基于代碼碎片化的軟件保護技術
2020-12-18 00:27:58郭京城舒輝熊小兵康緋
網絡與信息安全學報 2020年6期
關鍵詞:程序
郭京城,舒輝,熊小兵,康緋
基于代碼碎片化的軟件保護技術
郭京城,舒輝,熊小兵,康緋
(信息工程大學,河南 鄭州 450001)
針對當前軟件保護技術存在的不足,提出一種代碼碎片化技術,該技術是一種以函數為單元,對函數進行代碼shell化、內存布局隨機化、執行動態鏈接化的新型軟件保護技術,代碼shell化實現代碼碎片的位置無關變形,內存布局隨機化實現代碼碎片的隨機內存加載,動態鏈接化實現對代碼碎片的動態執行,通過上述3個環節實現對程序的碎片化處理。實驗表明,代碼碎片化技術不僅能實現程序執行過程中函數碎片內存位置的隨機化,還能實現函數碎片的動態鏈接執行,增加程序靜態逆向分析和動態逆向調試的難度,提高程序的抗逆向分析能力。
代碼碎片化;軟件保護;分離;動態鏈接
1 引言
軟件保護問題一直是計算機安全領域的重要研究課題,雖然當前的軟件保護手段能夠在一定程度上增加軟件被惡意修改和逆向分析的難度,但攻擊方可以實現對程序的結構特征進行靜態分析[1-2],也可以反復地對代碼進行逐步運行、調試、反匯編、反編譯,能夠獲取軟件在內存中的數據、執行期間的中間值,通過連續獲取系統的內存鏡像,進行前后鏡像之間的對比分析,可以獲取程序的具體行為[3]的動態分析,因此,如何有效地實現對應用程序的防破解、防盜版是一個亟待解決的問題。當前有很多軟件保護技術,代碼加殼[4]是通過對原程序的壓縮加密實現對可執行文件的保護手段,代碼虛擬化[5]是將本地指令轉換成自定義的虛擬指令,并通過虛擬解釋器解釋執行虛擬指令,實現原始程序的功能,代碼混淆[6-9]分為外形混淆、控制混淆、數據混淆和預防混淆[10-12]。在源代碼基礎上實現若干種控制混淆轉換與數據混淆轉換,通過適當插入垃圾代碼和不透明謂詞實現的改進型控制流混淆算法[13],通過增加冗余基本塊的數量和隨機下標生成實現改進型的二進制程序控制流扁平化[14],是常見的代碼混淆手段。內存布局隨機化通過不斷改變進程內存布局,實現進程攻擊面的隨機性變換,從而消除了攻擊者的不對稱優勢,增加了攻擊者的攻擊難度[15-16]。這些軟件保護技術能夠實現對代碼的保護,很大程度上增加逆向攻擊者對程序靜態分析的難度,但不能實現抗動態調試,當逆向攻擊者通過動態調試工具對保護后的代碼進行動態調試時,代碼的執行邏輯依然會被暴露,進而可以通過內存dump方法獲取完整的程序代碼。針對當前軟件保護技術在動態分析中存在的不足,提出一種基于代碼碎片化的新型軟件保護技術,該技術通過在中間語言(中間語言是一種采用靜態單賦值形式的中間表達)層面對功能函數代碼碎片進行分離,實現對代碼碎片的動態鏈接執行。該技術將功能函數的直接調用轉換成間接調用,能夠避免被完整地控制流分析,進而增加靜態分析的難度;各個函數模塊能夠加載到內存中的任意位置,有效防止程序被dump分析,增加程序動態分析的難度。
2 基本思路
代碼碎片化技術基于LLVM編譯平臺,LLVM是一系列分模塊、可重用的編譯工具鏈,它提供了一種代碼編寫良好的中間表示(IR),可以作為多種語言的后端,還可以提供與編程語言無關的優化和針對多種CPU的代碼生成功能。LLVM中間表示是一種采用靜態單賦值形式(SSA,static single assignment)的中間表達(intermediate representation),包含一套匯編語言類似的指令集和一個類型系統,該指令集是類似于RISC(reduced instruction set computer)的三地址指令集。以可移植的執行體(PE,portable executable)程序碎片化處理過程為例,說明代碼碎片化技術的原理,如圖1所示。首先,對源代碼進行shell化變形,在中間語言層面對源代碼進行相應的修改,將代碼中的所有全局變量和應用程序編程接口(API,application programming interface)函數等全局數據提取出來保存在全局數據區。然后,在中間語言層面將所有功能函數以數組的形式保存起來,并將功能函數的調用由直接調用改為間接調用的形式,添加Loader函數,負責對功能函數進行調用,同時構建功能函數的動態地址表,依據構建的函數數組將所有函數代碼碎片分離到獨立的中間語言文件中。最后,將主函數、Loader函數、全局數據區數據和分離的功能函數碎片作為一個整體進行編譯,生成類PE文件。
3 碎片化技術模型建立
代碼碎片化技術有3個階段:函數代碼shell化、函數內存布局隨機化、函數執行動態鏈接化。本文通過符號化形式建立碎片化的技術模型。
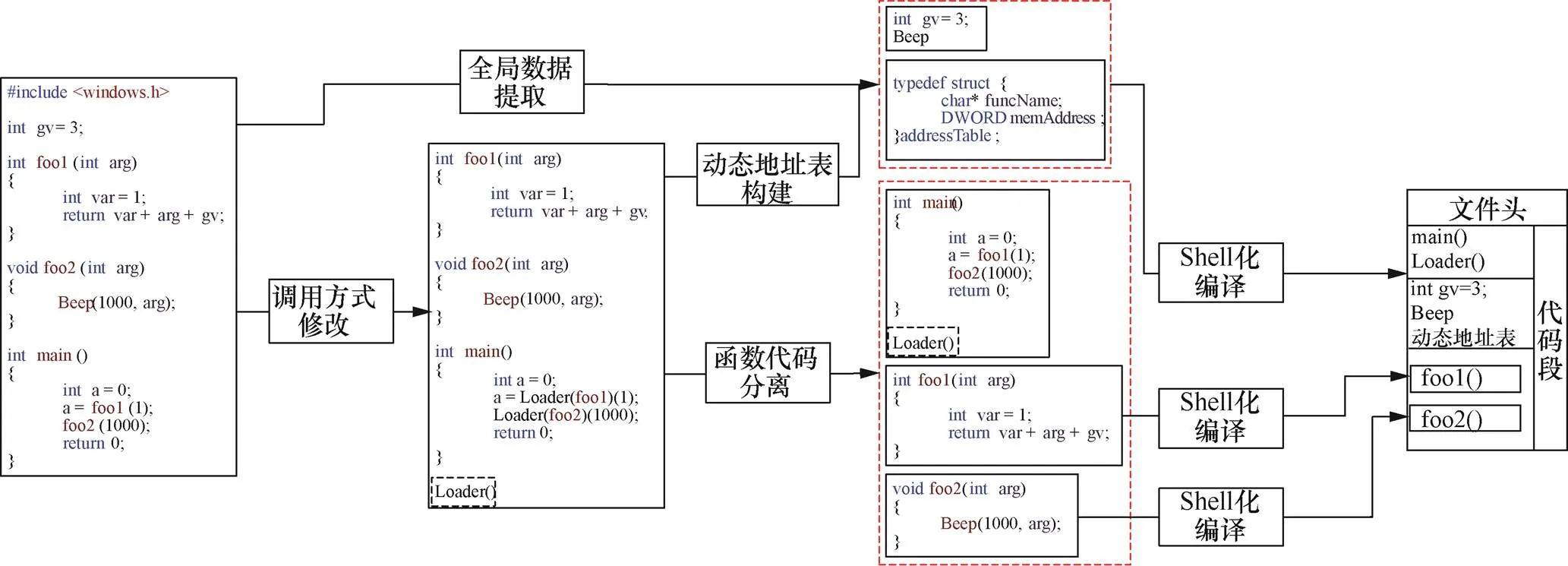
圖1 碎片化處理過程
Figure 1 The process of fragmentation

表1 函數fi中各元素定義
定義4 函數代碼shell化各映射關系定義如表2所示。

表2 代碼shell化各映射關系定義
定義7 函數執行動態鏈接化各映射關系定義如表3所示。

表3 動態鏈接化各映射關系定義
代碼碎片化模型可以形式化地表示為
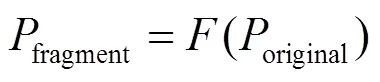
代碼碎片化由3個階段組成:函數代碼shell化,函數內存布局隨機化以及函數執行動態鏈接化。每個階段都對程序進行相應的修改,具體算法如算法1所示。首先,對中間語言IRoriginal提取API函數和全局變量;然后,對API函數調用方式和全局變量訪問方式進行修改,接著,修改函數調用方式,并將函數碎片進行分離,同時生成動態地址表;最后,通過Loader函數實現對分離的函數碎片進行調用。
算法1 代碼碎片化算法
輸入 原始中間語言文件IRoriginal
輸出 碎片化處理后的中間語言文件IRfragment
begin
2) Array
3) procedure Shell(module)
4) GetGVData(module)/*全局數據聚合*/
5) RetriveGVDataCall()/*修改全局數據調用方式*/
6) end procedure
7) procedure GetGVData(module)
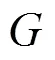
9) GV_INFO*oGV = new GV_INFO(GV);
11) API_INFO*oImportFn = new API_INFO(ImportFn);
13) end foreach
16) end procedure
17) procedure RetriveGVDataCall()
19) foreach GV_User in gv_info's Users
20) /*得到該變量在全局數據區中的位置*/;
21) var GV_Addr = CreateGetElementPtr(GlobalStruct, index)
22) /*替換原全局變量的使用 */
23) GV_User.ReplaceUseWith(GV, GV_Addr);
24) end foreach
25) end foreach
27) foreach API_User in api_info's Users
28) /*得到該變量在全局數據區中的位置*/;
29) var API_Addr = CreateGetElementPtr(GlobalStruct, index);
30) /*讀取該地址存儲的數據*/
31) var API_Addr_Value = CreateLoadMemory(API_Addr);
32) /*替換原API的使用 */
33) API_User.ReplaceUseWith (API, API_ Addr_Value);
34) end foreach
35) end foreach
36) end procedure
37) procedure Seperate(module)
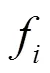
39) GenerateDynAddrTable()/*初步生成動態地址表*/
40) foreach CustomerFn in FuncInfoList
41) SeperateFragment(CustomerFn)/*分離功能函數碎片*/
42) end foreach
43) end procedure
44) procedure ModifyCallFunc(module)
45) CollectFunc(module, FuncInfoList) /*收集每個功能函數保存在結構體中*/
46) foreach CustomerFn in FuncInfoList
47) foreach UserInst in CustomerFn's Users
48) CreateCallOrInvoke(NewUserInst, Params)/*創建新的指令*/
49) UserInst.RemovefromFunction()/*刪除原指令*/
50) end foreach
51) end foreach
52) end procedure
53) procedure GenerateDynAddrTable()
54) foreach CustomerFn in FuncInfoList
55) GenerateTable(TableList) /*初步生成動態地址表*/
56) end foreach
57) end procedure
58) procedure DynamicLink()
59) addLoader()/*添加Loader函數*/
60) foreach CustomerFn in FuncInfoList
61) Loader(CustomerFn) /*動態調用功能函數*/
62) end foreach
63) end procedure
end
4 碎片化技術流程設計

圖2 碎片化技術基本流程
Figure 2 The basic process of fragmentation technology
4.1 代碼shell化變形
代碼shell化變形需要解決兩個關鍵問題。
1) 生成的碎片代碼必須具有位置無關性,即碎片代碼可以在任意內存空間中運行,碎片代碼對內存地址的引用及跳轉操作只依賴碎片代碼的基址。
2) 碎片代碼需要自行解決對外部函數的引用,即碎片代碼需要自行索引系統函數的地址。
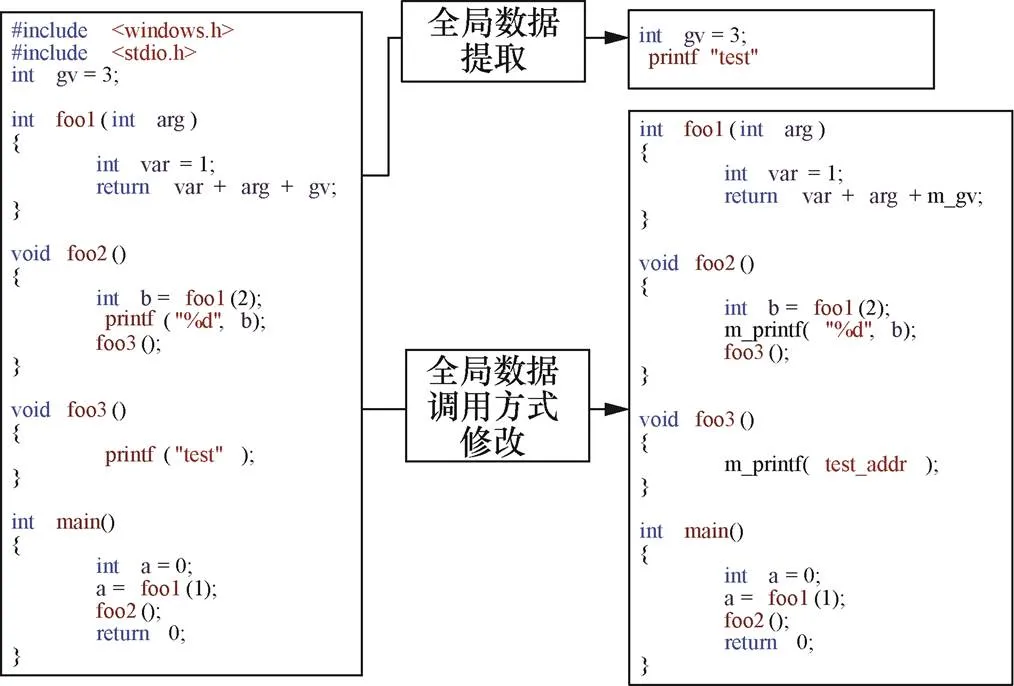
圖3 shell化變形過程
Figure 3 The process of Shell deformation
通過對IR文件的分析和變形,分別完成了全局數據區和結構體的構建、函數重定位的處理和位置無關變形。在這個過程中,生成的全局數據以內聯匯編宏代碼的方式保存在生成的頭文件中,同時引導文件內包括負責全局數據初始化和函數地址重定位的功能函數。因此,頭文件和引導文件需要同變形后的IR文件合并編譯鏈接。經過函數簽名修改后的IR文件,默認的入口函數符號已經發生變化,不再被鏈接器識別。因此,在合并編譯之前,需要新建IR文件的入口函數,該函數負責調用全局數據初始化函數和原入口函數。
4.2 函數碎片分離
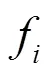
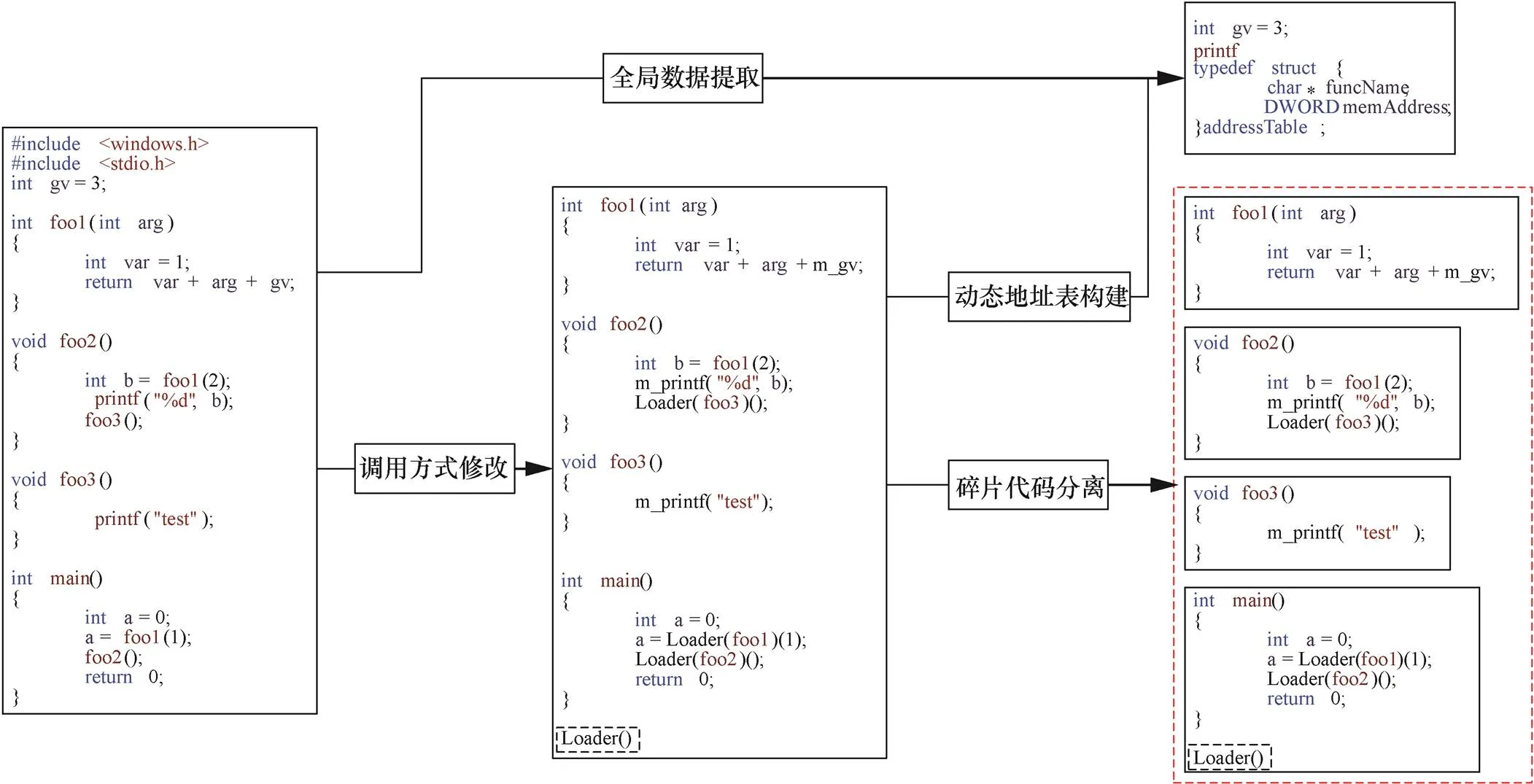
圖4 代碼碎片分離過程
Figure 4 The process of code fragmentation
算法2 功能函數分離算法
begin
1) foreach Fn in FuncList
2) SeparaeProcess(Fn)
3) end foreach
4) procedure SeparateProcess(Func)
5) if FuncCallNum>1 /*處理調用函數數量大于1的情況*/
6) separate(Func)/*分離函數*/
7) end if
8) if FuncCallNum == 1 /*處理調用函數數量等于1的情況*/
9) ParentNode = search(Func)/*回溯父節點*/
10) if ParentNode is main
11) separate(Func)
12) end if
13) if ParentNodeCallNum> 1/*處理父節點調用函數數量大于1的情況*/
14) separate(ParentNode& &Func)/*分離父節點與其子節點*/
15) end if
16) if ParentNodeCallNum == 1
17) SeparateProcess(ParentNode) /*遞歸處理*/
18) end if
19) end if
20) end procedure
end
4.3 碎片代碼執行時動態鏈接
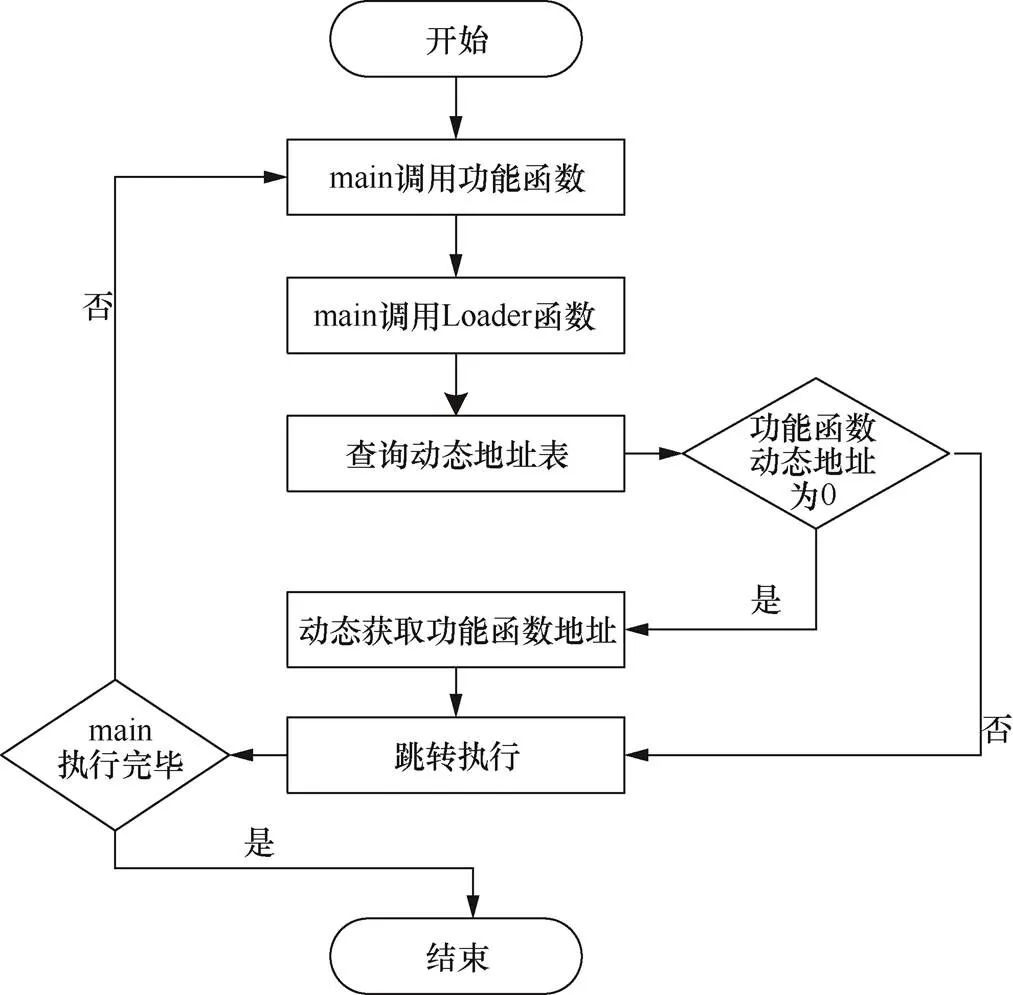
圖5 功能函數調用流程
Figure 5 The process of function call
5 原型系統
根據代碼碎片化技術設計流程,設計實現了代碼碎片化原型系統,如圖6所示,該系統主要由3個模塊組成:代碼shell化變形模塊、代碼碎片分離模塊和代碼碎片動態鏈接模塊。
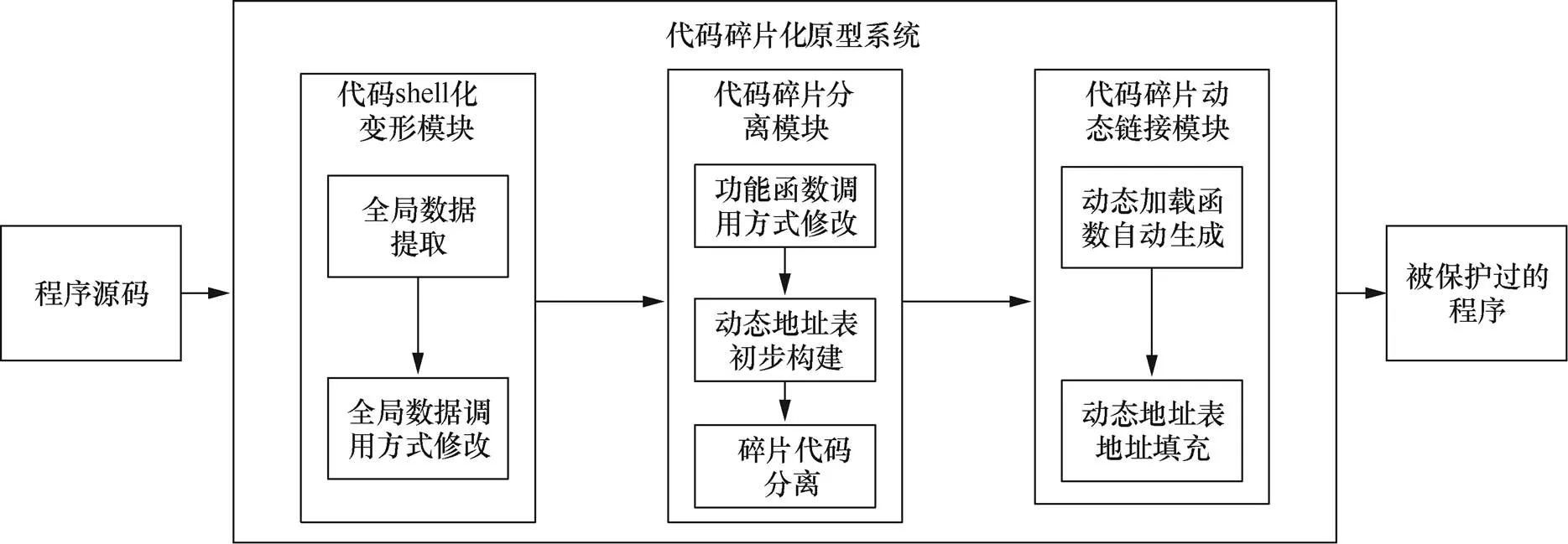
圖6 代碼碎片化原型系統
Figure 6 Code fragmentation prototype system
代碼shell化模塊實現對程序源碼中的全局數據進行提取,保存到統一的全局數據區中,并實現對全局數據引用方式修改,在全局數據區中通過“地址+索引”的方式實現對全局數據的引用。
代碼碎片分離模塊實現對功能函數代碼碎片的分離,是原型系統的關鍵。首先,在中間語言層面通過LLVM接口獲取所有功能函數,并修改對功能函數的調用方式,由直接調用修改為間接調用;然后,根據功能函數列表構建動態地址表;最后,通過LLVM編譯平臺將功能函數實體分離為代碼碎片,寫入獨立的中間語言文件中。
代碼碎片動態鏈接模塊完成代碼碎片的動態鏈接,這需要在主函數之外自動添加一個Loader加載函數,負責對分離后的代碼碎片進行動態調用,同時實現對動態地址表的動態填充。
6 實驗
代碼碎片化技術實現了對PE文件的結構布局的改變,通過該技術產生的類PE文件在代碼段中存在主函數和加載函數兩部分,其他功能函數以碎片的形式保存,通過間接調用的形式調用。因此,代碼碎片化技術能夠有效增加逆向攻擊者逆向分析的難度。目前學術界和工業界尚未提出一套合理有效的方法來評測代碼碎片化技術的強度,因此這里從程序執行的角度來說明該技術對軟件的保護效果。
本文選取實驗環境為Windows7操作系統,Intel I7 2.6 GHz CPU,4 GB內存;Windows8操作系統,Intel I7 2.6 GHz CPU,4 GB內存;Windows10操作系統,Intel I7 2.6 GHz CPU,4 GB內存。選用的測試集由rsa、rc4、MD5、aes、des、sm4、sha256、gzip、huffman、Huffcomprs這10個程序組成,測試集的基本信息如表4所示,分別記錄代碼行數、函數數量和程序功能。
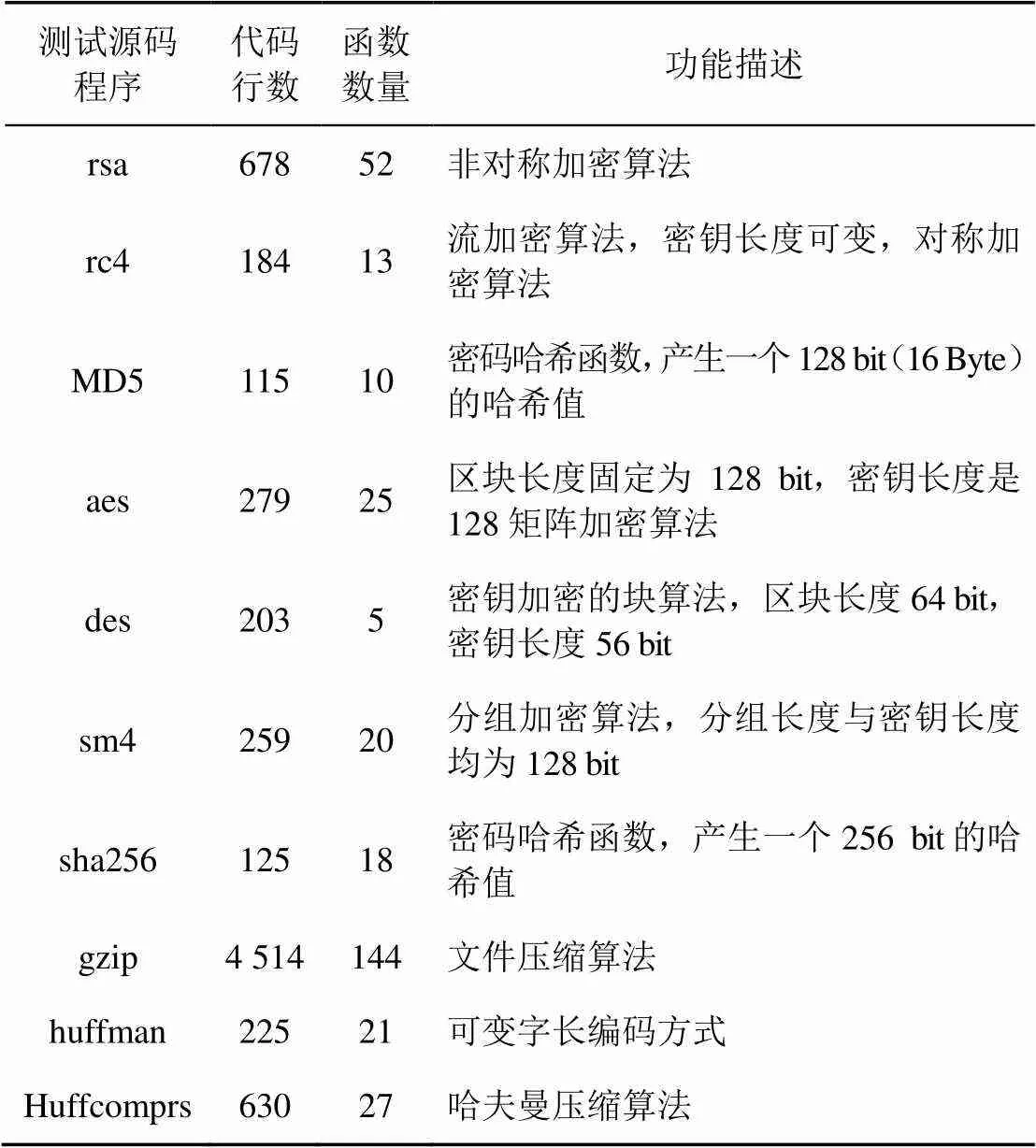
表4 測試集基本信息
對程序進行碎片化保護后需要對每個程序的可用性進行測試,分別在Windows7、Windows8、Windows10操作系統下進行測試,代碼碎片化保護之后所有程序功能均正常。
針對原型系統,采用3個指標對原型系統進行衡量,分別是導入函數變化、函數在內存中的布局與間接調用在程序中函數調用的比例。
函數導入表是記錄程序所用到的其他模塊的導出符號的地址、名稱和序號。在程序執行時導入函數是與位置有關的,代碼碎片化技術需要實現程序的位置無關化,消除導入函數的位置有關性。通過比較碎片化前后導入函數數量的變化能夠體現代碼碎片化的位置無關化,如表5所示。
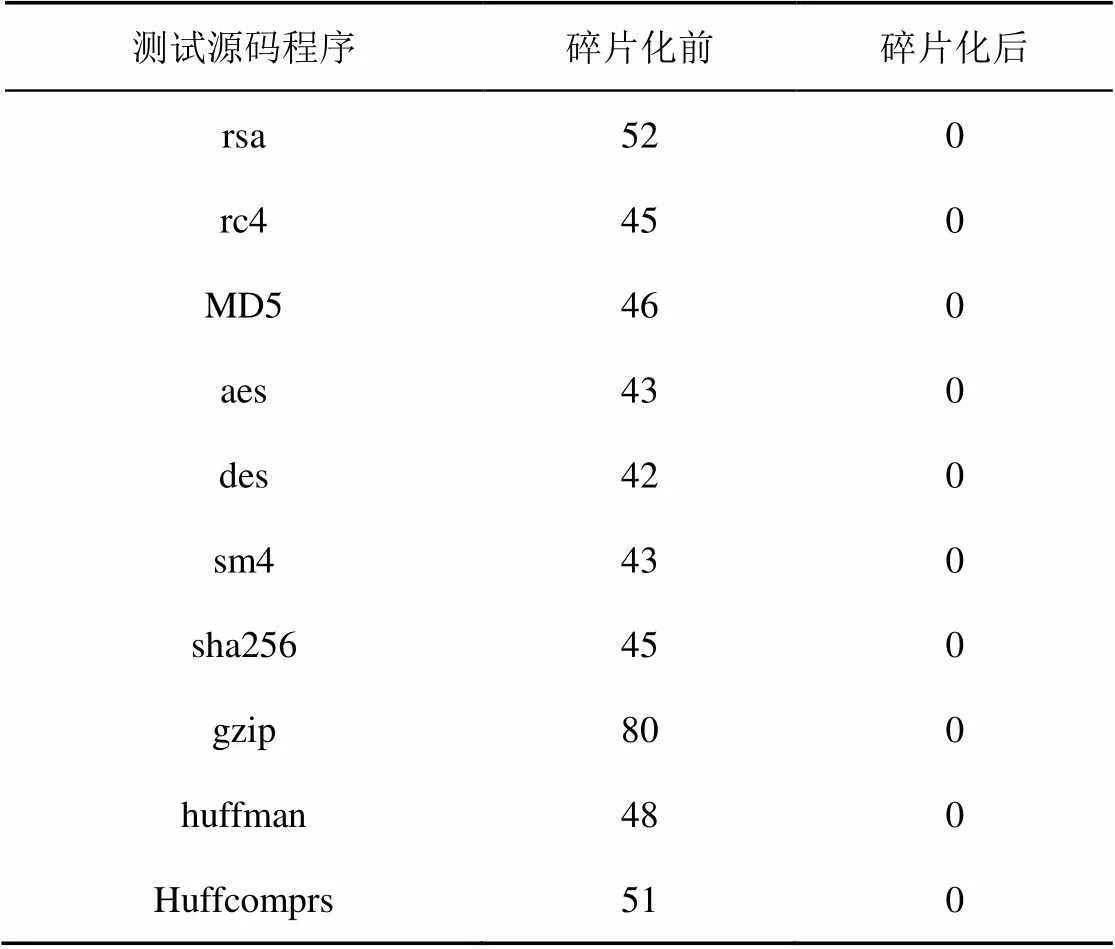
表5 導入函數數量變化
對于函數在內存中的布局,以gzip程序為例,記錄程序執行30次zip函數在內存中的加載位置,如圖7所示,zip函數在程序每次執行時在內存中的加載位置都不同,體現函數內存布局的隨機化。
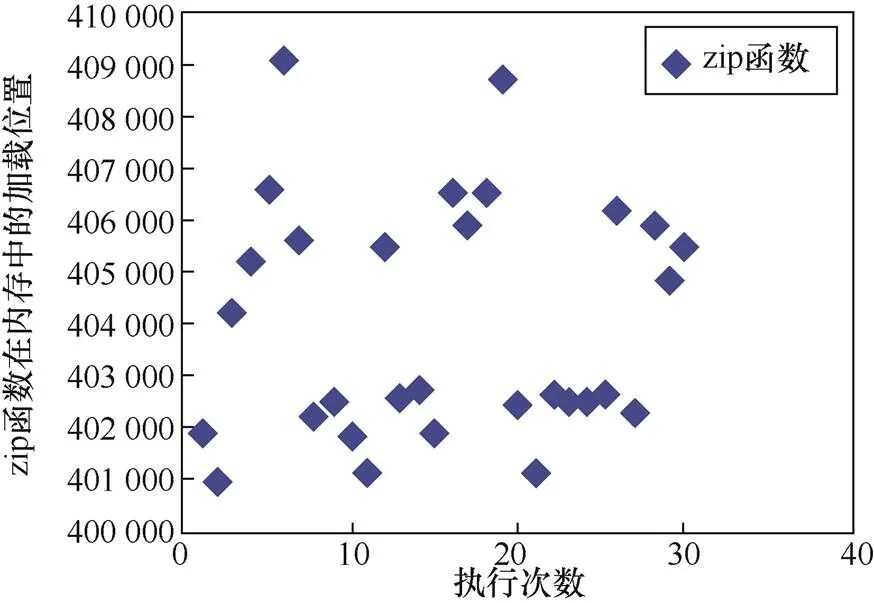
圖7 gzip程序中zip函數的內存布局
Figure 7 The memory layout of the zip function in the gzip program
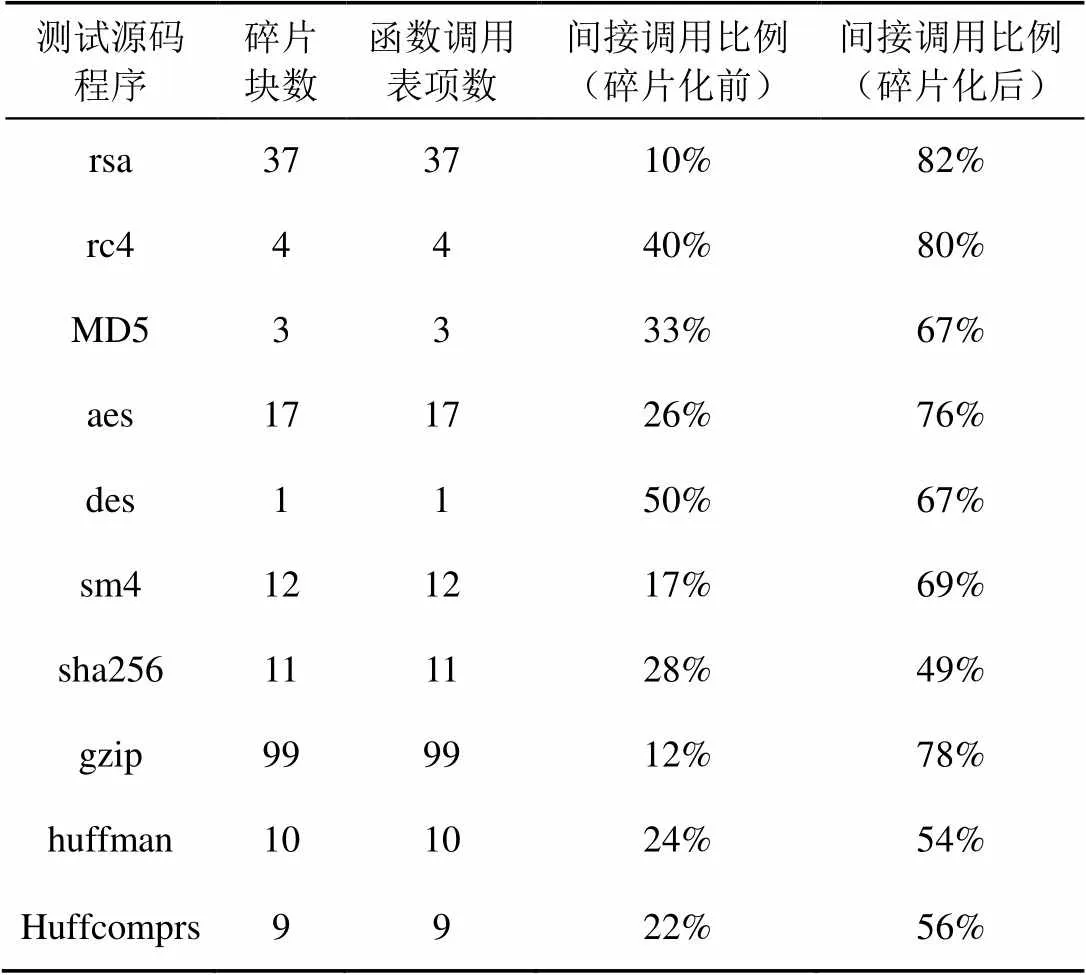
表6 程序中間接調用比例
函數碎片是在執行時通過動態鏈接的形式進行調用的,調用方式由直接調用修改為間接調用,因此,對程序進行代碼碎片化后,程序中間接調用的比例會有所增加,如圖8所示。
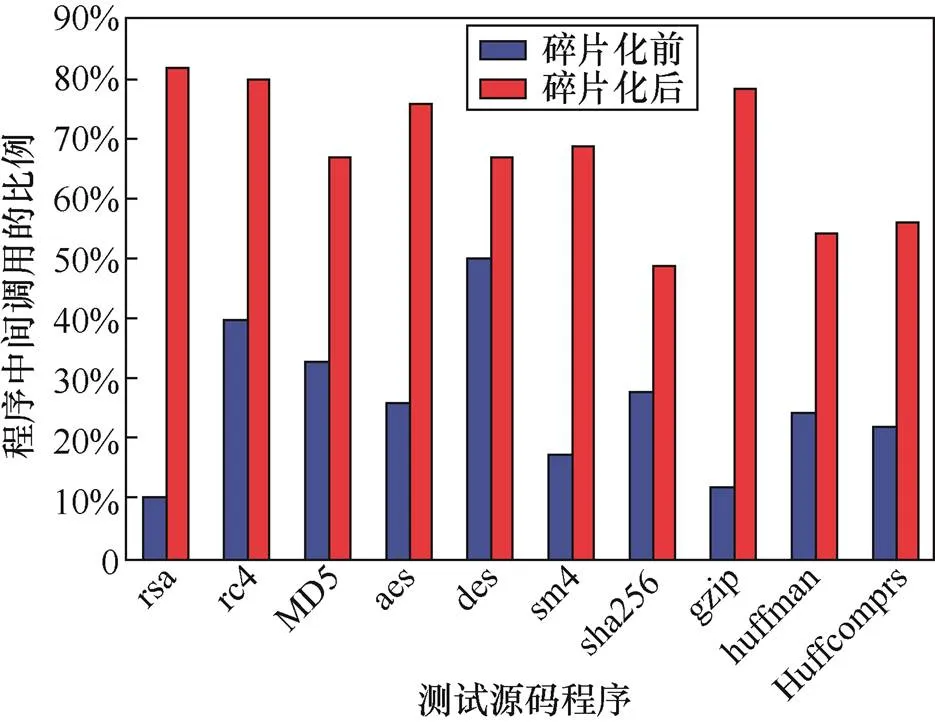
圖8 程序中間接調用比例變化
Figure 8 Changes in the proportion of indirect calls

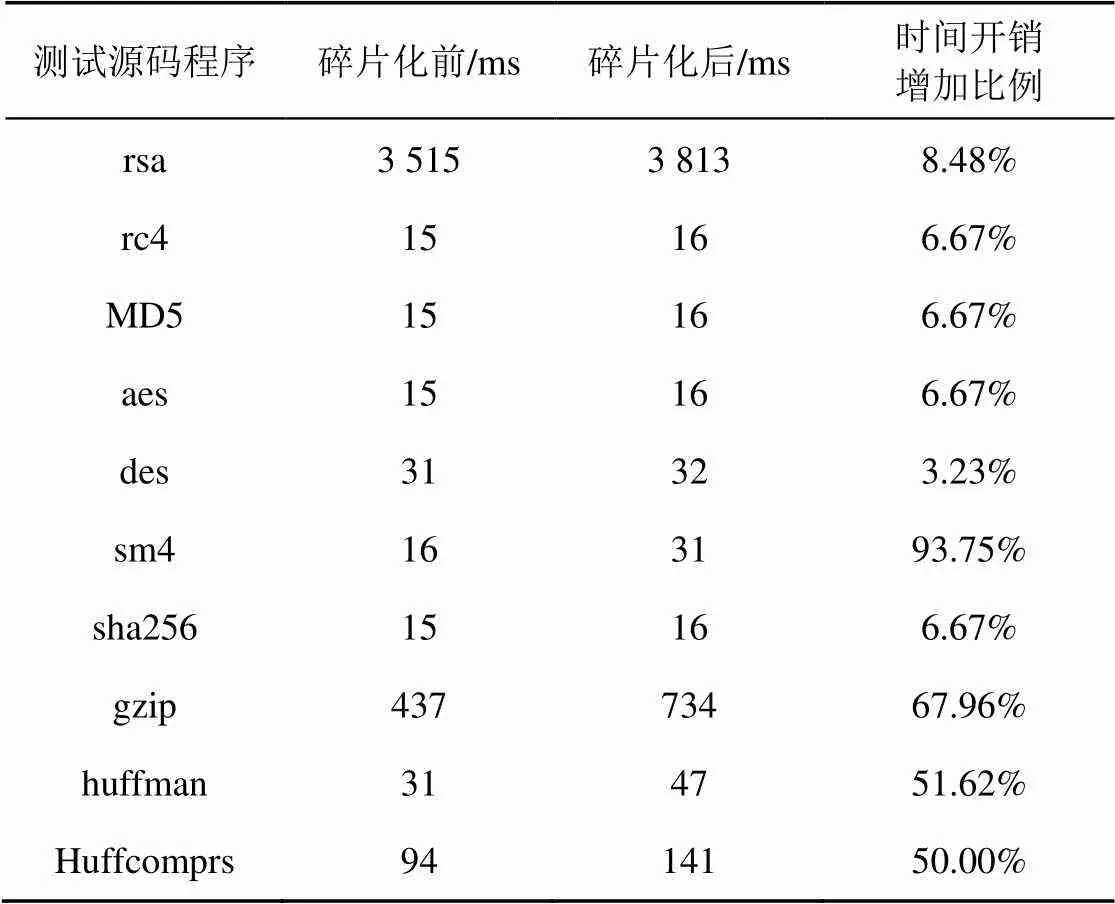
表7 碎片化前后時間開銷變化
7 結束語
代碼碎片化技術對代碼的保護是通過將功能函數分離并獨立編譯成能夠在內存中任意位置執行的碎片,通過動態加載函數碎片實現對功能函數的動態執行。攻擊者通過靜態分析碎片化保護后的程序時,只能實現對主函數和加載函數的分析,無法分析以碎片存在的功能函數。當攻擊者通過動態調試工具對程序進行動態調試時,只能跟蹤調試主函數和加載函數的控制流,無法對碎片中的控制流進行跟蹤,大大增加了程序逆向分析的難度。通過實驗分析,碎片化技術能夠實現函數碎片的內存布局隨機化,碎片化保護后的程序間接調用比例有所增加,通過將函數的直接調用修改為間接調用,能夠實現對函數碎片執行的動態鏈接。同時,代碼碎片化技術有很多不完善的地方。控制流完整性分析在程序逆向分析中具有重要作用,未來將針對模糊函數與函數之間的控制流,增加程序的控制流完整性分析的難度作進一步研究。
函數單個調用鏈的函數組采取以非內聯的形式進行處理,將每個函數單獨碎片化,將函數組中的函數內聯化為一個函數是減少程序時間開銷的有效手段,是將這些函數單獨處理的進階措施。程序因間接調用的增加而造成的攻擊面增加問題,將從兩個方面進行研究:一方面,采取隨機轉換策略,隨機選取部分函數進行碎片化,避免間接調用增加過多;另一方面,引入垃圾函數調用,平衡因碎片化而造成的間接調用比例失衡。軟件升級也是需要考慮的問題,對于以下載二進制補丁和匯編補丁的方式進行更新的軟件,需要作進一步研究。
[1] 許團, 屈蕾蕾, 石文昌. 基于結構特征的二進制代碼安全缺陷分析模型[J]. 網絡與信息安全學報, 2017, 3(9): 31-39.
XU T, QU L L, SHI W C. Analysis model of binary code security flaws based on structure characteristics[J]. Chinese Journal of Network and Information Security, 2017, 3(9): 31-39.
[2] 孫博文, 黃炎裔, 溫俏琨, 等. 基于靜態多特征融合的惡意軟件分類方法[J]. 網絡與信息安全學報, 2017, 3(11): 68-76.
SUN B W, HUANG Y Y, WEN Q K, et al. Malware classification method based on static multiple-feature fusion[J]. Chinese Journal of Network and Information Security, 2017, 3(11): 68-76.
[3] 李偉明, 鄒德清, 孫國忠. 針對惡意代碼的連續內存鏡像分析方法[J]. 網絡與信息安全學報, 2017, 3(2): 20-30.
LI W M, ZOU D Q, SUN G Z. Successive memory image analysis method for malicious codes[J]. Chinese Journal of Network and Information Security, 2017, 3(2): 20-30.
[4] 王健. 基于完整性驗證和殼的軟件保護技術研究[D]. 太原: 中北大學, 2018.
WANG J. Research on software protection technology based on in-tegrity verification and shell[D]. Taiyuan: North China University, 2018.
[5] 杜春來, 孔丹丹, 王景中, 等.一種基于指令虛擬化的代碼保護模型[J]. 信息網絡安全, 2017(2): 22-28.
DU C L, KONG D D, WANG J Z, et al. A code protection model based on instruction virtualization[J]. Netinfo Security, 2017(2): 22-28.
[6] BALACHANDRAN V, EMMANUEL S, KEONG N. Obfuscation by code fragmentation to evade reverse engineering[C]//2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC. 2014.
[7] BALACHANDRAN V, KEONG N W, EMMANUEL S. Function level control flow obfuscation for software security[C]//Eighth International Conference on Complex, Intelligence and Software Intensive Systems. 2014: 133-140.
[8] LASZLO T, KISS A. Obfuscating C++ programs via control flow flattening[R]. 2009.
[9] JUNOD P, RINALDINI J, WEHRLI J, et al. Obfusca-tor- LLVM?software protection for the masses[C]//2015 IEEE/ACM 1st International Workshop on Software Protection. 2015: 3-9.
[10] DAVIDSON J, HILL J, KNIGHT J. Protection of software-based survivability mechanisms[C]//2013 43rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). 2001: 193-193.
[11] WANG C, HILL J, KNIGHT J. Software tamper resistance: obstructing static analysis of programs[J]. 2000.
[12] WANG C.A security architecture for survivability mechanisms[D]. Virginia: University of Virginia,School of Engineering and Applied Science, 2000.
[13] 蔣華, 劉勇, 王鑫. 基于控制流的代碼混淆技術研究[J]. 計算機應用研究, 2013, 30(3): 897-899.
JIANG H, LIU Y, WANG X. Code confusion technology research based on control flow[J]. Application Research of Computers, 2013, 30(3): 897-899.
[14] 王旭. 基于目標代碼的控制流混淆技術研究[D]. 北京: 北京郵電大學, 2013.
WANG X. Research on control flow obfuscation technology based on object code[D]. Beijing: Beijing University of Posts and Telecommunications, 2013.
[15] 王豐峰, 張濤, 徐偉光, 等. 進程控制流劫持攻擊與防御技術綜述[J]. 網絡與信息安全學報, 2019, 5(6): 10-20.
WANG F F, ZHANG T, XU W G, et al. Overview of control-flow hijacking attack and defense techniques for process[J]. Chinese Journal of network and information security, 2019, 5(6): 10-20.
[16] 喬向東, 郭戎瀟, 趙勇. 代碼復用對抗技術研究進展[J]. 網絡與信息安全學報, 2018, 4(3): 1-12.
QIAO X D, GUO R X, ZHAO Y. Research progress in code reuse attacking and defending[J]. Chinese Journal of Network and Information Security, 2018, 4(3): 1-12.
Software protection technology based on code fragmentation
GUO Jingcheng, SHU Hui, XIONG Xiaobing, KANG Fei
Information Engineering University, Zhengzhou 450001, China
Aiming at the shortcomings of the current software protection technology, a code fragmentation technology was proposed. This technology is a new software protection technology that takes functions as units, shells functions, randomizes memory layout, and performs dynamic linking. The code shellization realizes the position-independent morphing of code fragments, the memory layout randomizes the random memory loading of the code fragments, the dynamic linking realizes the dynamic execution of the code fragments, and the program fragmentation processing is achieved through the above three links. The experiments show that the code fragmentation technology can not only realize the randomization of the memory location of function fragments during program execution, but also the dynamic link execution of function fragments, increasing the difficulty of static reverse analysis and dynamic reverse debugging of the program, and improving the anti-reverse analysis ability of the program.
code fragmentation, software protection, separation, dynamic linking
The National Key R&D Program of China (2016YFB08011601)
TP309.5
A
10.11959/j.issn.2096?109x.2020063

郭京城(1994? ),男,山東濟南人,信息工程大學碩士生,主要研究方向為網絡安全與軟件保護。
舒輝(1974? ),男,江蘇鹽城人,博士,信息工程大學教授、博士生導師,主要研究方向為網絡安全、嵌入式系統分析與信息安全。

熊小兵(1985? ),男,江西豐城人,博士,信息工程大學副教授,主要研究方向為網絡安全。
康緋(1972? ),女,河南周口人,碩士,信息工程大學教授,主要研究方向為網絡信息安全。
論文引用格式:郭京城, 舒輝, 熊小兵, 等. 基于代碼碎片化的軟件保護技術[J]. 網絡與信息安全學報, 2020, 6(6): 57-68.
GUO J C, SHU H, XIONG X B, et al. Software protection technology based on code fragmentation[J]. Chinese Journal of Network and Information Security, 2020, 6(6): 57-68.
2019?12?05;
2020?02?21
舒輝,shuhui@126.com
國家重點研發計劃(2016YFB08011601)
猜你喜歡
電腦愛好者(2020年6期)2020-05-26 09:27:33
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
信息安全與通信保密(2016年3期)2016-08-23 01:23:56
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:34
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:25
中國衛生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
