運營商網絡監控系統高可用性設計及應用①
2020-11-24 05:46:18袁守正
計算機系統應用 2020年11期
吳 舸,袁守正,孫 鼎
(中國電信上海理想信息產業(集團)有限公司,上海 201315)
中國電信NetCare 服務,是利用中國電信統一建立的基于通用網絡監控技術和專用探針技術的監控平臺,對包括客戶端網絡設備、云端應用及虛擬資源、專線及互聯網線路提供端到端監控和管理的業務,其界面如圖1、圖2所示.該業務面向中國電信政企客戶提供服務,監控了大量的客戶設備以及相關的線路資源,對于系統的可用性要求為99.99%.基于安全方面的考慮,企業的網絡監控系統基本采用自建的方式,其架構設計是以有限的監控對象為基礎設計的,所以其系統的監控容量是有限的[1];中國電信NetCare 服務基于電信級的安全服務構建,以SaaS 的方式提供服務,在監控的設備數量、動態的監控數據體量、系統性能、系統可用性方面有著更高的要求,整個系統采用分布式分層架構模式,底層使用成熟的分布式數據庫系統、消息隊列系統,相對于傳統封閉式的監控系統,NetCare 系統能夠通過底層分布式系統的資源的動態擴展更好地滿足業務的發展需要[2].一個系統的可用性是由多方面的因素共同決定的,通常會涉及硬件、網絡、操作系統、數據庫、中間件、應用本身等[3],NetCare 系統的高可用性方案中一方面在硬件、網絡、操作系統、數據庫、中間件方面引進了相應廠商的高可用性解決方案,另一方面通過設計與實踐提升了應用系統自身的高可用性.
圖1 NetCare 系統首頁界面
圖2 NetCare 系統監控板界面
1 影響系統高可用性的因素分析
1.1 NetCare 系統邏輯架構
如圖3,NetCare 系統架構主要由數據采集子系統、數據處理子系統、業務管理子系統、消息隊列、數據緩存、數據存儲6 大部分組成.為了分散系統的采集壓力數據采集子系統部署多臺采集機,系統實測數據:每臺采集機在采集頻率為10 s 的情況下可以承擔2000 臺設備的數據采集工作.數據處理子系統采用多臺數據處理機+數據緩存的方式提高數據歸并、計算的性能,系統實測數據:每臺數據處理機在采集頻率為10 s 的情況下可以同時支持20 000 臺設備的采集數據的計算、歸并,并將數據寫入分布式數據庫中[4].

圖3 NetCare 系統邏輯架構
1.2 應用層高可用性影響分析
故障綜合影響級別的定義見表1.

表1 故障綜合影響級別
嚴重:嚴重故障對系統有著較高影響且有較高發生可能性,嚴重故障會導致系統長時間(一般以天為時間單位)的故障停機,對客戶和運營單位造成巨大損失.
高危:高優先級別故障對系統有著較高影響和中等發生可能性,或中等影響和較高發生可能性.高優先級別故障會導致系統較長時間(一般以小時為時間單位)的故障停機,對客戶和運營單位造成較大損失.
中危:中優先級別故障對系統有著較高影響和較低發生可能性,或中等影響和中等發生可能性,或較低影響和較高可能性.中優先級別故障會導致系統短時間(一般以分鐘為時間單位)的故障停機,對客戶和運營單位造成中度損失.
低危:低優先級別故障對系統有著中等影響和較低發生可能性,或較低影響和中等發生可能性.低優先級別故障會導致系統較短時間(一般以秒為時間單位)的故障停機,對客戶和運營單位造成輕微損失.
根據NetCare 系統架構分析可以得到影響系統可用性的應用層分析表2.表2中羅列了影響NetCare 系統可用性的應用層方面的主要因素[5],細分的因素數量會更多,為了后續高可用性的設計描述更加清晰,本文對于各子系統架構的風險進行了概括的總結;對于消息隊列、數據存儲、數據緩存由于采用了成熟的開源軟件且其架構中都具有高可用性的設計及實現,所以故障發生的可能性定為低.

表2 影響系統可用性的應用層分析表格
2 系統高可用性設計與實踐
2.1 網絡層面的高可用實踐
NetCare 系統使用SD-WAN 服務為客戶提供多通道高可用性技術,可以在小于1 s 的時間內切換通道,保障網絡的高可用性.
2.2 硬件層面的高可用實踐
NetCare 系統部署在采用VMWare 構建的私有云上,通過vSphere 建立包括DRS、HA 功能的集群,HA 技術最高靈敏度可以在30 s 內檢測到虛擬機故障,并重置虛擬機;DRS 可以將虛擬機從負載較重的主機遷移到負載較輕的主機上.
2.3 中間件、數據存儲、數據緩存的高可用實踐
NetCare 系統在實踐中選取了開源的ActiveMQ、MySQL、HBase、Redis 分別作為消息隊列、數據存儲、數據緩存的組件,對應的高可用性設計也采用了開源軟件自身的高可用性方案.ActiveMQ 采用了Zookeeper+LevelDB 的部署方式.MySQL 采用了Master-Slave 的部署方式.HBase 本身為高可用的分布式數據庫.Rdeis 采用了Redis-Cluster 的部署方式.數據存儲選用了MySQL 和HBase 兩種類型的數據庫,主要是基于如下考慮:關系型數據庫用來存儲設備、客戶、服務包等基本信息,這類信息數據量較小,相對變動不大;分布式數據庫主要用來存儲采集的動態數據,這類信息的數據量巨大,不適合采用關系型數據庫存儲[6].
2.4 數據采集子系統的高可用實踐
NetCare 系統的數據采集子系統主要用于從設備或其他API 接口采集動態的性能數據(主要包括:線路通斷、端口流量、CPU、內存等),采集機支持的最短采集頻率為10 s/次.為了減少對采集對象的影響,每個采集對象的數據僅由一臺采集機進行采集.
為了確保采集的高可用性,首先在線路上需要設置兩條互相備份的采集鏈路(Active-Standby 模式),當一條鏈路不可用時,采集機通過備份的鏈路進行數據采集.
由于單臺采集機可以采集的對象的數量是有限的,所以數據采集子系統中部署有多臺采集機,分散采集壓力,增強系統的可用性[7]:當一臺采集機出現故障時,影響范圍僅限于在該采集機上進行數據采集的設備.表3是NetCare 系統需要部署的采集機的數量實踐數據,其中數據是在單臺采集機CPU、內存均小于等于60%前提下的測試結果.
整個系統需要的采集機數量計算如下:
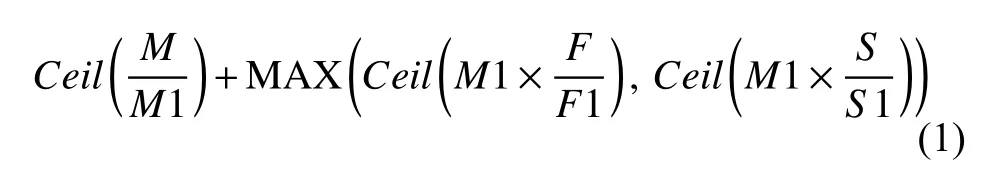
其中,Ceil為進位取整函數,MAX 為取最大數函數;M是系統總的監控設備數量;M1 為單臺采集機測試的監控設備數量上限;F為單臺被監控設備實際每秒上報的Netflow 的flow 數量;F1 為單臺采集機測試的每秒上報的Netflow 的flow 數量;S為單臺被監控設備實際每秒上報的SNMP Trap 包數量;S1 為單臺采集機實際每秒上報的SNMP Trap 包數量.
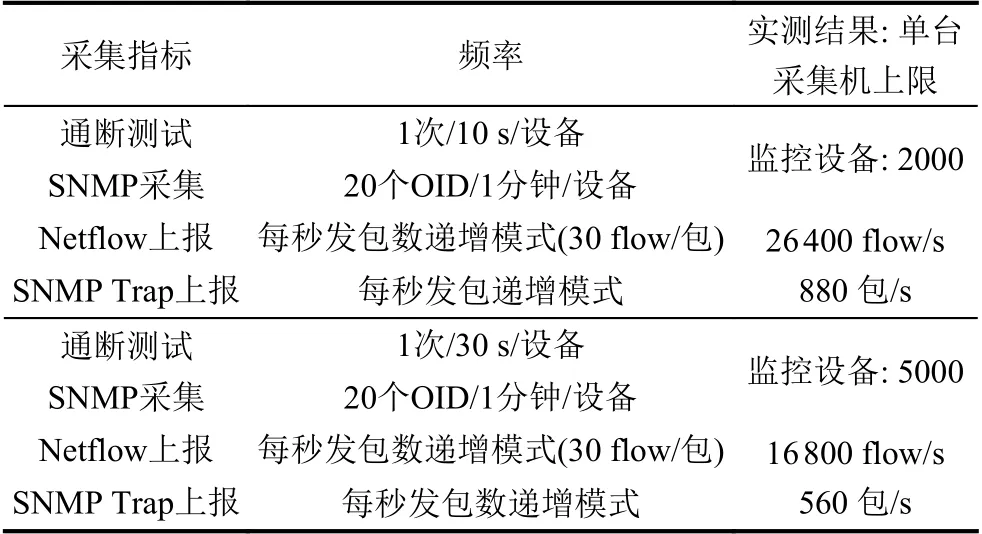
表3 單臺采集機上限測試數據
系統對采集機的狀態進行持續監控,當采集機發生故障時,可以從業務管理子系統將該采集機負責的設備轉移到其他采集機上;另外采集機上部署有關系型數據庫,當消息隊列發生故障時,可以臨時存儲采集上來的數據,增強了數據采集子系統的可用性.數據采集子系統的應用層故障時間主要取決于采集機監控頻率且重新分配設備的所屬采集機的時間.
2.5 數據處理子系統的高可用實踐
NetCare 系統的數據處理子系統主要從消息隊列中獲取最新的采集數據,從緩存中獲取最近持久化的采集數據,將兩種數據進行歸并、計算,并持久化到數據存儲中,替換緩存中的數據.多臺數據處理機采用競爭消費的方式從消息隊列中獲取數據,當一臺數據處理機故障時,其他數據處理機會分擔數據處理任務.單臺數據處理機的實測的處理速率為近600 條/s,部署3 臺數據處理機,因而數據處理子系統的應用層故障時間主要取決于消息隊列競爭的多消費者之間切換的時間.
2.6 業務管理子系統的高可用實踐
NetCare 系統的業務管理子系統主要面向客戶、運營人員提供可視化的監控相關功能,主要是Web 服務,采用兩臺Web 服務器負載均衡的方式對外提供服務.
Web 應用程序框架為自研的邊緣計算引擎[8],采用前后端分離的方式,該框架支持自動熱遷移,兩臺Web 服務器的前后端可以分別互作備份,當一臺服務器的后端服務升級時,兩個前端服務可以共享依然活躍的后端服務,可以有效減少系統維護的停機時間.
業務管理子系統應用層故障時間主要取決于Web應用容器的后端服務健康檢測時間.
2.7 IDC 層面的高可用實踐(異地災備)
以上均為同地的可用性設計及實踐,為了防患于未然,需要設置異地的災備系統,由于資源限制,NetCare系統主要采用同市區不同機房的異地災備方式,并未采用跨地域、跨電網、跨地震帶的方式.在發生機房故障時,故障時間主要取決于域名的切換時間[9].
3 NetCare 系統的可用性計算
基于以上分析,NetCare 系統的各層故障停機時間分析如表4.

表4 NetCare 系統應用層停機時間分析表
NetCare 系統總的全年預估最長停機時間:

NetCare 系統的可用性為[10]:

以上為本地系統的可用性估算,異地災備系統的切換取決于域名的生效時間(最長為48 小時),則考慮本地系統無法提供服務,啟動異地系統的情況下,NetCare系統的可用性為:

4 結論與展望
影響系統的可用性主要由平均無故障時間和平均維修時間決定,NetCare 系統采用了本文描述的相關高可用性設計后,提升了系統的平均無故障工作時間,整個系統的分布式架構減少了相關模塊的耦合度,單個模塊故障對整個系統的影響范圍得到了有效控制,縮短了故障的處理時間,整個系統可用性達到了99.9978%.影響系統可用性的因素比較多,系統建設時需要盡可能多的識別,提高系統的可用性同時也意味著成本的增加,所以對于所有影響因素要進行綜合考慮,需要在系統可用性的實際需求、建設方的資金投入、系統建設周期之間找到一個切實的平衡點.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
汽車維修與保養(2019年7期)2020-01-06 03:30:42
家庭影院技術(2017年9期)2017-09-26 03:41:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
汽車維修與保養(2015年6期)2015-04-17 03:31:50
