基于邏輯回歸模型的缺血性腦卒中發(fā)病率預(yù)測(cè)研究*
2020-11-25 03:07:38李鵬
醫(yī)學(xué)信息學(xué)雜志 2020年6期
李 鵬
(1湖南中醫(yī)藥大學(xué)信息科學(xué)與工程學(xué)院 長(zhǎng)沙410208 2中南大學(xué)湘雅三醫(yī)院 長(zhǎng)沙410006 3醫(yī)學(xué)信息研究湖南省普通高等學(xué)校重點(diǎn)實(shí)驗(yàn)室(中南大學(xué)) 長(zhǎng)沙410006)
閔 慧
(湖南信息職業(yè)技術(shù)學(xué)院軟件學(xué)院 長(zhǎng)沙410200)
瞿昊宇
(湖南中醫(yī)藥大學(xué)信息科學(xué)與工程學(xué)院 長(zhǎng)沙410208)(醫(yī)學(xué)信息研究湖南省普通高等學(xué)校重點(diǎn)實(shí)驗(yàn)室(中南大學(xué)) 長(zhǎng)沙410006)
羅愛(ài)靜
(中南大學(xué)湘雅三醫(yī)院 長(zhǎng)沙410006)
1 引言
缺血性腦卒中是指由于腦的供血?jiǎng)用}(頸動(dòng)脈和椎動(dòng)脈)狹窄或閉塞、腦供血不足導(dǎo)致的腦組織壞死的總稱(chēng)。近年來(lái)缺血性腦卒中[1]已經(jīng)成為危害人類(lèi)健康和生命安全的重大疾病,如何有效地對(duì)缺血性腦卒中發(fā)病率進(jìn)行預(yù)測(cè),識(shí)別可能導(dǎo)致缺血性腦卒中疾病的高危因素,提高高危患者風(fēng)險(xiǎn)意識(shí),具有十分重要的意義[2]。目前臨床上用于腦卒中篩查或預(yù)測(cè)復(fù)發(fā)的相關(guān)方法較多,例如汪仁等[3]采用全國(guó)腦卒中篩查數(shù)據(jù)作為訓(xùn)練和測(cè)試數(shù)據(jù),構(gòu)建一種基于決策樹(shù)的腦卒中分級(jí)預(yù)測(cè)方法。朱千里[4]從腦卒中致病原因(是否存在心房顫動(dòng))出發(fā),采用人工神經(jīng)網(wǎng)絡(luò)對(duì)腦卒中發(fā)病率進(jìn)行預(yù)測(cè),預(yù)測(cè)結(jié)果可用于指導(dǎo)腦卒中患者的個(gè)性化治療。陳莉平等[5]根據(jù)收集的腦卒中數(shù)據(jù),構(gòu)建腦卒中大數(shù)據(jù)應(yīng)用平臺(tái),開(kāi)發(fā)基于AdaBoost的腦卒中復(fù)發(fā)預(yù)測(cè)模型對(duì)腦卒中初患人群進(jìn)行復(fù)發(fā)風(fēng)險(xiǎn)預(yù)測(cè)。本文針對(duì)現(xiàn)有方法的不足提出一種基于邏輯回歸模型的缺血性腦卒中發(fā)病率預(yù)測(cè)方法。通過(guò)收集和清洗數(shù)據(jù)、提取面向缺血性腦卒中預(yù)測(cè)特征、構(gòu)建基于邏輯回歸的模型等過(guò)程來(lái)實(shí)現(xiàn)缺血性腦卒中發(fā)病率的預(yù)測(cè),最后通過(guò)仿真實(shí)驗(yàn)驗(yàn)證方法的有效性。
2 基于邏輯回歸的缺血性腦卒中發(fā)病率預(yù)測(cè)
2.1 具體流程(圖1)
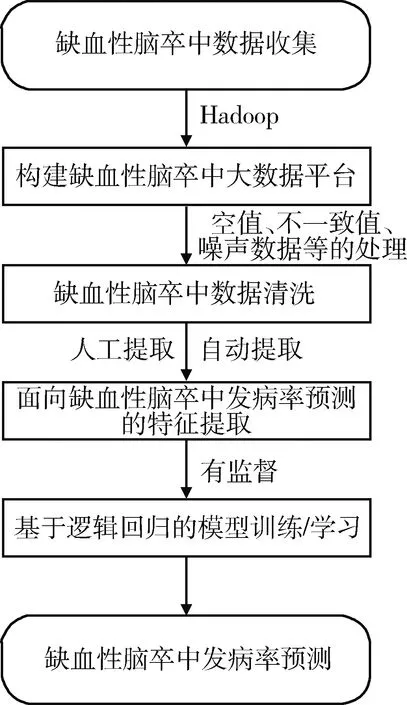
圖1 基于邏輯回歸的腦卒中預(yù)測(cè)流程
2.2 數(shù)據(jù)收集和平臺(tái)構(gòu)建
首先利用數(shù)據(jù)接入及導(dǎo)入工具對(duì)分散在基地醫(yī)療機(jī)構(gòu)、社區(qū)衛(wèi)生中心、保健機(jī)構(gòu)、體檢機(jī)構(gòu)和三甲醫(yī)院等各級(jí)機(jī)構(gòu)中的患者信息進(jìn)行采集和集成,最終形成缺血性腦卒中患者病歷信息庫(kù)。采集內(nèi)容涉及患者個(gè)人信息、既往史、家族史、住院診療數(shù)據(jù)、階段性隨訪(fǎng)數(shù)據(jù)、體檢數(shù)據(jù)等。在數(shù)據(jù)收集的基礎(chǔ)上,采用Hadoop[6]作為基本的分布式執(zhí)行架構(gòu),在該架構(gòu)上配置Python與Spark等分析工具,構(gòu)建集腦卒中患者數(shù)據(jù)采集、存儲(chǔ)、分析、模型學(xué)習(xí)、疾病診治等功能一體化的大數(shù)據(jù)平臺(tái),見(jiàn)圖2。
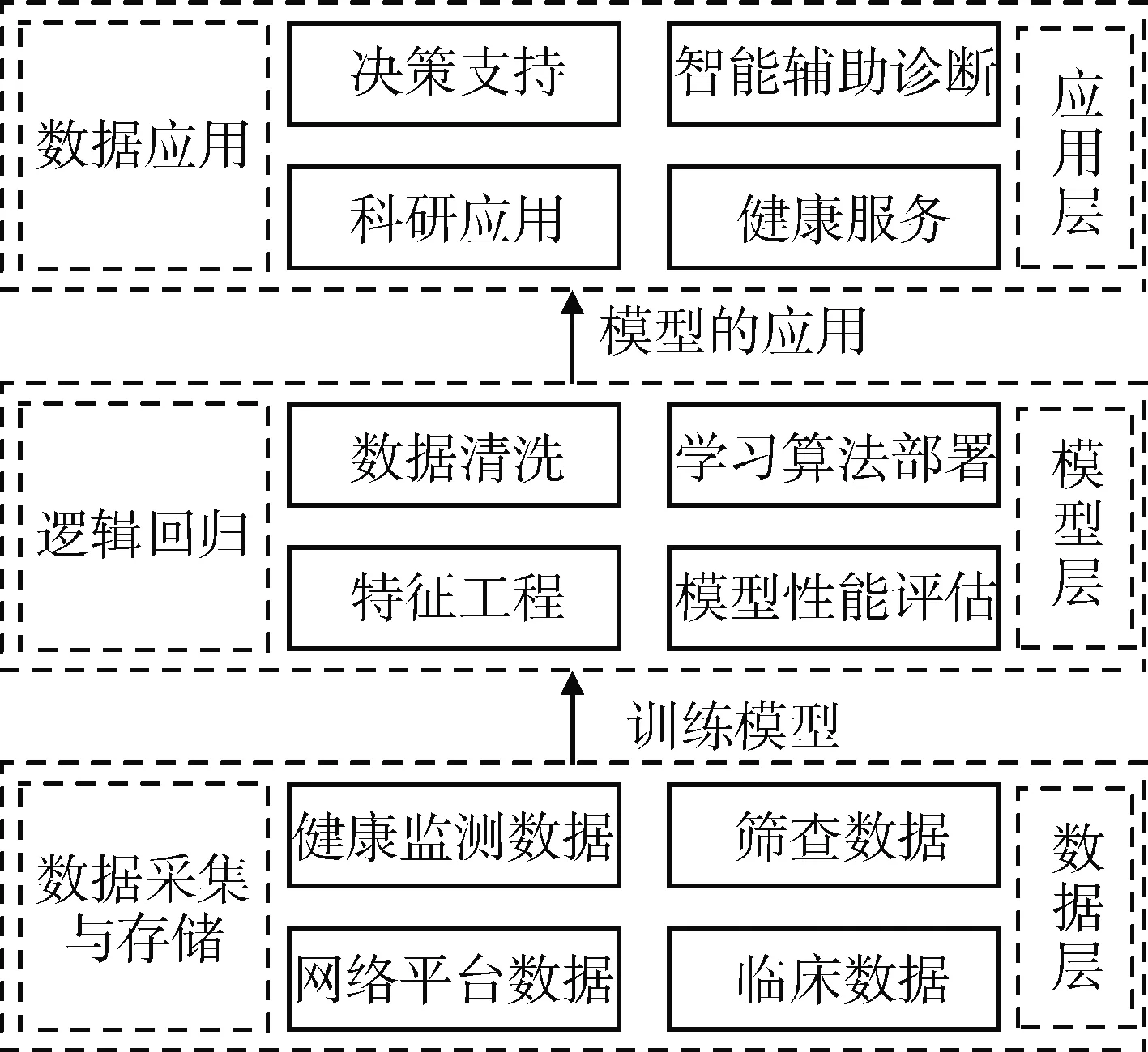
圖2 缺血性腦卒中大數(shù)據(jù)平臺(tái)
2.3 數(shù)據(jù)清洗
腦卒中管理數(shù)據(jù)來(lái)源廣泛,形式多樣,涉及種類(lèi)很多,且由于受到篩查對(duì)象主觀性、時(shí)間限制、信息獲取成本高等因素影響,收集到的腦卒中大數(shù)據(jù)經(jīng)常存在空值、不一致、噪聲數(shù)據(jù)等。因此需要對(duì)這些數(shù)據(jù)進(jìn)行預(yù)處理以提高后續(xù)預(yù)測(cè)方法的準(zhǔn)確性。其中空值數(shù)據(jù)對(duì)于算法的影響很大,采用刪除包含空值的記錄、自動(dòng)和手工補(bǔ)全缺失值等方法處理;對(duì)于不一致數(shù)據(jù),則在分析產(chǎn)生原因的基礎(chǔ)上利用各種變換、格式化、匯總分解函數(shù)實(shí)現(xiàn)數(shù)據(jù)清洗;對(duì)于噪聲數(shù)據(jù),采用分箱、計(jì)算機(jī)與人工檢查相結(jié)合和聚類(lèi)3種方法處理。
2.4 特征提取
2.4.1 概述 實(shí)證研究和相關(guān)統(tǒng)計(jì)表明[7]目前影響缺血性腦卒中發(fā)病的高危因素包括:年齡、遺傳、高血壓、高血脂、高血糖、心臟病、不良飲食、缺乏運(yùn)動(dòng)、吸煙、酗酒。從預(yù)處理后的腦卒中數(shù)據(jù)集中提取上述10種因素作為特征來(lái)進(jìn)行模型訓(xùn)練。考慮到基于邏輯回歸模型的輸入一定是數(shù)值類(lèi)型,而提取的10個(gè)特征中大部分是字符串類(lèi)型,需要將字符串類(lèi)型轉(zhuǎn)換成數(shù)值類(lèi)型,如向量、矩陣或張量形式。一般而言常見(jiàn)特征可以分為類(lèi)別和數(shù)值型特征兩大類(lèi)。其中對(duì)于類(lèi)別特征,使用獨(dú)熱編碼[8]技術(shù)將其轉(zhuǎn)換為數(shù)值類(lèi)型后再作為模型的輸入。對(duì)于數(shù)值型特征,直接對(duì)其進(jìn)行特征歸一化后將其作為模型的輸入。
2.4.2 特征編碼 將分類(lèi)特征表示為二進(jìn)制向量,又稱(chēng)一位有效編碼,其方法是使用N位狀態(tài)寄存器來(lái)對(duì)N個(gè)狀態(tài)進(jìn)行編碼,每個(gè)狀態(tài)都有獨(dú)立的寄存器位,在任意時(shí)間其中只有一位有效。提取的10個(gè)特征中遺傳、心臟病、不良飲食、缺乏運(yùn)動(dòng)、吸煙和酗酒6個(gè)特征屬于類(lèi)別特征,需要對(duì)其進(jìn)行獨(dú)熱編碼后再作為模型的輸入。編碼過(guò)程,見(jiàn)圖3。
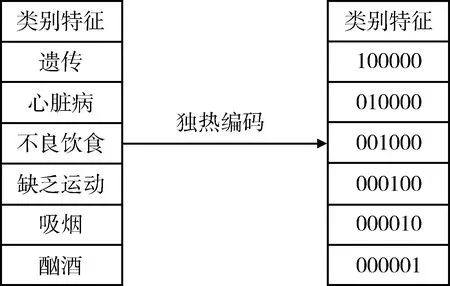
圖3 獨(dú)熱編碼
2.4.3 特征歸一化 提取的10個(gè)特征中年齡、高血壓、高血脂和高血糖4個(gè)特征屬于數(shù)值類(lèi)特征,對(duì)其進(jìn)行特征歸一化處理,以提高模型精度和訓(xùn)練過(guò)程中算法的收斂速度。采用兩種常見(jiàn)的特征歸一化方法:線(xiàn)性歸一化和標(biāo)準(zhǔn)差標(biāo)準(zhǔn)化。其中線(xiàn)性歸一化是指將特征值范圍映射到[0,1]區(qū)間,見(jiàn)公式1;標(biāo)準(zhǔn)差標(biāo)準(zhǔn)化的方法是指將特征值映射到均值為0、標(biāo)準(zhǔn)差為1的正態(tài)分布,見(jiàn)公式2。
(1)
(2)
其中min(x)指x的最小值,max(x)指x的最大值,mean(x)指x的平均值,std(x)指x的標(biāo)準(zhǔn)差。以10個(gè)樣本的年齡特征為例,根據(jù)上述公式對(duì)其進(jìn)行特征歸一化的結(jié)果,見(jiàn)圖4。
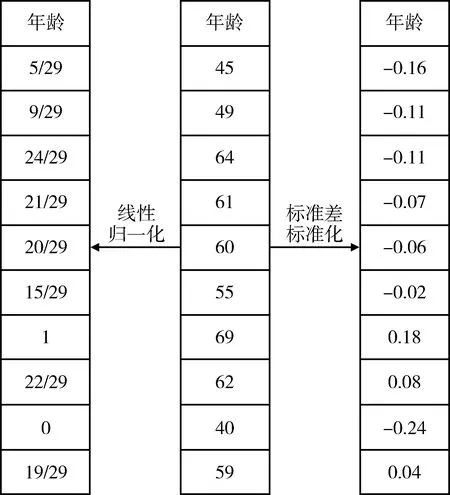
圖4 年齡特征的歸一化
2.5 基于邏輯回歸的模型訓(xùn)練
2.5.1 概述 邏輯回歸又稱(chēng)為logistic回歸分析[9],是一種廣義的線(xiàn)性回歸分析模型,常用于數(shù)據(jù)挖掘、疾病自動(dòng)診斷、經(jīng)濟(jì)預(yù)測(cè)等領(lǐng)域。以腦卒中病情分析為例,選擇兩組人群,一組是腦卒中患者組,一組是非腦卒中患者組,兩組人群必定具有不同的體征與生活方式等。因變量為是否患上腦卒中,值為“是”或“否”;自變量為上述影響腦卒中發(fā)病的10大特征。自變量可以是連續(xù)或是分類(lèi)的,通過(guò)logistic回歸分析可以得到自變量最優(yōu)權(quán)重,從而準(zhǔn)確預(yù)測(cè)不同人群患腦卒中的可能性。
2.5.2 確定目標(biāo)函數(shù) 首先基于邏輯回歸模型將缺血性腦卒中發(fā)病率預(yù)測(cè)問(wèn)題采用以下數(shù)學(xué)表達(dá)式進(jìn)行建模:
(3)
其中y指待觀測(cè)個(gè)體患上缺血性腦卒中的概率,是一個(gè)Sigmoid函數(shù)[10],采用該函數(shù)的意義在于不管影響腦卒中的因素有多少,最終得到的是一個(gè)關(guān)于缺血性腦卒中發(fā)病率的取值在[0,1]之間的概率。x1,x2,...,x10指影響缺血性腦卒中發(fā)病的10大特征,θ是權(quán)重參數(shù)。為使預(yù)測(cè)結(jié)果與真實(shí)結(jié)果的誤差最小化,采用最小化均方誤差[11]作為邏輯回歸的損失函數(shù),從而得到本研究預(yù)測(cè)問(wèn)題的優(yōu)化目標(biāo)為:
(4)
其中m是樣本的規(guī)模;yθ(x(i))是對(duì)第i個(gè)樣本進(jìn)行訓(xùn)練得到的預(yù)測(cè)結(jié)果;y(i)是第i個(gè)樣本的真實(shí)結(jié)果(標(biāo)簽)。要構(gòu)建準(zhǔn)確的缺血性腦卒中發(fā)病率預(yù)測(cè)模型,即要求解得到式(4)中的參數(shù)θ的最優(yōu)值。
2.5.3 模型求解 為求解式(4)的優(yōu)化問(wèn)題,常采用最小二乘法,將求解式(4)的優(yōu)化問(wèn)題轉(zhuǎn)化為求函數(shù)極值問(wèn)題,但這種做法并不適合計(jì)算機(jī)。為此采用小批量梯度下降法(Mini-batch Gradient Descent,MBGD)[12]進(jìn)行模型求解。該方法訓(xùn)練過(guò)程比較快,且能保證最終參數(shù)訓(xùn)練的準(zhǔn)確率。特點(diǎn)是每次訓(xùn)練迭代在訓(xùn)練集中隨機(jī)采樣M個(gè)樣本,其數(shù)學(xué)表達(dá)式為:
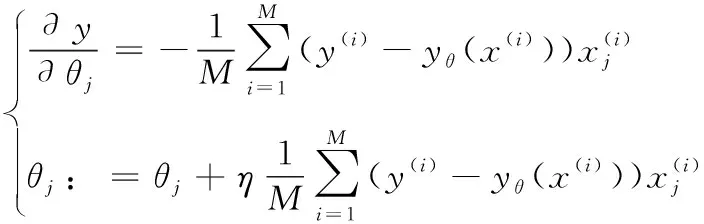
(5)
3 實(shí)驗(yàn)
以獲取到的全國(guó)2012-2018年缺血性腦卒中院外篩查數(shù)據(jù)作為研究對(duì)象,覆蓋全國(guó)31個(gè)省市自治區(qū)總計(jì)454個(gè)篩查點(diǎn),隨機(jī)選定城鄉(xiāng)社區(qū)的40歲及以上常駐人群進(jìn)行社區(qū)整群抽樣獲得數(shù)據(jù)。截至目前累計(jì)收集并存儲(chǔ)近700萬(wàn)人的院外篩查檔案。本文從這些檔案數(shù)據(jù)中隨機(jī)抽樣50 000條檔案作為數(shù)據(jù)集。其中70%數(shù)據(jù)集為訓(xùn)練集,30%數(shù)據(jù)集為測(cè)試集。將本文提出的預(yù)測(cè)方法與決策樹(shù)算法[3]、人工神經(jīng)網(wǎng)絡(luò)算法[4]和AdaBoost算法[5]進(jìn)行性能對(duì)比,采用查準(zhǔn)率來(lái)評(píng)價(jià)各種算法性能。不同方法查準(zhǔn)率比較結(jié)果,見(jiàn)圖5。可以看出隨著數(shù)據(jù)規(guī)模的增加,4種方法的預(yù)測(cè)精度都有不同程度的上升。總的來(lái)看,本文方法的預(yù)測(cè)精度要略高于人工神經(jīng)網(wǎng)絡(luò)算法,比決策樹(shù)算法和AdaBoost算法的預(yù)測(cè)精度分別高出約18.8%和21.7%。分析原因可知:一是本文預(yù)測(cè)方法在建模過(guò)程中采用多種技術(shù)對(duì)缺血性腦卒中原始大數(shù)據(jù)進(jìn)行清洗,并對(duì)影響腦卒中的高危因素進(jìn)行分析和特征提取,將噪聲數(shù)據(jù)對(duì)模型的影響降到最低;二是對(duì)每個(gè)特征進(jìn)行特征編碼或歸一化的分類(lèi)處理,提高特征對(duì)于模型的吻合度;三是采用小批量梯度下降法在降低訓(xùn)練時(shí)間的同時(shí)進(jìn)一步保證預(yù)測(cè)準(zhǔn)確性。
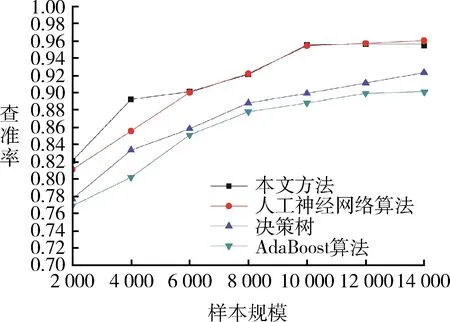
圖5 不同方法查準(zhǔn)率比較
4 結(jié)語(yǔ)
本文提出一種基于邏輯回歸模型的缺血性腦卒中發(fā)病率預(yù)測(cè)方法并通過(guò)實(shí)驗(yàn)驗(yàn)證其有效性。下一步工作中將采用深度學(xué)習(xí)技術(shù)自動(dòng)提取影響缺血性腦卒中發(fā)病的重要因素,設(shè)計(jì)一種基于圖卷積神經(jīng)網(wǎng)絡(luò)的缺血性腦卒中發(fā)病率預(yù)測(cè)方法,為醫(yī)生智能診療提供更好的技術(shù)支持。
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56

- 醫(yī)學(xué)信息學(xué)雜志的其它文章
- 醫(yī)學(xué)碩博士研究生專(zhuān)利知識(shí)和行為調(diào)查分析*
- 中醫(yī)藥院校醫(yī)學(xué)信息工程專(zhuān)業(yè)人才創(chuàng)新創(chuàng)業(yè)能力評(píng)價(jià)模型研究*
- 國(guó)內(nèi)外醫(yī)療人工智能戰(zhàn)略及細(xì)分領(lǐng)域現(xiàn)狀分析*
- 中老年慢性疾病患者健康信息素養(yǎng)現(xiàn)狀及影響因素*
- 統(tǒng)計(jì)學(xué)方法在生物信息學(xué)分析中的應(yīng)用
- 基于計(jì)算思維的地方醫(yī)學(xué)院校計(jì)算機(jī)基礎(chǔ)課程改革*