基于集成學習的全云化健康大數據整合系統設計
2020-12-07 06:14:15張喆湯永利
現代電子技術 2020年22期
關鍵詞:數據存儲
張喆 湯永利
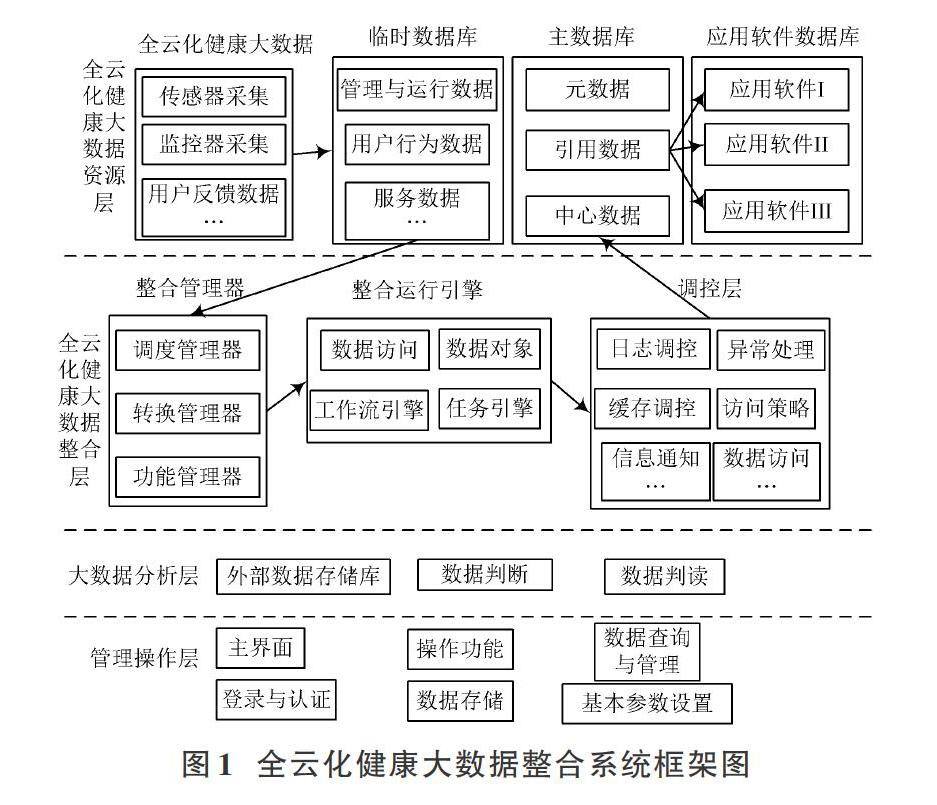

摘? 要: 設計基于集成學習的全云化健康大數據整合系統,實現健康大數據的高效率、高精度整合。管理員操作管理操作層實現系統控制、調控以及應用;大數據分析層通過ELM預測模型的參數單步預測方法獲取融合多維參數信息的健康數據預測結果,并采用Bagging集成學習方法融合ELM預測模型獲取高精度的強學習模型,實現差異多維全云化健康大數據的有效判讀;通過全云化健康大數據整合層中的整合管理器以及整合運行引擎整合健康大數據,并通過調控層將整合后的健康大數據反饋到大數據資源層中,存儲到該層中的臨時數據庫以及元數據庫中,同時這些數據庫中的數據為應用軟件數據庫提供數據調度服務。實驗結果說明,該系統整合健康大數據的整合量和整合效率高,且具有較高的空間存儲容量和并發數據處理性能。
關鍵詞: 健康大數據; 整合系統; 系統設計; 集成學習; 預測建模; 數據存儲
中圖分類號: TN919?34; TP311? ? ? ? ? ? ? ? ? 文獻標識碼: A? ? ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2020)22?0173?04
Abstract: A all?cloud health big data integration system based on integrated learning is designed to achieve the high efficiency and high precision integration of health big data. The administrator can perform operation management of the operation layer to realize the system control, regulation and application. The big data analysis layer is used to obtain the health data prediction results integrating multi?dimensional parameter information by means of the parameter single?step prediction method of the ELM prediction model, and the Bagging integrated learning method is used to integrate the ELM prediction model to obtain the high?precision strong learning model, so as to realize the effective judgment of the differentiated multi?dimensional all?cloud health big data. The integration manager and integrated running engine in the all?cloud health big data integration layer are used to integrate the health big data, and the integrated health big data is fed back to the big data layer by means of the regulating layer and stored in the temporary database and metadata database in the layer. The data in these databases is used to provide data scheduling service for the application software database. The experimental results show that the system has high integration capacity and efficiency in integrating health big data, as well as high spatial storage capacity and concurrent data processing performance.
Keywords: health big data; integration system; system design; integrated learning; prediction modeling; data storage
0? 引? 言
健康大數據(Healthy Big Data)是通過常規軟件工具在不能接收的時間界限內對數據進行采集、操控和處理的健康數據的集合[1],是隨著信息時代發展出現的新名詞,具有諸多優勢,應用范圍十分廣泛。隨著全云化時代的到來,健康大數據越來越多地和計算機組合到了一起,讓健康大數據走進每一家。因此,全云化健康大數據智能化分析方法成為相關人員研究的熱點問題。該方法無需先驗知識,分析歷史采集數據判斷規范,可實現不同類型健康大數據的有效判斷和整合。通常采用基于數據預測的全云化健康大數據智能分析方法,實現健康大數據整合。因為極限學習機(Extreme Learning Machine,ELM) 預測模型是一種新的參數訓練方法,其具有很多如訓練速度快、精度高、擁有極少參數設置等優點。集成學習(Ensemble Learning)又稱多分類器系統,其功能組成構造是通過多個學習器的組建和結合完成學習任務,具有準確性高和多樣性強等功能。集成學習應用十分廣范,如在計算機、電子醫療輔助等領域[2]。因此,本文設計的基于集成學習的全云化健康大數據整合系統,采用Bagging集成學習方法融合極限學習機(Extreme Learning Machine,ELM) 預測模型實現健康大數據的有效預測后,通過整合層和資源層,完成健康大數據的整合和存儲,本文系統不僅實現了全云化大健康數據的整合,也為今后大數據發展提供了可靠依據[3]。
2.2? 全云化健康大數據整合效率
由圖5可知,隨著實驗物流公司大數據存儲量的不斷增加,本文系統整合全云化健康大數據效率遠遠高于物聯網整合系統。本文系統整合時間在200~500 ms之間,而物聯網整合系統的整合時間在300~900 ms之間,說明本文系統整合全云化健康大數據效率較高。
2.3? 存儲空間容量對比
設置實驗兩種系統的基本存儲參數為0.83,存儲空間容量極限參考數為7.1×28 TB,在這些條件下,檢測兩種系統進行實驗物流公司2016年8—10月期間全部健康大數據整合過程中耗費的存儲空間容量情況,結果見表1。
2.4? 并發度對性能影響分析
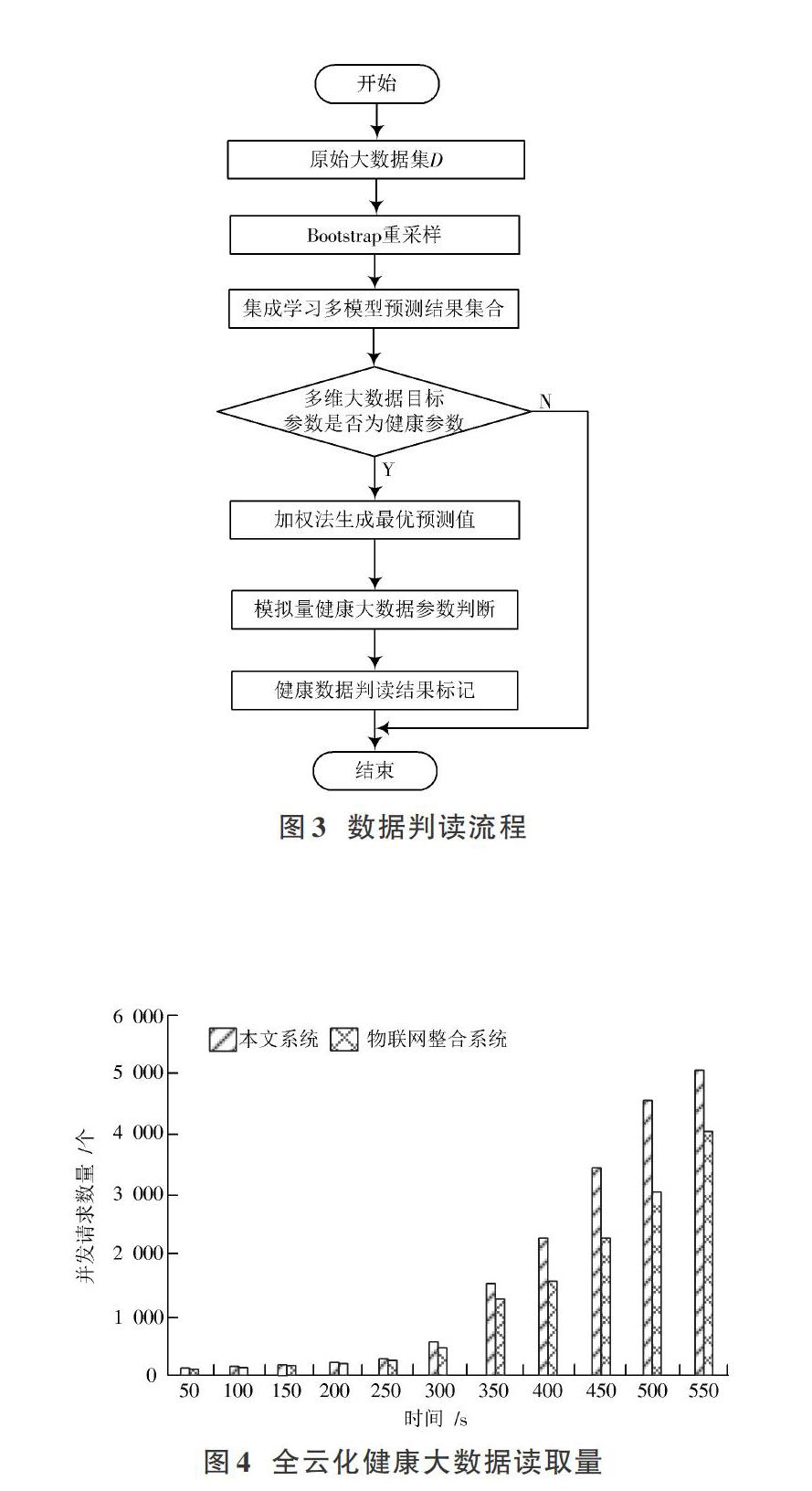
分析圖6可知,隨著時間的增加,本文系統在處理對全云化健康大數據處理性能并發數量上遠遠大于基于物聯網的健康大數據整合系統,說明本文系統對全云化健康大數據處理性能更高。
3? 結? 論
本文設計的全云化健康大數據整合系統是一個多層體系結構,通過管理操作層、大數據分析層、全云化健康大數據整合層和全云化健康大數據資源層間的協同合作,實現全云化健康大數據的有效整合。其中,大數據分析層和大數據整合層是總體系統的關鍵組成部分,分析層采用Bagging集成學習方法和ELM預測模型組成強學習方式,實現健康大數據的有效預測和判讀后,通過整合層實現健康大數據的有效整合。隨著5G時代的發展,健康大數據越來越多地呈現在人們的視野中,本文系統會讓更多的全云化健康大數據走進人們的生活中,帶給人們方便快捷的使用效果,為今后大數據的發展奠定了有效的基礎。
參考文獻
[1] 艾科,馬國帥,楊凱凱,等.一種基于集成學習的科研合作者潛力預測分類方法[J].計算機研究與發展,2019,56(7):1383?1395.
[2] 劉勝娃,蘇興華,詹勝,等.面向鉆井大數據的數據集成及分析系統的設計與實現[J].微電子學與計算機,2018,35(1):128?132.
[3] 周敏,岳麗娜.基于物聯網和云技術的橋梁結構安全信息平臺設計[J].武漢理工大學學報(信息與管理工程版),2017,39(6):765?768.
[4] 饒川,茍先太,金煒東.基于選擇性集成學習的高速列車故障識別研究[J].計算機應用研究,2018,35(5):1365?1367.
[5] 臧艷輝,趙雪章,席運江.基于MF?R和AWS密鑰管理機制的物聯網健康監測大數據分析系統[J].計算機應用研究,2019,36(7):2065?2069.
[6] 劉浩,文廣超,謝洪波,等.大數據背景下礦井水害案例庫系統建設[J].工礦自動化,2017,43(1):69?73.
[7] 劉伯德,張森.基于網絡化大數據的城市軌道交通安檢系統[J].城市軌道交通研究,2019,22(6):182?186.
[8] 李俊楠,李偉,李會君,等.基于大數據云平臺的電力能源大數據采集與應用研究[J].電測與儀表,2019,56(12):104?109.
[9] 劉洪霞,馮益明,曹曉明,等.荒漠生態系統大數據資源平臺建設與服務[J].干旱區資源與環境,2018,32(9):126?131.
[10] 韋麗華,張敏.合肥城鄉規劃數據采集及集成系統研究[J].規劃師,2018,34(z1):26?28.
[11] 李超強,侯文軍,李豪.“量化自我”?復雜信息系統人因功效評估大數據分析平臺的建設[J].中國電子科學研究院學報,2017,12(6):563?569.
[12] 歐強新,李海奎,雷相東,等.基于清查數據的福建省馬尾松生物量轉換和擴展因子估算差異解析:3種集成學習決策樹模型的比較[J].應用生態學報,2018,29(6):2007?2016.
[13] 徐禹洪,黃沛杰.基于優化樣本分布抽樣集成學習的半監督文本分類方法研究[J].中文信息學報,2017,31(6):180?189.
[14] 高慧云,陸慧娟,嚴珂,等.基于差異性和準確性的加權調和平均度量的基因表達數據選擇性集成算法[J].計算機應用,2018,38(5):1512?1516.
[15] 張燕,杜紅樂.基于異構距離的集成分類算法研究[J].智能系統學報,2019,14(4):733?742.
猜你喜歡
文理導航(2017年2期)2017-02-16 13:18:46
辦公室業務(2016年11期)2017-01-09 18:02:44
中國科技博覽(2016年24期)2016-12-28 23:25:48
電子技術與軟件工程(2016年20期)2016-12-21 11:11:51
電腦知識與技術(2016年28期)2016-12-21 10:13:14
電腦知識與技術(2016年27期)2016-12-15 20:33:05
電腦知識與技術(2016年12期)2016-06-14 19:10:43
電腦知識與技術(2016年12期)2016-06-14 01:13:57
科教導刊·電子版(2016年11期)2016-06-03 19:01:33
電腦知識與技術(2016年8期)2016-05-19 13:33:11
