基于改進密度聚類與SVM的非法廣播信號識別研究
2020-12-26 08:22:32王朝衛
微型電腦應用 2020年12期
王朝衛
(青海省廣播電視局 青海中波臺管理中心, 青海 西寧 810001)
0 引言
非法廣播俗稱“黑廣播”,不僅形式多樣,而且占用頻率,在缺少有效的信號識別技術的情況下,非法組織者采取改變發射位置或者頻繁切換頻率的手段來躲避追索,這給無線電行業的有序發展造成嚴重危害[1]。這種危害的表征,具體體現在以下幾點:其一,非法廣播信號具有欺騙性,嚴重擾亂公共秩序;其二,選用低劣的違法發射機對外發射無線信號,會對正常通信信號造成干擾。針對于此,必須引用先進的信號識別技術對非法廣播信號進行識別和追蹤,從而遏制非法廣播的肆意發展,達到無線電行業擁有正常秩序的目的。雖我國對識別非法廣播信號的文獻較少,但研究成果頗為豐富,已形成了一套完整的識別體系。。如杜利敏(2014)[2]利用聚類算法與ReliefF算法相結合的方法對無線點信號的特征進行提取;張自豪(2015)[3]為了對地空通信信號進行識別,運用結合了聚類算法與SVM算法的識別方法,這一策略不僅能夠達到信號識別的效果,而且可以有效規避外部信號的干擾;杜利敏(2017)[4]、Xuezhi He(2018)[5]、何學智(2018)[6]等學者在模式識別領域引入深度學習算法,實現了對各種無線電信號特征的準確提取;孫潔(2018)[7]構建了以狼群搜索算法為基礎的信號特征識別方法,相較于傳統算法表現出更高地識別率。同時研究發現在中頻測量數據中包含許多的孤立點及噪聲,使得對中頻信號的分類識別變得復雜,如采用傳統的單一SVM進行分類識別,難以達成理想效果。因此本研究嘗試在進行SVM分類識別前,結合中頻信號數據的多維特征,引入改進密度聚類對數據進行處理,以減少數據的維度。最后利用SVM算法對無線電信號進行識別并分類,為識別非法廣播信號提供了新途徑。
1 SVM分類原理
假設SVM分類器的訓練樣本為{(xi,yi)},i=1,2,…,N,xi∈Rd式子中的xi含有d個不相同的特征,yi={-1,+1},將非松弛變量ξi引入公式,i=1,2,…,N。為了實現不同類型樣本的分離來達到分類的效果,需要通過尋找最優超平面來實現,具體數學描述[8-12],如式(1)、式(2)。
(1)
s.t.yi=(ωTxi+b)≥1-ξi,i=1,2,…,N
(2)
式中,C指的是懲罰因子,它可以平衡分類邊界大小。
(3)
運用K(Xi,Yi)將核函數的樣本映射到高維空間,從而實現將兩類非線性問題轉化為一個線性分類問題的目的。
分類決策函數,如式(4)。
f(x)=sgn(∑yiαi*K(X,Xi)+b*)
(4)
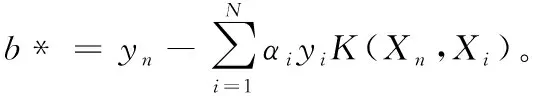
2 密度聚類改進
2.1 密度聚類簡介
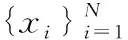
(5)
式中,dc指的是截斷距離,ρi可通過高斯核函數進行求解。根據上式,隨著ρi值的增大,與xi的間距在dc以內的數據增多,反之則數據越少。
通過求解點i與其他高密度點的最小距離,從而推算出δi值,如式(6)。
(6)
從上述式子中可以看出,數據點xi為最大局部密度時,δi代表數據集S中xi與距離xi最大點的間距;反之,δi代表在局部密度大于xi的點內,xi與距離xi最小點的間距。
密度聚類算法的實現過程分如下三步。
1、運用樣本數據計算歐式距離dij和截斷距離dc;
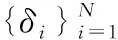
3、確立聚類中心并輸出結果。
2.2 密度聚類算法的改進
聚類算法實現分類有三個環節,分別為提取特征、計算相似度和確立聚類中心。在過去,人們通過歐式定理計算相似度,如式(7)。
(7)
能夠對任意的數據樣本xi與xj的空間距離進行計算,但在測量出的調頻信號數據不難發現,在整體樣本中不同樣本的分布具有差異性,那么其對距離產生的影響也隨之發生改變。由此可見,給予不同分布比例的樣本權重,對提高計算歐式距離準確性有積極作用。
基于此,對式(7)進行改進,如式(8)。
(8)
3 中頻測量信號特征提取
中頻測量,又名單頻測量,即依據對單一信號點進行監測后得到的監測結果判斷信號的頻譜信號正常與否。具體操作過程為:第一步,檢測人員向監測設備發出數據監測請求;第二步,對指定信號進行監測;第三步,運用頻譜圖展示中頻信號參數的特征(例如頻率的寬帶和頻偏)。87.5-108 MHz頻段的光譜測量圖,深色區域表示在此頻段下的信號強度大,如圖1所示。
為了避免采樣信號中產生冗余數據,從連續采樣的x廣播信號中選取N個不同采樣點。從這N個采樣點中采集到的廣播信號十分復雜,選用傳統算法(比如去噪)進行信號預處理,需要占用較長時間。對此,本文通過提取關鍵特征的做法進行信號預處理,極大縮減了計算量。結合裴崢教授的研究成果,選擇以下關鍵特征[5]。
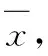
(9)
方差Var,如式(10)。
(10)
(11)
峭度K,如式(12)。
(12)
歸一化峰度Peak,如式(13)。
(13)
零中心歸一化絕對值標準差De,如式(14)。
(14)

4 結合改進密度聚類的中頻信號識別模型構建
根據中頻測量數據提取不同頻率信號的關鍵特征,通過加權方式確定不同樣本的權重,引用歐氏定律計算距離,據此確定聚類中心,并建立起完成聚類的訓練樣本。上述處理方法在極大程度上減少了訓練樣本數量,消除了冗余數據對信號的干擾。運用SVM分類器將聚類后的數據樣本分類歸納為非法廣播信號和正常廣播信號。
中頻測量信號識別模型,如圖2所示。

圖2 非法廣播異常信號識別模型
以上模型是由3個部分構成的,分別是信號樣本聚類、SVM訓練和SVM分類器。在完成信號樣本聚類以后,根據計算出的ρi、δi值,建立起正常信號與非法信號的特征集合V1,如式(15)。
(15)
為了方便后續的分類識別,輸入樣本使用式(15)中的特殊參數。
5 仿真實驗
5.1 數據準備
選定某省廣播電視局中波臺管理中心的中頻數據監測項目作為案例,對前文闡述的思路方法進行驗證。在實際操作過程中,為了保證某省廣播電視臺正常的參數監測環境,包含信號的強度、帶寬以及頻率等等,需要運用相應的監測軟件對發出的中頻信號進行整點掃描,并將其結果保存于系統數據庫內,從中篩選數據并建立訓練樣本。選用密度聚類效果、非法廣播信號識別準確率和分類訓練效率等指標對上述模型的優劣進行評價。在穩定的信噪比(S/N)下對該試驗進行驗證,并選擇200 kHz帶寬的R&S. EM100設備,并返回電平值。另外,出于保密要求,本次實驗對部分廣播信號數據進行了適當處理。
5.2 參數設置
所選擇的300幀信號數據中包含了正常廣播信號和非法廣播信號,從中提取出六個關鍵性特征,并構建300*6的六維特征空間。假設聚類密度閾值為ρ=0.5;SVM核函數采用徑向函數,并運用交叉驗證和網格搜索的方法訓練各項參數,確定C=10 000,σ=0.05。
5.3 實驗結果
5.3.1 正常廣播信號聚類結果與頻譜圖
由R&S. EM100設備監測獲得連續300幀信號數據,采用密度聚類算法,所得靜音信號聚類結果,如圖3所示。

圖3 密度聚類結果
上圖中的綠點和紅點均為聚類中心,據此對信號數據進行重新分配,如圖4所示。
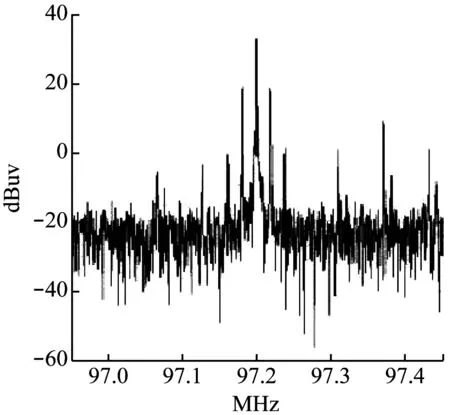
圖4 靜音信號頻譜圖
5.3.2 非法廣播信號的聚類結果以及頻譜圖
在特定時間段采集300幀非法廣播信號,并利用密度聚類算法進行處理,所得該非法廣播信號的聚類結果,如圖5所示。

圖5 非法廣播信號聚類圖
在正常廣播信號中加入非法廣播信號,所得頻譜圖展示,如圖6所示。
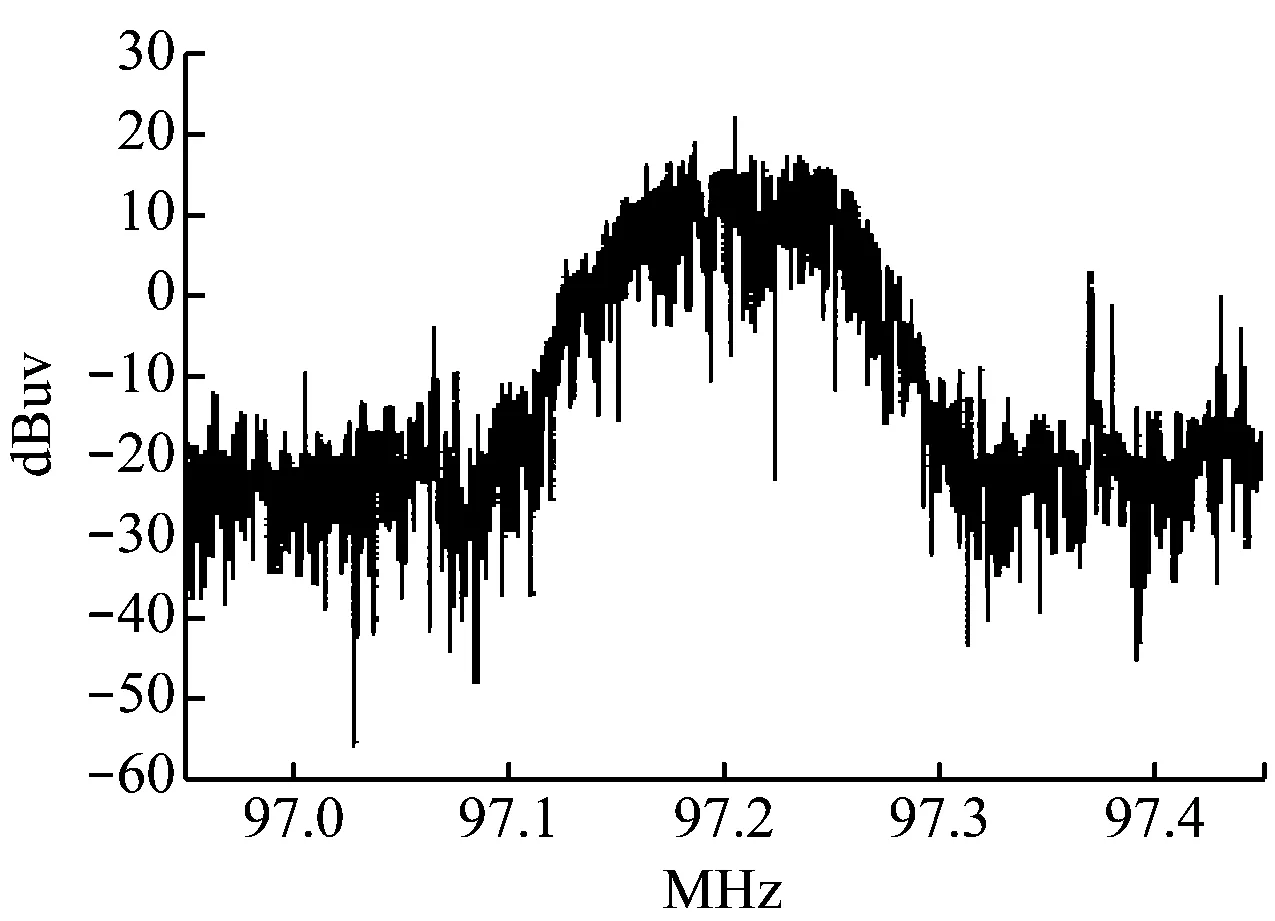
圖6 加入非法廣播信號后的頻譜圖
分析可知,在正常廣播信號中加入非法廣播信號,頻譜圖中的靜音信號大為減少。基于這一規律,可以根據頻譜圖中的靜音信號對非法廣播信號進行識別。
5.3.3 分類結果
針對聚類后的樣本,對比分析SVM、K-均值聚類+SVM、密度聚類+SVM的分類結果,從而證實本文算法的優越性。在本次實驗中保持相關參量不變,實驗結果,如表1所示。

表1 分類結果對比
可見,與SVM、K-均值聚類+SVM等算法作對比,本文提出的改進密度聚類+SVM算法在信號識別的正確率和訓練時間等方面都具有顯著優勢。
6 總結
經過對傳統DBSCAN聚類樣本縮減的了解和分析,本文為了減小采集樣本的數量,運用了引入聚類算法,因而提升SVM的分類訓練效率和準確率。正常廣播段會受到中頻非法廣播段影響,致使正常廣播頻率中的靜音信號變少,為了徹底根除“黑廣播”這一頑疾,本文提出的改進密度聚類+SVM算法,能夠準確、高效地識別非法廣播信號,從而維持無線電行業的正常秩序。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年11期)2018-08-04 03:25:42
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
