基于嵌入式NLP的鐵路車務(wù)術(shù)語語音識別方法
2020-11-25 07:59:28黃大吉林海香
蘭州交通大學(xué)學(xué)報(bào) 2020年5期
黃大吉,林海香
(蘭州交通大學(xué) 自動化與電氣工程學(xué)院,蘭州 730070)
2015年9月至2016年4月,連續(xù)發(fā)生了3起因車務(wù)值班員的操作不熟練而引起的操作違規(guī)、列車區(qū)間停車、擅自調(diào)整調(diào)度計(jì)劃等類事故,為防止此類安全事故的再次發(fā)生,2016到2017年,鐵總連續(xù)發(fā)了3個(gè)文件,明確提到車站需要配備相應(yīng)的仿真演練設(shè)備,以確保上崗車務(wù)值班員素質(zhì)達(dá)標(biāo),持證上崗.鐵路車務(wù)仿真培訓(xùn)系統(tǒng)應(yīng)運(yùn)而生,但無論是基本作業(yè)還是應(yīng)急處理,在實(shí)際工作中值班員都需要與各個(gè)崗位進(jìn)行語音交互,而現(xiàn)有仿真培訓(xùn)系統(tǒng)中都未能實(shí)現(xiàn)語音交互[1-2],語音識別的引入,可以解決這一問題.
但現(xiàn)有的語音識別軟件對車務(wù)術(shù)語的識別準(zhǔn)確率不盡人意,例如科大訊飛、百度、中科信利等,并沒有針對鐵路行業(yè)的識別庫.文獻(xiàn)[3]對比了科大訊飛、Siri、Cortana以及百度的語音識別率得分,Cortana的綜合得分最高,科大訊飛的識別率最穩(wěn)定.本文通過實(shí)際測試,運(yùn)用科大訊飛識別鐵路車務(wù)專用術(shù)語的準(zhǔn)確率僅為50%,這遠(yuǎn)遠(yuǎn)達(dá)不到要求.所以急需研發(fā)一種提高鐵路車務(wù)術(shù)語語音識別準(zhǔn)確率的方法.
自然語言處理是人工智能的一個(gè)分支,使機(jī)器像人一樣對接收到的語言進(jìn)行理解并反饋[4-5].近幾年來,NLP不斷與語音識別(automatic speech recognition,簡寫為ASR)、語音合成(text to speech,簡寫為TTS)等語音技術(shù)相互結(jié)合形成新的研究分支.文獻(xiàn)[6]設(shè)計(jì)了一種基于NLP和ASR的電信業(yè)務(wù)軟件;文獻(xiàn)[7]完成了嵌入式人機(jī)語音交互系統(tǒng)的研究,把NLP與ASR結(jié)合運(yùn)用到了服務(wù)機(jī)器人的語音交互;文獻(xiàn)[8]則把研究擴(kuò)展到了智能家居領(lǐng)域.
本文提出一種基于嵌入式NLP的鐵路車務(wù)術(shù)語語音識別方法,運(yùn)用NLP的方法來提高鐵路車務(wù)術(shù)語的ASR準(zhǔn)確率,并將嵌入式設(shè)計(jì)與傳統(tǒng)培訓(xùn)系統(tǒng)相結(jié)合,以實(shí)現(xiàn)培訓(xùn)人員與仿真系統(tǒng)的語音交互.
1 NLP簡述
NLP一般分為詞法、句法、語義、語用以及篇章分析[9].第一部分是詞法分析,包含去除停止詞、中文分詞和詞性標(biāo)注;第二部分就是利用從第一部分得出的結(jié)果理解出整個(gè)句子的框架結(jié)構(gòu)進(jìn)行句法分析;第三部分是在前兩部分的基礎(chǔ)上對輸入文本的整體意思進(jìn)行語義分析;語用和篇章分析是在第三部分的基礎(chǔ)上利用上下文或者整篇文章進(jìn)行分析.對自然語言的研究分為開放領(lǐng)域和特定領(lǐng)域,開放領(lǐng)域的研究設(shè)定可以解決任何主題的問題,本文研究的是特定領(lǐng)域,即鐵路車務(wù)用語語音識別后文本的處理,使其滿足鐵路車務(wù)術(shù)語并能被系統(tǒng)識別.
隨著NLP與ASR的越發(fā)成熟,NLP與ASR的兩個(gè)重要方向是基于PC機(jī)的大詞匯量識別和嵌入式的自然語言處理,尤其是嵌入式的自然語言處理,漸漸發(fā)展到了鐵路行業(yè).吳萍等[10]將NLP與ASR應(yīng)用于火車票查詢系統(tǒng);翁湦元等[11]設(shè)計(jì)了一種鐵路語音識別引導(dǎo)購票系統(tǒng);潘梁生[12]針對鐵路機(jī)務(wù)部門的“車機(jī)聯(lián)控”,設(shè)計(jì)了一種列車車載識別系統(tǒng).但前兩者,更多傾向于開放領(lǐng)域的識別,而后者,并未真正實(shí)現(xiàn)與列車運(yùn)行監(jiān)控裝置的聯(lián)調(diào),其準(zhǔn)確率有待進(jìn)一步考證.
把語音識別引入到了車務(wù)仿真培訓(xùn)系統(tǒng)中,但僅僅使用語音識別不能解決鐵路車務(wù)專業(yè)術(shù)語的識別率問題.針對現(xiàn)有車務(wù)仿真培訓(xùn)系統(tǒng)對標(biāo)準(zhǔn)用語的語音識別準(zhǔn)確率低的問題,本文提出了一種基于嵌入式NLP的車務(wù)術(shù)語ASR方法,將NLP與ASR、TTS等語音技術(shù)應(yīng)用到鐵路車務(wù)仿真培訓(xùn)系統(tǒng)的語音交互中,其整體流程如圖1所示.
車務(wù)值班員輸入語音,通過無線傳輸至科大訊飛云識別轉(zhuǎn)化為文字信息,然后經(jīng)過分詞,把句子切分為一個(gè)個(gè)詞串;接著進(jìn)行鐵路專有詞處理,生成符合鐵路標(biāo)準(zhǔn)用語的詞串信息;然后通過語義分析,轉(zhuǎn)化為標(biāo)準(zhǔn)的詞義塊后輸入計(jì)算機(jī)識別;最后結(jié)合TTS技術(shù)播放出來,完成語音交互.
2 嵌入式NLP算法
2.1 嵌入式技術(shù)
為了與傳統(tǒng)車務(wù)仿真培訓(xùn)系統(tǒng)更好地結(jié)合,運(yùn)用嵌入式技術(shù),設(shè)計(jì)了運(yùn)用NLP算法的車務(wù)仿真調(diào)度電話,該調(diào)度電話能直接與傳統(tǒng)仿真培訓(xùn)系統(tǒng)相連接,節(jié)約了成本.
以飛凌OK6410開發(fā)板為基礎(chǔ)搭建硬件平臺,結(jié)合Intel Loihi547文本處理芯片進(jìn)行自然語言處理,配上SYN6288語音播放芯片實(shí)現(xiàn)語音合成.OK6410開發(fā)板采用ARM11系列的S3C6410微處理器,提供了飛凌FIT-LCD4.3 LCD顯示屏、256MByte的RAM、2GByte的ROM、音頻接口、聲卡模塊、TTL電平和RS232電平的串口,支持Nand-flash和SD卡兩種啟動方式[13].硬件平臺結(jié)構(gòu)如圖2所示,語音識別模塊、自然語言處理模塊、語音合成模塊共同完成了系統(tǒng)的語音交互功能.
2.2 分詞與糾錯(cuò)算法
1) 基于詞典的改進(jìn)正向最大匹配分詞算法
分詞是NLP的基礎(chǔ),提高分詞的正確性與效率至關(guān)重要.研究表明[14],在非限定性領(lǐng)域,正向最大匹配的錯(cuò)誤率僅為0.5%,而應(yīng)用到鐵路行業(yè)內(nèi),其正確率將大幅提高,所以本文提出一種hash函數(shù)結(jié)合正向最大匹配的分詞算法,提高了分詞效率.
本文應(yīng)用于鐵路車務(wù)場景,為減少停止詞的數(shù)量,建立一個(gè)專用于此場景的詞典.結(jié)合《鐵路技術(shù)管理規(guī)程》、《鐵路行車組織規(guī)則》以及收集到的車務(wù)培訓(xùn)系統(tǒng)中的規(guī)范語的正確與錯(cuò)誤語料,收錄了包含舉例車站名稱、專有名詞等在內(nèi)的2 000個(gè)詞,存入文本文檔中.為了便于詞與詞各種屬性的查詢,把文本中的詞存于內(nèi)存中,即詞庫的初始化.
定義數(shù)組dictionary[]和hash[],前者用來存放所有的詞,后者用來存放key值相同的詞,即只要key值相同的詞都存放于相同的數(shù)組hash[key]中.具體流程:
① 獲取詞庫中詞的首字w和長度L;
② 用MD5算法計(jì)算w對應(yīng)的MD5值,得出value值,即
value=MD5(w)+L;
(1)
③ 定義哈希函數(shù)key=value%n,由于本文詞庫規(guī)模相對較小,取n=300;
④ 將詞的key值存儲到相應(yīng)的hash[key]中,并重復(fù)上述過程,直到所有的詞都存儲在hash[]中.
初始化結(jié)果如圖3所示,其中:hash[i]表示第i個(gè)數(shù)組;Cij、Sij分別表示hash[i]中的第j個(gè)詞及其屬性.
通過以上的初始化,所有首字相同且字?jǐn)?shù)相同的詞都被存儲在同一鏈表中,能快速定位關(guān)鍵詞,這樣有利于縮短算法的運(yùn)行時(shí)間.改進(jìn)的分詞算法基本原理如圖4所示,具體過程如下:
a. 定義輸入:帶切分的字串T,最大詞長L;輸出:切分后的字串T’;
b. 令P指向T首部,T’初始化為空;
c. 計(jì)算length為P至T尾部的長度,如果length=0則至h,反之則下一步;
d. 在dictionary[]中搜索以P為首字的詞,如果搜索不到則將后移一位P,返回c,反之則下一步;
e. 設(shè)置最大詞長為L,當(dāng)length的值大于L時(shí),賦值length=L;
f. 在P后提取長度為length的字符串t;
g. 計(jì)算P指向的首字和長度為length的key值,在hash[key]對應(yīng)鏈表中查找字符串t,如果存在則在T’中添加t并賦予詞性,同時(shí)P后移length的長度,返回步驟b;否則令length減一,在P后提取長度為length的字串t,重復(fù)步驟g,直到length=0時(shí),將P后移1個(gè)單位,返回c;
h. 返回切分后得到的字串T’.
2) 鐵路專有詞糾錯(cuò)
引入識別可信度概念,定義百分百正確識別的詞的可信度為1,百分百錯(cuò)誤識別的詞的可信度為0,可信度的范圍為0~1,其具體值為識別正確的次數(shù)與總的識別次數(shù)的比值.通過統(tǒng)計(jì)現(xiàn)有的語音識別軟件對車務(wù)值班員口呼信息的輸出結(jié)果,可以得到比較正確的語句與大量錯(cuò)誤的訓(xùn)練語句,例如:原文為“蘭州西站,6道軌區(qū)段出現(xiàn)紅光帶,影響D1402次接車”,科大訊飛識別結(jié)果為“蘭州西站,6導(dǎo)軌/搗鬼/島柜區(qū)段出現(xiàn)虹光/宏光/鴻光帶,影響動1402次接車/街車/借車”.從中可以發(fā)現(xiàn)大都是專業(yè)詞匯或者平時(shí)交流中不常用的詞出現(xiàn)錯(cuò)誤,例如:“蘭州西站”、“出現(xiàn)”、“區(qū)段”、“影響”、“次”的識別率較高,而“道軌”、“紅光帶”、“動”、“接車”等專業(yè)詞匯或者需要特殊轉(zhuǎn)換的詞的識別率極低.考慮到鐵路領(lǐng)域標(biāo)準(zhǔn)用詞的有限性,根據(jù)語音識別結(jié)果,人為挑選識別率高的詞,其可信度均為1,識別率低的詞和其他詞,其可信度均為0.例如例子中識別結(jié)果用可信度表示為11,10110,10111110.由此,只對可信度為0的詞進(jìn)行查錯(cuò)和糾錯(cuò).
糾錯(cuò)框架如圖5所示,創(chuàng)立一個(gè)鐵路專用詞匯列表庫,其包含5個(gè)數(shù)據(jù)庫:上下詞模式庫、邊界詞庫、正確詞匯庫、錯(cuò)誤詞匯庫以及對比詞匯庫.采用模式匹配的方法對可信度為0的詞進(jìn)行糾錯(cuò),具體步驟為:
a. 通過訓(xùn)練識別后的文本和標(biāo)準(zhǔn)文本,形成糾正詞匯庫(正確詞匯庫、錯(cuò)誤詞匯庫和對比詞匯庫)和替換詞匯庫(上下詞模式庫和邊界詞庫).
b. 對于鐵路專用術(shù)語,例如“紅光帶”、“道岔”等,匹配糾正詞匯庫,然后根據(jù)三個(gè)詞匯庫之間的映射關(guān)系,保留正確詞,糾正錯(cuò)誤詞.
c. 對于特殊替換詞,例如車次號中的“D”、“Z”等以及“道軌”應(yīng)為“DG”等,繼續(xù)匹配替換詞匯庫,例如“動”的右邊界詞為數(shù)字,則替換為“D”.
2.3 語義識別
語義分析旨在系統(tǒng)考核,考核值班員與其他崗位的語音交互信息操作流程是否滿足標(biāo)準(zhǔn).現(xiàn)有的語義分析有概念從屬理論和模板匹配語義分析兩種[15].概念從屬理論認(rèn)為只要表達(dá)的語義相同即為正確,無論表達(dá)方式幾何,其由有限語義塊組成的語義表達(dá)式只有一個(gè);模板匹配語義分析是對關(guān)鍵信息進(jìn)行抽取來理解語義.本文運(yùn)用模板匹配語義分析,實(shí)現(xiàn)系統(tǒng)識別.
經(jīng)過分詞和糾錯(cuò)流程得到帶有詞性標(biāo)注的詞串,并得到一個(gè)詞的上下詞詞性與邊界詞性,系統(tǒng)運(yùn)用模板匹配語義分析,直接抽取關(guān)鍵詞信息進(jìn)行考核評判即可.例如,值班員口呼“6DG區(qū)段出現(xiàn)紅光帶”,系統(tǒng)只要能抽取到“6DG”和“紅光帶”,即系統(tǒng)認(rèn)為值班員口呼正確.
3 實(shí)驗(yàn)測試與對比分析
下文中所涉及到的實(shí)驗(yàn)指標(biāo)[16]正確率P、召回率R和綜合評價(jià)指標(biāo)F1值定義如下:
(2)
(3)
(4)
其中:N1表示實(shí)際正確識別的個(gè)數(shù);N2表示總的個(gè)數(shù);N3表示系統(tǒng)認(rèn)為正確識別的個(gè)數(shù).
由于鐵路車務(wù)術(shù)語的語料庫規(guī)模較小,本文測試時(shí)采用交叉驗(yàn)證的方法使訓(xùn)練語料達(dá)到最大化.不區(qū)分訓(xùn)練集和測試集,把500句樣本隨機(jī)分為50份,每份10句樣本,測試時(shí)把其中一份作為測試樣本,其他為訓(xùn)練樣本,統(tǒng)計(jì)各組的正確率P、召回率R和F1值.
3.1 準(zhǔn)確率測試
圖6為各系統(tǒng)識別的P、R、F1的總體分布圖.由圖6(a)和圖6(b)可知百度和科大訊飛的識別分布大都集中在45%~55%,科大訊飛的分布更為緊密,且比百度語音在更小的區(qū)間有較少的分布,說明雖然其兩者識別準(zhǔn)確率差不多,但是科大訊飛識別時(shí)有較少的語料沒有被識別出來,識別性更加穩(wěn)定,這也是本文選取科大訊飛的識別結(jié)果作為系統(tǒng)輸入的原因.從圖6(c)可以看出,傳統(tǒng)的結(jié)合了語音識別的仿真系統(tǒng)雖然準(zhǔn)確率有所提高,集中分布在60%~70%,但和百度語音識別存在相同的問題,即分布松散、在更小的區(qū)間有較多的分布,造成有較多的語料沒有被識別出來.圖6(d)為本文研究的系統(tǒng),準(zhǔn)確率有了極大的提高,集中分布在了90%~95%的區(qū)間,減少了未被識別的語料的數(shù)量,具體的識別結(jié)果見表1.
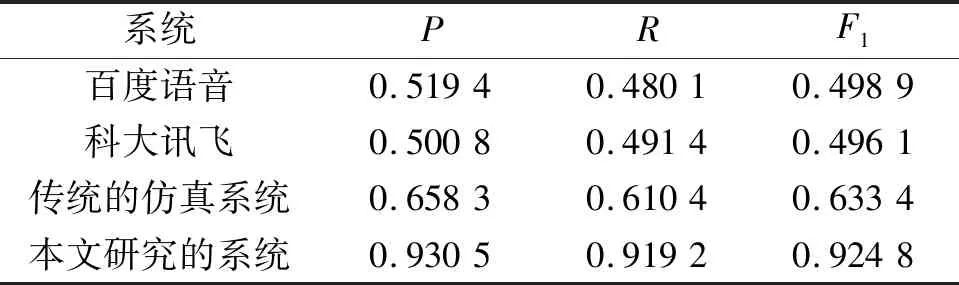
表1 各系統(tǒng)具體識別結(jié)果Tab.1 Specific identification results of each system
3.2 運(yùn)行時(shí)間測試
從語料庫中隨機(jī)選出20組來進(jìn)行運(yùn)行時(shí)間的測試,同時(shí)確保每組的總字?jǐn)?shù)大似接近.對這20組數(shù)據(jù)分別用正向最大匹配分詞算法和本文改進(jìn)的分詞算法進(jìn)行分詞,得出每組中每條語句的運(yùn)行時(shí)間,再計(jì)算平均時(shí)間,得到的結(jié)果如圖7所示.
由圖7可知,改進(jìn)的正向最大匹配分詞算法縮短了近50%的運(yùn)行時(shí)間,其中第7、9、11組運(yùn)行時(shí)間較短,通過對比語料進(jìn)行分析可得這3組中停止詞較少,因?yàn)槲锤倪M(jìn)的分詞算法出現(xiàn)一次停止詞,就要遍歷一次詞庫而進(jìn)行不必要的運(yùn)算,而改進(jìn)的正向最大匹配分詞算法,利用hash結(jié)合正向最大匹配只運(yùn)算一次就將停止詞去除,提高了算法運(yùn)行時(shí)間.對比加入人工自定義詞典后,除第2組和第8組略高外,總體運(yùn)行效率進(jìn)一步提高,原因在于本文自定義詞典時(shí),結(jié)合了收集到的車務(wù)培訓(xùn)系統(tǒng)中規(guī)范語的正確與錯(cuò)誤語料后,進(jìn)一步減少了停止詞,縮短了運(yùn)行時(shí)間.
4 案例應(yīng)用
將基于嵌入式NLP的鐵路車務(wù)術(shù)語語音識別方法運(yùn)用于哈爾濱南上行發(fā)車場道岔區(qū)段紅光帶的接車作業(yè)培訓(xùn).車務(wù)培訓(xùn)系統(tǒng)通過TDCS(train dispatching command system)下發(fā)調(diào)度命令,聯(lián)鎖場景布置,TDCS下發(fā)接車命令,值班員收到接車命令排列進(jìn)路,發(fā)現(xiàn)6號道岔區(qū)段顯示紅光帶,通過調(diào)度電話,向助理值班員通話檢查6DG紅光帶.接著值班員與電務(wù)、工務(wù)通話,分析6DG區(qū)段紅光帶的原因,并給出應(yīng)急處理,系統(tǒng)實(shí)時(shí)記錄值班員操作記錄與語音交互信息,最后系統(tǒng)判分,給出培訓(xùn)建議,系統(tǒng)截圖如圖8所示.
對比現(xiàn)有的僅加入了語音識別的車務(wù)仿真培訓(xùn)系統(tǒng),從圖9中看到,傳統(tǒng)系統(tǒng)語音識別為“6導(dǎo)軌區(qū)段出現(xiàn)宏光帶”,出現(xiàn)了“導(dǎo)軌”和“宏光”這兩個(gè)不符鐵路術(shù)語的詞,而本系統(tǒng)通過自然語言處理后識別為“6DG區(qū)段出現(xiàn)紅光帶”,可以看到,不僅把“導(dǎo)軌”和“宏光”這兩個(gè)詞正確識別了,還把“道軌”替換為了“DG”,更加符合鐵路標(biāo)準(zhǔn)用語.
運(yùn)用本文方法的車務(wù)仿真調(diào)度電話系統(tǒng)已在哈爾濱、西安、成都等多個(gè)車站的職教中心投入使用.主要用于車務(wù)值班員、助理值班員、信號員等崗位培訓(xùn),在部分車站作為選拔車務(wù)作業(yè)崗位人員的輔助系統(tǒng).
5 結(jié)論
針對應(yīng)用于非特定行業(yè)的語音識別軟件對鐵路車務(wù)術(shù)語識別準(zhǔn)確率低的問題,本文提出了一種基于自然語言處理的車務(wù)術(shù)語語音識別方法,通過實(shí)驗(yàn)分析,得出以下結(jié)論:
1) 該方法以科大訊飛云識別的識別結(jié)果為輸入,經(jīng)過改進(jìn)的分詞算法、車務(wù)術(shù)語庫糾錯(cuò)以及模板匹配的語義分析,輸出最后結(jié)果,并將嵌入式設(shè)計(jì)直接與傳統(tǒng)系統(tǒng)結(jié)合,節(jié)約了成本.
2) 相比于傳統(tǒng)的帶語音識別系統(tǒng)63.34%的識別率,運(yùn)用本文方法的系統(tǒng)則為92.48%,識別率提高了29.14%.
3) 提出改進(jìn)的正向最大匹配分詞算法,利用hash結(jié)合正向最大匹配只遍歷一次就將停止詞去除,提高了算法運(yùn)行時(shí)間.
由于本文的語料規(guī)模較小,需要不斷地?cái)U(kuò)充具有廣泛代表性的語料庫,進(jìn)而提出更高效的標(biāo)注方法.
猜你喜歡
云南畫報(bào)(2021年12期)2021-03-08 00:50:54
開放教育研究(2020年2期)2020-03-31 01:54:14
鐵道通信信號(2018年7期)2018-08-29 01:17:04
鐵道通信信號(2018年2期)2018-04-18 12:18:23
電鍍與環(huán)保(2016年3期)2017-01-20 08:15:32
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
通信電源技術(shù)(2016年4期)2016-04-04 02:58:04
工程建設(shè)與設(shè)計(jì)(2016年3期)2016-02-27 10:50:46
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
單片機(jī)與嵌入式系統(tǒng)應(yīng)用(2014年9期)2014-03-11 15:35:13
