面向醫院網絡輿情分析的情感文本挖掘
2020-12-25 03:16:16楊雪寒焦瑋張倩孟潔
微型電腦應用 2020年12期
楊雪寒, 焦瑋, 張倩, 孟潔
(河北醫科大學第三醫院, 河北 石家莊 050051)
0 引言
互聯網中許多社交平臺和評論社區為公眾提供了大量自由表達意見的平臺,這導致與醫院相關的公眾意見或評論的數據集十分龐大,通過研究這些公眾意見,可以分析公眾對醫患關系、醫療事故爭議等與醫院相關事件的主觀態度和情感取向,從而為取得輿論導向主動權提供科學的數據支撐[1-3]。因此,開展針對醫院輿論的文本挖掘和情感分析具有重要的現實意義。為此,本文提出了附加特征、奇異值分解(SVD)[4]和主成分分析(PCA)[5]的情感文本挖掘方法,實現提高分析準確性并減少文本挖掘的時間,并基于詞干設計了五個具有不同功能的模塊實驗,以比較性能并探索哪些因素會影響性能分類精度。本研究的目標如下:1)提出一種基于附加特征方法的情感文本挖掘方法,以提高情感評論大數據分析的分類準確性;2)提出一種特征提取算法,以提高情感分類的準確性;3)利用有效的SVD和PCA文本挖掘方法來減少數據維數,提高情感分類效率。
1 情感文本挖掘方法
情感分類的目標是將文檔、文本或評論分類為已標記的情感類別(例如正面、負面、快樂、悲傷等)。情感分類中最具挑戰性的工作是如何提高分類結果的準確性。許多因素會影響分析,例如不同的數據預處理方法、情感分類(文檔或句子)的級別、所提取各種文本特征、特征詞典以及不同的機器學習方法。已有研究表明不同的特征選擇方法,例如詞語組合、雙字、詞性(POS)標記[6]、帶有POS標記的n-gram序列[7]和詞語頻率-反向文檔頻率(TF-IDF)[8]等,會導致情感分類結果的不同。為此,本文將實驗擴展到其他特征上以提高準確性,并結合SVD和PCA方法來減小特征維度、縮短文本分類的時間。此外,本研究利用詞干設計了五個具有不同功能的模塊實驗,以比較其性能并發現影響分類器準確性的因素。
本研究所提出的情感文本挖掘方法的過程,如圖1所示。
首先,將收集的數據集用于情感分類;然后,采用R統計的標記化,去除的停用詞和POS標記的預處理步驟;隨后,定義和提取特征,包括TF-IDF、每個文檔的情感分數、正負頻率以及形容詞和副詞的數量,之后,應用分類算法訓練和預測數據;最后,評估分類結果。

圖1 情感文本分類方法
下面結合所收集的數據集對上述方法中五個主要步驟展開闡述以展示該方法的詳細過程。
步驟1,數據集收集。所搜集的一個數據集是基于使用Python程序從微博平臺中所爬取的數據組成了針對疫苗的用戶評論數據集。該數據集由WEB文檔組成,包括1 000條正面評論和1 000條負面評論。本研究使用Excel VBA(Microsoft)程序對所爬取的WEB文檔進行導入處理,形成帶有標簽的Excel格式的情感文檔。
步驟2,數據預處理。通常從網絡收集的數據包含噪聲。在實施各種機器學習方法之前,始終需要通過以下五個步驟來處理所收集的數據:標記化、停用詞刪除、詞干與詞性標記(POS標記)、特征提取和表現[9-10]。標記化的目的是刪除文本中的標點符號。這些標記對分類算法的準確性沒有幫助。停用詞是在文章中經常使用的詞,即“在”、“也”、“的”、“它”、“為”等。這些詞會降低分類結果的準確性。詞干將單詞還原為詞根形式,而忽略單詞的POS。POS標記是用于識別文本中單個文字的詞性不同部分的過程。由于爬取數據經常涉及噪聲,因此需要進行特征提取以幫助獲得相關信息。此步驟使用了兩個稱為RTextTools和openNLP的R語言包來處理POS[11]。特征提取將在下面詳細討論。除了特征提取之外,特征選擇也是影響分析結果重要的一步。

表1 特征說明
此步驟將所有文檔轉換為TF-IDF矩陣權重,同時讓正負頻率形成另一個特征集。接下來,利用POS標記對形容詞和副詞的數量進行計數,并添加附加特征。TF-IDF參數,如表2所示。特征提取算法,如表3所示。
步驟4,縮減TF-IDF矩陣維度。由于TF-IDF矩陣是具有許多零元素的大型稀疏矩陣,因此分析該矩陣需要耗費大量計算時間。因此,本研究采用SVD和PCA相結合的方法縮減矩陣維度。特征提取后,將預處理的矩陣用作SVD輸入。將SVD技術用于分解TF-IDF矩陣,使得接近零的值轉

表2 TF-IDF算法參數說明

表3 特征提取算法
換為零。然后,應用PCA技術處理縮小后的矩陣,以進一步縮小矩陣維度。PCA的輸出,如表4所示。

表4 PCA降維算法的輸出
以本研究從微博等社交平臺所收集的疫苗評論數據集為例,經過降維處理后,TF-IDF矩陣維度從2 000×46 467縮減至2 000×2 000。
步驟5,應用四個分類算法訓練處理后的數據集以實現對文本的分類,對數據集進行分類。所使用的四個分類算法包括樸素貝葉斯分類算法(NB)[12]、最大熵分類算法(ME)[13]、SVM[14]和隨機森林(RF)[15]分類算法。在本研究中,四個分類器的所有參數設置為默認值,并使用10次隨機采樣和10倍交叉驗證來驗證準確性。詳細說明和參數設置,如表5所示。
步驟6,準確度評估分類算法的性能。使用分類混淆矩陣計算準確度,如表6所示。
以對帶有正負標簽的文檔級情感進行分類。因為本研究所涉及的實驗數據集具有明顯的正面和負面情緒評論,所以本研究基于混淆矩陣使用來計算分類結果的準確度,如式(1)。

(1)
2 實驗驗證
基于提出的算法,本研究收集了針對疫苗的公眾評論數據集,并利用不同的實驗模塊進行了實驗,并將結果與列表方法進行了比較。數據集從微博等社交平臺收集的評論文本。實驗數據集的詳細屬性,如表7所示。
對醫院來說,人才是立院之本、發展之基。齊魯醫院副院長陳玉國表示,通過三年住培,培養出了基本功扎實、達到主治醫師水平的臨床醫師,為醫院提供了真正“好用”的臨床醫師,縮短了用人單位與醫師的“磨合期”,充實與壯大了醫院醫療力量,為醫院的人才梯隊建設和學科發展提供了優良儲備,也為醫療服務質量提供了根本和長遠保障。“作為承擔住培任務的基地醫院,教學相長使其保有優良的教學氛圍,提升醫院帶教醫師的能力水平,獲得可持續發展、追求卓越的強勁動力。”
2.1 數據集特征
基于TF-IDF的不同參數設置和是否進行詞干提取,設計了五個實驗模塊,并采用列表方法對實驗結果進行比較,討論了哪些因素會影響分類算法的準確性,如表8所示。

表5 分類算法的參數設置
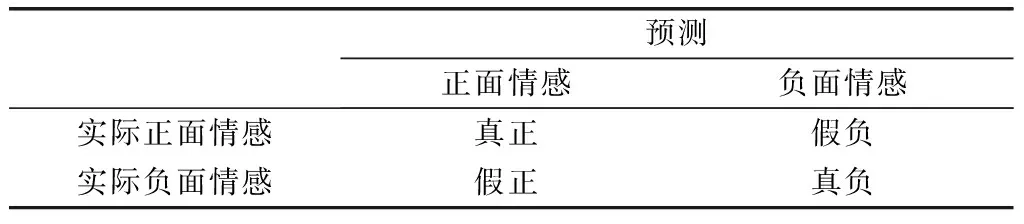
表6 情感分類的混淆矩陣

表7 實驗數據集的屬性

表8 實驗模塊
實驗在提出的算法的第2步和第3步之后,從特征集中一共提取了46 467個特征。為了測試不同設置的效果,將SVD和 PCA相結合方法與列出的方法進行比較。實驗采用十次隨機采樣和十倍交叉測試方法以驗證算法性能,如表9、表10所示。

表9 不降維的實驗結果

表10 降維的實驗結果
如表9顯示,就五個分類算法的平均準確性而言,所建議的具有附加特征的方法要比不具有附加特征的方法更好。在準確性方面,SVM和最大熵分類算法優于其他分類算法。表10顯示了在沒有詞干的情況下,模塊1和模塊4在縮小和不縮小矩陣大小之間的比較結果。總體而言,在帶有和不帶有矩陣大小縮減的情況,所提出的具有附加特征的方法要比沒有附加特征的方法性能更好。在大多數設置中,SVM和最大熵分類算法更為準確。
5個分類算法的總實現時間,在五個模塊中,除了模塊5以外,4個模塊可以減少運行時間。因此,為該方法中添加附加特征和矩陣降維是可行的,如表11所示。

表11 五個分類算法的運行時間
基于上述實驗結果可以發現。
1) 從表9可以看出,在特征提取方面,所提出的方法在模塊1和模塊4上表現最優。模塊4在所有實驗中均獲得最高的準確度,并且特征數量減少到9.4%(4 366/46 467否)。表11的數據表明,在本實驗中的詞干特征的分類效果不明顯。
2) 從表9和圖2可以看出,將附加特征組合到特征集中后,可以提高分類性能,尤其是使用帶有徑向基函數的SVM算法時。
3) 從表10可以看出,采用附加特征和SVD、PCA相結合的矩陣降維方法可以增強情感分類的性能。此外基于表11的數據可知,采用附加特征和SVD、PCA相結合的矩陣降維方法后算法的運行效率較好,因此該方法具有良好的可行性,如圖2所示。

圖2 附加特征對不同模塊的影響
3 總結
隨著互聯網在全球范圍內的普及,互聯網人口覆蓋率越來越高,互聯網已經成為人們生活,工作和學習的不可或缺的組成部分。因此通過對網絡評論進行情感分析,把握公眾對醫院焦點事件的心里態度和行動趨勢,對醫院相關部門了解輿論動態和政府相關部門控制輿論導向都具有現實意義。為此本研究提出了一種通過附加特征方法來提高網絡文本情感趨向分類準確性,并采用SVD和PCA結合的方法則縮短情感文本挖掘中的實現時間。附加特征包括正面和負面形容詞和副詞的頻率。針對兩個實驗數據集的測試結果表明,所提出的方法比其他方法具有更高的精度,并且添加附加特征可以提高分類精度。此外,實驗數據表明,相對于本實驗中的其他算法,SVM和最大熵分類算法被證明是實現情感文本分類的更好選擇。將來,本研究從以下兩個方面繼續進行深入探討:1)從使用特定于領域的詞典來查找或過濾特征、為特征分配不同的權重、考慮文字和文檔之間的關系三個方面優化特征選擇,以提高分類準確性;2)將該方法應用于醫院聲譽監控和患者情感檢測等不同的應用領域。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
