高分辨率遙感影像城中村提取的景觀語義指數方法
2021-01-18 01:01:38丁樂樂史芙蓉
測繪學報 2021年1期
張 濤,丁樂樂,史芙蓉
1. 天津市勘察設計院集團有限公司,天津 300191; 2. 武漢大學測繪遙感信息工程國家重點實驗室,武漢 430079
中國在快速的城市化進程中,大量農村土地被政府部門征收用于城市建設與發展,而他們的聚居地由于拆遷安置成本較高,大多被完整地保留下來,并且逐漸被擴張的城市區域所包圍。這些居民區被形象地稱為“城中村”(urban villages,UVs)[1]。如今,城中村廣泛分布于中國的各大城市,如廣州、深圳、武漢等城市,在城市化進程中,為眾多的外來務工人員提供了廉價的住房,然而城中村也給城市的可持續發展帶來諸多問題[2]。城中村內部建筑分布擁擠,缺乏公共基礎設施,人口混雜,容易引發環境衛生問題。因此,及時有效的城中村制圖信息對城市管理非常必要,能幫助城市管理人員制定合理的城市規劃方案。然而,許多中國城市依然缺乏細致的城中村信息,傳統的數據獲取方法主要是實地測繪與調研,耗費巨大的人力與時間[3]。
隨著遙感技術的發展,高分辨率遙感影像已經廣泛應用于城市基本地物要素的監測[4],比如城市功能區(urban functional zone)的分類[5],建筑與道路等不透水面的提取[6-8]。但是,國內利用遙感影像進行城中村的研究還相對較少,現有的城中村研究主要集中在社會科學領域,且多是局部案例分析,缺乏大范圍、連續的城中村空間分布信息[9]。同時,筆者也注意到,國外有一些針對貧民窟(slum)或者非正式居民區(informal settlements)提取的相關研究,而貧民窟與城中村在物理外觀上具有一定的相似之處。文獻[10—11]采用面向對象的影像分析方法分別從IKONOS和QuickBird影像上進行貧民窟的提取,文獻[12]采用邊緣檢測和基于間隙度(lacunarity-based)的方法進行貧民窟的識別,文獻[13]采用機器學習的方法并聯合SAR影像的極化和紋理特征,提取了印度孟買的貧民窟。目前大部分方法主要依賴于影像的光譜和紋理等底層特征信息,比如常用的灰度共生矩陣測度(gray-level co-occurrence matrix,GLCM)[14-15],但是這些底層特征依然難以描述大范圍復雜的城中村場景。
遙感影像中地理要素的空間分布與排列所形成的具有可區分性的模式稱之為景觀。與現代城市景觀相比,城中村具有顯著而獨特的物理特點,主要表現為建筑覆蓋率高、建筑個數多、建筑尺寸小、建筑間距近等。因此,可以通過這些典型的景觀特征來推斷該場景的語義功能。并且,景觀特征具有明確的物理意義,該物理意義不依賴于影像的光譜和紋理屬性,只與基本地理要素的實際分布模式有關。因此,景觀特征可以看成是一種高層次的語義信息,具有較強的場景特征表達能力。建筑景觀特征的計算依賴于準確的建筑覆蓋信息,本文采用形態學建筑指數(morphological building index,MBI)來進行建筑特征提取[16]。MBI旨在建立基本的形態學運算與建筑屬性之間的關聯,是一種較為有效的自動化建筑提取指數,已經成功應用于建筑提取和變化檢測等領域[17-18]。本文中,只要MBI在城中村區域內能夠表征更密集分布的建筑,相對于非城中村能表現出明顯可區分的空間排列模式,那么基于MBI提取的建筑計算的景觀指數就有望描述城中村的場景特點,從而進行城中村的提取。
另外,在大范圍的遙感制圖實踐中,為了提升制圖產品的精度,需要修正制圖過程中存在的一些錯誤,以滿足后續應用的需求。本文將根據機器學習的輸出結果評估分類置信度,對不同置信度的分類結果分別進行精度評價,以城中村制圖應用為導向,對其中的低置信度分類結果進行檢查修正。該“分類置信度-反饋”機制能夠參考機器學習輸出的概率,以有限的人工干預提升最后的制圖精度,在大規模的遙感應用中是一種實際可操作的人機交互策略。
1 研究區與試驗數據
本文的研究區是中國的超大城市廣州。在快速的城市化進程中,廣州的城區內留下了眾多的城中村,而且有些城中村位于城市的中心地帶,引發了嚴重的環境和土地利用問題。從圖1可以看出城中村內部雖然光譜特征復雜,但是它們擁有一些共性特點:城中村的建筑分布擁擠而密集,居住環境較差,這種建筑分布模式是城中村比較普遍的特點。這為城中村的場景語義推斷提供了線索。
本文從天地圖(http:∥www.tianditu.cn/)上獲取高分辨率衛星影像,影像包含可見光3個波段,分辨率為2 m, 覆蓋廣州核心城區約300 km2。該影像的光譜和分辨率信息能夠較好地支撐單個建筑物的提取,從而進行城中村場景的推斷。此外,本文獲取了開放地圖OpenStreetMap (OSM)[19]的道路矢量數據作為輔助數據用于城市的街區分割。最后,衛星影像和OSM數據都投影到WGS-84 UTM Zone 49坐標帶,且兩種數據源能夠很好地疊加貼合。
2 城中村提取方法
本文的關鍵在于針對城中村這個特定分類任務,如何設計有效的特征來描述復雜的城中村場景。在深入了解城中村的物理特點后(建筑覆蓋率高、個數多、尺寸小、間距近等),本文采用幾個典型的景觀語義指數來描述建筑的空間分布特征,實現城中村的提取(圖2)。首先,采用道路矢量將影像分割成不同的街區作為基本的制圖單元,然后采用形態學建筑指數從影像上提取建筑特征,并在街區層計算典型的景觀指數來表征建筑物的空間分布模式;接著采集訓練樣本輸入分類器進行模型訓練和分類,根據機器學習輸出的分類概率得到高、低置信度結果,并有針對性地對低置信度分類結果進行檢查修正,得到更準確的城中村制圖信息;最后基于該制圖產品進行相關的土地政策分析,服務于城市管理與規劃。
2.1 基本制圖單元
城中村的識別可以看成是一個場景分類或者土地功能制圖的任務[20]。目前,已經有一些研究采用道路矢量數據將影像劃分成不規則的多邊形區域(即街區)用于土地功能的制圖[21]。街區是現代城市管理的基本單元,一般被多條道路包圍形成,沒有固定大小,但是內部的土地利用和功能屬性相對一致,因此,與規則的格網相比,街區具有天然的語義信息。街區劃分的道路矢量數據一般來源于現有的道路GIS數據,比如OpenStreetMap(OSM)。OSM是一個開源的地圖[19],能夠提供矢量格式的道路數據。本文采用道路矢量數據劃分城市街區并作為城中村識別和制圖的基本單元(圖3)。在實際應用中,GIS道路數據可能會有所缺失,一般需要參考衛星影像進行檢查,對不一致的地方進行必要的修正。
2.2 城中村場景表達
一般而言,城中村內部的建筑分布表現為:覆蓋率高、個數多、尺寸小、間距近。根據這些特點,能夠推斷建筑的空間排列信息是區分城中村與其他場景(如現代居民區和自然場景)的關鍵要素。因此,本文采用幾個典型的景觀語義指數,包括建筑斑塊覆蓋率(PLAND)、建筑斑塊個數密度(PD)、平均建筑斑塊面積(MPA)以及平均建筑斑塊最鄰近距離(MNND)來描述建筑物的空間分布特點(表1)。這些典型的景觀語義指數具有明確的物理意義,易于理解,能夠較好地區分城中村與非城中村場景。在每個街區內,計算以上地物的景觀指數,作為該街區場景的特征表達。

表1 本文用于城中村提取的景觀語義指數
在定量計算建筑的景觀語義指數之前,需要獲取影像上的建筑覆蓋信息。本文采用形態學建筑指數[16](morphological building index,MBI)進行建筑提取。MBI的主要思想是通過基本的形態學運算(如白頂帽變換,形態學差分)描述建筑物的內在屬性(如亮度、對比度、方向和尺寸等)。MBI的構建主要包含以下3個步驟:①計算亮度影像作為后續處理的基影像,由于建筑的材質在可見光波段范圍內一般表現為較高的反射率,因此亮度影像定義為每個像素在可見光波段的最大值。②采用多尺度和多方向的線性結構元素對亮度影像進行白頂帽變換(WTH),并生成差分形態學特征(DMP)來表征不同尺度和方向上的建筑分布。③對DMP-WTH形態學譜進行均值聚合凸顯建筑的存在,這是考慮到建筑相對于狹長的道路顯得更加各向同性。MBI定義如下
(1)
式中,DMP-WTH是基于WTH的DMP特征;s和d分別表示WTH變換中線性結構元素的尺寸和方向;Ns和Nd分別表示尺寸和方向的總數。

圖1 本文高分辨率遙感影像Fig.1 High-resolution remote sensing image used in this study
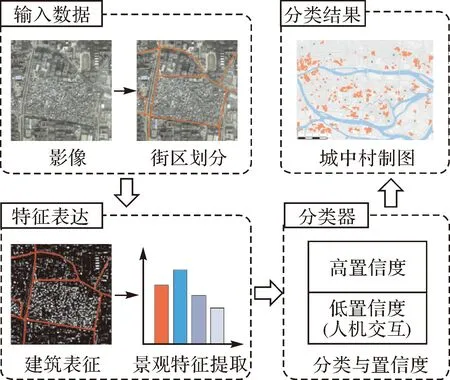
圖2 本文方法流程Fig.2 Framework of this study
圖4展示了城中村與非城中村場景的MBI特征,可以看到MBI特征影像能夠較好地反映建筑信息。同時,也注意到MBI主要適用于具有較高局部對比度的建筑,對一些較暗的建筑提取效果不佳。雖然MBI無法精確提取城中村內的每個建筑,但是相對于城市其他景觀,在城中村內,MBI還是能夠表征更密集分布的建筑。從MBI的特征圖中依然可以看到城中村內的建筑分布具有明顯可區分的模式,主要表現為建筑覆蓋率較高、建筑個數較多、建筑尺寸較小、建筑間距較近等特點。
更進一步,本文分別選擇了40個城中村和非城中村街區,計算了它們的景觀特征分布(圖5)。可以看出來,基于MBI計算的景觀語義指數在城中村與非城中村場景下具有比較明顯的差異,尤其是城中村的建筑斑塊覆蓋率(PLAND),建筑斑塊個數密度(PD)顯著高于非城中村,而城中村的平均建筑斑塊最鄰近距離(MNND)顯著低于非城中村,這與城中村的物理特點是相符的。此外,平均建筑斑塊面積(MPA)的差別較小,這可能是因為一些非城中村區域包含了一些沒有建筑的自然區域,如綠地、公園等。但是從特征的可解釋性出發,本文也保留這個基本的語義指數。因此,采用MBI指數以及景觀特征能夠定量衡量建筑的空間排布模式,較好地描述城中村的場景語義信息。

圖3 道路矢量街區分割Fig.3 Local example for city blocks enclosed by road networks

圖4 城中村與非城中村的局部景觀Fig.4 Local examples of UVs and non-UVs
2.3 “分類置信度-反饋”機制
本文采用隨機森林(random forest,RF)作為城中村場景識別的分類器。RF是一個著名的集成學習分類器,它通過多棵決策樹的眾數投票結果決定最后的類別輸出[23]。RF由于其較好的穩健性,特征重要性計算方便等優勢,已經廣泛應用于遙感影像的土地覆蓋分類[5,24]。RF不僅能夠輸出硬分類結果(類別標簽),它還能通過考慮每棵決策樹的投票結果得到每個類別的分類置信度,可以表示如下
(2)
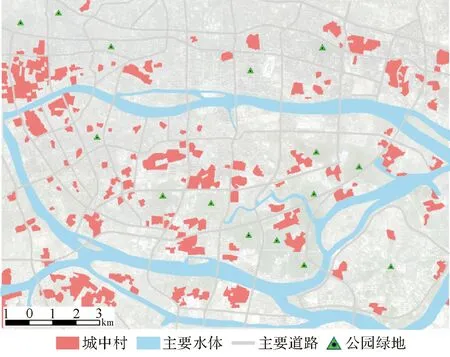
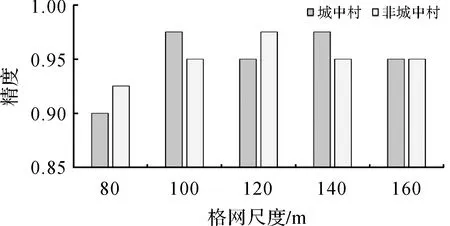
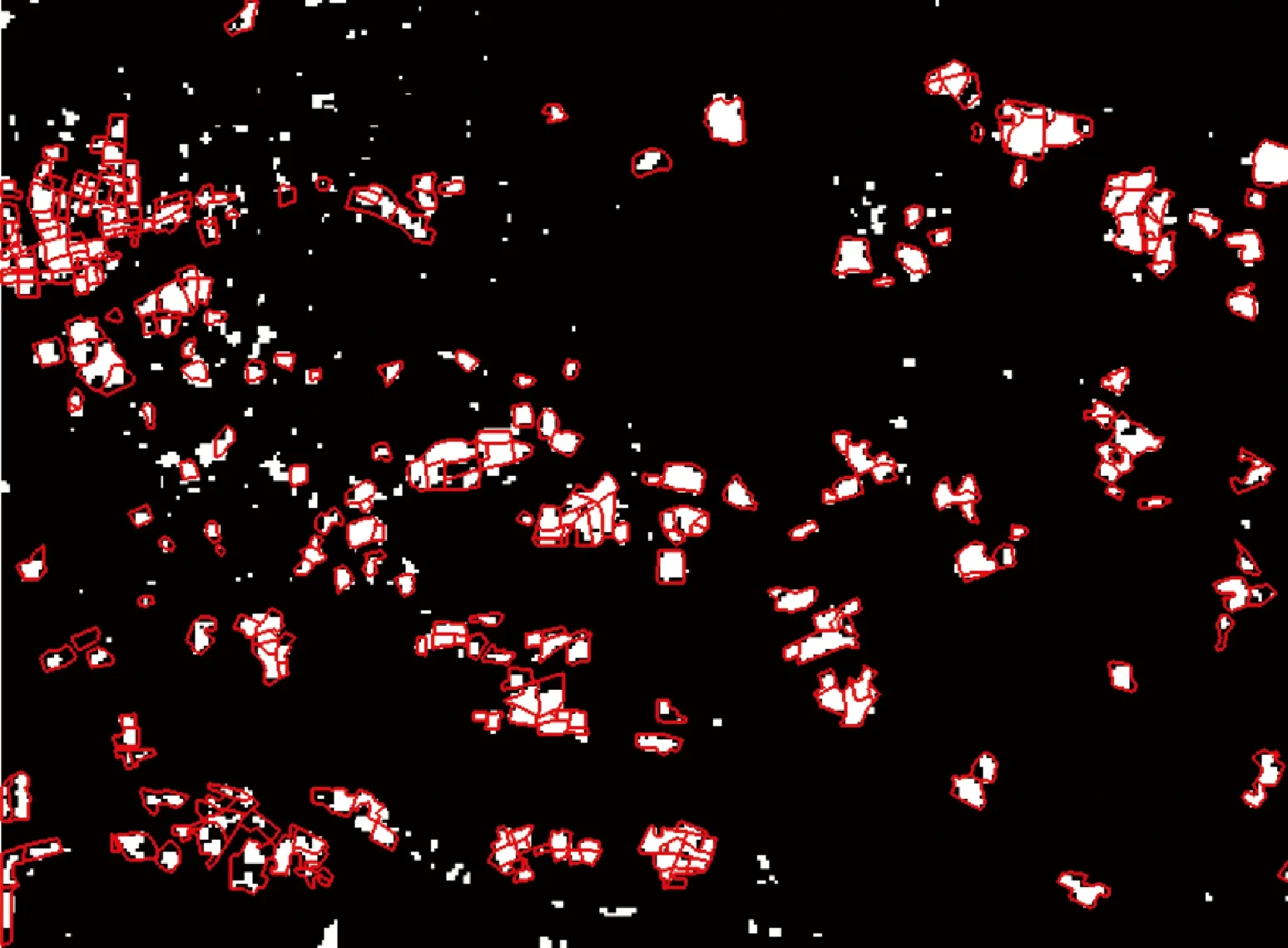
式中,R(x)指街區x分類結果的置信度;TreeNumber指決策樹的棵數,本文試驗中設為100棵;votek指第k個類別的投票數,也就是本文試驗中識別成城中村(k=1)或非城中村(k=2)的投票數。根據R(x)的數值,將所有街區的分類結果置信度分成高置信度(R(x)>0.9)和低置信度(0.5 圖5 樣本景觀特征分布Fig.5 Landscape feature distribution of training samples 在高分辨率影像與電子地圖的輔助下,分別隨機選擇了40個城中村和非城中村街區作為訓練樣本,這些樣本均勻地分布在整個研究區,并且空間分離,確保其空間獨立性。隨后,將訓練樣本與街區景觀特征聯合輸入到RF分類器中進行城中村的識別。 所有街區的分類結果都會根據式(2)標記為高置信度結果或者低置信度結果。根據分類置信度采用分層隨機抽樣方法(stratified random sampling)選取了一定數量的樣本進行精度評價,選擇的測試樣本(街區)與訓練樣本保持獨立。對于高/低置信度的分類結果,隨機選擇40個城中村和40個非城中村街區進行精度驗證。城中村街區正確分類的個數越多,表示城中村探測的錯分誤差越小,即正確性越高。同時,在非城中村類別中,正確分類的個數越多,表明城中村探測的漏分誤差越小,即完整性越高。 本文研究區內,大部分街區都以高置信度被劃分成城中村或非城中村。在城中村類別中,高置信度分類結果的比例為79.5%,同時,在非城中村類別中,高置信度分類結果的比例為94.9%。表2展示了不同分類置信度下的城中村與非城中村的分類精度。可以看出來,高置信度的分類結果表現出較高的精度,其中城中村類別的正確率為92.5%,非城中村類別的正確率為100%。這表明,本文方法在城中村探測任務中,主要存在的是錯分誤差,而漏分誤差相對非常小。一些與城中村比較類似的區域相對容易識別錯誤,而一旦分類器認為某個街區不是城中村,則該結果具有較高的可信度。而對于低置信度的分類結果,精度則相對較低,其中城中村類別的正確率為65%,非城中村類別的正確率為85%。 表2 不同分類置信度下的城中村與非城中村探測精度 此外,文獻[13,15]都采用了GLCM的方法分別從雷達影像和光學影像上提取了貧民窟(slum)區域。因此,本文也采用GLCM紋理特征提取城中村作為對比方法。GLCM的紋理測度包括常用的均值(mean),方差(variance),同質性(homogeneity),對比度(contrast),不相似性(dissimilarity),熵(entropy),二階矩(second moment)和相關性(correlation)。紋理特征以街區為單元,計算4個方向上(0°,45°,90°,135°)的特征,然后求取平均值,消除GLCM特征的方向性。一般而言,城中村內的建筑分布雜亂,建筑材質多樣,城中村的紋理異質性較高。 采用上述相同的160個測試樣本街區進行評定,結果表明本文方法的城中村提取精度更優。對于采用景觀指數檢測到的非城中村樣本,對比方法在這些區域表現的錯誤較多。這些非城中村區域內部一般包含多種地物類型(如建筑、植被、裸地與廣場),光譜豐富多變,紋理異質性較高,容易與城中村的紋理特征混淆。對比結果說明相對于光譜、紋理等底層影像特征,本文采用的景觀指數物理意義明確,具有較高的語義信息,并且特征維度相對更低,能夠更好地描述城中村的根本形態特點。 最后,綜合考慮分類結果的高低置信度比例及其精度,為了生產更加精確的制圖產品,針對低置信度分類結果進行檢查和修正。由于低置信度的分類結果只占探測結果中很少的一部分,只需要少量的人工干預,就能夠提升整體的制圖精度。通過這種“分類置信度-反饋”機制,一些錯誤標記的城中村能夠被去除,與此同時,一些遺漏的城中村可以得到補充。在大范圍的遙感應用中,這種機制考慮了機器學習輸出的分類概率,是一種有效的人機交互方式。 RF中每顆決策樹的構造實際上只用到了部分的訓練樣本,而沒有用到的樣本稱之為袋外數據(out-of-bag samples)[7],可用于驗證該決策樹的分類精度。當對某個屬性進行隨機重新排列(randomly permuted),此時RF中所有決策樹分類精度的平均減少量可以衡量該特征的分類重要性。如果對某個特征的隨機數值重排使得分類精度減少較多,則認為該特征對分類的貢獻度較大。特征重要性詳細計算步驟可參見文獻[25]。圖6展示了本文選取的景觀語義指數在城中村識別中的重要性。可以看出來,建筑斑塊個數密度(PD)表現出最高的貢獻度,其次是平均建筑斑塊最鄰近距離(MNND),建筑斑塊覆蓋率(PLAND)。實際上,城中村最主要的物理特點就是建筑分布密集,建筑覆蓋率高,建筑間距小。而平均建筑斑塊面積(MPA)對于城中村的識別作用相對較小,這可能是由于其他的城市功能區也分布著較小尺寸的房屋,比如高檔住宅區。總之,從城中村的物理特點以及特征的可解釋性出發,本文選取的典型景觀語義指數直觀且物理意義明確,較好地描述了城中村的形態,特征重要性的定量排序結果與城中村的物理特點是相符的。 圖6 城中村提取中的特征重要性Fig.6 Feature importance in UVs detection 圖7展示了研究區內城中村的制圖結果,在研究區范圍內共檢測出330個城中村街區,占地面積2525公頃。城中村的存在給城市的可持續發展帶來諸多問題。首先,城中村居住環境惡劣,嚴重影響城市景觀。另外,城中村內土地價值沒有完全開發。在城市建設中,政府經常面臨城市用地短缺的問題[26],而一些城中村占據了城市中優越的地理位置,但是土地利用非常低效[2]。為了促進土地的高效利用,城中村的改造不可避免。然而,城中村的改造進度卻比較緩慢。一方面,城中村為大量外來務工人員提供了廉價的住房,在城市化進程中也發揮了一定程度上的積極作用[3]。據報道,廣州的城中村容納了超過600萬的外來人口。另一方面,城中村拆遷過程中的利益沖突也會嚴重影響城中村的拆遷進度。廣州是中國的一線城市之一,城中村改造成本昂貴。因此,廣州的城中村改造相對緩慢,盡管如此,廣州2016年發布的“十三五”規劃中仍然提到要將城中村改造作為城市更新的重點行動。 上文在街區層進行了城中村的提取,街區層的城中村制圖結果比較適用于實際的城市規劃與管理,但是街區分割受制于預先提供的道路矢量數據。本節在格網層繼續探討更細粒尺度的城中村提取。格網劃分不依賴于外部矢量數據,但是需要注意格網的尺寸設置。一般而言,格網大小需要覆蓋一個完整的場景區域,其內部應當具有比較明顯的場景模式。在城中村提取任務中,考慮到城中村內建筑的大小與空間分布,本文探索了不同格網尺度下的城中村提取結果。格網邊長分別設為80、100、120、140、160 m,對應影像上的像素個數分別為:40、50、60、70、80。采用半重疊格網來進行城中村場景特征的提取(景觀語義指數),以減少格網劃分帶來的邊緣效應,重疊區域對分類概率采用均值操作。對于每個尺度,隨機標記了80個城中村和80個非城中村格網場景作為參考數據,其中40個城中村和40個非城中村場景作為訓練數據,其余為測試數據。格網尺度的城中村檢測精度如圖8所示。 圖7 廣州城中村制圖結果Fig.7 UVs mapping in Guangzhou 圖8 不同格網尺度下的城中村提取精度Fig.8 Accuracy of UVs detection at grid level with different spatial scales 可以看到,當格網尺度為80 m時,精度相對較低,這說明該空間尺度不能充分表征城中村的場景特點,而格網尺度較大時,精度相對較高。但是,也要認識到,大的格網尺度會導致明顯的邊緣效應,使得城中村提取結果不夠精細。因此,格網層的城中村提取需要考慮精度與精細度之間的平衡。在試驗中,格網尺度在120 m左右時,能夠覆蓋具有一定空間模式的城市基本地物,從而能夠較好地表征城中村的場景特點。圖9展示了120 m格網尺度下的城中村提取結果,與街區層提取結果疊加顯示,表現出了較高的一致性。 城中村的空間分布信息對城市管理非常必要。本文從城中村的物理特點出發,設計采用景觀語義指數描述高分辨率遙感影像上復雜的城中村場景(主要是建筑的空間排列模式),并采用“分類置信度-反饋”機制,進行了大范圍的城中村提取與制圖。結果表明,景觀指數物理意義明確,具有高層次的語義信息,能夠成功地進行城中村場景表達,而且“分類置信度-反饋”機制能夠引導參考機器學習輸出的分類概率專門針對低置信度分類結果進行檢查修正,以有限的人工干預生產更加準確的城中村制圖產品,為后續的應用提供基礎。結果表明,本文方法能夠應用于大范圍的城中村提取與制圖,未來可以將其拓展到多時序影像,探究城中村的時空演變。 注:紅色邊框為街區層提取結果圖9 格網尺度(120 m)的城中村提取結果Fig.9 UVs detection result at grid level with spatial scale of 120 m
2.4 精度評價
3 試驗與分析
3.1 城中村提取精度

3.2 特征重要性

3.3 城中村現狀與土地政策分析
3.4 精細尺度城中村提取探討
4 總 結
猜你喜歡
現代裝飾(2021年6期)2021-12-31 05:27:54
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小學科學(學生版)(2020年12期)2021-01-08 09:28:10
少年漫畫(藝術創想)(2020年12期)2020-06-09 05:50:08
開放教育研究(2020年2期)2020-03-31 01:54:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
