基于可分離卷積的輕量級惡意域名檢測模型
2020-12-18 00:07:48楊路輝白惠文劉光杰戴躍偉
網絡與信息安全學報 2020年6期
楊路輝,白惠文,劉光杰,2,戴躍偉,2
基于可分離卷積的輕量級惡意域名檢測模型
楊路輝1,白惠文1,劉光杰1,2,戴躍偉1,2
(1. 南京理工大學自動化學院,江蘇 南京 210094;2. 南京信息工程大學電子與信息工程學院,江蘇 南京 210044)
考慮到基于深度學習的惡意域名檢測方法計算開銷大,難以有效應用于真實網絡場景域名檢測實際,設計了一種基于可分離卷積的輕量級惡意域名檢測算法。該模型使用可分離卷積結構,能夠對卷積過程中的每一個輸入通道進行深度卷積,然后對所有輸出通道進行逐點卷積,在不減少卷積特征提取效果的情況下,有效減少卷積過程的參數量,實現更加快速的卷積過程并不降低模型的準確性。同時,為了減輕模型訓練過程中正負樣本數量不平衡與樣本難易程度不平衡的情況對模型分類準確率的影響,引入了一種聚焦損失函數。所提算法在公開數據集上與3種典型的基于深度神經網絡的檢測模型進行對比,實驗結果表明,算法能夠達到與目前最優模型接近的檢測準確率,同時能夠顯著提升在CPU上的模型推理速度。
可分離卷積;域名生成算法;深度學習;網絡安全
1 引言
近年來,越來越多的僵尸網絡(Botnet)和高級可持續威脅攻擊(APT,advanced persistent threat)成為網絡安全中不可忽視的安全事件類型。在這些網絡攻擊事件中,攻擊者通常會先向目標網絡中植入惡意軟件,惡意軟件向命令與控制(C&C,command and control)服務器傳輸數據并接受控制命令,實現對目標的持續控制。在通信過程中,惡意軟件為了提高隱蔽性,盡可能增加存活時間,往往會使用域名生成算法(DGA,domain generation algorithm)隨機生成一組域名,并注冊為C&C服務器的域名,然后,惡意軟件只需內置DGA的隨機種子,即可計算出可用的C&C服務器域名,進而與之通信。通過DGA的方法,能夠避免使用硬編碼的域名和IP地址,增加了安全軟件對可疑通信行為的發現和阻斷難度。因此,高效準確地檢測DGA生成的域名,能夠有助于及時發現網絡攻擊事件中的可疑通信行為,對于網絡攻擊事件的分析和防御有十分重要的意義。
為了有效地檢測DGA域名,早期的研究者主要通過提取域名的字符特征的方法進行檢測。文獻[1]分析了域名的相對熵、雅克比系數、編輯距離等特征,通過這些字符特征進行惡意域名檢測。文獻[2]在提取字符特征的基礎上,引入了線性回歸算法進行分類。文獻[3]提取了15個維度的域名特征,并引入了機器學習分類的方法,采用J48決策樹進行分類,并且在真實網絡場景下的數據集中驗證了分類模型的有效性。文獻[4]針對基于單詞的DGA域名,提出了一種基于詞關聯特征提取結合混合分類器的檢測算法。這些使用域名特征結合機器學習分類器的方法能夠在部分場景中有效使用。文獻[5]提出僅從域名上提取特征不足以實現精確的檢測,于是在提取域名字符特征的基礎上,增加了流量維度的特征分析。文獻[6]則進一步深入和優化了該類算法。特征工程結合機器學習分類器的方法過度依賴于人工分析和特征提取,提取的特征維度有限且容易出現檢測模型失配或者過擬合問題,且分類器的選取對于分類結果影響很大。對于域名字符特征之外的通信流量特征,無法滿足檢測的實時性和效率要求,從域名的字符特性出發,依舊是最行之有效的檢測方法。
近幾年來,深度學習的發展為DGA惡意域名的檢測提供了新的思路,文獻[7]首次采用深度學習的方法進行DGA域名檢測,其采用了長短期記憶網絡(LSTM,long short-term memory)的檢測模型,實現了比采用特征工程結合機器學習分類器更有效的檢測算法。隨后,文獻[8]首次采用比LSTM計算速度更快的卷積神經網絡(CNN,convolutional neural network)設計了檢測模型,同樣取得了比傳統方法更好的檢測結果。文獻[9]分析和比較了多種深度網絡模型對DGA域名的檢測結果,發現使用了并行CNN結構的模型檢測效果最好。考慮到DGA域名樣本存在不均衡問題,文獻[10]使用了一種結合權重調節的LSTM模型提高DGA域名的檢測以及DGA家族的多分類結果,是目前檢測效果最好的模型。文獻[11]則使用了一種結合注意力機制的LSTM模型實現DGA域名檢測與多分類。近年來的研究成果表明,使用深度學習進行DGA惡意域名檢測模型檢測準確率明顯優于傳統的特征工程結合機器學習分類器方法。然而,深度學習模型參數量大、計算復雜度較高,真實網絡場景下對域名檢測的時效性要求高,在保證準確率的情況下,設計更加輕量化的檢測模型是惡意域名檢測的一個重要研究方向。
本文基于可分離卷積結構設計了一種輕量化的惡意域名檢測模型,通過對每一個輸入通道進行空間深度卷積,然后對所有輸出通道進行逐點卷積,能夠在不降低卷積特征提取效果的情況下,有效減少卷積過程的參數量,實現更加快速的卷積過程并實現特征提取。同時,考慮到域名樣本收集過程中,存在正負樣本數量不平衡以及不同DGA算法生成的域名檢測難易程度不同的雙重不平衡問題,在模型的訓練過程中引入了一種聚焦損失函數提高模型準確率。本文檢測模型與3種基于深度學習的DGA域名檢測模型進行了對比實驗,實驗結果表明,本文檢測模型能夠在保證較高檢測率的基礎上,顯著提高檢測速度。本文主要貢獻在于首次將可分離卷積結構引入惡意域名檢測領域,減少模型的計算參數量,且引入了聚焦損失函數,在不增加計算復雜度的情況下提高平均檢測準確率,同時比較和分析了多種基于深度方法的惡意域名檢測模型的計算時間和檢測準確率,對于將深度學習實際應用到網絡域名安全領域起到積極作用。
2 可分離卷積神經網絡結構
本節介紹卷積神經網絡的原理及其在惡意域名檢測問題上的應用方式,以及可分離卷積模型結構與原理,進一步闡述了可分離卷積結構應用在惡意域名檢測領域的可行性及帶來的益處。
2.1 卷積神經網絡
卷積神經網絡最早由文獻[12]提出,后來被廣泛應用于二維圖像的分類和目標檢測問題。其主要原理是通過卷積層提取二維圖像的高維特征,然后通過全連接層輸出預測結果。經過數十年的發展,卷積神經網絡在圖像分類、圖像識別、圖像分割等領域占據了絕對的主導地位。在自然語言處理領域,尤其是文本分類領域,早期的模型是基于循環神經網絡(RNN,recurrent neural network)以及由RNN發展而來的LSTM網絡結構進行設計,由于文本長度不定,且文本屬于序列數據,前后關聯性較大,早期的研究者并不認為CNN能夠有效應用于文本分類,直到文獻[13]首次將CNN應用于句子的分類,并取得了不錯的效果,此后,CNN被廣泛應用于各種文本分類任務,近年來也被用于DGA惡意域名的檢測。

圖1 基于CNN的文本分類過程
Figure1 Text classification process based on CNN
圖1展示了基于CNN的文本分類過程,首先需要對文本進行分詞,然后將每個詞量化成可用于卷積計算的詞向量,使用相應大小的卷積核對詞向量進行卷積操作,得到一組特征圖,對特征圖進行池化,選擇其中顯著性較高的特征量形成一個一維特征圖,將這個一維特征圖輸入全連接層中,并輸出預測結果。其中,卷積過程可以用式(1)表示。

其中,c表示每次卷積輸出的結果,表示非線性激活函數,表示每個卷積濾波器的參數,表示偏置項,表示一個窗口的詞向量,表示卷積窗口大小即卷積核大小。
文本分類中對文本的卷積操作需要對文本中的單詞進行量化,其原理為通過某種映射方式,將單詞映射成數值向量,目前較為流行的詞向量量化方法包括Word2vec及BERT等,然而這些量化方法依賴于大量標注過的語料庫并需要訓練,量化準確率依賴于語料庫的語料數量及標注的準確性。為了避免詞向量的量化準確性對于文本分類結果準確性的影響,文獻[14]提出使用字符級的CNN進行文本分類,只需要對每個英文單詞中的單個字母進行量化,即可進行卷積操作與全連接分類,使用字符級的量化方法,同樣能夠充分利用CNN進行特征提取,并得到準確的分類結果。對于DGA惡意域名,由于域名的構成元素一般為英文字母、數字以及特殊字符,且域名生成過程大部分采用某種隨機選擇的方式選擇一定數量的字符組合成一個域名,所以生成的DGA域名不具備完整的單詞構成,使用CNN處理DGA域名時,必須采用字符級的CNN模型。同樣地,本文中的檢測模型也是基于字符級的域名量化和處理的。
2.2 可分離卷積
可分離卷積是文獻[15]提出的MobileNets模型中的高性能卷積結構,其基本原理是將標準卷積過程分解成等效的深度卷積和逐點卷積,能夠在不損失卷積精度的情況下顯著減少運算量。可分離卷積結構如圖2所示。

圖2 標準二維卷積與深度可分離二維卷積結構
Figure2 Standard and depthwise separable 2D convolution structures
對于標準二維卷積過程,如圖2(a)所示,每次卷積過程使用大小的卷積核進行卷積濾波,輸出的特征圖通道數為。圖2(b)表示深度卷積,每一次卷積過程使用個大小的卷積核進行卷積,輸出特征圖通道數設為1。圖2(c)表示逐點卷積,即使用1×1卷積核對圖2(b)的輸出通道進行卷積操作,圖2(b)和圖2(c)的結合使用即可取代圖2(a)所示的標準二維卷積過程,然而計算量顯著減少。圖2(a)表示的卷積過程參數量如式(2)所示。
×××(2)
可分離二維卷積過程即使用圖2 (b)和圖2(c)結合,其參數量如式(3)所示。
××+1×1××(3)
因此,可分離二維卷積與標準二維卷積參數量對比如式(4)所示。

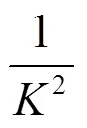
對于惡意域名檢測,一般使用的是一維卷積,卷積核大小為,同理即可得出可分離一維卷積與標準一維卷積參數量對比為


3 基于可分離卷積的惡意域名檢測模型設計
由于可分離卷積能夠有效減少卷積過程中的參數量,并提升計算速度,本節詳細介紹基于可分離卷積的惡意域名檢測模型結構及參數設置,同時,針對域名進行卷積操作前,需要將域名量化成為數值向量,本節詳細介紹域名量化過程。針對多種類型的惡意域名樣本,存在數量與難易程度不同的雙重不平衡問題,極大影響深度模型的訓練準確率,為了提高模型的準確率,本文在模型訓練過程中引入了一種聚焦損失函數。
3.1 域名量化
為了使用卷積神經網絡提取域名的字符級特征,需要對域名中的字符進行量化,將每個字符映射成為一個數值向量。在傳統自然語言處理領域中,字符量化存在兩種量化模型,分別為獨熱表示模型和分布式表示模型。獨熱表示模型是將單詞映射成為一個長向量,向量中的所有分量中只有一個值為1,其他值全為0,數值1的位置代表該詞在所使用的映射字典中的位置,這種量化方法維度等于字典大小,不能有效表達兩個單詞之間的聯系,且字典較大時維度過高,不利于運算。分布式表示模型是將單詞映射成一個固定維度的向量,向量維度可控,便于運算,是目前更主流的量化方法。本文采用分布式表示模型對域名中的每個字符進行量化,量化過程首先需要統計所有域名中可能出現的字符,形成映射字典,本文基于大量域名樣本統計了出現過的87個字符,包括大小寫字母、數字、特殊符號等;然后對每個字符進行編號,將域名中的每個字符與編號進行一一映射;最后基于深度學習框架Keras中的Embedding層進行量化,即可得到每個字符的向量表達結果。
圖3以域名“baidu”為例展示了量化過程,域名長度設定為128個字節,長度不夠則補0,將每個字符向量的長度設定為128。
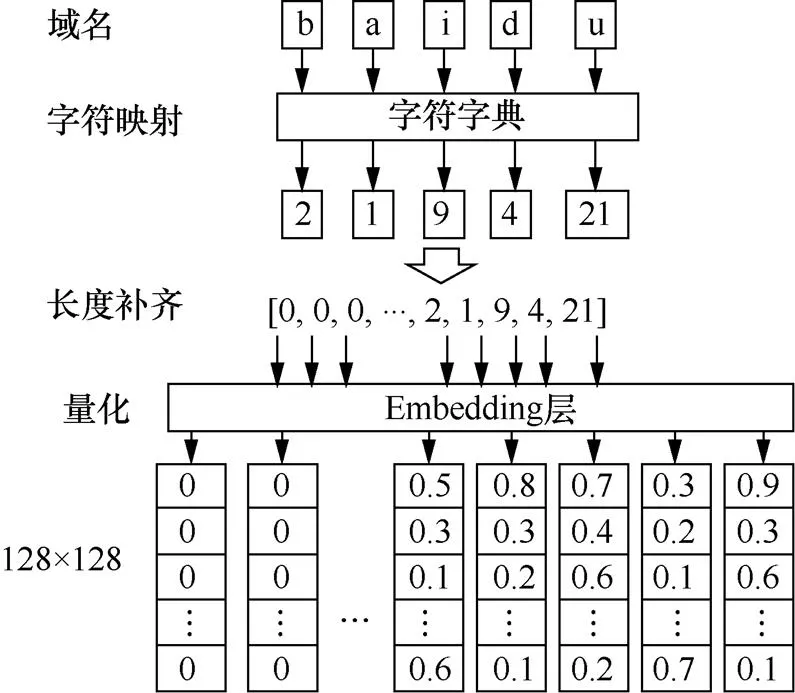
圖3 域名量化過程
Figure3 Domain name embedding process
3.2 基于可分離卷積的惡意域名檢測模型與參數設計
基于可分離卷積的惡意域名檢測模型基于第3.1節所述的字符量化方法與第2節所述的可分離卷積結構,輔以其他標準深度模型結構進行設計而成,其完整模型結構如圖4所示。模型主要包含9層深度網絡結構。第1層為輸入層,模型輸入為經過字典映射的域名向量,域名長度設為128,長度不足則補0。第2層為量化層(Embedding),將輸入的1×128維域名向量量化為128×128維向量,具體量化過程如第3.1節所示。第3層為一維可分離卷積層(SeparableConv1D),卷積核大小設為5,卷積核代表了卷積的感受野,卷積核太小,感受野不足,無法有效提取更大范圍的相鄰字符間的關聯特征,卷積核太大,則感受野過大,容易造成忽略局部相鄰字符間的關聯特征,卷積核太小或太大均會對分類結果造成不利影響,本文通過實驗對比了卷積核為3~7的分類結果,選擇了表現最好的卷積核大小5。第4層是隨機失活層(Dropout),設置隨機失活概率為0.5,可以增加模型隨機性,有效防止過擬合。第5層是展開層(Flatten),用于將所有通道的卷積結果展開并合并成一個一維向量,輸出維度為1×16384。第6層是全連接層(Dense),將1×16384維度的特征圖進行全連接,輸出1×128維度的特征圖。第7層是隨機失活層,同樣是為了防止過擬合。第8層是全連接層,輸入為1×128維度的特征圖,經過全連接后輸出1×1特征圖。第9層是激活層(Activation),由于本文的模型是二分類模型,采用sigmoid激活函數,將輸出映射為0~1的數值結果,輸出值如果小于0.5,則判定為合法域名,否則為惡意域名。完整的模型參數如表1所示。
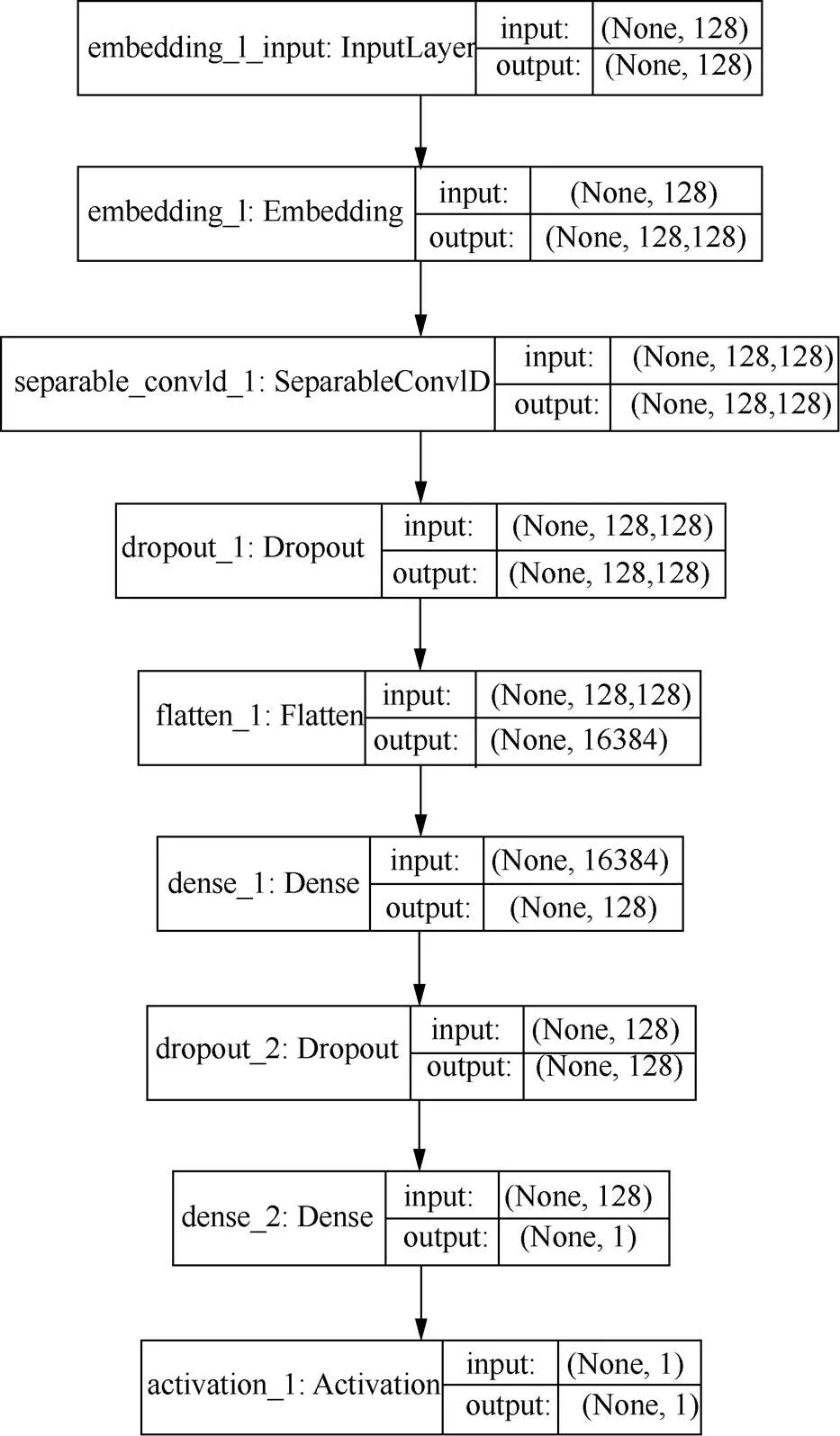
圖4 基于可分離卷積的惡意域名檢測模型結構
Figure4 The structure of malicious domain name detection model based on depthwise separable convolution
3.3 聚焦損失函數

表1 檢測模型參數
聚焦損失函數(focal loss)最早由文獻[16]提出,用于緩解圖像目標檢測問題中的樣本不均衡問題,由傳統的交叉熵損失函數改進而來,其原理是通過調節難易樣本的損失值,增大難分類樣本的損失,減少容易分類樣本的損失,使網絡模型向難分類樣本聚焦,增加對難樣本的檢測能力,從而增加整體的檢測準確率。傳統二分類交叉熵損失函數如式(6)所示。
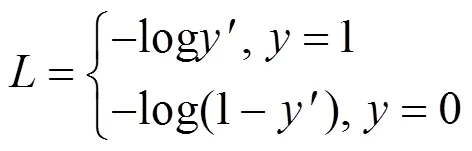
其中,是網絡模型輸出的預測結果值,是樣本真實標簽,在二分類中值為0或1。當=1時,預測值越接近1,損失值越小;當=0時,預測值越接近0,損失值越小。然而,當訓練樣本中存在大量容易樣本時,即預測結果很接近真實值時,大量容易樣本帶來的損失將淹沒少量難樣本的損失,從而影響梯度下降的方向,使模型無法得到最優的結果。為了減少容易樣本對模型的影響,增加難樣本的影響力,引入一個影響因子,改進后的函數如式(7)所示。
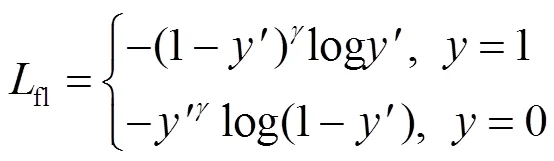
損失值隨預測值變化如圖5所示,聚焦損失函數增大了難易樣本產生的損失值的區分度,使難樣本產生相對于容易樣本更加顯著的損失值。
考慮到在域名檢測問題中,合法域名的樣本比惡意域名樣本更容易獲取,合法域名的數量明顯多于惡意域名,需要增加一個權重,完整的聚焦損失函數如式(8)所示。

Figure5 The loss curve of focalloss
惡意域名檢測模型的訓練樣本中,合法域名數量遠多于惡意域名樣本數量,且惡意域名種類較多,不同DGA算法原理不同,其生成的域名異常程度也不相同,因此針對惡意域名進行分類時,對于部分異常程度較高的DGA種類檢測效果較好,而針對部分異常程度低的DGA種類,檢測效果一般不好。為了使檢測模型聚焦在更難檢測的DGA種類上,本文采用聚焦損失函數作為訓練過程中的損失函數,用來緩解訓練過程中樣本數量和難易程度不均衡帶來的問題,提高綜合檢測率。
4 實驗與結果分析
4.1 數據集
本文從公開數據源中收集了400 000個合法域名和100 000個惡意DGA域名,其中,合法域名來自思科收集的DNS白名單數據。惡意域名來自360網絡安全實驗室收集的DGA域名樣本,共包含20種惡意軟件或攻擊事件中的DGA域名樣本,每種類型取5 000個樣本。樣本詳情如表2所示,訓練集與測試集按照9:1的比例劃分。
4.2 實驗平臺與模型評價標準
本文實驗使用的硬件平臺處理器為英特爾酷睿i7-7700HQ@2.8 GHz,訓練過程使用英偉達顯卡GTX2080Ti進行加速,深度神經網絡框架采用Keras作為前端,Tensorflow作為后端。在參數設置方面,本文采用Adam優化器,學習率設為0.001,1設為0.9,2設為0.999,參數衰減率設為0.000 05。
實驗結果評價標準采用平均準確率、召回率和曲線下面積(AUC,area under curve)和CPU推理時間。平均準確率和曲線下面積用于衡量模型整體的分類效果,召回率用于比較對算法生成域名樣本的分類效果,CPU推理時間是指模型對單個域名進行預測所使用的CPU計算時間。準確率、召回率與AUC計算式如(9)所示。

其中,avg為模型分類平均準確率,pos表示惡意域名樣本的分類準確率,neg表示合法域名樣本的分類準確率,表示召回率,TP為惡意域名樣本預測正確的數量,TN為合法域名樣本預測正確的數量,N表示惡意域名樣本預測錯誤的數量,FP表示合法域名樣本預測錯誤的數量,AUC表示曲線下面積的值。
4.3 損失函數參數設置
本文在訓練過程中使用了聚焦損失函數,其中有兩個可調節的超參數和,由合法域名與惡意域名樣本數量決定,由于使用的合法域名與惡意域名數量為4:1,合法域名標簽為0,惡意域名標簽為1,因此取=0.8。值與樣本的難易程度有關,無法通過計算得出最優值,因此在實驗過程中設置不同值,通過實驗選取最佳的值,在實驗過程中,分別取={0, 1, 1.5, 2, 2.5, 3, 3.5, 4, 5},模型平均準確率如圖6所示。通過調節參數后的平均準確率和AUC結果發現,當=2時,模型的檢測平均準確率和AUC最高,且實驗結果表明,使用聚焦損失函數能夠提高模型的檢測準確率。
4.4 對比實驗結果
本文對比了提出的基于可分離卷積的檢測算法、文獻[8]中基于標準卷積的檢測算法、文獻[7]中基于LSTM的檢測算法以及文獻[10]中的檢測算法,對比結果如表3所示,樣本中每種域名的分類準確率如圖7所示。
與文獻[8]中基于標準卷積的檢測算法和文獻[7]中基于LSTM的算法相比,本文提出的算法平均準確率和召回率更高。與文獻[10]中的檢測算法相比,本文算法的平均準確率與其相差不大。然而,本文提出的算法在CPU上的計算速度與3種對比算法相比均有明顯優勢,推理時間僅為0.6 ms,用時僅為文獻[8]算法的57%,是文獻[7]和文獻[10]的29%。本文在保證整體檢測效果與目前最優算法接近的基礎上,顯著提升了模型計算速度。具體到針對20類不同種類的DGA域名的檢測率,詳細結果如圖7所示。由于每種DGA域名的生成原理不同,其異常程度和檢測難度也不相同,文獻[8]中的算法對大部分DGA域名能夠實現超過95%的準確率,本文算法針對這些DGA種類保持了相近的準確率。然而,對于部分較難檢測的DGA域名種類,文獻[8]中的算法檢測率較低,對Symmi的檢測率僅為67.87%, 對Virut的檢測率僅為66.25%,對Simda的檢測率為84.82%,由于本文使用了聚焦損失函數,使模型能夠聚焦到這幾類難樣本,對Symmi的檢測率提升至80.09%,對Virut的檢測率提升至81.27%,對Simda的檢測率提升至89.03%,提升效果明顯。

表2 數據集描述

圖6 模型檢測結果隨參數γ值變化曲線
Figure6 Detection result with different value of

圖7 域名分類結果對比詳情
Figure7 Details of the classification result
實驗結果表明,本文提出的基于可分離卷積的輕量級惡意域名檢測模型能夠在保證較高檢測率的情況下,與對比算法相比明顯提升了在CPU上的模型推理速度,在使用聚焦損失函數后,能夠有效提升部分較難檢測的DGA類型的檢測準確率,與對比算法相比,本文提出的檢測模型更適合在真實網絡場景中應用。
5 結束語
考慮到在真實網絡環境中應用深度網絡模型進行惡意域名檢測,需要兼顧準確率和計算速度,本文提出了一種基于可分離卷積的輕量級惡意域名檢測模型,該模型使用可分離卷積結構取代標準卷積結構,能夠使用深度卷積核逐點卷積相結合的方式代替標準卷積過程,顯著提升卷積計算速度,同時保證不降低準確率,為了減輕樣本數量和難易程度對模型訓練結果的影響,引入了一種聚焦損失函數。本文從公開數據源上采集了大量合法域名與惡意域名樣本,并且將提出的檢測模型與基于標準卷積的檢測模型、基于LSTM的檢測模型以及目前檢測率最高的檢測模型進行對比實驗,實驗結果表明,本文提出的模型能夠達到與目前最優算法接近的檢測準確率,同時能夠顯著提升在CPU上的模型推理速度。

表3 對比實驗結果
本文設計的惡意域名檢測模型是一種通用的檢測模型,針對部分較難檢測的DGA域名種類準確率不夠高,未來的研究工作可以針對一些特定種類DGA域名的特征設計專用的檢測模型,同時考慮到近年來人工智能芯片的快速發展,可以結合人工智能芯片的特性,設計更加快速而準確的檢測算法。
[1] YADAV S, REDDY A K K, REDDY A L N, et al. Detecting algorithmically generated malicious domain names[C]//Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement 2010. 2010: 48-61.
[2] YADAV S, REDDY A K K, REDDY A L N, et al. Detecting algorithmically generated domain-flux attacks with DNS traffic analysis[J]. IEEE/ACM Transactions on Networking, 2012, 20(5): 1663-1677.
[3] BILGE L, SEN S, BALZAROTTI D, et al. EXPOSURE: a passive DNS analysis service to detect and report malicious domains[J]. ACM Transactions on Information and System Security (TISSEC), 2014, 16(4): 1-28.
[4] YANG L, ZHAI J, LIU W, et al. Detecting word-based algorithmically generated domains using semantic analysis[J]. Symmetry, 2019, 11(2): 176.
[5] SCHIAVONI S, MAGGI F, CAVALLARO L, et al. Tracking and characterizing botnets using automatically generated domains[J]. Computer Science, 2013(2): 217-248.
[6] SCHIAVONI S, MAGGI F, CAVALLARO L, et al. Phoenix: DGA-based botnet tracking and intelligence[C]//International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment. 2014: 192-211.
[7] WOODBRIDGE J, ANDERSON H S, AHUJA A, et al. Predicting domain generation algorithms with long short-term memory networks[J]. arXiv preprint arXiv:1611.00791, 2016.
[8] YU B , GRAY D L , PAN J , et al. Inline DGA detection with deep networks[C]//2017 IEEE International Conference on Data Mining Workshops (ICDMW). 2017.
[9] YU B, PAN J, HU J, et al. Character level based detection of DGA domain names[C]//2018 International Joint Conference on Neural Networks (IJCNN). 2018: 1-8.
[10] TRAN D, MAC H, TONG V, et al. A LSTM based framework for handling multiclass imbalance in DGA botnet detection[J]. Neurocomputing, 2018, 275: 2401-2413.
[11] QIAO Y, ZHANG B, ZHANG W, et al. DGA domain name classification method based on long short term memory with attention mechanism[J]. Applied Sciences,2019, 9:4205.
[12] LECUN Y, BOSER B, DENKER J S, et al. Backpropagation applied to handwritten zip code recognition[J]. Neural Computation, 1989, 1(4): 541-551.
[13] KIM Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
[14] ZHANG X, ZHAO J, LECUN Y. Character-level convolutional networks for text classification[C]//Advances in Neural Information Processing Systems. 2015: 649-657.
[15] HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications[J]. arXiv:1704.04861, 2017.
[16] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, (99): 2999-3007.
Lightweight malicious domain name detection model based on separable convolution
YANG Luhui1, BAI Huiwen1, LIU Guangjie1,2, DAI Yuewei1,2
1. School of Automation, Nanjing University of Science and Technology, Nanjing 210094, China 2. School of Electronic & Information Engineering, Nanjing University of Information Science and Technology, Nanjing 210044, China
The application of artificial intelligence in the detection of malicious domain names needs to consider both accuracy and calculation speed, which can make it closer to the actual application. Based on the above considerations, a lightweight malicious domain name detection model based on separable convolution was proposed.The model uses a separable convolution structure. It first applies depthwise convolution on every input channel, and then performs pointwise convolution on all output channels. This can effectively reduce the parameters of convolution process without impacting the effectiveness of convolution feature extraction, and realize faster convolution process while keeping high accuracy. To improve the detection accuracy considering the imbalance of the number and difficulty of positive and negative samples, a focal loss function was introduced in the training process of the model. The proposed algorithm was compared with three typical deep-learning-based detection models on a public data set. Experimental results denote that the proposed algorithm achieves detection accuracy close to the state-of-the-art model, and can significantly improve model inference speed on CPU.
separable convolution, domain generation algorithm, deep learning, cyber security
The National Natural Science Foundation of China (U1836104)
TP309
A
10.11959/j.issn.2096?109x.2020084

楊路輝(1992? ),男,江西黎川人,南京理工大學博士生,主要研究方向為網絡與信息安全。
白惠文(1992? ),男,吉林白山人,南京理工大學博士生,主要研究方向為網絡流量分析。

劉光杰(1980? ),男,江蘇徐州人,博士,南京信息工程大學教授、博士生導師,主要研究方向為信息安全、多媒體系統、深度學習。
戴躍偉(1962? ),男,江蘇鎮江人,博士,南京信息工程大學教授、博士生導師,主要研究方向為網絡與多媒體信息安全。
論文引用格式:楊路輝, 白惠文, 劉光杰, 等. 基于可分離卷積的輕量級惡意域名檢測模型[J]. 網絡與信息安全學報, 2020, 6(6): 112-120.
YANG L H, BAI H W, LIU G J, et al. Lightweight malicious domain name detection model based on separable convolution[J]. Chinese Journal of Network and Information Security, 2020, 6(6): 112-120.
2020?01?03;
2020?05?21
楊路輝,yangluhui005@foxmail.com
國家自然科學基金(U1836104)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
