水平井油藏建模統計偏差的處理方法與應用
2021-01-14 07:40:30張改革佟彥明
非常規油氣 2020年6期
關鍵詞:方法
張改革,佟彥明
(斯倫貝謝中國公司,北京 10015)
目前,隨著油田老井產能恢復、致密油氣壓裂開發增產以及頁巖油氣的大規模開發[1-3],水平井在常規油氣藏和非常規油氣藏的勘探開發中的應用越來越普遍。隨著水平井數量的增加,水平井數據在常規油氣藏精細表征中起著越來越重要的作用。由于水平井主要設計于儲層段,水平段延伸距離長,因此,應用水平井數據參與儲層精細表征與建模過程中,可以有效減小井間預測的不確定性,提高砂體連通性的分布預測[4-6]。
但是由于水平井一般針對特定目的層,在特定目的層段內水平層段的數據使得建模過程中目的層段的數據集中度過高,從而數據無法滿足統計學的無偏最優估計,因此,應用井上數據統計儲層的分布以及孔滲性不能正確反映儲層的特征[7-8]。
前人對如何應用水平井資料進行油藏精細描述和建模進行了大量研究,主要可以概括為以下幾點:①為砂體平面展布特征研究提供更多的資料來源;②落實目標油藏構造層面和精確落實砂體在縱向上的微構造起伏;③為物性模型提供更多平面上的有效數據[9-10]。水平井資料在以往的建模過程中,主要為幫助定性分析儲層在平面分布的非均質性,從而進一步提高儲層表征精度,但水平井資料在實際建模過程中的定量統計插值、水平井資料權重統計偏差的處理一直是困擾建模的一個難題,這在過往的研究中沒有提出有效的處理方法。
本文從建模過程中水平井資料的定量統計插值出發,闡述分析了水平井資料權重統計偏差的處理方法與適用條件,并應用理論沉積相模型驗證了處理方法對于提高儲層描述的精度與可行性,優化了定量統計插值中存在的問題。
1 統計偏差處理方法概述
常規直井油藏建模過程中對于采樣統計偏差的處理方法,一般為通過計算并賦值一定權重給不同采樣密度區域的相應數據,在計算過程中數據比較集中的區域使用較小的權重,而在數據較稀疏的區域使用較大的權重(通過調整數據統計分布實現)[11]。網格去叢聚方法即是通過應用網格的大小來控制不同區域井數據的分布的統計偏差,而對于水平井資料,由于水平井與直井的差異性,內核去叢聚法則能夠更好地處理數據的統計偏差。
1.1 方法原理
1.1.1 網格去叢聚方法
網格去叢聚方法為一種常規去權重的方法,這種方法是將地質模型劃分為不同的區塊網格,然后根據不同區塊網格內井上粗化網格的數量來計算每一區塊的權重方法。每一區塊的權重由區塊的大小和形態決定,這由建模數據分析中的I、J、K參數所設定,如圖1所示。因此尋找最優的I、J、K參數,對于網格中數據在建模過程中的權重起著重要作用。

圖1 網格去叢聚權重估計方法
其權重系數:α=1/網格中井數據。
1.1.2 內核去叢聚方法
內核去叢聚方法是基于內核密度估計的一種統計去權重的方法。簡言之,通過在粗化地質網格卷積平滑的內核函數來估計每個地質網格的密度分布函數。這可以簡單地理解為應用內核函數和平滑參數到每一個粗化的地質網格,然后將多個內核函數相加得到其最終的密度分布函數(圖2)。去叢聚的權重為其局部密度函數的倒數。

圖2 內核去叢聚權重計算方法
在這種方法中,內核去叢聚的網格形態由I、J、K3個方向的平滑參數所決定,通過給予相應的網格數量來實現。內核去叢聚的網格形態決定了地質網格相加平滑的數量和方向,最終影響內核去叢聚的權重系數,如圖2所示。
其權重系數:α=1/內核密度分布。
不論是應用網格去叢聚方法,還是內核去叢聚方法,其最終目的是計算測井曲線粗化后井軌跡穿過的每個井網格的權重,然后根據其井軌跡穿過網格的測井曲線的平均值,來優化計算去叢聚后能夠更加符合真實地下儲層特征的沉積相比例或者儲層參數。
其最終去叢聚的平均值計算公式如下:
(1)

αi——井軌跡穿過每個網格的權重系數;
P(ci)——井軌跡穿過的每個網格的平均值。
1.2 水平井去叢聚的適用條件
應用水平井數據進行儲層精細表征去叢聚的過程中,由于去叢聚方法會改變原始數據的統計柱狀分布和其他統計學特征(例如平均值、方差等),如果數據不滿足去叢聚條件,盲目地使用會造成數據的錯誤。在進行數據采樣之前,重要的一步就是分析查看水平井數據是否會由于井斜的原因導致統計偏差,其分析的數據可以為沉積相、巖相等離散類數據,也可以為孔隙度、滲透率及飽和度等連續型數據。
首先需要評估沉積相分布比例是否會由于水平井輸入數據的采樣而導致統計偏差:
(1)確保對儲層沉積相或者沉積環境了解詳細,需要對全區不同沉積相的形態、維度和不同方向的連續性進行詳細定量描述。
(2)檢查水平井或者大斜度井是否穿過特定目的層的特定沉積相。這些可以影響數據是否會出現采樣偏差,如圖3所示。

圖3 水平井數據采樣沉積相分布比例偏差示意圖
(3)檢查原始沉積相測井曲線是否由于采樣而過度估計或者欠估計,并與實際沉積相的已知分布比例相對比。
如果確認水平井數據存在統計偏差,在應用去叢聚處理統計偏差之前,需要檢查以下條件是否滿足:
(1)是否有足夠的數據可以覆蓋目標屬性分布的整體值域分布。由于權重值只影響不同值域區間內的值,因此去叢聚方法只有當好的研究區和差的研究區都有足夠的水平井分布時才可以應用。
(2)沒有證據表明地質趨勢分布會導致數據的空間采樣偏差。如果地質趨勢分布導致數據分布出現偏差,則去叢聚方法不能校正此類偏差。在這種情況下,應當首先應用數據分析將原始數據中的趨勢進行去趨勢分析,再來查看是否會導致出現采樣偏差。
如果出現上述兩種情況,可以應用3D去叢聚方法來嘗試處理其采樣偏差,但不能保證其采樣偏差可以完全被校正。如果沒有明顯的證據可以顯示輸入數據存在采樣偏差,或者沒有足夠的數據可以覆蓋全區的數據分布,則在其處理過程中建議采取簡單的無權重的處理方法來處理其數據分布。
2 水平井油藏建模難點及質控分析
2.1 水平井油藏建模難點
在頁巖氣勘探開發或者油氣田開發后期,水平井的大量出現可以極大地提高目的儲層的油氣產量,使得水平井在油氣田勘探開發中起重要作用。但是在儲層精細描述過程中,由于水平井一般鉆遇目的儲層的特殊性,使得其大量數據在統計上的分布具有不穩態特征;且由于水平井一般針對特定儲層,其儲層沉積相及孔滲飽等儲層參數的統計往往會大大好于整個區域的實際儲層參數分布,從而使得儲層沉積相及孔滲飽分布出現過度良好的估計偏差。
在常規儲層建模過程中[12-14],一般以排除水平井數據、抽稀水平井數據或者采用其他間接方法來應用水平井數據進行儲層建模,這樣會大大降低水平井這類有用數據在儲層建模過程中的作用。而網格去叢聚方法由于受網格的方向和大小影響較大,一般對區域分布不均的直井數據的統計偏差處理效果較好,但對于斜井和水平井數據,由于其井軌跡在不同深度的差異性而導致處理結果并不理想。
在水平井地質建模過程中[15-16],應用Petrel數據分析中的三維內核去叢聚方法[17]直接對原始測井曲線采樣進行優化估計,既可以最大限度地應用已有水平井的數據分布,又可以良好地處理水平井數據在建模中的采樣偏差,從而提升水平井油藏建模的精度。
在應用3D內核去叢聚方法水平井油藏建模過程中,其難點主要包含以下幾點:
(1)水平井的分布是否足夠均勻,即在欠估計和過分估計的區域水平井的分布數量要足夠,過度的分布不均即使應用去叢聚,其與實際結果差別也會較大。
(2)對不同沉積相的分布或者屬性分布有較好的分析了解,以便了解哪些沉積相或者屬性是欠估計或過分估計。
(3)3D內核去叢聚密度函數的估計,以及I,J,K密度平滑參數的優化估計。
2.2 技術實現
在應用Petrel進行去叢聚過程中,其主要通過數據分析(Data Analysis)中的Declustering來實現,如圖4所示。在其應用過程中,通過估計調整I,J,K網格的大小來估計密度函數,生成的密度函數可以輸出來查看質控。在進行沉積相去叢聚過程中,選擇主要的沉積相類型,如果對應的沉積相采樣完成后為過分估計則選擇Minimize proportion,如果為欠估計則選擇Maximize proportion,然后再來進行估計。如果應用自動估計的I,J,K網格大小去叢聚的結果達不到要求,還可以選擇Specified來進行人為調整。
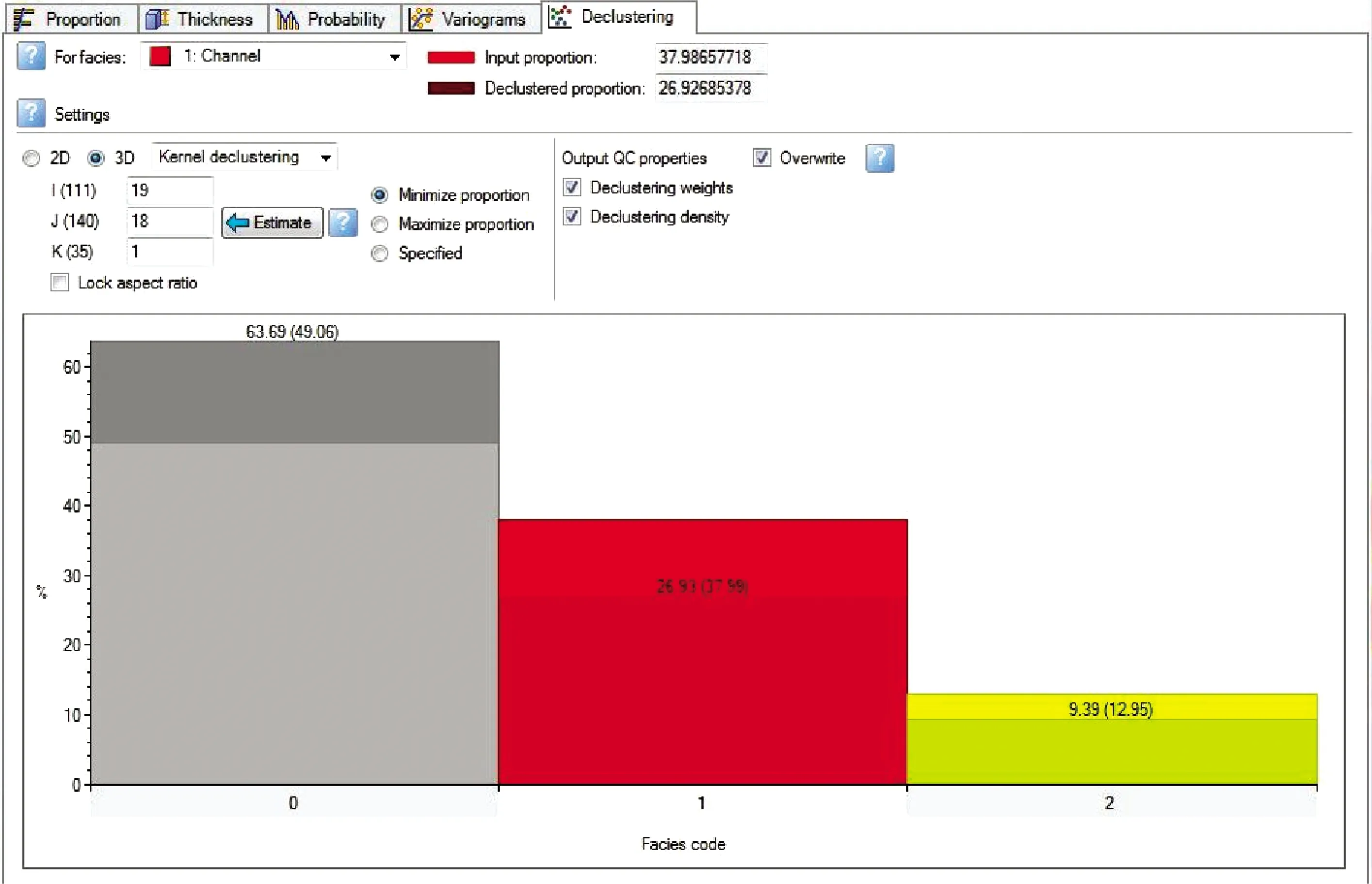
圖4 Petrel Declustering去叢聚設定
在應用Declustering去叢聚對水平井采樣數據進行優化去偏差之后,需要在沉積相模擬過程中應用去叢聚優化的沉積相分布比例作為研究區沉積相模擬的最終目標,這樣才會在沉積相建模過程中應用去叢聚的數據統計,進一步才能達到優化沉積相或屬性建模的結果。
2.3 質控分析
正如之前所說,應用去叢聚方法并不能100%保證能將由于優選采樣而導致的水平井采樣偏差完全去除,但是可以通過此種方法來優化建模的結果。因此,對于應用去叢聚儲層建模結果的質量控制就變得非常重要。
在質量控制過程中,需要將應用去叢聚優化之后的沉積相分布比例或者孔、滲、飽等連續型數據的分布,與之前已知的或者假定的沉積相或者連續型屬性分布比例來對比。分別對比應用去叢聚方法之前和之后的建模結果,并與實際估計的沉積相比例或連續型屬性對比,來最終確定是否需要應用去叢聚方法的統計結果來建模。
一般可以通過定性和定量兩種方法來對結果進行質量控制。
(1)定性質控:對比檢查應用去叢聚方法和不應用去叢聚方法建模結果的差異性,分別在三維窗口顯示、剖面顯示、連井地層對比,或者對某一沉積相、某一地層或者某一區塊來分別進行過濾對比顯示;此外還可以生成質量可信度圖(QA)屬性圖來對某一層或者某一層的每一個沉積相來進行質控。
(2)定量質控:分別對比應用去叢聚方法和不應用去叢聚方法沉積相比例的柱狀分布表、沉積相分布比例的統計數據,優選查看哪種結果更能與實際分析估計的結果相一致,則選擇哪種方法。
3 實例分析
由于地下實際沉積相的分布比例一般只有定性的分布類型與分布區域,而整體沉積相比例在區域上很少獲得精確的沉積相分布比例,因此,為了能夠更好地說明去叢聚方法對水平井數據統計偏差的處理,在此應用理論沉積相模型作為例子,來說明去叢聚方法處理水平井導致的統計偏差在沉積相建模中的作用。
首先在Petrel中做一個理論的河流相模型,此沉積相模型稱為Facies_origional(理論沉積相模型),在模型中不同的小層定義河道相和天然堤相兩個相,其各相的分布在不同小層不同區域分布不同,如圖5(左圖)所示。河道相和天然堤相在工區的西北部較為發育,其相的分布比例如圖5(右圖)所示,泥巖相占比為74.8%,河道相占比為15.7%,天然堤相占比為9.5%。

圖5 理論沉積相模型、井位分布及各相占比
在此模型中,井的分布、河道平面厚度分布如圖6(左圖)所示,全區共分布25口水平井,在工區的西部,河道相和天然堤相較為發育的區域,井分布較密,共有9口井。在理論模型的基礎上,從模型中生成沉積相測井曲線,并再次粗化到模型中去,應用數據分析功能分析粗化的沉積相曲線。由于井的平面分布不平均,在河道良好發育的西部共計10口井,導致其粗化的相數據出現很大偏差——泥巖的分布占比為49.0%,河道占比為38.0%,天然堤占比為13.0%,如圖6(右圖)所示。
從測井曲線粗化后各沉積相占比(圖6右圖)可以發現,由于平面上井在河道發育區分布較多,且水平井軌跡鉆遇層段主要為河道和天然堤較為發育的層段(圖7),導致其河道相和天然堤相被過分估計,分別由實際占比15.7%和9.5%被過分估計到分別占比38.0%和13.0%。這就是由于水平井的分布導致的數據統計偏差,去叢聚方法即是為了將這個偏差降到最小。在數據分析中應用3D Declustering方法對粗化的測井曲線進行處理,在粗化的數據中,需要將欠估計的泥巖、過估計的河道和天然堤應用三維內核去叢聚方法重新進行相比例估計。其應用去叢聚方法處理之后的結果見表1。

圖6 河道垂向累積厚度平面分布圖(左圖)及測井曲線粗化后沉積相占比(右圖)

圖7 水平井剖面鉆遇層段示意圖

表1 去叢聚處理前后與實際理論各相占比
通過去叢聚方法對統計偏差的處理,可以發現,處理后的泥巖相分布比例有了很大提高,由原來的49.0%提高到63.7%,而河道相分布比例降為26.9%,天然堤相分布比例降為9.4%。河道相分布比例與實際理論相分布比例還有差距,但相比較原始的38.0%已經有了很大提高;而天然堤相分布比例已經接近實際理論沉積相的分布比例。
應用去叢聚的數據統計結果和不應用去叢聚的統計結果,應用相同的建模地質參數分別進行基于目標的河流相建模以及基于像素的序貫指示模擬,在此分別生成10個模型來進行綜合統計,提取10個模型中各個網格出現最多的沉積相(Most of)作為最終相模型,對比其模擬結果的各相統計比例,從模擬的統計結果中可以發現,應用去叢聚方法模擬的各相比例與不應用去叢聚方法模擬的各相比例相比(圖8),其沉積相的分布比例更符合真實的理論沉積相分布,結果更加準確,對于勘探開發具有更符合實際的指導意義。

圖8 去叢聚方法與不應用去叢聚方法各相比例模擬結果對比
應用基于目標的河流相模擬方法進行沉積相模擬,比較去叢聚方法的模擬結果與不應用去叢聚方法的模擬結果(圖9)可以發現,由于去叢聚方法對過分估計的河道和天然堤進行了優化估計,應用去叢聚方法的河道和天然堤的分布比例更加符合真實的沉積相分布,其模擬結果中河道和天然堤的分布區域更小,多次模擬的結果統計更加符合實際沉積相的分布。而不應用去叢聚方法由于對河道和天然堤的過分估計,使得模擬結果分布比例過高,從而進一步影響全區橫向范圍和不同小層河道和天然堤的分布更廣。

圖9 不應用去叢聚方法與應用去叢聚方法沉積相目標模擬結果對比
4 結論
(1)網格去叢聚法(Cell Declustering)適用于由于直井平面分布不均所導致的沉積相及孔滲飽數據的統計偏差,其方法受去叢聚中網格大小和方向參數影響較大,且對大斜度井和水平井的處理效果較差。
(2)3D 內核去叢聚法(Kernel Declustering)應用內核密度分布函數,針對水平井及大斜度井三維油氣藏模型中的不同位置和深度的網格計算不同密度函數,生成相應的權重,并對儲層精細建模中的統計偏差進行優化再估計,可以大大提高建模中的沉積相與儲層參數分布。
(3)應用Petrel中的3D內核去叢聚方法,以理論河流沉積相模型為例,對比分析了應用與不應用水平井3D內核去叢聚方法對建模結果精度的影響。應用3D內核去叢聚方法可以優化提高水平井采樣數據沉積相統計結果的精度,使其更加符合真實沉積相的分布比例,河道相和天然堤相占比分別由38.0%和13.0%降低到26.9%和9.4%。
(4)對目標研究區沉積相及儲層參數分布的精細研究、水平井的分布是應用Declustering去叢聚處理水平井統計偏差的必要條件,只有在對目標區充分了解的基礎上才可以更好地應用去叢聚來處理水平井儲層建模中的統計偏差問題。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
