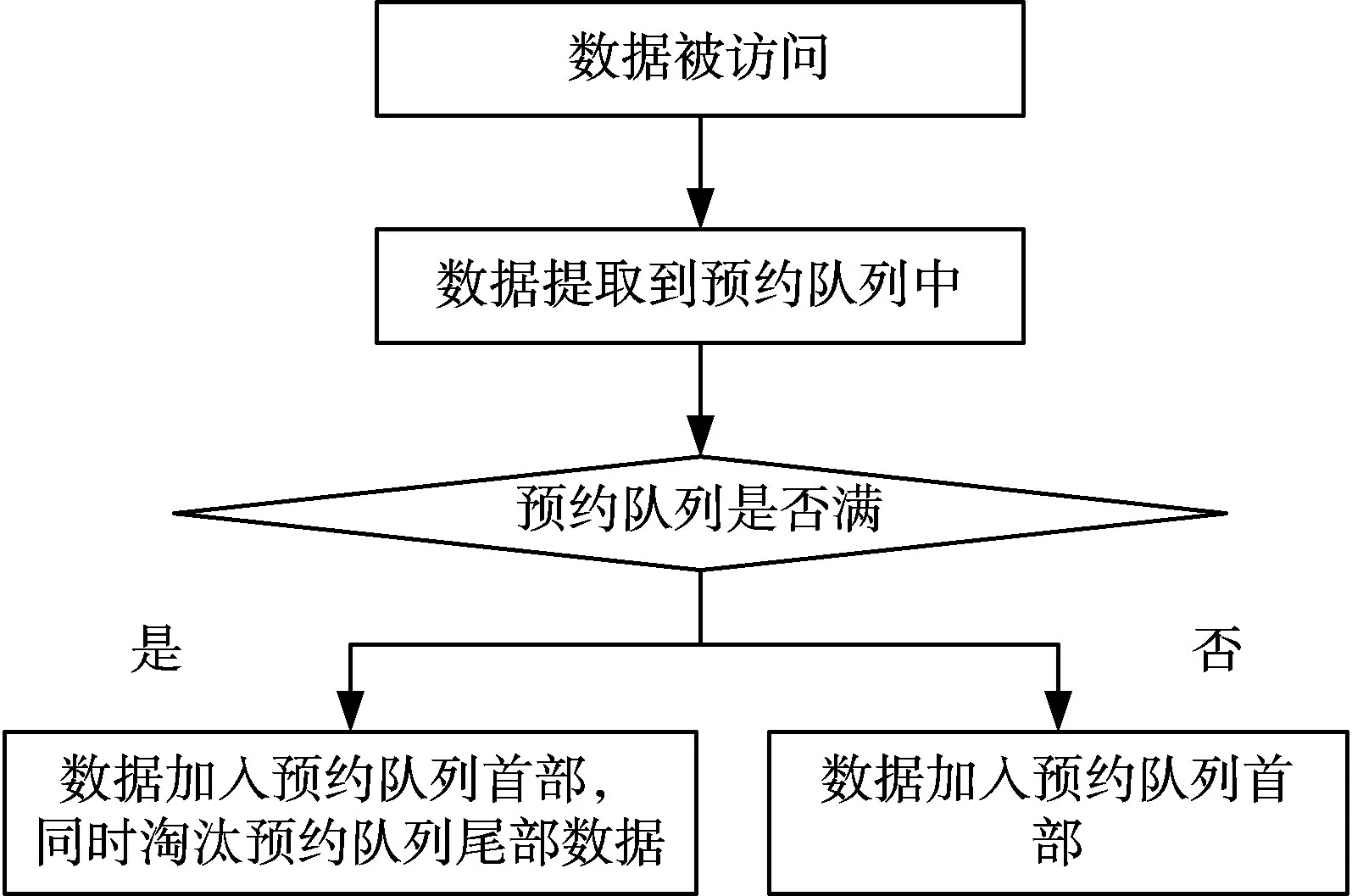
圖6 被訪問數據不在固態硬盤時的數據組織流程
2)當被訪問的數據存在于固態硬盤中時,數據組織流程如圖7所示。若數據被訪問時存在于預約隊列中,則檢查其訪問次數是否達到閾值,若達到閾值,則將其提升到最小代價優先隊列中,計算其替換代價,并在最小代價優先隊列容量滿時淘汰替換代價最小的數據;若未達到閾值,則繼續保留在預約隊列,并按照LRU算法進行排序。若數據被訪問時存在于最小代價優先隊列中,則重新計算其替換代價,再次確定替換代價最小的數據。
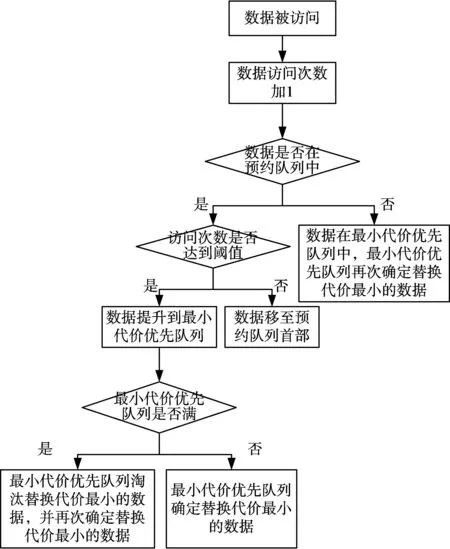
圖7 被訪問數據在固態硬盤時的數據組織流程
可以看出,預約隊列和最小代價隊列都有各自的淘汰方式,最小優先代價隊列并不等待預約隊列為空時才開始淘汰數據。這種數據淘汰方式考慮了時間局部性數據熱點遷移的特點,能及時將變冷的數據塊淘汰出固態硬盤,避免緩存空間污染[13]。
4 性能測試與結果分析
4.1 測試方案
測試時存儲系統的實現基于開源的iSCSI(Internet Small Computer System Interface,Internet小型計算機接口)[14~15]代碼。i SCSI是當前存儲界的熱門技術之一,其使用TCP/IP協議,用廣域網仿真高性能本地存儲總線,從而創建了一個存儲局域網。內存、固態硬盤、機械硬盤構成的混合存儲系統安裝在作為iSCSI目標端的存儲服務器,客戶端通過iSCSI發起端將讀寫請求負載發送到iSCSI目標端的存儲服務器。
測試時將本文中所提的DRCC算法與經典的LRU算法、LFU算法,以及針對固態硬盤的高效算法CFLRU進行比較,以證明DRCC算法的優勢。
4.2 測試環境
測試環境配置如表1所示。根據測試數據集的大小,通過代碼進行控制,將用于測試的混合存儲系統的內存大小設置為500M,固態硬盤大小設置為1G×3,機械硬盤大小設置為20G×6。

表1 測試環境配置
4.3 測試數據
測試數據通過模擬產生,在某個服務器部署待訪問數據,通過另一個客戶端對其進行時間局部性訪問。通過訪問記錄收集工具記錄一段時間之內服務器的訪問情況。為了充分反映數據的訪問特點,記錄約120h的數據。
表2所示統計了以1000、5000、10000、20000次訪問為數據第一次訪問起點,數據被再次重新訪問的平均距離。
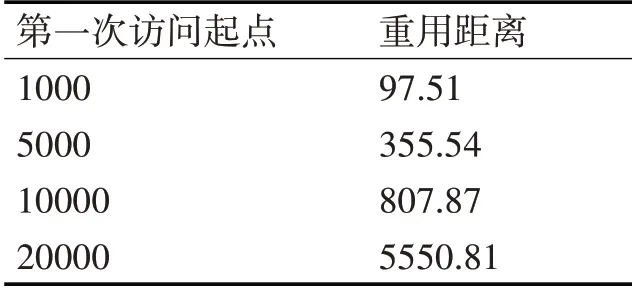
表2 平均重用距離統計
從表2可以看出,數據以20000次訪問為數據第一次訪問起點時,平均重用距離相比較以10000次訪問為起點時陡然增大了約7倍,這與時間局部性訪問的特點非常相符,熱數據在一段時間內被頻繁訪問過后,熱度迅速降低甚至不再被訪問。
4.4 測試結果
1)每小時平均IOPS對比測試
DRCC算法與LRU算法、LFU算法、CFLRU算法的每小時平均IOPS的測試結果如圖8所示。
可以看出,DRCC算法的每小時平均IOPS絕大多數時間都要高于LRU算法、LFU算法、CFLRU算法。
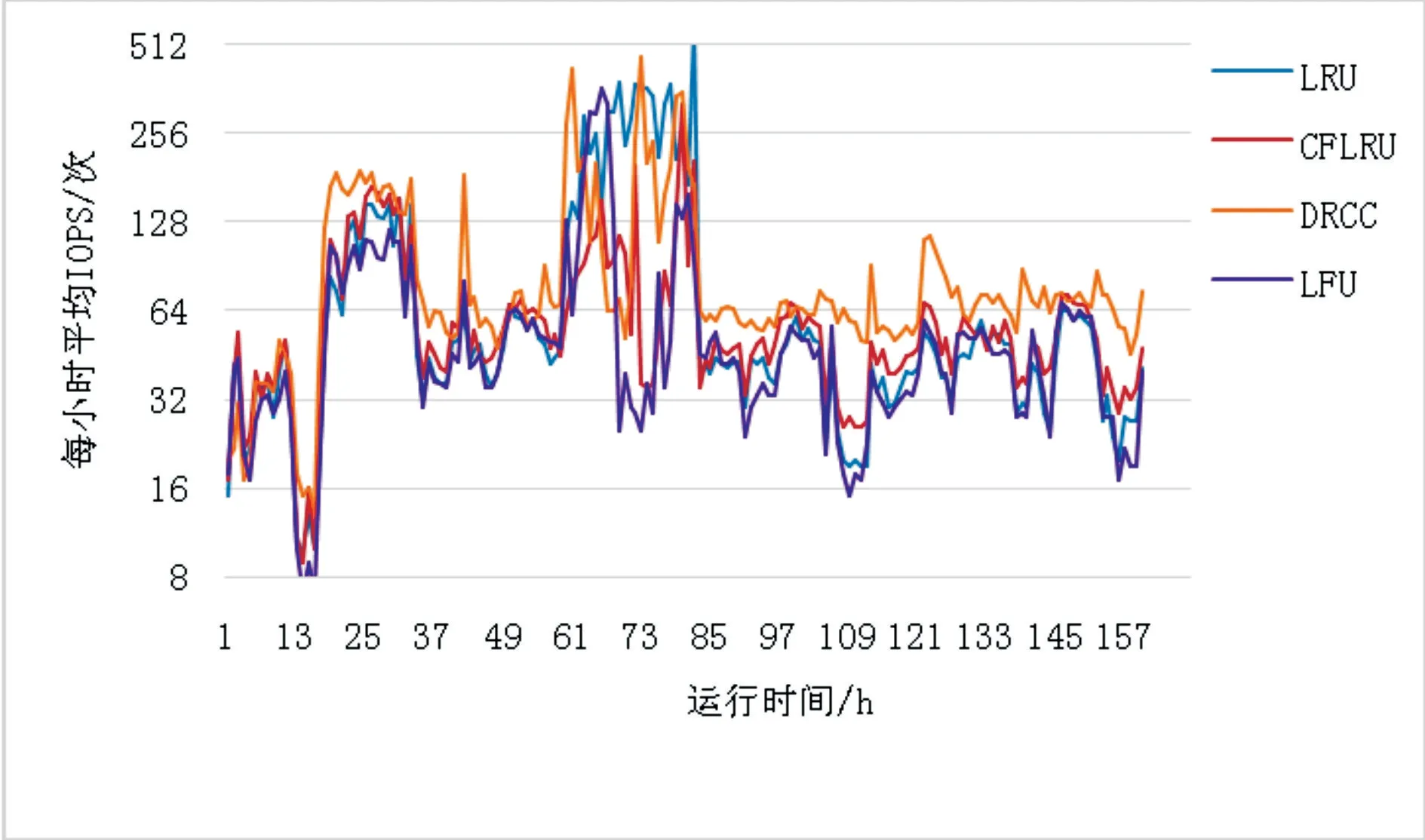
圖8 每小時平均IOPS測試結果
2)總平均IOPS對比測試
DRCC算法與LRU算法、LFU算法、CFLRU算法的總平均IOPS的測試結果如圖9所示。
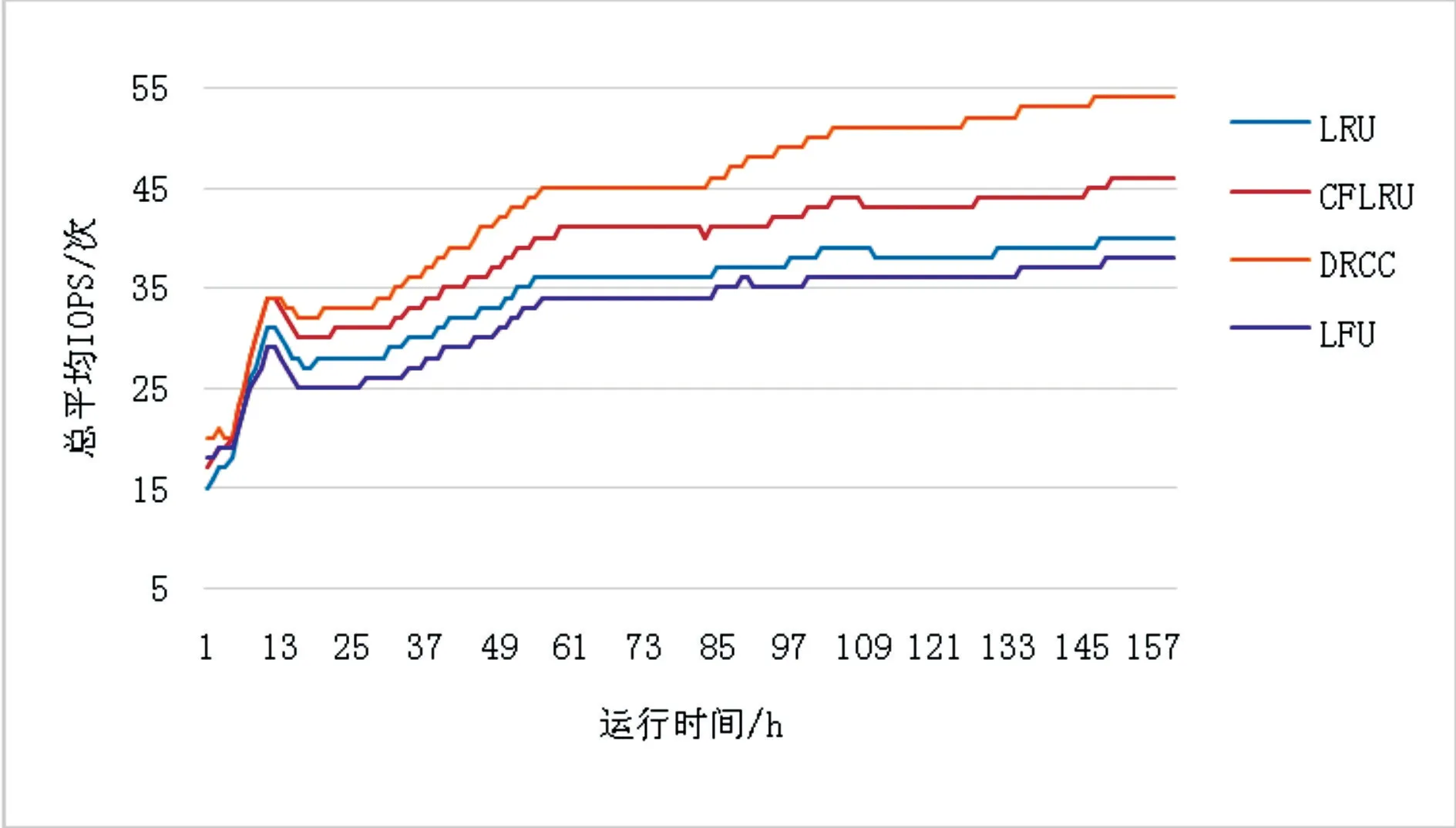
圖9 總平均IOPS測試結果
可以看出,存儲系統運行一小段時間后,DRCC算法的總平均IOPS就開始表現出明顯的優勢,而且隨著時間的推移,這種優勢進一步擴大。在總平均IOPS方面,相比較于LRU、LFU、CFLRU三種算法,DRCC算法的提升幅度均超過了10%。
5 結語
本文針對內存、固態硬盤、機械硬盤組成的混合存儲系統中的時間局部性訪問,設計了一種高效的緩存算法。該算法通過預約隊列和最小代價優先隊列實現數據的組織,同時兩個隊列分別進行數據的淘汰,充分解決了高時間局部性數據熱點遷移所帶來的緩存污染問題。測試結果表明,該算法不僅比經典的LRU算法和LFU算法更有優勢,而且相比較于針對固態硬盤的高效緩存算法CFLRU,同樣表現出較大的性能提升。
