一種基于深度學(xué)習(xí)的無(wú)人機(jī)識(shí)別方法
2020-12-25 02:09:28黃湘鵬黃曉剛
雷達(dá)與對(duì)抗 2020年2期
關(guān)鍵詞:分類
黃湘鵬,黃曉剛
(海軍裝備部駐南京地區(qū)第四軍事代表室,南京 211106)
0 引 言
在過(guò)去幾年中,小型無(wú)人駕駛飛機(jī)的普及迅速發(fā)展,并且有望進(jìn)一步增加。小型無(wú)人機(jī)在軍事領(lǐng)域和民用領(lǐng)域都得到越來(lái)越廣泛的應(yīng)用,例如獲得重要事件的電視錄像或在危險(xiǎn)地區(qū)提供急救支持。無(wú)人機(jī)在給人們生活帶來(lái)便利的同時(shí)也對(duì)個(gè)人隱私、社會(huì)安全、軍事安全等領(lǐng)域構(gòu)成了嚴(yán)重威脅。[1-2]如何更快、更精確地實(shí)現(xiàn)無(wú)人機(jī)的檢測(cè)和識(shí)別是無(wú)人機(jī)反制的前提,但小型無(wú)人機(jī)由于飛行速度較慢、飛行高度較低等原因很難被檢測(cè)到。此外,飛鳥(niǎo)可能會(huì)導(dǎo)致無(wú)人機(jī)檢測(cè)系統(tǒng)出現(xiàn)很多的虛警。因此,不僅必須及時(shí)檢測(cè)進(jìn)來(lái)的無(wú)人機(jī),而且要將其歸類為可疑的、具有潛在危險(xiǎn)的人造目標(biāo)。
一般來(lái)說(shuō),小型無(wú)人機(jī)的檢測(cè)和識(shí)別可以使用不同的傳感器執(zhí)行,例如聲學(xué)傳感器、高分辨率紅外傳感器、光學(xué)傳感器和雷達(dá)等。通常,通過(guò)聲傳感器進(jìn)行的檢測(cè)很不可靠,因?yàn)樾⌒蜔o(wú)人機(jī)相對(duì)安靜,并且在城市中環(huán)境噪聲水平一般較高。利用光學(xué)圖像實(shí)現(xiàn)無(wú)人機(jī)檢測(cè)和識(shí)別是一種常用手段。隨著機(jī)器學(xué)習(xí)及深度學(xué)習(xí)技術(shù)的發(fā)展,越來(lái)越多的研究者選擇構(gòu)建深度學(xué)習(xí)網(wǎng)絡(luò)實(shí)現(xiàn)無(wú)人機(jī)分類,在有足夠訓(xùn)練資源的情況下可以達(dá)到較好的性能。[3]高分辨紅外傳感器能夠在一定距離檢測(cè)無(wú)人機(jī),檢測(cè)后可以通過(guò)放大目標(biāo)區(qū)域以獲得支持分類的詳細(xì)圖像。但是,紅外傳感器無(wú)法提供目標(biāo)的速度和范圍,既不適合大區(qū)域搜索也不適合霧天等惡劣天氣條件下運(yùn)行,而這些卻是雷達(dá)的強(qiáng)項(xiàng)。國(guó)外有些研究者使用高重頻雷達(dá)獲取目標(biāo)微多普勒特征,實(shí)現(xiàn)無(wú)人機(jī)分類。[4-6]本文聚焦于無(wú)人機(jī)與飛鳥(niǎo)的分類識(shí)別,提出一種基于深度學(xué)習(xí)的無(wú)人機(jī)識(shí)別方法。主要工作有:(1)構(gòu)建深度學(xué)習(xí)網(wǎng)絡(luò),利用深度學(xué)習(xí)網(wǎng)絡(luò)強(qiáng)大的學(xué)習(xí)能力,對(duì)目標(biāo)RCS序列進(jìn)行特征學(xué)習(xí),獲得特征向量后使用邏輯回歸進(jìn)行分類;(2)針對(duì)無(wú)人機(jī)數(shù)據(jù)遠(yuǎn)少于飛鳥(niǎo)數(shù)據(jù)量的問(wèn)題,基于SMOTE(Synthetic Minority Over-sampling Technique)算法提出聚類SMOTE算法,一定程度上緩解了數(shù)據(jù)不平衡問(wèn)題。通過(guò)實(shí)測(cè)數(shù)據(jù)驗(yàn)證,本文方法具有良好的分類性能,在無(wú)人機(jī)識(shí)別正確率達(dá)到87%的同時(shí)過(guò)濾掉60%的飛鳥(niǎo)目標(biāo)。
1 處理流程
圖1為無(wú)人機(jī)識(shí)別流程。首先由雷達(dá)回波提取目標(biāo)RCS序列,訓(xùn)練集和測(cè)試集數(shù)據(jù)獨(dú)立采集,可驗(yàn)證方法的有效性;然后對(duì)訓(xùn)練集和測(cè)試集數(shù)據(jù)分別進(jìn)行預(yù)處理,本文采用均值方差歸一化,測(cè)試集使用訓(xùn)練集的均值方差進(jìn)行歸一化;訓(xùn)練集數(shù)據(jù)由于存在數(shù)據(jù)不平衡的問(wèn)題,使用聚類SMOTE算法插值平衡;使用平衡后的訓(xùn)練集訓(xùn)練深度學(xué)習(xí)網(wǎng)絡(luò),使用測(cè)試集驗(yàn)證訓(xùn)練好的深度神經(jīng)網(wǎng)絡(luò)。
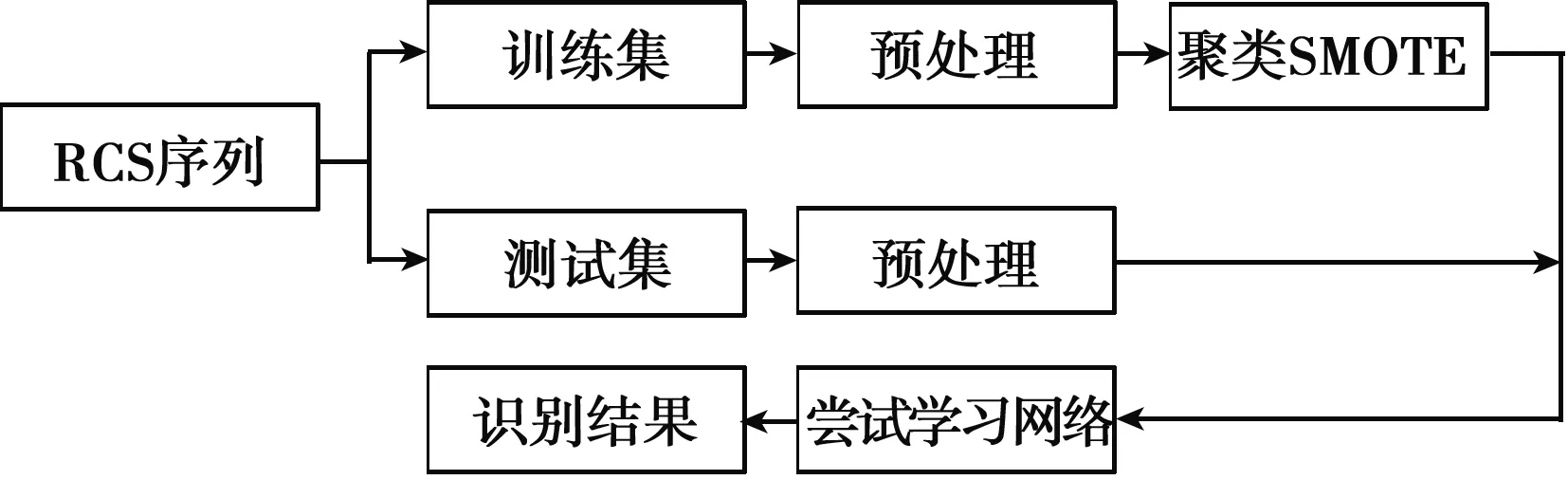
圖1 無(wú)人機(jī)識(shí)別流程
2 深度學(xué)習(xí)網(wǎng)絡(luò)
2.1 網(wǎng)絡(luò)結(jié)構(gòu)
本文的深度學(xué)習(xí)網(wǎng)絡(luò)使用卷積神經(jīng)網(wǎng)絡(luò)搭建,有1個(gè)輸入層、兩個(gè)卷積層加池化層、1個(gè)全連接層和1個(gè)輸出層。卷積核大小為3*1。卷積層及全連接層激活函數(shù)均為ReLU函數(shù)。第2層卷積層及全連接層接dropout,隨機(jī)失活一半的神經(jīng)元,以緩解過(guò)擬合現(xiàn)象。訓(xùn)練時(shí)訓(xùn)練集數(shù)據(jù)批量輸入,大小為N*12*1(其中N為批大小,12為序列長(zhǎng)度,1為通道數(shù))。經(jīng)過(guò)第1層卷積后輸出特征圖大小為N*12*32,經(jīng)過(guò)池化后特征圖大小為N*6*32。第2層卷積后輸出特征圖大小為N*6*64,經(jīng)過(guò)池化后特征圖大小為N*3*64。全連接層輸出128維特征向量,輸出層輸出目標(biāo)為無(wú)人機(jī)的置信度,越接近1則無(wú)人機(jī)的置信度越高。圖2為無(wú)人機(jī)識(shí)別網(wǎng)絡(luò)結(jié)構(gòu)。
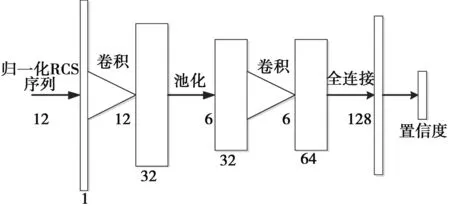
圖2 無(wú)人機(jī)識(shí)別網(wǎng)絡(luò)結(jié)構(gòu)
2.2 卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)是深度學(xué)習(xí)模型中的重要內(nèi)容。[7]在傳統(tǒng)人工神經(jīng)網(wǎng)絡(luò)中引用了卷積核、池化層等操作,實(shí)現(xiàn)了權(quán)值共享,具有強(qiáng)大的特征提取能力,并且相對(duì)于全連接網(wǎng)絡(luò)有效減少了網(wǎng)絡(luò)參數(shù),在一定程度上緩解了過(guò)擬合,提升了網(wǎng)絡(luò)的性能。
卷積神經(jīng)網(wǎng)絡(luò)由輸入層、輸出層及多個(gè)隱藏層構(gòu)成。隱藏層一般包括卷積層、池化層。池化層接在卷積層后面,減少特征維數(shù)。輸入樣本在輸入后首先經(jīng)過(guò)卷積層,與卷積核進(jìn)行卷積,然后加上偏置。經(jīng)過(guò)卷積后輸出的特征向量再輸入池化層進(jìn)行特征降維。一般網(wǎng)絡(luò)中有多個(gè)卷積層和池化層。卷積層的輸出作為池化層的輸入,池化層的輸出作為下一層卷積的輸入。重復(fù)上述的卷積池化操作,直至達(dá)到設(shè)定的網(wǎng)絡(luò)深度。在卷積和池化操作后,輸出的特征向量一般會(huì)使用非線性激活函數(shù)激活映射成非線性特征。卷積神經(jīng)網(wǎng)絡(luò)的最后一層或幾層一般是全連接層。全連接層的作用是對(duì)卷積結(jié)構(gòu)提取的抽象特征進(jìn)行合并整合。在網(wǎng)絡(luò)末尾通常會(huì)連接著logistic回歸或softmax分類器,實(shí)現(xiàn)二分類或者多分類。
2.3 卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練
和其他的人工神經(jīng)網(wǎng)絡(luò)類似,卷積神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過(guò)程通常分為前向傳播和后向傳播兩個(gè)主要過(guò)程。[8]前向傳播表達(dá)了特征信息的傳遞。反向傳播主要是傳播誤差,計(jì)算梯度通過(guò)梯度下降方法實(shí)現(xiàn)參數(shù)的更新,并使參數(shù)最終收斂至全局最小或局部最先值。
(1) 前向傳播
全連接層前向傳播公式可以表示為
al=σ(al-1wl+bl)
(1)
其中,σ()為非線性激活函數(shù),一般有Sigmoid、tanh、ReLU等。
卷積層的前向傳播公式可表示為
al=σ(al-1*wl+bl)
(2)
池化層是對(duì)卷積得到的特征圖進(jìn)行下采樣的過(guò)程,主要有平均池化、最大池化等方式。
(2) 后向傳播
? 最后一層的殘差
(3)
δL=▽aCeσ′(zL)
(4)
? 全連接層殘差反向傳播公式
δl=((wl+1)Tδl+1)·σ′(zl)
(5)
? 全連接層權(quán)重及偏置更新公式
(6)
(7)
? 卷積層殘差反向傳播公式
δl=δl+1*rot180(wl+1)·σ′(zl)
(8)
? 卷積層權(quán)重及偏置更新公式
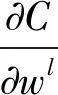
(9)
(10)
池化層殘差反向傳播時(shí),如果是最大池化層,則下一層的誤差項(xiàng)的值會(huì)原封不動(dòng)地傳遞到上一層對(duì)應(yīng)區(qū)塊中的最大值所對(duì)應(yīng)的神經(jīng)元,而其他神經(jīng)元的誤差項(xiàng)的值都為零。如果是平均池化層,下一層的誤差項(xiàng)會(huì)平均分配到上一層對(duì)應(yīng)區(qū)塊中的所有神經(jīng)元。
3 聚類SMOTE算法
在進(jìn)行鳥(niǎo)和無(wú)人機(jī)的數(shù)據(jù)處理時(shí),由于鳥(niǎo)類數(shù)據(jù)多,無(wú)人機(jī)數(shù)據(jù)少,鳥(niǎo)類樣本是無(wú)人機(jī)樣本的好幾倍,數(shù)據(jù)集存在嚴(yán)重的不平衡問(wèn)題,因此可能會(huì)導(dǎo)致模型學(xué)到的分類決策面傾向鳥(niǎo)類一側(cè),導(dǎo)致無(wú)人機(jī)分裂損失過(guò)大,無(wú)法有效識(shí)別無(wú)人機(jī)。數(shù)據(jù)集不平衡問(wèn)題是機(jī)器學(xué)習(xí)中經(jīng)常遇到的一類問(wèn)題。在不平衡問(wèn)題中一般將樣本多的類稱為多數(shù)類,樣本少的類稱為少數(shù)類。在像本文的這種二分類問(wèn)題中,將多數(shù)類稱為負(fù)類,少數(shù)類稱為正類。由于樣本數(shù)量的嚴(yán)重傾斜,直接分類具有很大的偏向性。多數(shù)類的分類準(zhǔn)確率相對(duì)較高,少數(shù)類的分類準(zhǔn)確率相對(duì)較低。不均衡數(shù)據(jù)的分類問(wèn)題是機(jī)器學(xué)習(xí)、深度學(xué)習(xí)領(lǐng)域的重要研究?jī)?nèi)容之一,在均衡數(shù)據(jù)集上表現(xiàn)良好的分類方法在不均衡數(shù)據(jù)集上往往會(huì)暴露出很多問(wèn)題。常用的解決方法主要分為兩個(gè)層面:數(shù)據(jù)層面和算法層面。數(shù)據(jù)層面包括上采樣、下采樣和混合采樣,算法層面主要包括單類學(xué)習(xí)、集成學(xué)習(xí)、代價(jià)敏感性學(xué)習(xí)等方法,目前比較常用的方法是SMOTE算法。[9]
3.1 SMOTE算法
SMOTE算法是一種過(guò)采樣算法,被廣泛應(yīng)用于解決不平衡數(shù)據(jù)集的問(wèn)題,其主要思想是:對(duì)于每一個(gè)少數(shù)類樣本x,搜索其K個(gè)同類最近鄰樣本,若上采樣的倍率是N,則在其K個(gè)最近鄰樣本中隨機(jī)選擇N個(gè)樣本,記為y1,y2,…,yN,在少數(shù)類樣本x和yi(i=1,2,…,N)之間進(jìn)行隨機(jī)線性插值,構(gòu)造新的少數(shù)類樣本pi。公式描述如下:
pi=x+rand(0,1)*(yi-x),i=1,2,…,N
(11)
在使用公式(11)插值后,將新產(chǎn)生的少數(shù)類樣本加入到原來(lái)的訓(xùn)練集中產(chǎn)生新的訓(xùn)練集。
3.2 基于聚類的SMOTE
由圖3可以看出,由于未考慮少數(shù)類內(nèi)間聚類問(wèn)題,直接插值會(huì)產(chǎn)生噪聲,導(dǎo)致分類性能下降。因此,本文提出一種基于聚類的SMOTE算法,其基本思想是先利用K-means算法在少數(shù)類內(nèi)部產(chǎn)生聚類,然后圍繞類中心使用SMOTE算法插值。具體步驟如下:
(1) 統(tǒng)計(jì)雜波點(diǎn)數(shù)M、目標(biāo)點(diǎn)數(shù)N(M>N);
(2) 基于ENN(Edited Nearest Neighbor),清理雜波噪聲點(diǎn),假設(shè)有P點(diǎn);
(3) 利用T-SNE對(duì)目標(biāo)數(shù)據(jù)可視化,得到目標(biāo)類間聚類數(shù)C;
(4) 基于K-means對(duì)目標(biāo)進(jìn)行聚類,聚類數(shù)設(shè)為C,聚類產(chǎn)生C個(gè)類間簇;
(5) 對(duì)每個(gè)類間簇使用SMOTE插值,每個(gè)點(diǎn)插值個(gè)數(shù)為(M-N-P)/N。
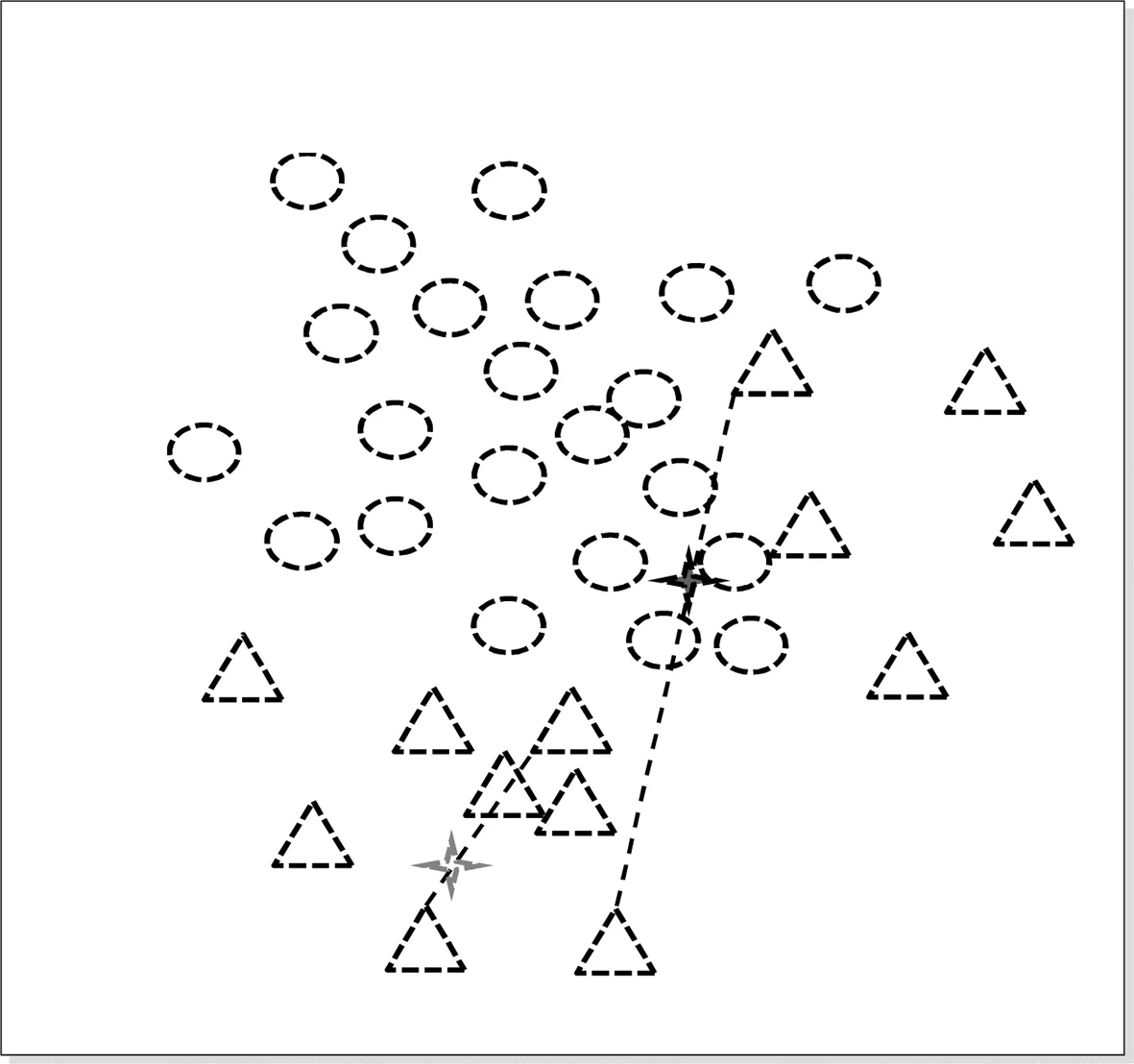
圖3 SMOTE插值
4 分類性能評(píng)價(jià)指標(biāo)
由于類別不平衡,不能簡(jiǎn)單地使用平均準(zhǔn)確率作為評(píng)價(jià)指標(biāo),因?yàn)槎鄶?shù)類樣本對(duì)平均準(zhǔn)確率的影響更大,性能評(píng)估度量應(yīng)區(qū)別對(duì)待不同類別上的準(zhǔn)確率,最常見(jiàn)的評(píng)價(jià)指標(biāo)有F-measure、G-mean、AUC[10]等。為了介紹這些指標(biāo),先要引入模糊矩陣這一概念,如表1所示。

表1 混淆矩陣
TP表示實(shí)際為正例被分為正例的樣本數(shù),同理FN、FP、TN分別表示對(duì)應(yīng)情況的樣本數(shù),顯然有TP+FN+FP+TN=樣本總數(shù)。精準(zhǔn)度是分類問(wèn)題常用的評(píng)價(jià)指標(biāo),在樣本平衡時(shí)可以有效地反映分類器的分類性能。
(12)
針對(duì)不平衡數(shù)據(jù)集,常用的評(píng)價(jià)指標(biāo)有F-measure、G-mean、ROC曲線和AUC。
(13)
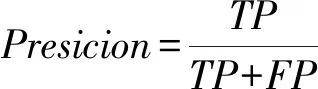
(14)
可以看出,G-mean值綜合考慮了兩類的分類準(zhǔn)確率,相對(duì)于單獨(dú)使用準(zhǔn)確率而言,能夠更好地衡量分類器的分類性能,不均衡數(shù)據(jù)集下常用的衡量指標(biāo)。
在本文中,分類器采用卷積神經(jīng)網(wǎng)絡(luò),網(wǎng)絡(luò)末尾使用logistic回歸輸出樣本是無(wú)人機(jī)的置信度。實(shí)際上,可以設(shè)置一系列置信度閾值,大于閾值則認(rèn)為是正類(無(wú)人機(jī)),小于閾值則認(rèn)為是負(fù)類(鳥(niǎo))。因此,可以得到一個(gè)動(dòng)態(tài)的指標(biāo)。一般將“真正類率”(TPR)作為縱軸,“假正類率”(FPR)作為橫軸,得到的曲線稱為ROC曲線。TPR和FPR定義為
(15)
(16)
一般來(lái)說(shuō),ROC曲線越靠近左上角說(shuō)明分類器性能越好。為了定量地比較,可以ROC曲線下的面積,也就是AUC值,AUC值越大則說(shuō)明分類器性能越好。本文綜合使用這幾個(gè)指標(biāo)來(lái)評(píng)價(jià)無(wú)人機(jī)的分類性能。
5 實(shí)錄數(shù)據(jù)驗(yàn)證
5.1 數(shù)據(jù)集
訓(xùn)練集和測(cè)試集來(lái)自不同日期、不同批次的數(shù)據(jù)。因此,測(cè)試集可有效驗(yàn)證方法的泛化能力。從表2可以看出,數(shù)據(jù)集存在嚴(yán)重的不平衡問(wèn)題,訓(xùn)練集中不平衡比例達(dá)到了8.36。因此,在訓(xùn)練前使用聚類插值方法將無(wú)人機(jī)樣本從544個(gè)擴(kuò)充到4 548個(gè)。實(shí)驗(yàn)中也使用了未平衡的原始數(shù)據(jù)訓(xùn)練作為對(duì)照比較。
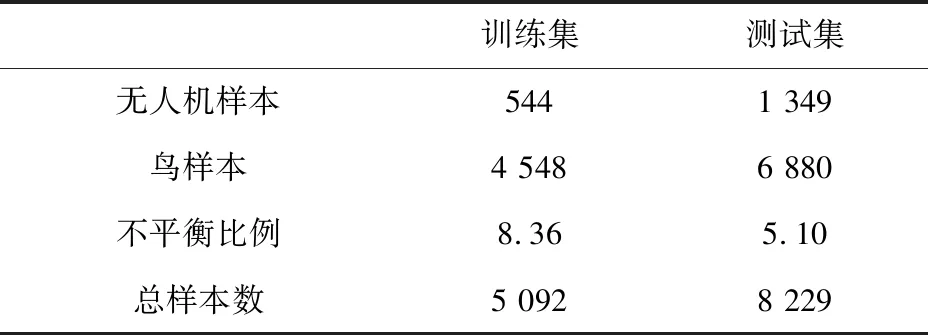
表2 數(shù)據(jù)集
在數(shù)據(jù)輸入網(wǎng)絡(luò)前需要對(duì)數(shù)據(jù)預(yù)處理,將數(shù)據(jù)縮放在0~1間。無(wú)人機(jī)和鳥(niǎo)樣本示例如圖4所示。
5.2 訓(xùn)練過(guò)程及特征可視化
在訓(xùn)練中,隨著訓(xùn)練的進(jìn)行,訓(xùn)練損失會(huì)逐漸降低,網(wǎng)絡(luò)會(huì)慢慢收斂,測(cè)試集的AUC值會(huì)逐漸上升。圖5為訓(xùn)練集損失曲線,圖6為測(cè)試集AUC變化曲線。
訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)最后一層全連接層輸出網(wǎng)絡(luò)學(xué)習(xí)到的特征向量(如圖7所示),分別為鳥(niǎo)類樣本和無(wú)人機(jī)類樣本對(duì)應(yīng)的特征向量。為了驗(yàn)證學(xué)習(xí)到的特征向量具有有效的可分性,使用PCA降維可視化(如圖8所示),可以看出數(shù)據(jù)在學(xué)習(xí)到的特征上具有明顯的可分性。
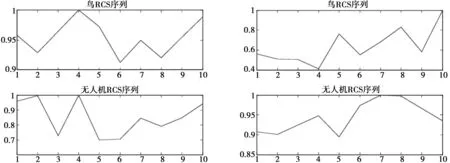
圖4 數(shù)據(jù)集樣本

圖5 訓(xùn)練集損失曲線
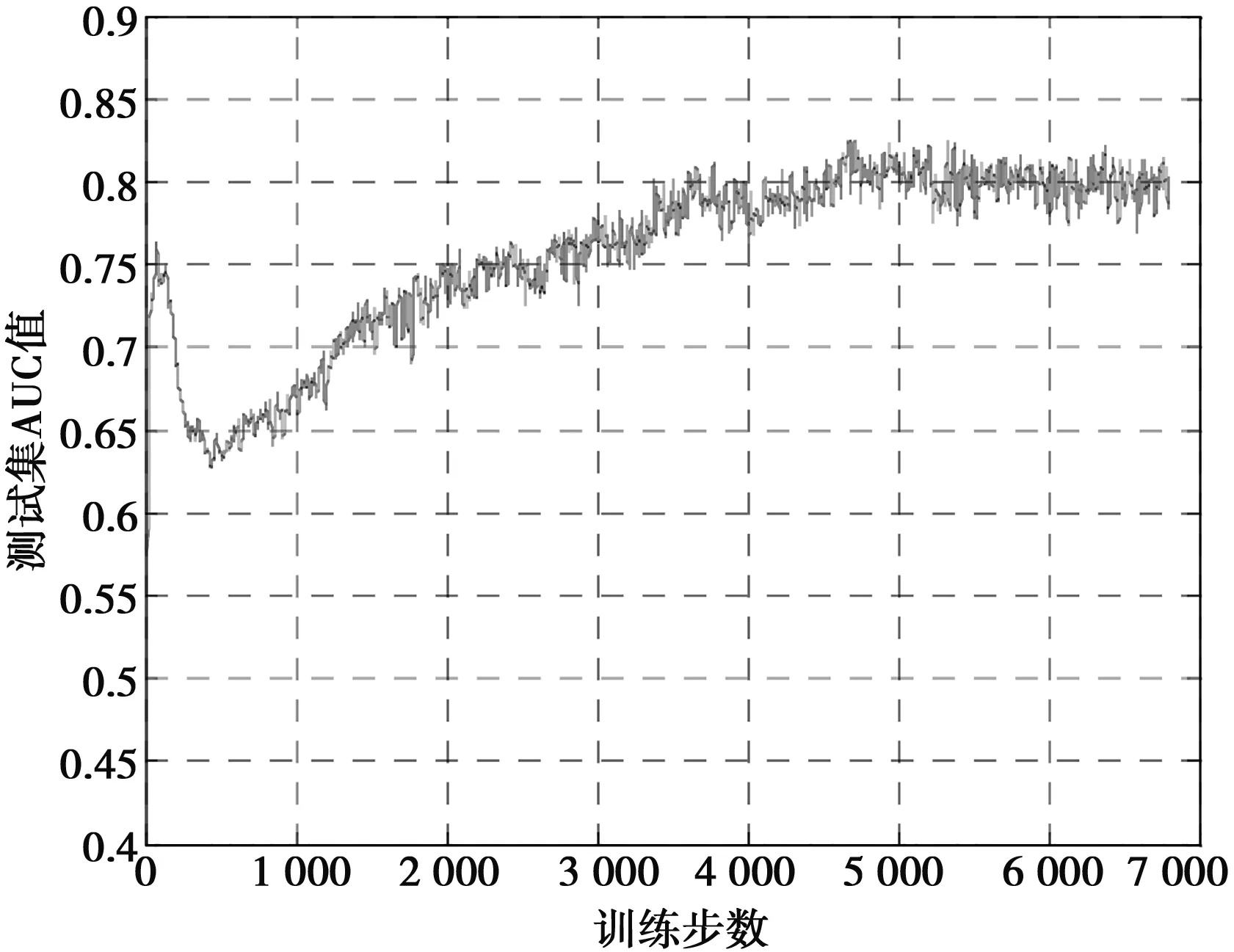
圖6 測(cè)試集AUC變化曲線
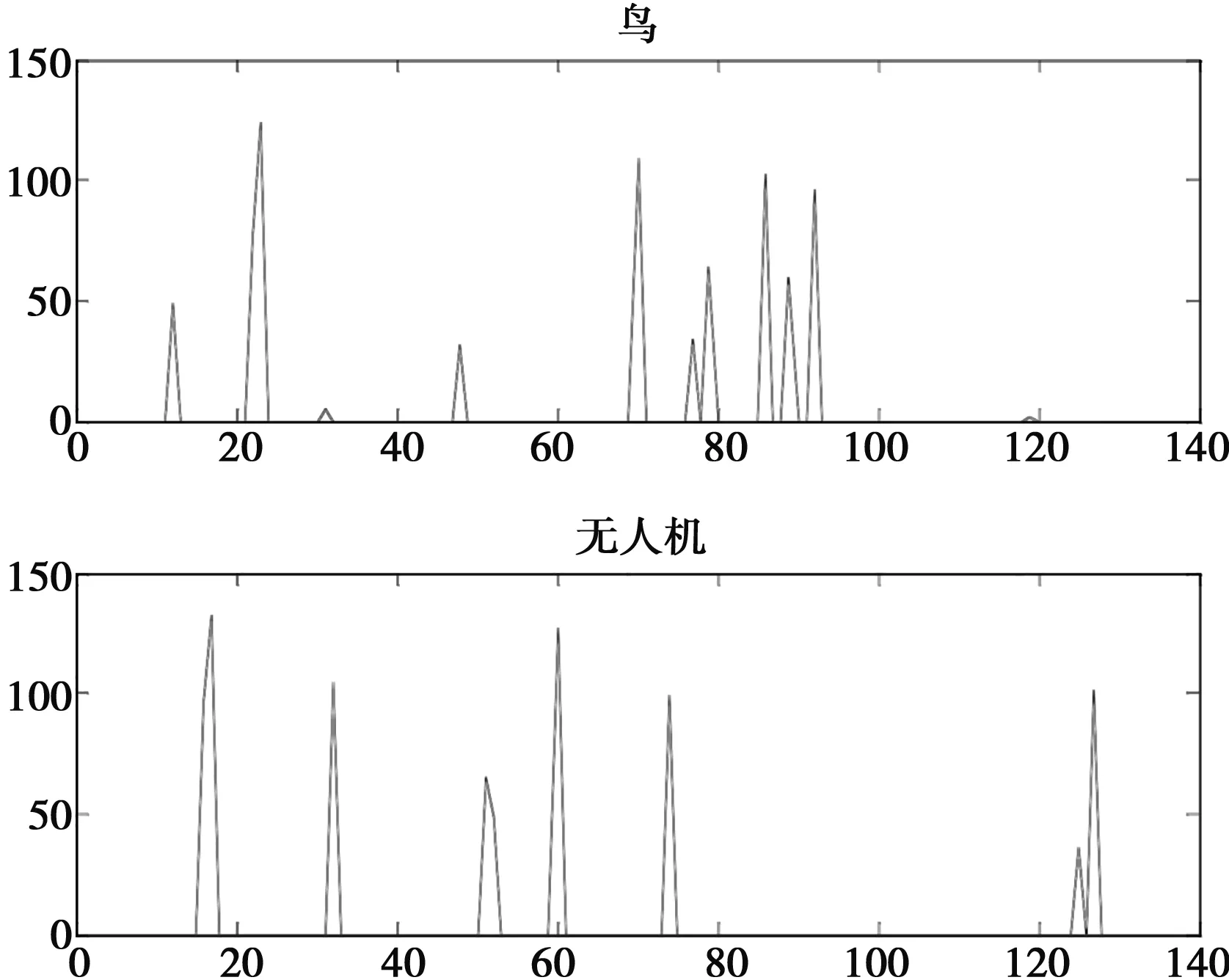
圖7 特征向量
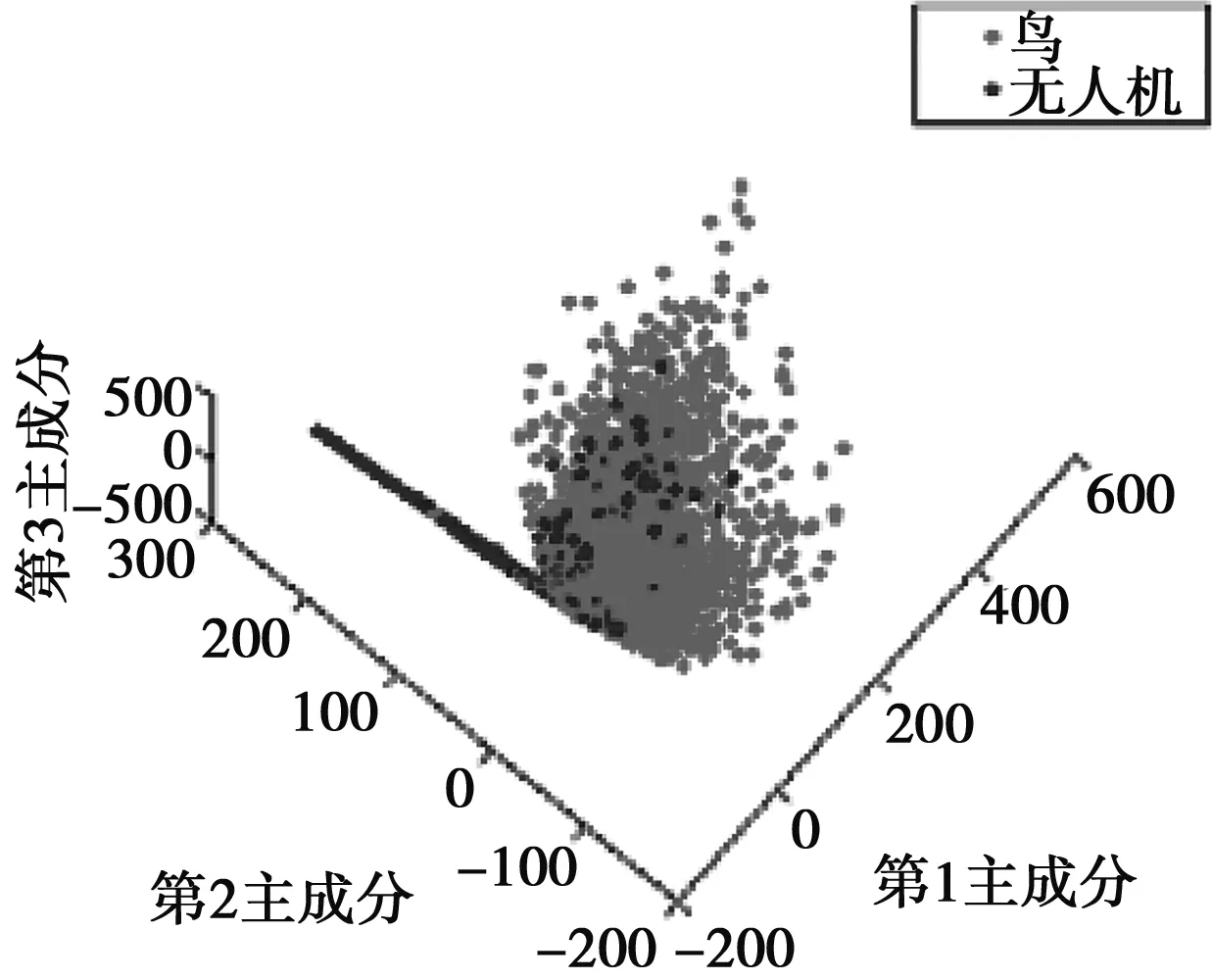
圖8 特征向量可視化結(jié)果
5.3 性能分析
為了驗(yàn)證本文方法的有效性,采用F-measure、G-mean、ROC曲線、AUC 4個(gè)指標(biāo)評(píng)價(jià)最終性能,并將使用SMOTE平衡的訓(xùn)練集和未平衡的訓(xùn)練集作為對(duì)照組,驗(yàn)證聚類SMOTE解決本文不平衡問(wèn)題的能力。由表3可以看出,聚類SMOTE方法3種定量指標(biāo)值均優(yōu)于對(duì)照組,且由圖9通過(guò)ROC曲線可以看出聚類SMOTE的 ROC曲線完全包裹住對(duì)照組曲線。實(shí)驗(yàn)結(jié)果可以看出,聚類SMOTE可有效緩解數(shù)據(jù)不平衡問(wèn)題。將置信度閾值設(shè)為0.5后得到混淆矩陣如表4。可以看出,在無(wú)人機(jī)識(shí)別率達(dá)到87%的同時(shí)可過(guò)濾60%的虛假目標(biāo)。
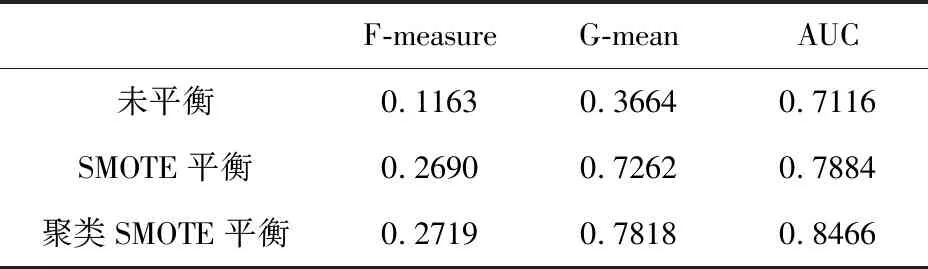
表3 指標(biāo)對(duì)比

表4 混淆矩陣
6 結(jié)束語(yǔ)
由于小型無(wú)人機(jī)飛行速度較慢、飛行高度較低且RCS小,飛鳥(niǎo)會(huì)導(dǎo)致無(wú)人機(jī)檢測(cè)系統(tǒng)出現(xiàn)大量虛警。本文聚焦于無(wú)人機(jī)和飛鳥(niǎo)的識(shí)別問(wèn)題,使用深度學(xué)習(xí)網(wǎng)絡(luò)對(duì)RCS序列進(jìn)行特征學(xué)習(xí),針對(duì)數(shù)據(jù)不平衡問(wèn)題提出聚類SMOTE算法,進(jìn)而實(shí)現(xiàn)無(wú)人機(jī)的有效識(shí)別。經(jīng)過(guò)實(shí)錄數(shù)據(jù)驗(yàn)證,本文方法在無(wú)人機(jī)識(shí)別準(zhǔn)確率達(dá)到87%的同時(shí)過(guò)濾掉60%的飛鳥(niǎo)目標(biāo)。
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫(huà)刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
