基于機器學習的跨患者癲癇自動檢測算法
2021-01-18 08:04:16楊舒涵周豐豐
吉林大學學報(理學版) 2021年1期
楊舒涵, 李 博, 周豐豐
(1. 吉林大學 計算機科學與技術學院, 長春 130012;2. 吉林大學 符號計算與知識工程教育部重點實驗室, 長春 130012;3. 吉林大學 軟件學院, 長春 130012)
癲癇是一種神經系統的疾病[1], 嚴重危害患者的生命安全. 癲癇檢測可幫助醫生更好地了解患者的發病信息, 并根據檢測結果結合其他檢測工具, 實現病灶定位. 傳統檢測方法是通過詢問患者家屬關于患者的以往發病史, 并觀察患者的腦電數據, 得出結論. 腦電數據, 即腦電圖(electroencephalo-graphy, EEG), 是一組隨時間變化連續的一維數據, 可記錄大腦活動時的電信號. 癲癇發作時, 通常會伴有大腦神經元的異常放電, 因此腦電數據對癲癇的檢測有很大幫助. 癲癇檢測被視為一個二分類問題, 分為發作期和發作間期, 發作間期指兩次發作期之間的時刻. 目前對癲癇自動檢測的研究多集中于專人專治, 即為每個患者建立自身的檢測模型. Vidyaratne等[2]先使用快速小波分解和分形維數方法對腦電數據進行特征提取, 再使用相關支持向量機模型進行分類, 實現了模型與患者相關的癲癇檢測. 該方法分類結果較好, 但是也存在以下問題: 首先, 模型的建立需要患者的以往發病記錄, 而當患者無發病記錄時, 即無法為該患者進行檢測; 其次, 該模型不具有泛化性, 即一個患者的模型無法適用于其他患者.
針對上述問題, 本文提出一種使用機器學習的跨患者癲癇自動檢測算法. 該算法首先使用濾波器對原始腦電數據進行固定頻率范圍的數據過濾, 達到去除噪聲的目的; 然后從時域角度和非線性角度對濾波后的數據進行特征提取; 再使用遞歸特征消除(recursive feature elimination, RFE)和序列后向選擇(sequential backward selection, SBS)算法對提取到的特征做進一步篩選, 被選擇特征作為分類模型的輸入數據; 最后用XGBoost(eXtreme gradient Boosting)模型分類, 實現癲癇的自動檢測. 本文檢測算法在特征提取后增加了基于XGBoost模型的特征選擇算法, 能選擇出更具有代表性和泛化性的特征, 并使用XGBoost模型進行分類. 實驗結果表明, 該方法不僅減少了特征數量, 簡化了模型的復雜度, 且提升了模型的分類性能.
1 跨患者的癲癇自動檢測模型
本文癲癇自動檢測算法基于采集到的腦電數據, 通過一系列機器學習算法得到最具代表性的特征矩陣, 然后輸入到分類模型中, 得到最終的分類結果. 實驗流程如圖1所示.

圖1 癲癇自動檢測實驗流程Fig.1 Experimental process of automatic epileptic seizure detection
1.1 數據預處理
常用的腦電數據是通過將電極放置在患者頭皮上采集得到的, 這種采集方式對人體無傷害, 成本較低, 患者易接受, 但因為是外置電極, 所以很可能受外界干擾, 導致數據中摻雜一些噪聲, 影響最后的分類結果. 濾波算法是一種常見的去除腦電信號中噪聲的方法, 本文使用帶通濾波器, 其可使一個特定頻段的數據通過濾波器, 而抑制或削弱其他頻段的數據. 常用于癲癇病診斷的頻段為0.01~32 Hz[2], 在該范圍內的頻段又分為4種不同的腦波, 分別為δ波(1~3 Hz)、θ波(4~7 Hz)、α波(8~13 Hz)和β波(14~30 Hz)[3]. 因此, 本文分別使用四階Butterworth濾波器、 Chebyshev濾波器、 Bézier濾波器和橢圓濾波器對原始的腦電數據進行0.01~32 Hz的濾波, 并研究不同類型腦電波的特征.
1.2 特征提取
原始的腦電信號數據量較大, 數據不具有代表性, 使用特征提取方法可提煉出更有意義的數據建立模型. 本文主要從時域角度和非線性角度對腦電數據進行特征提取.
設T為腦電數據. 對于時域特征提取, 本文從一段腦電數據T中主要提取了21種特征, 其中前11種包括數據的最大值(maxT)、 最小值(minT)、 平均值(meanT)、 標準差(stdT)、 方差(varT)、 總體變化量(totalT)、 偏斜度(Skewness)、 峰度(Kurtosis)、 平均能量比(APR)、 峰值(Peak)和均峰比(PAR). 定義一段時長的腦電數據T=(T1,T2,…,Tn), 其中n為數據點個數. 則總體變化量計算公式為
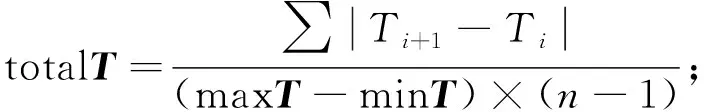
(1)
偏斜度計算公式為
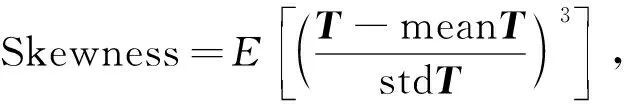
(2)
其中E表示對括號中值求期望; 峰度計算公式為
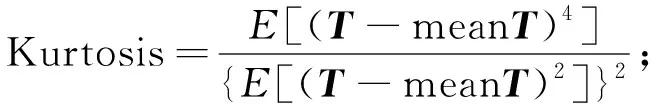
(3)
平均能量比計算公式為
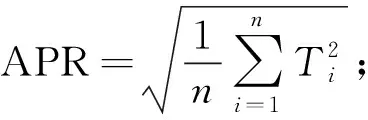
(4)
峰值計算公式為
Peak=max{|maxT|,|minT|};
(5)
均峰比計算公式為
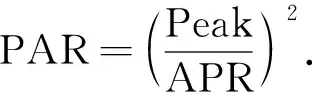
(6)
后10種特征是根據腦電數據波動情況得到的一種百分數, 計算步驟如下:
1) 創建數組L=(L1,L2,…,Lk), 用于保存一段時長腦電信號T中相鄰波峰(相鄰數據點的值均小于當前數據點的值)和波谷(相鄰數據點的值均大于當前數據點的值)差值的絕對值.
2) 定義L_min=min{L},L_max=max{L}, winNum=10, feet=(L_max-L_min)/winNum, 其中:L_min為L中的最小值, 作為直方圖橫軸的左側起始點;L_max為L中的最大值, 作為直方圖橫軸的右側終止點; feet作為直方圖的組距寬度. 即直方圖的橫軸被分為10組, 每組取值分別為[L_min,L_min+feet),(L_min+feet,L_min+2feet),…,(L_min+9feet,L_max].
3) 統計L中數據落在直方圖中每個組內的個數, 并除以數組L的長度k進行歸一化, 結果定義為Bin1,Bin2,…,Bin10, 該結果即為后10個時域特征.
對于非線性特征提取, 本文提取了8種特征, 分別為小波熵(WaveletEn)[4-5]、 信息熵(SampEn)[6]、 排列熵(PeEn)[7]、 去趨勢波動分析方法(DFA)[8]得到的實驗結果、 分形維數值(PFD)、 RS法計算得到的Hurst指數以及使用Hjorth參數計算得到的移動性值(mobility, HM)和復雜性值(complexity, HC)[9]. 實驗采用的所有特征提取方法已整理為python代碼上傳至https://github.com/yangsh827/Seizure_FE. 本文特征提取階段獲得的特征列于表1.

表1 根據腦電數據提取的特征Table 1 Features extracted by EEG data
1.3 特征選擇
本文結合計算機領域與生物醫學領域的相關知識, 使用機器學習算法實現跨患者的癲癇自動檢測. 生物醫學領域的數據具有樣本少、 特征多的特點, 當輸入分類模型的特征接近或大于樣本數時, 會增加分類模型的復雜度, 模型很可能出現過擬合的情形, 使其不具有泛化性, 同時還會增加模型的訓練時間. 因此, 需要對特征矩陣進行特征選擇. 目前在機器學習中, 特征選擇通常分為3種類型: 過濾式、 包裝式和嵌入式, 如圖2所示.

圖2 特征選擇的分類Fig.2 Classification of feature selection
本文主要使用包裝式中的兩種特征選擇算法, 一種是遞歸特征消除法RFE, 另一種是基于貪心算法的SBS. 首先將特征提取后的特征矩陣進行RFE特征選擇. RFE是一種常用的特征選擇算法, 其主要思想是先在原始的特征矩陣中遞歸地刪除特征, 然后用剩余的特征構建模型. 通過模型的評價指標判斷哪些特征(或特征組合)對預測結果貢獻較小, 從而對其進行剔除. 該算法的時間復雜度為O(n), 算法步驟如下:
1) 歸一化處理特征提取后的特征矩陣, 將其結果作為RFE算法的輸入數據;
2) 選擇一種可得到各特征權重的模型作為基分類器, 設每輪訓練減少的特征數為n, 最終要保留的特征數為k, 選擇模型的評價指標;
3) 對輸入數據集進行訓練, 得到各特征的權重, 并用五折交叉驗證得到該模型各評價指標值;
4) 將特征的權重從大到小排列, 從數據集中移除n個擁有最小絕對值權重的特征, 得到下一輪輸入的數據集;
5) 重復步驟3),4), 當剩余特征數為k時, 算法停止.
實驗中, 設參數n=1,k=1, 即每次去除一個特征, 在特征數減少到1時RFE算法停止. 通過步驟3), 可得每輪交叉驗證的結果, 選擇具有最好性能模型對應的特征數, 作為本文實驗RFE算法最終選擇出的特征數.
經過RFE特征選擇后, 使用SBS算法對特征進行進一步篩選. SBS算法是一種啟發式搜索算法, 使用貪心算法的思想. 該方法選擇一個模型作為基分類器, 每次從特征矩陣中移除一個特征, 使特征矩陣在移除該特征后得到的評價指標相對于移除其他特征是最優的. SBS算法由于在每次移除特征時, 都要對剩余的所有特征模型進行訓練, 因此該算法的時間復雜度為O(n2), 故將其作為RFE特征選擇后的進一步篩選.
1.4 分類模型
本文使用的分類器以及在RFE和SBS算法中使用的基分類器均為XGBoost模型, 其為一種集成的機器學習模型, 該模型在各項算法競賽中均表現良好, 因此本文使用XGBoost作為分類模型.
2 數據集與評價指標
2.1 數據集
實驗采用CHB-MIT頭皮腦電信號公開數據集. 該數據集采集于美國波士頓一家兒童醫院, 共記錄了23名癲癇患者的腦電數據, 采樣頻率為256 Hz, 共包含157次癲癇發作. 數據采集時, 電極在患者頭皮的放置位置遵循國際標準10-20系統. 該數據集中大部分樣本均包含22個通道(FP1-F7,F7-T7,T7-P7,P7-O1,FP1-F3,F3-C3,C3-P3,P3-O1,FZ-CZ,CZ-PZ,FP2-F4,F4-C4,C4-P4,P4-O2,FP2-F8,F8-T8,T8-P8,P8-O2,P7-T7,T7-FT9,FT9-FT10,FT10-T8)的數據, 因此本文僅使用包含上述22個通道的樣本. 同時, 因為chb12患者的發作間期持續時間較短(平均415 s), chb16患者的發作期持續時間較短(平均8.6 s), 因此未采用這兩位患者的數據.
實現癲癇的自動檢測, 使用的檢測數據時長不應過長, 因此, 本文將檢測時長設為6 s, 即將發作期的數據以6 s為一個窗口進行無重疊滑動, 不足6 s的數據將被舍棄, 得到正樣本集合. 發作間期的數據也以6 s為一個窗口進行滑動, 得到負樣本集合. 因為發作間期時長遠大于發作期時長, 為避免由正負樣本數據量不平衡而導致模型偏向某類樣本, 因此本文實驗在負樣本中進行隨機采樣, 最終使正負樣本數據量相同, 得到正負樣本各1 260個.
2.2 評價指標
使用準確率(accuracy, Acc)、 敏感性值(sensitivity, Sn)和特異性值(specificity, Sp)測試算法的性能. 準確率Acc定義為分類正確的樣本占所有樣本的比例, 計算公式為
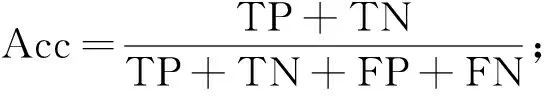
(7)
敏感性值Sn定義為分類正確的正樣本占所有正樣本的比例, 即正確判斷為患病的比例, 計算公式為

(8)
特異性值Sp定義為分類正確的負樣本占所有負樣本的比例, 即正確判斷為非患病的比例, 計算公式為
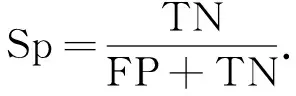
(9)
3 實驗結果與分析
3.1 實驗環境
本文用Python 3.6.4作為開發環境, 所用sklearn數據庫版本為0.19.1, numpy數據庫版本為1.16.3, pandas數據庫版本為0.22.0, scipy數據庫版本為1.0.0, XGBoost版本為0.71. 實驗環境需要安裝nolds數據庫(https://pypi.org/project/nolds/)和PyWavelet數據庫(https://pywavelets.readthedocs.io/en/latest/install.html). 實驗中各種算法的參數設置均使用函數默認參數.
3.2 結果分析
先分別使用Butterworth濾波器、 Chebysher濾波器、 Bézier濾波器和橢圓濾波器對原始腦電數據進行0.01~32 Hz的帶通濾波, 然后對濾波后的數據特征提取, 經過五折交叉驗證, 所得實驗結果列于表2. 由表2可見, 先用Butterworth濾波器對原始腦電數據進行濾波, 然后再進行特征提取, 得到的準確率Acc、 敏感性值Sn和特異性值Sp均高于其他3種濾波器, 說明Butterworth濾波器更適合本文癲癇檢測方法.

表2 4種濾波器的分類結果Table 2 Classification results of four filters
下面用Butterworth濾波器進一步分析不同頻率范圍的4種腦波(δ波、θ波、α波和β波)與癲癇檢測的關系. 用Butterworth濾波器先分別對腦電數據進行4種腦波對應頻率范圍的帶通濾波, 然后對濾波后的腦電數據特征提取, 經過五折交叉驗證, 所得實驗結果列于表3. 由表3可見, 對于綜合準確率Acc、 敏感性值Sn和特異性值Sp,β波(14~30 Hz)的分類結果比0.01~32 Hz頻率范圍和其他腦波的分類結果更優. 而β波是一種人在緊張情形下釋放的腦波, 實驗結果表明, 14~30 Hz頻率范圍的β波腦電數據更適合于本文檢測方法.

表3 在4種腦波上的癲癇分類結果Table 3 Classification results of epileptic seizure of four brain waves
用Butterworth濾波器對原始腦電數據進行β波(14~30 Hz)濾波去噪, 再進行特征提取, 共得到638個特征. 對這638個特征進行RFE特征選擇, 再對選擇后的特征矩陣使用SBS算法做進一步篩選, 經過五折交叉驗證, 每種特征選擇算法所得分類結果列于表4. 表4中特征數(features numbers, FNums)表示使用兩種特征選擇算法得到的最好分類準確率對應的特征數. 由表4可見: RFE算法將原始特征數由638個減少到66個, 分類準確率提升了2.5%; SBS算法將RFE選擇后的特征數由66個減少到44個, 分類準確率提升了1.63%. 表明機器學習中的特征選擇算法不僅提高了分類性能, 同時減少了特征數量. 因此, 針對經過特征提取的數據, 用本文的特征選擇算法可極大提高分類性能. 本文算法、 神經網絡算法[10]和隨機森林算法[11]的敏感性分別為0.854 8,0.850 0,0.808 7, 表明本文算法在敏感性值上優于另外兩種對比算法, 說明本文算法效果更佳.

表4 特征選擇算法RFE和SBS的分類結果Table 4 Classification results of feature selection algorithms of RFE and SBS
綜上所述, 本文提出了一種基于機器學習算法的跨患者癲癇自動檢測算法. 首先對原始腦電數據用濾波器去除噪聲, 從時域和非線性角度對去除噪聲后的腦電數據進行特征提取, 并在4種濾波器和5種頻率范圍的腦波中找出了更適合跨患者癲癇檢測的Butterworth濾波器和β腦波; 然后用基于XGBoost基學習器的特征選擇算法RFE和SBS對特征矩陣實現進一步的特征篩選; 最后在638個特征中保留了44個特征. 實驗結果表明, 本文使用機器學習算法, 在更少特征的情形下實現了更高的分類性能, 分類準確率Acc為0.877 4, 敏感性值Sn為0.854 8, 特異性值為0.9. 該結果在準確率上比特征選擇前提升了4.13%, 且在跨患者癲癇檢測模型中表現出更優的性能, 表明本文算法檢測性能更高、 效果更好.
猜你喜歡
中國民間療法(2021年5期)2021-06-09 09:21:04
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
電子制作(2019年15期)2019-08-27 01:12:00
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
飲食科學(2017年5期)2017-05-20 17:11:53
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
西南軍醫(2015年4期)2015-01-23 01:19:30
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
