基于頻繁模式挖掘的風電爬坡事件統計特性建模及預測
2021-01-09 05:38:28屈尹鵬姜尚光孫元章柯德平
電力系統自動化 2021年1期
關鍵詞:模型
屈尹鵬,徐 箭,姜尚光,柳 玉,孫元章,柯德平
(1. 武漢大學電氣與自動化學院,湖北省武漢市430072;2. 國家電網公司華北分部,北京市100053)
0 引言
風電等高比例可再生能源發電的接入[1],對電力系統的輔助服務[2-3]提出了更高的要求。準確建立可再生能源爬坡事件的統計特性和預測模型,能更好地為輔助服務提供數據支撐[4-7]。
文獻[8]采用旋轉門算法分析了爬坡事件單屬性統計特性。文獻[9-10]采用L1 滑窗算法和動態規劃算法進行爬坡檢測,并建立了爬坡參數的二維統計特性模型。文獻[11]分析了不同季節下爬坡參數統計特性的差異。文獻[12]分析了風電原始數據特性對檢測到的爬坡事件單個參數統計特性的影響。文獻[13]將風電功率映射到頻域空間,建立了爬坡事件各個參數的時頻特性并進行分類。文獻[14]采用高斯混合模型擬合爬坡參數的一維概率分布。
風電爬坡預測可分為間接功率序列預測[15-16]和事件預測[17-18]兩大類。文獻[19]采用優化的旋轉門算法從大量風電功率預測場景中提取風電爬坡事件。文獻[20]使用風電功率序列多項式logit 結構和分類分布估計爬坡事件超出不同參數閾值的概率。文獻[21]利用風電功率的分位數生成功率場景,通過邏輯回歸來估計在特定時間間隔內風電爬坡發生的概率。文獻[22]建立了正交檢驗和支持向量機的混合預測模型,分析當前點發生爬坡事件的概率。文獻[23]使用Granger 因果檢測法,構建了基于多變量的支持向量機回歸預測模型,對下一次爬坡事件進行預測。文獻[24]對風電功率爬坡持續時間和爬坡幅值采用原子分解算法進行滑動分解得到原子分量和殘差分量進行預測,并采用線性回歸方法校正各個參數的誤差。
爬坡統計特性建模的基本現狀是:①對單個爬坡事件而言,多為單屬性或雙屬性的統計特性建模分析;②相鄰爬坡事件之間自相關統計特性模型研究較少。針對上述問題,本文提出了爬坡事件的多屬性聯合統計特性建模方法。基于該模型得到爬坡事件的基本模式,將風電功率序列降維為爬坡事件序列,對其進行頻繁項挖掘從而進一步建立多個相鄰爬坡事件之間的自相關統計特性模型。
現階段爬坡預測尚待解決的主要問題體現在:①基于事件的預測方法無法全方位充分利用爬坡事件的歷史信息;②日前爬坡預測往往通過對日前的風電功率預測數據進行爬坡檢測得到。但由于預測的點數較多、易造成爬坡預測誤差的累積和發散,從而造成爬坡事件的正確捕獲率的降低。針對上述問題,本文基于所提出的爬坡事件基本模式以及爬坡事件的自相關統計特性模型,設計了一種日前爬坡事件序列預測算法。以爬坡事件為預測點,通過自相關模型進行迭代,生成新的預測事件。相較于以風電功率為預測點的間接爬坡事件預測算法,其有效地減少了爬坡事件預測中的誤捕和漏捕現象。
1 爬坡事件多屬性統計特性建模
1.1 參數和分辨率自適應算法的爬坡事件檢測
文獻[12]提出了一種對參數和數據分辨率進行魯棒分析的爬坡檢測算法——參數和分辨率自適應算法(PRAA),其使用異常旋轉門算法[25]對原始數據進行壞數據處理和趨勢擬合,旋轉門的檢測公式為:

式中:Vc為當前被檢測點的信號幅值;Vo為起點的信號幅值;Vg為門點的信號幅值;tc為當前時刻;tg為門點的時刻;to為起始點的時刻;Vub為上邊界;Vlb為下邊界;ε 為旋轉門的門寬。
得到的旋轉門數據段代表了原始數據的趨勢,可以用來進行爬坡檢測。該爬坡檢測共分為如下2 個階段。
第1 階段用來合并相鄰的具有相同方向的旋轉門數據段。 給定一個風電旋轉門序列X ={(t1,p1),(t2,p2),…,(tm,pm),…,(tN,pN)},其 中,tm為時標,pm為該時標下的風電功率,N 為風電旋轉門數據段總數。 風電爬坡事件集合表示為EX={ E1,E2,…,Ed,…,EL},其中,Ed={ sd,ed},sd為第d 個爬坡事件的起點,ed為第d 個爬坡事件的終點,L 為該集合中總的爬坡事件數,則合并標準可寫為:

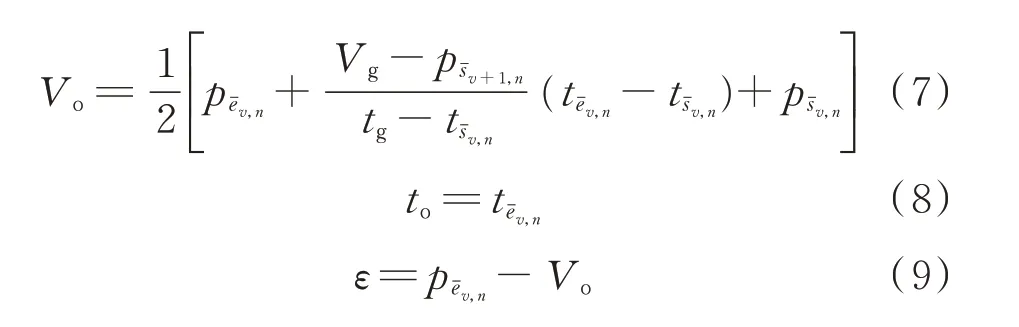
將式(5)—式(9)求出的等效旋轉門參數代入式(1)中進行檢測,若式(1)成立,則這2 個非有效爬坡事件屬于同一趨勢段,進行合并;否則屬于不同的趨勢段,繼續檢測下一對非有效爬坡事件。有關于PRAA 的詳細信息參見文獻[10]。
在本文中,有效爬坡事件的定義為:

式中:PGN為風電場的額定功率。
式(10)和式(11)表示,如果風電功率4 h 內向上爬坡20% 的額定功率或向下爬坡15% 的額定功率,則判定為發生一次有效爬坡事件。通過PRAA得到的所有有效爬坡事件集合和爬坡間隔將作為下一階段爬坡分類的輸入數據。
1.2 聯合統計特性檢測
爬坡事件具有3 個重要屬性:爬坡幅值、爬坡斜率和爬坡持續時間。通過對原始風電數據進行爬坡檢測,可以得到爬坡事件單個屬性的統計特性。在此基礎上,對爬坡事件集合進行多屬性聚類得到爬坡事件的多屬性統計特性模型。為了方便對風電功率時間序列進行事件重編碼,本文選擇爬坡起點、爬坡持續時間和爬坡終點作為爬坡事件的數據屬性。需要注意的是,這3 個屬性同樣包含了幅值和斜率信息。通過實驗發現,爬坡事件的聯合分布圖具有分布區域形狀復雜、分布密度具有伸縮性和延展性等特點。以中國某風電場一年實測數據中的向上爬坡事件為例,爬坡事件多屬性聯合分布圖如附錄A圖A1 所示。
附錄A 圖A1(a)中,紅色圓圈部分為高密度區域,綠色圓圈部分為中密度區域,剩余部分為低密度區域;圖A1(b)中,紅色三角形部分為高密度區域,綠色三角形部分為中密度區域,剩余部分為低密度區域。由于在一個聚類過程中需要不同的密度參數,而常見的密度算法[26]對輸入的參數極為敏感,因此不適用。又由于簇形狀的復雜性,使得圓形簇聚類算法如K-means 算法[27]也不適用。
針對上述難點,本文使用排序識別聚類結構(ordering points to identify clustering structure,OPTICS)算法[26]進行數據挖掘,通過輸出點的距離排序的方式聚類,因此能夠檢測到任意形狀的簇,并保持對輸入參數的魯棒性,適用于風電爬坡事件多屬性聯合統計特性檢測。OPTICS 算法的基本參數及原理見附錄A。
在進行聚類之前為了保證點距離不會被某一個數據屬性所淹沒,需要對所有數據點的屬性值進行標準化,即轉化到一個特定的數據區間內,如[-1,1]。為了防止噪聲點對標準化的影響,本文使用中位數和絕對標準差進行數據x 的標準化,即
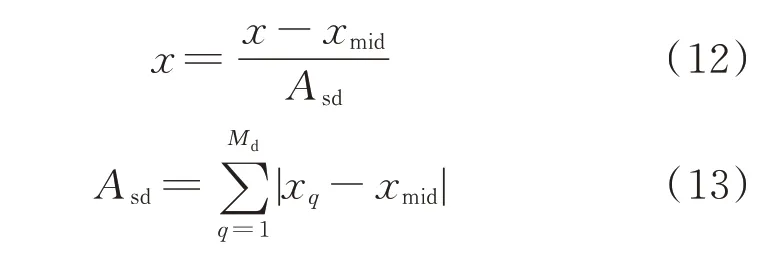
式中:Asd為絕對標準差;xmid為中位數;Md為對象的個數;xq為第q 個對象。
OPTICS 算法流程見附錄A 圖A3。不斷更新有序隊列(核心點及該核心點的直接密度可達點)和結果隊列(存儲樣本輸出及處理次序),直至數據庫為空。最后,OPTICS 算法輸出的結果隊列保證了距離近的點在一起,可根據簇排序決定最后實際的輸出聚類,從而檢測出爬坡事件的基本模式即多屬性聯合統計特性。
2 基于關聯規則算法的爬坡事件自相關性建模及預測
2.1 時序序列的事件編碼
基于功率時序序列的日前爬坡預測易造成誤捕和漏捕的很大一部分原因是預測的點數較多,誤差的累積和發散難以控制。因此,如何從功率序列中提取出有效信息和摒棄冗余信息來進行時序序列降維,對減少爬坡預測的預測點和提高事件捕獲率顯得尤為關鍵。
通過爬坡事件聚類所用的數據屬性(爬坡起點、爬坡終點、爬坡持續時間和爬坡間隔持續時間)能夠完整地表達時序序列中的爬坡信息。再者,使用爬坡事件和爬坡間隔進行聚類得到的爬坡模式完成對時序序列的重新編碼,如圖1 所示。時序序列{(t42,p42),(t43,p43)…,(t190,p190)}能夠重編碼為事件序列{A,B,C},其中,A,B,C 為爬坡事件聚類得到的爬坡模式(簇)。以模式A 數據段為例,數據段內的小幅波動信息對于爬坡事件來說為冗余信息,而紅色直線為爬坡事件,包含有效的爬坡信息(爬坡幅值、爬坡持續時間、爬坡起點、爬坡斜率等)。由于模式A 為爬坡聚類得到的基本模式(簇心),因此,若使用模式A 來代表該爬坡事件,會損失一定程度的爬坡信息,然而由于模式A 為聚類的簇心,因此損失的信息是有限的。同樣對模式B 和模式C 的數據段進行降維編碼之后,可將一個150 維的功率序列降維為一個3 維的事件序列。
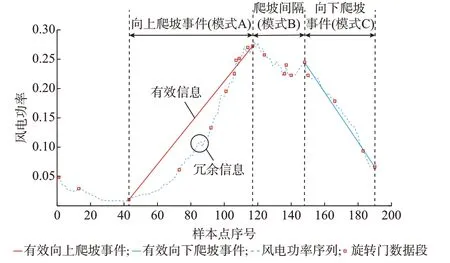
圖1 事件編碼圖Fig.1 Diagram of event encoding
2.2 關聯規則算法的關聯性分析
在風電功率預測中,風電功率的自相關特性往往被用來進行功率序列的預測。然而在爬坡預測模型中,由于缺少類似的風電爬坡事件的自相關統計特性模型,現階段基于事件的爬坡預測大部分集中于中短期的爬坡預測,因此在進行了功率序列的事件重編碼之后,進一步挖掘出爬坡事件的自相關特性,有助于爬坡事件序列預測模型的建模。
本文采用關聯規則挖掘算法——APRIORI 算法進行爬坡事件頻繁模式挖掘,建立爬坡事件的自相關統計特性模型。APRIORI 算法[26]的基本參數及原理見附錄B。
本文應用上述方法對2.1 節中的模式事件序列進行搜索。由于相隔較遠的爬坡事件相關性較小,只需考慮到頻繁四項集即可,即依次包含2 起爬坡事件和2 個爬坡間隔的頻繁項集。因此,從頻繁二項集到頻繁四項集包含了爬坡事件的自相關信息。例如,附錄B 圖B1 中,在模式A 發生之后,模式B 發生的概率如式(14)所示,其中(A,B)、(A,E)、(A,F)為所有包含模式A 的頻繁二項集,從而建立起模式A 和模式B 的自相關特性。
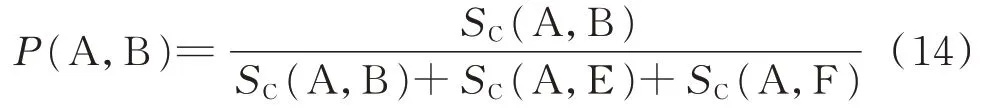
式中:SC(?)為支持度計數函數;E 和F 為爬坡模式。
2.3 基于事件序列的爬坡預測模型
為了展示爬坡事件的聯合屬性統計特性和自相關統計特性對于風電爬坡預測的數據支撐作用,本文研究了一種基于上述統計特性模型的爬坡事件序列預測的基本概念和模型。
本文采用功率事件對的形式交替進行預測。給定一個功率點事件對Fd={(td,pd),Rd},td為第d 個爬坡事件起點時刻,pd為第d 個爬坡事件起點的功率值,Rd=(Ud,Gd)為第d 個爬坡事件,其中,Ud為持續時間,Gd為爬坡幅值,若為爬坡間隔模式,則爬坡幅值為0。給定預測起始點前3 個爬坡模式為{MO1,MO2,MO3},頻繁二項集至頻繁四項集的支持度計數分別為SC2(?),SC3(?),SC4(?),括號內為相應的模式。將首個功率事件對的功率點設置為第3 個爬坡模式的終點,則首個爬坡事件的預測模型為:
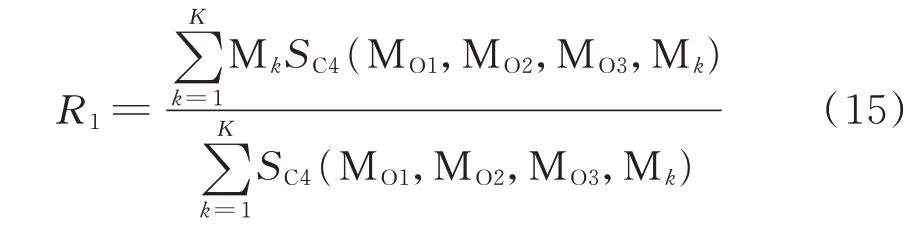
其中,K 為頻繁四項集中前 3 項為{MO1,MO2,MO3}的頻繁項的總個數,Mk為其中第k 個頻繁項的第4 個模式。需要注意的是,若K 為0,刪除MO1,在頻繁三項集中進行匹配,若仍然沒有匹配到相應的頻繁項,則在頻繁二項集中進行搜索。直至得到首個功率事件對F1={(t1,p1),R1},接著進行第2 個功率事件對功率點的預測,其預測模型為:
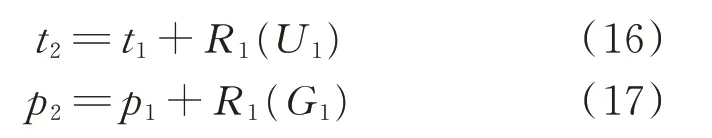
提取第1 個爬坡事件的起點、爬坡終點和爬坡持續時間,計算其與已有各個模式簇心的距離,將其歸為距離其簇心最近的模式,設為MOn,然后更新前3 個爬坡模式為:

在更新完已有模式之后,用式(15)進行第2 個爬坡事件的預測,用式(16)和式(17)進行第3 個功率事件對功率點的預測,重復該過程,交替預測功率事件對的功率點和爬坡事件并更新,直至完成一天的爬坡事件預測。式(15)—式(18)為爬坡事件序列預測模型,其流程圖見附錄C 圖C1。
從預測模型中可以發現,正是由于爬坡事件自相關模型的建立,才能夠通過式(15)由歷史爬坡事件序列推導出新的爬坡事件序列。且由于對功率序列進行了降維,減弱了預測誤差累積及發散,從而提高了爬坡事件的捕獲率。
整體算法的結構圖見附錄C 圖C2。爬坡檢測為所有算法的基礎,本文所使用的PRAA 能夠對不同數據源和數據屬性(如分辨率)的數據庫進行原始數據處理和爬坡檢測,得到的有效爬坡事件集合作為其他算法的輸入數據。對PRAA 得到的爬坡事件集合使用OPTICS 算法進行爬坡聚類,可以得到爬坡事件的多屬性統計特性建模,即基本爬坡事件模式。基于OPTICS 算法得到的基本爬坡模式,對風電功率序列進行事件重編碼,使用關聯規則算法對事件序列進行頻繁模式挖掘,即可以得到爬坡事件的自相關統計特性模型。所得到的單爬坡事件多屬性統計特性模型和爬坡事件自相關統計特性模型為輔助服務或爬坡預測等高級應用提供數據支撐。
3 算例分析
本文通過2 個實際風電場的原始數據集來驗證所提算法的有效性。第1 個數據集來自BPA(Bonneville Power Authority),包含2 年共184 032 個數據樣本,采樣時間間隔為200 s。該數據集主要用來展示所提的爬坡聚類方法并驗證其有效性。第2個數據集來自中國中部省份某風電場,共包含1 年6 個月的風電功率數據,采樣時間間隔為15 min,有58 477 個實測點和58 477 個預測點(來自某商用預測軟件)。該數據集主要用來驗證所提爬坡事件自相關統計特性建模方法并對比展示基于事件序列的爬坡預測效果。其中,1 年5 個月的數據用來做樣本學習集,剩余1 個月的數據用來驗證預測算法。
3.1 數據集1 算例
對BPA 的原始風電數據進行PRAA 爬坡檢測,共檢測到1 062 次有效爬坡事件,其中包括478 次上爬坡事件和584 次下爬坡事件。檢測到的上爬坡事件的二維屬性分布見附錄D 圖D1。從圖D1 中可以發現,小幅值、短時間的爬坡事件密度較高,而爬坡起點和終點的分布則相對而言較為均勻,呈現倒三角的形式。上爬坡事件的三維屬性(爬坡起點、爬坡終點和爬坡持續時間)的整體分布圖以及使用OPTICS 進行聚類得到的結果如圖2 所示。BPA 的上爬坡事件分類如表1 所示。

圖2 上爬坡事件聚類圖Fig.2 Cluster diagram of up-ramp events

表1 BPA 的上爬坡事件分類Table 1 Classification of up-ramp for BPA
對上爬坡事件聚類得到3 種模式,如表1 和圖2所示。其中,模式1 和模式2 均代表小幅值且短時間的爬坡事件,區別在于模式1 的爬坡起點較低而模式2 則表征高起點的爬坡事件,小幅值且短時間的上爬坡事件占所有上爬坡事件的86.4%。模式3代表大幅值、長持續時間且低起點的上爬坡事件,其占比為13.6%。
檢測到的下爬坡事件的二維屬性分布見附錄D圖D2,其整體分布特性與上爬坡事件分布特性類似。對下爬坡事件聚類得到4 種模式,見表D1 和圖D3。其中,模式5 代表小幅值、超短持續時間且高起點的爬坡事件,占比為35.96%;模式6 代表小幅值、短持續時間且低起點的爬坡事件,占比為40.07%;模式7 代表大幅值、超長持續時間且低起點的爬坡事件,占比為12.67%;模式8 代表大幅值、長持續時間且高起點的爬坡事件,占比為11.99%。
爬坡間隔由持續時間構成,對其進行聚類,可得到6 種模式,見附錄D 表D2。可以發現,短期的爬坡間隔占比較高。如4 h 內的爬坡間隔占比為73.43%。而長時間的爬坡間隔如9 h 以上的則占比較少,為26.57%。需要特別注意的是模式12,其爬坡間隔時長為0,說明發生了連續爬坡事件,如發生了上爬坡事件之后立刻發生下爬坡事件,該類事件所造成的爬坡間隔為0 的占比為22.6%。若該類爬坡間隔的占比較高,說明該地區的風電波動相當頻繁,否則說明該地區的風電相對平穩。因此,爬坡間隔為0 占整體爬坡間隔的比例能夠作為一個地區風電波動特性的體現。
至此,數據集1 的爬坡事件多屬性聯合統計特性檢測完成。在單屬性的統計特性的基礎上,多屬性統計特性模型進一步完善了爬坡事件統計特性建模,使得對于爬坡事件的描述更加直觀和完整,對風電爬坡預測能夠給予更好的數據支撐。
3.2 數據集2 算例
對數據集2 的實測數據學習集進行爬坡檢測并進行事件聚類,得到5 個上爬坡模式、5 個下爬坡模式和6 個爬坡間隔模式。如前所述,數據集2 主要用來驗證爬坡事件自相關統計特性模型,由于篇幅限制,其聚類結果不在此展示。
為便于事件編碼,將上爬坡模式編號為1~5,下爬坡模式編號為6~10,爬坡間隔模式編號為11~16。對重編碼之后的事件序列進行APRIORI算法關聯性分析,設定頻繁項閾值為10 個支持度計數。
如附錄D 圖D4 所示,共搜索到91 個頻繁二項、126 個頻繁三項和33 個頻繁四項。其中,頻繁二項集總的支持度計數和為4 534,頻繁三項集的支持度計數和為2 587,頻繁四項集的支持度計數和為537。圖3 和附錄D 圖D5 分別為頻繁四項集和頻繁三項集具有相同N -1 前綴項的示例。
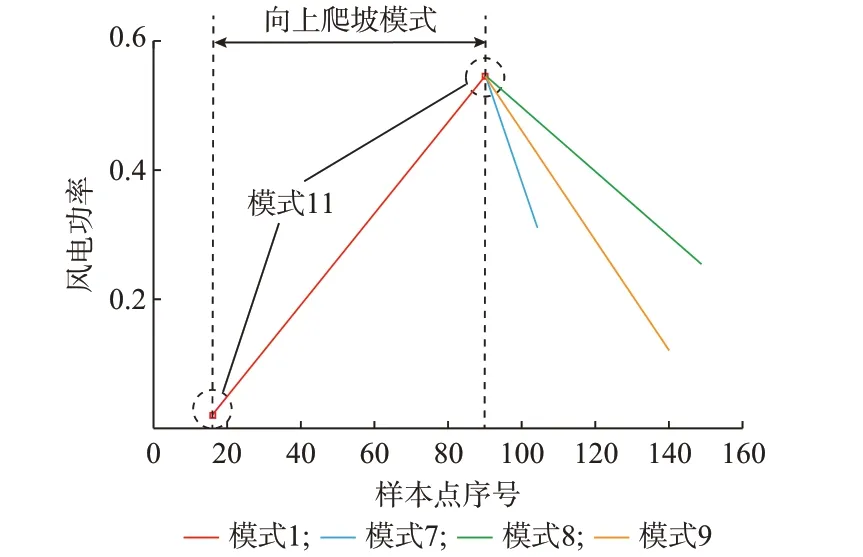
圖3 頻繁四項集自相關特性示例Fig.3 An example of autocorrelation characteristicin frequent four itemset
圖3 顯示前綴為11,1,11 的頻繁四項第4 項的概率圖。其中,模式11 為爬坡間隔模式,持續時間為0,模式1 為上爬坡模式。從圖中可以看出,當前面接連發生爬坡事件(間隔)的模式分別為11,1,11后,緊接著會發生一起下爬坡事件(模式7,8,9 均代表下爬坡事件)且模式8 下爬坡事件概率最大,為49%。模式7 和9 下爬坡事件的發生概率相近,分別為24%和27%。這樣就建立了模式11,1,11 和模式7,8,9 的自相關特性統計特性模型。但由于頻繁四項集內項數較少,在某些情況下可能匹配不到相同的前綴,此時需從頻繁三項集中進行搜索。
如附錄D 圖D5 所示,當發生了模式9 和11 的爬坡事件和爬坡間隔之后,接下來會發生一起上爬坡事件(模式1,2,3,4 均代表上爬坡事件),其中模式2和3 上爬坡事件的概率較大,分別為35%和33%,而發生模式1 和4 上爬坡事件的概率較小,分別為14%和17%。這樣就建立了模式9,11 和模式1,2,3,4 的自相關統計特性模型。同樣,若在頻繁三項集中匹配不到前綴,則繼續搜索頻繁二項集。因此,頻繁二項集、頻繁三項集和頻繁四項集表征了爬坡事件的自相關特性。
為了展示這種基于事件序列自相關特性的風電爬坡事件預測方法的效果,本文將其所得到的結果與基于風電場風電功率預測序列的爬坡檢測結果進行對比。
如附錄D 圖D6 所示,一個月的實際風電功率數據中共檢測到150 起有效風電爬坡事件,而風電功率預測數據中僅檢測到39 起爬坡事件,并且出現多次誤捕的現象。該預測軟件預測周期為24 h,預測數據分辨率為15 min,即一天產生96 個預測點。漏捕的主要原因是爬坡誤差在96 點預測過程中的不斷積累和發散。然而,本文所提的基于事件序列自相關特性的風電爬坡事件預測能夠預測到168 起爬坡事件,其中,誤捕27 次、漏捕9 次。圖4 展示了該月第一天的預測效果。日前捕獲率相較于基于功率序列的爬坡預測有了提高。這也體現了本文所研究的爬坡事件多屬性統計特性模型和爬坡事件自相關統計特性模型對于日前爬坡預測所提供的數據支撐的有效性。
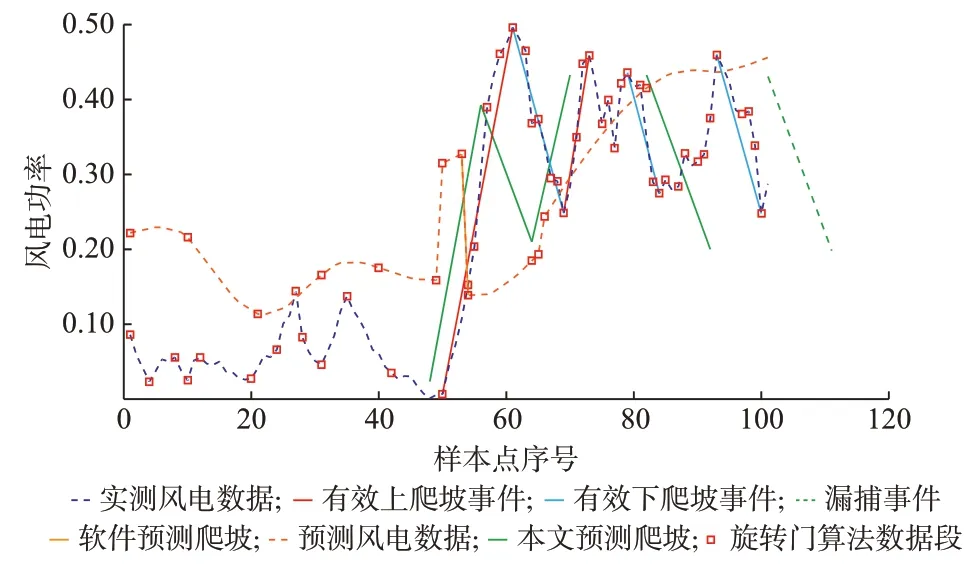
圖4 一天預測效果對比Fig.4 Comparision of forecasting results in one day
從圖4 中可以發現,雖然風電功率預測序列能夠大致在趨勢上擬合實際的風電功率序列,但由于其預測誤差會隨時間發散,無法起到爬坡預測的作用。相反的,若使用基于事件序列自相關特性的爬坡預測方法,雖然無法提供逐點的風電功率序列信息,但卻能夠在爬坡事件上做到相當高的捕獲率。從算例結果中發現,漏捕9 次的主要原因如圖4 綠色虛線所示,由于爬坡起點的預測誤差累積,導致一天之內最后一起預測爬坡事件起點距離預測起點超過24 h,因此沒有計入當日的預測事件中,從而出現漏捕事件。從上述算例中可以發現,僅依靠風電功率進行爬坡預測的精確性仍然有提高的空間。
4 結語
本文利用數據挖掘技術、設計了一套爬坡事件統計特性建模方法,主要包含以下幾個步驟:①PRAA 的原始風電數據爬坡檢測,得到歷史風電爬坡數據集;②OPTICS 算法爬坡聚類,得到單爬坡事件多屬性統計特性模型;③關聯規則算法頻繁模式挖掘,得到爬坡事件自相關統計特性模型。通過BPA 風電場數據和國內某風電場數據的對比驗證可以發現,所提算法的多屬性聯合統計特性模型相較于單屬性或雙屬性統計特性模型能夠更為完整且直觀地提供爬坡事件信息。所提出的爬坡事件自相關統計特性模型在以往僅提供單個爬坡事件的統計特性模型的基礎上,能夠進一步提供相鄰爬坡事件的相關特性。
在此基礎上,本文研究了基于上述模型的日前爬坡事件序列預測的基本概念和模型。實驗證明,相較于某商業軟件的基于風電功率序列的間接爬坡預測算法,本文所研究的方法在不包含誤差控制算法的前提下,能夠提供更高的爬坡事件捕獲率,將漏捕事件從功率事件序列預測算法中的111 次減少到了9 次,反映了本文所研究的爬坡事件統計特性模型對于爬坡預測算法的數據支撐作用。
本文所提預測模型僅包含了風電功率數據,在未來工作中,將通過引入數值天氣預報數據來抑制爬坡事件預測誤差的累積和發散,進一步提升爬坡事件預測算法的正確捕獲率,合理選擇預測時間窗,建立中長期的爬坡事件序列預測模型。
附錄見本刊網絡版(http://www.aeps-info.com/aeps/ch/index.aspx),掃英文摘要后二維碼可以閱讀網絡全文。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
