基于SSD模型的船載危險駕駛行為檢測系統設計?
2021-01-19 10:18:34劉常榕趙雪寒劉慶華杜春旺張翟容
艦船電子工程 2020年12期
劉常榕 趙雪寒 劉慶華 金 文 杜春旺 張翟容
(1.江蘇科技大學 鎮江 212003)(2.江蘇金海星導航科技有限公司 鎮江 212002)
1 引言
交通安全一直是社會重大安全問題之一,每年多少人都因為道路交通事故失去寶貴的生命,一方面是由于行人等自身不遵守交通規則,一方面也是因為駕駛員的危險駕駛行為導致災禍的發生。在道路交通領域中,危險駕駛一直是人們比較關注的地方。道路交通事故統計資料表明,駕駛員超速、疲勞駕駛、酒后駕駛等危險駕駛行為是造成交通安全事故的主要因素。楊曉峰等人提出了一種基于臉部特征提取的駕駛員低頭行為的檢測方法[1],吳超仲[2]等人以駕駛疲勞狀態監測為研究對象,介紹現有幾種疲勞檢測方法及其優缺點,提出了對駕駛行為操作和駕駛員生理指標進行建模,建立疲勞識別模型,實現了對疲勞駕駛行為的檢測。李娟根據數據融合的思想,采用粗糙集模型融合人眼疲勞識別特征參數和車道線危險識別特征參數,建立危險駕駛識別的數據融合模型,得出了最終的危險識別結果[3]。然而,水上駕駛安全也同樣重要。每年,全國范圍內水上交通事故發生也非常多,水上交通安全問題日益凸顯,如何降低水上交通事故發生已經成為江河流域管理部門的重大難題之一。我們認識到,水上危險駕駛行為是導致水上交通事故的主要原因[4],嚴重威脅水上交通安全。因此,如何實現對船舶駕駛員的危險駕駛行為的實時檢測對于減少水上交通事故顯得尤為重要。
在水上交通安全領域,船員的危險駕駛行為主要有低頭、閉眼、打哈欠、打電話、抽煙、轉頭等行為。這些行為可以通過安裝在船長駕駛室的攝像頭進行捕捉畫面,并且通過分析畫面中的相應行為來檢測是否有危險行為發生,這其實就涉及到對人臉、電話等的目標檢測問題。目前,在計算機視覺領域,目標檢測是一個非常重要的研究方向,很多新型科研領域如無人駕駛、人臉識別、智能監控等都有廣泛的應用。它是以圖象分類技術為基礎,檢測圖像中的目標對象并進行分類,并且在目標對象周圍繪制適當大小的邊框對目標對象進行定位實現的[5]。傳統顯著性目標檢測方法常假設只有單個顯著性目標,其效果依賴顯著性閾值的選取,并不符合實際應用需求。近來利用目標檢測方法得到顯著性目標檢測框成為一種新的解決思路[6]。選取SSD模型可以同時精確檢測多個不同尺度的目標對象,其對小尺度目標檢測精度不佳的問題在船舶駕駛員行為檢測中影響較小,因此,采用SSD模型實現對船舶駕駛員行為的檢測是可行的。
本文將首先介紹整個船載危險駕駛行為檢測系統的整體設計,并且闡述使用SSD模型實現目標檢測功能的原理,并選取典型的目標檢測數據,制作用于目標檢測模型的圖像數據集,結合SSD_MobileNet預訓練模型,在具有安裝NVIDIA顯卡的主機上訓練危險駕駛行為檢測模型,最后將訓練好的模型集成到安裝好特定環境并帶有NVIDIA顯卡的主機上,實現危險駕駛行為檢測的功能,并且分析這些行為檢測的準確度并且得出相應結論。
2 系統設計
2.1 硬件系統設計
整個船載危險駕駛行為檢測系統的主機為惠普i5-9400F,其內存容量為8GB,硬盤容量為1TB,顯卡型號為NVIDIA GetForce GTX1660,滿足作為訓練主機和正式環境的要求。在訓練模型時,我們可以使用該主機對SSD模型在增加數據集的基礎上進行訓練;在實際船舶環境中,我們可以將該主機放置在船長駕駛室內,配置相關程序供電之后即可使用。
該行為檢測系統硬件框圖如圖1所示。首先,船舶一般配置一臺路由器和一臺交換機,安裝在船員駕駛艙前面的海康攝像頭通過連接到交換機通過配置相關參數即可使該攝像頭具有靜態的IP,搭載檢測模型的主機通過連接到交換機與該攝像頭同處一個局域網下,就能通過攝像頭固定的本地地址實現通信。主機上的檢測程序主要是通過實時流傳輸協議RTSP(Real Time Streaming Protocol)將駕駛員的實時監控視頻流獲取到,然后將該視頻流輸入到船載危險駕駛行為檢測的深度學習模型中,模型根據視頻流會進行幾種駕駛行為的檢測,如果發現檢測到危險駕駛行為,則會通過報警模塊將該行為信息通過聲音播報出來并且會通過MQTT協議的數據消息發送到遠程后臺管理平臺,后臺管理平臺可以將這些信息保存到數據庫并且通過界面展示出來。
船載主機可以設置掉電自動重啟功能,每次船舶開始啟動通電時主機能夠自動開機,檢測程序隨之能夠實時地檢測船員的危險駕駛行為,非常方便,不需要人工干預。

圖1 硬件系統設計示意圖
2.2 軟件系統設計
放置在船上的主機里面集成了危險駕駛行為的檢測程序,其主要的流程如圖2所示。首先,當主機通電時,檢測程序自動開始運行,首先會進行系統初始化,根據主機、端口和主題等配置向MQTT服務器發起訂閱,訂閱成功則開始檢查TTS模塊是否正常啟動,其次,加載危險駕駛行為檢測模型,然后開始讀取視頻流,讀取每幀的圖片進行檢測,如果檢測到危險駕駛行為則通知TTS模塊播放對應的提示語音并且通過MQTT向遠程平臺發送MQTT數據包。

圖2 檢測程序執行流程圖
MQTT協議[9]特別適合應用在物聯網領域,本系統中,我們就是采用MQTT協議發送數據包。MQTT協議是一種基于Publish/Subscribe模式的協議,它的主題支持通配符格式,一般常用的是“+”和“#”。本系統設計的主題格式主要是根據公司代碼還有船舶九位碼來區別不同的船舶發送過來的駕駛行為的數據,主要形式為/ship/+/+/alert/publish,其中第一個“+”匹配的是公司代碼,第二個加號匹配的是船舶九位碼,這樣設計的目的是可以根據主題的層級關系每個公司可以只訂閱自己管理的船舶的主題,便于后續需要。MQTT的數據格式采用json格式,各字段含義主要如表1所示。
系統的后臺管理平臺主要使用的語言為java,主要的架構為Springboot+mybatis+JSP實現,將項目打包成war直接使用docker部署。平臺主要使用的是postgresql關系型數據庫,整個架構如圖3所示。
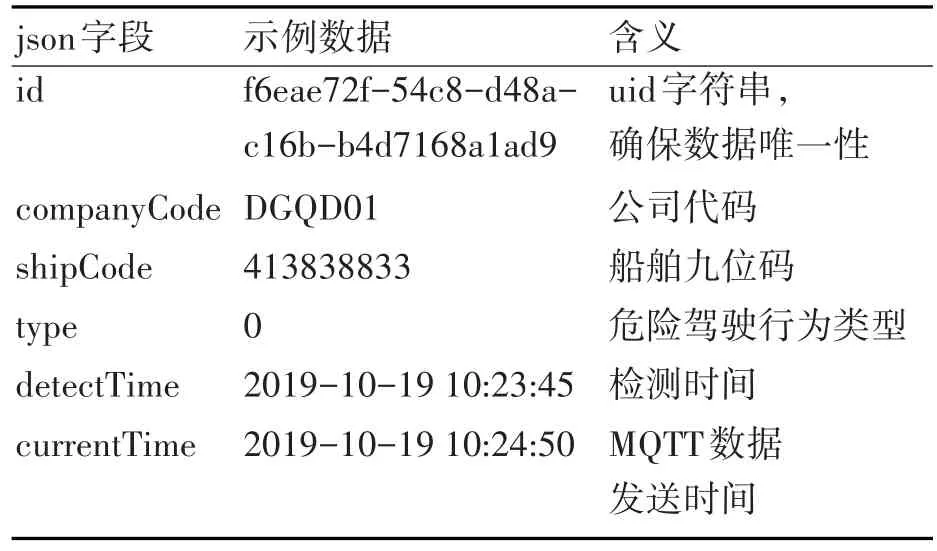
表1 MQTT數據包字段說明

圖3 網絡模型結構圖
3 算法實現
3.1 SSD網絡模型簡單介紹
SSD模型是由WeiLiu,Dragon Anguelov等[7]提出的使用單個深層神經網絡檢測圖像中對象的方法。其結構示意圖4所示:SSD模型的前五層為VGG-16網絡的卷積層,第六和第七層全連接層轉化為兩個卷積層,之后再加上三個卷積層和一個平均池化層。SSD模型的主要特征就是采取VGG-16卷積神經網絡作為基礎,然后連接多層卷積層和池外層來提供額外提取特征的效果。SSD模型獲取目標對象位置和類別的方法雖然也是回歸方法,但是主要去除了候選框的操作,使用候選對象位置周圍的特征,采用的是Anchor機制。在使用SSD模型進行對象的檢測時,各個卷積層會將特征圖分割為若干稱為feature map cell的大小相同的網格,針對每個網格使用固定大小的Default boxes對目標對象進行包圍,預測這些Default boxes的偏移和類別得分,最后采用非極大值抑制方法獲取目標檢測的結果。Default boxes可以作用于不同層次的多個特征圖上,幫助我們以最合適的尺度來匹配目標對象的實際區域范圍。

圖4 VGG結構圖
SSD_MobileNet模型是將MobileNet網絡替換VGG網絡成為該模型的基礎網絡結構的。MobileNet的設計之初是為了應用于嵌入式視覺,它十分高效,主要的特點就是將標準卷積核進行分解計算,引入寬度乘數和分辨率乘數兩個超參數減少計算量。Andrew G.Howard等人針對COCO數據集進行實驗,得出了使用基于SSD框架下的這兩種模型的訓練及測試的結果[8],如表2所示。綜合這實驗結果可以得出,SSD框架使用MobileNet網絡結構作為基礎網絡結構,雖然在檢測的準確率上面會有些許下降,但是在圖像處理時的計算量和參數量會大幅度下降。在嵌入式應用中,硬件資源一般都是有限的,機器的性能也不是很高,減少計算量,提高目標檢測實時性非常關鍵,而使用MobileNet這種輕量級、延遲性低的檢測模型能夠顯著地提高目標檢測的速度。
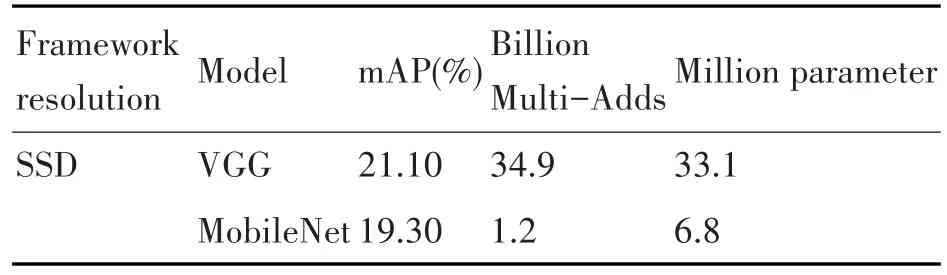
表2 VGG和MobileNet對比實驗結果對比
3.2 數據集的處理
危險駕駛行為模型的數據集使用全新的數據集,數據集取自鎮江市新區大港汽渡公司。通過船舶上面對駕駛員的監控視頻處理得到的圖片,采用專門的圖形標注軟件對各種危險駕駛行為進行目標對象標注,并且轉化為標準的目標檢測數據集格式。一般數據集格式包含Annotations、ImageSets和JPEGImages三個文件夾,Annotations文件夾保存了圖片的標注信息,一般是xml格式;用于訓練、驗證和測試的樣本名稱記錄在ImmageSets文件夾,一般是txt格式;而JPEGImages文件夾保存了所有圖片,圖片的格式為JPG格式。經過人工的篩選和標注,我們最后搜集的圖片每類圖片各1000張,共6000張。通過水平翻轉、調節圖片對比度、多角度旋轉圖片、放大裁剪等多種方法擴充數據集數量至10000張,其中圖片標注文件也需隨圖片變換做相應的坐標變換。
3.3 SSD網絡模型訓練
危險駕駛行為檢測模型在SSD模型的基礎上,訓練模型的服務器GPU為GTX1060,訓練參數如下:模型識別種類數為6;每次訓練更新參數時,批處理圖片的數量為24,即batch_size值為24;載入模型的訓練圖片大小為300*300;初始學習率為0.004,每訓練1000次學習率變為上次學習率的0.99倍,使用不斷減小的學習率提高模型權重值的準確度,由此提高整個模型的識別精度;momentum動量優化值為0.9;模型采用l2正則化,如式(1)所示,其作用為對最優的元素進行不同比例縮放;計人計車模型的總訓練次數為20萬次,即epoch值為200000。
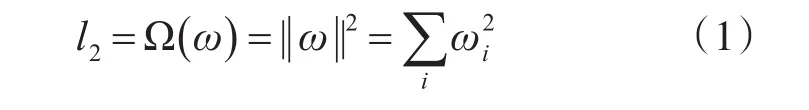
4 結果分析
本系統采用docker部署,docker現在在業界應用越來越廣泛,而且docker運行相當于在一個容器里面,不會與主機中其他依賴產生沖突,啟動、重啟和關閉都比較方便。根據制作的數據集和訓練過之后的模型,我們對真實視頻進行處理。視頻為真實室內環境,視頻幀尺寸為450×450像素,視頻處理幀率為15fps,實現了實時處理。針對每種危險駕駛行為,我們對檢測模型的結果和實際的情況進行統計,主要結果如表3所示。
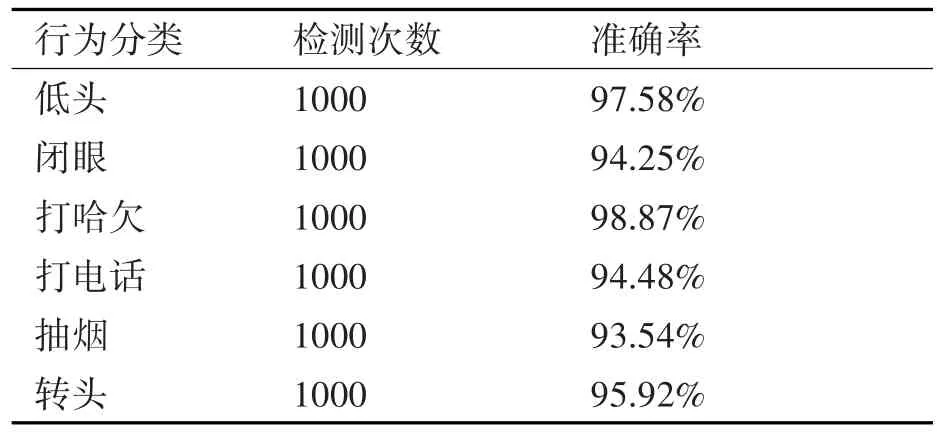
表3 檢測結果
測試效果如圖5所示。針對駕駛員的低頭、閉眼、打哈欠、打電話、抽煙、轉頭這些危險駕駛行為,訓練好的危險行為檢測模型都能很好地檢測出來。

圖5 測試效果圖
5 結語
本文提出了一種基于SSD模型的船載危險駕駛行為檢測系統。該系統主要是通過檢測模型讀取監控視頻的實時RTSP流進行分析,檢測到有危險駕駛行為出現的話,就會有語音報警,并且檢測程序會通過MQTT數據包將該行為檢測的信息發送到遠程后臺管理平臺。后臺管理平臺可以接收到這些消息并且保存到數據庫當中并且通過界面展示,這極大地方便了管理部門查看船員的駕駛情況,也能夠避免江河流域上面交通事故的發生。從實驗結果來看,采用SSD模型經過數據集的訓練之后,準確度識別度為95.76%,視頻處理平均幀率為15fps。由此可見,該船載危險駕駛行為檢測系統檢測效果明顯,具有非常廣泛的應用價值,如果應用到水上交通安全上將會規避很多不必要的事故發生,保障生命安全,減少人民財產損失。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車實用技術(2022年14期)2022-07-30 06:13:42
汽車實用技術(2022年4期)2022-03-07 06:07:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
