基于BERT模型的圖書表示學習與多標簽分類研究
2020-11-23 02:03:14蔣彥廷胡韌奮
新世紀圖書館 2020年9期
關鍵詞:深度學習
蔣彥廷 胡韌奮
摘 要 中文圖書細粒度多標簽分類的自動化,有利于促進圖書的檢索與學科的溝通。文章充分發揮BERT語言模型的微調特性,提出一種通過21類粗粒度分類微調語言模型,學習到更好的圖書表示,進而實現細粒度分類的新策略。結果顯示,在單標簽的分類任務上,BERT模型的正確率分別較LSTM與Fasttext模型提升約4.9%與2.0%。KNN-ML對257類的細粒度多標簽分類證明了前期微調的有效性。最佳情況下,有75.82%的圖書細粒度類別恰好全部預測正確,92.10%的圖書至少被正確預測了一個細粒度類別。因此可以得出結論,該系統有助于實現圖書自動的細粒度歸類,并幫助圖書標引者補充合理的分類號。
關鍵詞 中文圖書 BERT模型 深度學習 微調策略 多標簽分類
分類號 G254.1
DOI 10.16810/j.cnki.1672-514X.2020.09.007
Representation Learning and Multi-label Classification of Books Based on BERT
Jiang Yanting, Hu Renfen
Abstract The automation of the fine-grained multi-label classification of Chinese books is beneficial to the book index and subject communication. This paper makes full use of fine-tuning of BERT model and puts forward a novel strategy which fine-tunes the model on the coarse-grained classification task to learn a better book representation, and then completes the multi-label classification. The result shows that on the single-label classification, the accuracy of BERT has increased by about 4.9% and 2.0% compared with LSTM and Fasttext. The classification result of KNN-ML indicates the effectiveness of fine-tuning. Under the best situation, 75.82% of books are correctly sorted out, and 92.10% of books are predicted with at least one correct label. It draws a conclusion that this system is of great benefit to automatic fine-grained classification, and can help book annotators replenish the potential missing category code.
Keywords Chinese books. BERT. Deep learning. Fine tuning. Multi-label classification.
中國近年來的圖書出版規模十分可觀。據統計,2016至2018年國內年均申報各類圖書選題29.5萬余種[1]。伴隨各學科的發展與相互交融,越來越多跨學科、邊緣學科、復合視野的研究成果以圖書的形式呈現出來。這意味著用《中國圖書館分類法》(以下簡稱《中圖法》)中的單一類別標簽,已難以全面、準確地概括它們的主題與內容。然而囿于有限的精力與知識面,人工編制的圖書在版編目(Cataloguing In Publication, CIP)給大多數圖書只指定了1個分類標引,這在一定程度上限制了圖書的檢索與學科間的交流。因此,如何利用信息技術,自動補全原有圖書可能缺失的分類號,并實現新圖書自動的、細粒度歸類,打通各專業學科之間的屏障,是圖書情報領域值得研究的課題。圖書自動分類是文本分類(Text Classification)的一個子領域,與其他類型的文本相比,學界對中文圖書分類的研究相對較少。本文擬嘗試一種基于BERT語言模型的模型的圖書的粒度分類引法來解決自動分類中存在的問題。
1 相關研究回顧
在以往的成果中,中文圖書分類的方法主要分為兩種。一是基于特征工程的經典機器學習方法,二是自動編碼提取特征的深度學習方法。前者如王昊等[2]在特征加權的基礎上,采用支持向量機(SVM),構建了一個淺層的中文圖書分類模型;劉高軍等[3]、潘輝[4]混合采用TF-IDF、隱含狄利克雷分布(LDA)主題模型抽取圖書特征,采用極限學習機算法實現圖書分類。后者以鄧三鴻、傅余洋子[5]等的研究為代表,基于字嵌入與LSTM模型,通過構造多個二元分類器,對5類圖書進行多標簽分類實驗。總的來看,目前的研究還存在提升的空間。第一,實驗數據集涉及的類別較少,未反映出《中圖法》的基本面貌。第二,總體上缺乏對圖書多標簽分類的關注,既有的圖書多標簽分類方法存在計算開銷大、類別不均衡的問題。第三,圖書分類號的精細程度與分類器的性能難以兼得。《中圖法》是一個樹狀的、多層次的圖書分類體系,如果只將一級大類作為分類標簽,分類器無法預測更加具體的分類號;如果采用層次化的細粒度分類,則會存在類別過多、數據稀疏等問題[6],且難以顧及兼類的圖書。因此,如何細粒度地、準確地預測圖書的分類號,是亟待探研的問題。
近年來,自然語言處理界以ELMo[7]、BERT[8]為代表的深度預訓練語言模型(Pre-trained Language Model)極大改善了文本語義表示的效果,并在文本分類等各項下游任務中取得了明顯突破。預訓練語言模型應用于下游任務,主要分為兩種策略:一是基于特征的(Feature-based)策略,將固定的語言特征向量從模型中提取出來,以ELMo為代表;二是微調(Fine-tuning)策略,一方面,模型頂部接入著眼于具體任務的分類層,另一方面,語言模型所有的參數也隨著下游任務的訓練適度優化,以BERT為代表[8]。由此,我們嘗試提出一種基于BERT語言模型的圖書細粒度分類的方法,首先尊重并充分利用原有的圖書信息及分類標簽,通過進一步預訓練(Further Pre-training)與粗粒度的分類任務,讓BERT模型微調經由圖書向量相似度計算,實現圖書的細粒度分類。
2 BERT模型介紹
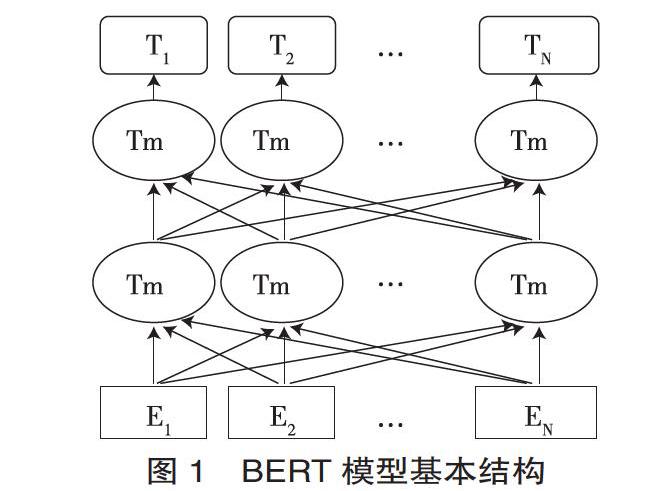
BERT (Bidirectional Encoder Representations from Transformers)是一種基于Transformer架構的深度預訓練語言模型,其結構主要如圖1所示。
以中文預訓練模型為例,圖1的E1,E2,…EN表示在首尾分別添加[CLS]和[SEP]標記的文本字符。它們依次經過12層雙向的Transformer(Trm)編碼器,就可以得到文本字符語境化的向量表示(Contextual Embeddings)。Transformer是一個基于自注意力(Self-attention)機制的編碼-解碼器。最底層的Transformer編碼器的輸入為字符向量、字符位置向量與句子片段向量之和。模型內每一層均由多頭自注意力(Multi-head Self-attention) 和前饋神經網絡(Feed-forward Neural Networks)兩部分構成,前者使編碼器在給每個字符編碼時,能關注到周圍其他字符的信息;后者用于增強模型的擬合能力。模型的每一層經過一個相加與歸一化(Add & Norm)操作后,生成新的字符向量,作為下一層編碼器的輸入。頂層編碼器輸出的[CLS]標記的編碼向量T1,可以視為整個句子的語義表征,用于后續的文本分類任務[9]。
另外,為增強語義表示的能力,BERT提出了遮罩語言模型(Masked LM, MLM)和下句預測(Next Sentence Prediction, NSP)的概念。MLM實質是一個完型填空任務,中文語料中15%的字會被選中,其中的80%被替換為[MASK],10%被隨機替換為另一個字,剩下的10%保持原字。模型需要經由一個線性分類器,預測被選中的字。出于與后面任務保持一致的考慮,BERT需按一定的比例在預測的字的位置放置原字或者某個隨機字,使得模型更偏向于利用上下文信息預測被選中字。在下句預測任務中,模型選擇若干句子對,其中有50%的概率兩句相鄰,50%的概率兩句不相鄰。模型通過上述兩個目標任務,能夠較好地學習到字詞和句間的語義信息。
3 基于表示學習的圖書粗粒度分類
我們嘗試在圖書粗粒度分類任務上對模型進行微調(Fine-tuning),提升預訓練模型對圖書數據表示的準確度,為后續的細粒度分類任務奠定基礎。首先進行單標簽分類,以測試BERT圖書分類的有效字段,檢驗進一步預訓練的效果,并與其他模型進行比較;既而進行多標簽實驗并討論其實用性。本文的整體模型架構如圖2所示。
3.1 數據集與實驗環境
圖書數據①廣泛采集自讀秀學術網站。考慮到Z類(綜合性圖書)主要包括辭典、類書、年鑒等類型,出版數量較少,字段缺失的情況較多,我們采集了A-X共21大類、132 803冊圖書的書名、主題詞、摘要、中圖分類號等字段。在這些圖書中,只有1個分類號的書為128 548冊,占比約96.8%;擁有2個分類號的書達4152冊,擁有3個及以上分類號的書為103冊。
實驗的操作環境為Ubuntu16.04.2LTS(GNU/Linux
4.8.0-36-genericx86_64),采用2塊1080ti型號的GPU,預訓練語言模型為BERT基礎(BERT-base-Chinese)版②,為12層的Transformer模型,hidden size為768,自注意力機制的head數量為12,總參數量為110M。
3.2 單標簽分類實驗
我們首先對只有1個分類號的圖書進行實驗。具體到各類別的圖書數量如表1所示。
對于單標簽文本分類任務,BERT模型提取頂層的符號[CLS]的特征向量v(768維)作為整個文本的特征表示,再后接一個768*n的全連接層(Fully-connected layer)W(n為類別數量),最后通過softmax函數歸一化,輸出一個文本分別屬于各個類別的概率:
其中softmax函數:
在訓練過程中,模型會調整全連接層W以及BERT模型的參數,使得正確標簽所對應的概率最大化。
在訓練策略方面,我們將圖書數據集的順序隨機打亂,按8:1:1的比例劃分訓練集、驗證集和測試集,并參考Sun(2019)等人[10]在BERT上的分類實驗經驗,如下設置超參數:學習率lr=2e-5,衰變因子ξ=0.95。此外,訓練遵循早停(Early stopping)原則,當模型的損失在驗證集上不再下降,就視為模型在驗證集上已經收斂,可以停止訓練。
如圖3所示,當書名與主題詞字段作為分類字符串時,分類正確率比單一的書名大幅提升近8%。而在此基礎上加入出版社名、摘要等字段,分類正確率上升幅度不明顯,訓練收斂需要的迭代次數卻逐漸增多。綜合考慮性能、訓練次數與字段的常見性,我們認為“書名+主題詞”能夠扼要地表示圖書的主要內容,將它們作為后續實驗所用的字段,將對應的分類實驗記為BERT-base-Chinese,作為后續實驗的參考。
在訓練基本版BERT中文模型時,Devin 等[8]采用了字粒度的中文維基百科作為訓練語料。Sun[10]等人檢驗了進一步預訓練(Further pre-train)該語言模型對文本分類的有效性。我們嘗試利用圖書數據集增量訓練語言模型。考慮到每一本書均表示為一個書名加若干主題詞、按字切分的短文本,我們只采用如前文所述的遮罩語言模型(Masked LM)的訓練策略,選擇語料中15%的字進行預測,一共訓練5900步,得到增量訓練后的語言模型。在此基礎上再進行21類圖書的單標簽分類實驗,記作BERT-Increse。另外,本文將鄧三鴻、傅余洋子等[5]提出的基于單向長短期記憶網絡(LSTM)的圖書分類模型,以及基于Facebook的Fasttext文本分類模型④作為基線(Baseline)模型。LSTM設置1層隱層,每個隱層含128個節點,并采用Adam優化算法[11]與早停策略。Baseline與BERT-base-Chinese、BERT-Increse實驗均使用同樣比例與內容的訓練、驗證、測試數據。
如圖4所示,進一步預訓練的語言模型BERT-Incerse較BERT-base-Chinese能再獲得約0.23%的正確率提升,表明通過遮罩語言模型(Masked LM)增量訓練BERT對于文本分類也具有一定的功效。BERT-Increse模型在驗證集上的正確率分別高出LSTM和Fasttext模型約4.9%與2.0%,并且前者需要訓練的周期數比后者更少,這證明了我們基于BERT的圖書分類方法的有效性。
此外,如圖5所示,在具體圖書類別的F1值精度方面,A(馬列主義等)、J(藝術)和U(交通運輸)三類圖書具有最佳的分類表現,而T(工業技術)、K(歷史、地理)和N(自然科學總論)三類圖書的分類F1值較低。這表明A、J、U類圖書至少在書名、關鍵詞上的分布較為集中。而T、K、N類圖書涉及的子領域較多,話題更為廣闊,數據相對稀疏。它們是人們進一步優化分類模型時,需要著重關注的對象。
3.3 多標簽分類實驗
在單標簽分類的基礎上,我們進行多標簽的分類實驗。除了前一小節所用的單標簽數據外,又增加了4152冊兼類的圖書數據。雖然多標簽的圖書占數據集圖書總數的比例較小(約3.2%),但圖書兼類情況錯綜復雜,種類高達181種。兼類最多的兩類情況是F兼D(經濟類兼政法類)、R兼Q(醫藥衛生類兼生物科學類),圖書分別達到124、105例。而兼類情況較少的如N兼I(自然科學總論類兼文學類)都僅有1例。這意味著在后續的多標簽分類時,不宜簡單地將兼類的圖書單獨劃類,否則將面臨類別過多、數據稀疏的問題。
多標簽分類是文本自動分類中的一個研究熱點與難點,其目的在于給測試集中每一個文本預測一個或多個可能的類別。根據假設的不同,以往的研究主要分為兩大類。第一,假設各類別相互獨立,不考慮類別之間的相關性,進而運用3種具體的分類算法:(1)二元相關(Binary Relevance)算法[12],即把多標簽分類轉化為多個二類分類任務。(2)基于K近鄰(KNN)改進的惰性學習算法[13]。(3)調整損失函數,獨立地計算、輸出一個文本屬于各類的概率[14]。第二,考慮標簽兩兩之間的相關性,由此設計出排序支持向量機(Rank SVM)[15]、雙層的主題模型[16]等方法,以及基于深度學習序列生成的多標簽分類方法[17]。具體到本任務,由于圖書不存在諸如“屬于甲類就一定屬于乙類”或“屬于丙類就一定不屬于丁類”的情況,因此我們仍假設21個圖書大類相互獨立,將損失函數調整為帶有sigmoid函數的二元交叉熵損失函數(Binary Cross Entropy with Logits Loss, BCE with Logits Loss),其中一個樣本的損失如下式計算[14]:
其中sigmoid函數n為類別總數,xn是模型的輸出值,表示預測樣本屬于某一類別的概率;yn是樣本在某一類別下的真實標簽,1表示屬于該類別,0表示不屬于該類別,是xn的優化目標。與單標簽分類通常采用的softmax交叉熵損失函數不同的是,sigmoid函數使一個樣本屬于各類別的概率分布在(0,1)之間,且沒有進行類別之間的歸一化,使各類別的概率之和可能大于1。這允許模型給每一個標簽分配獨立的概率。在測試階段,模型將凡是概率大于50%的標簽輸出,作為一個樣本多標簽分類的預測結果。
我們基于上文BERT-Increse實驗的模型進行多標簽分類的微調。整個數據集按約8:1:1的比例劃分訓練集、驗證集、測試集,一共訓練2個epoch使模型在驗證集上的損失收斂。模型在測試集13334個樣本上預測的結果如表2所示。
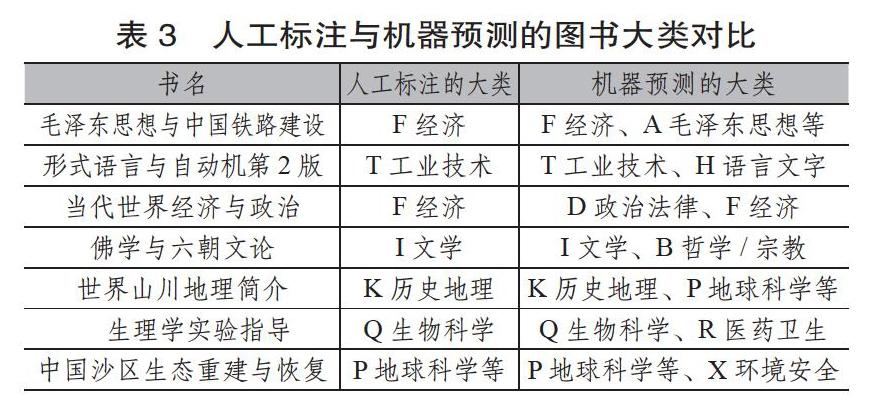
值得注意的是,在符合情況(3)的165例樣本里,一些預測雖然比實際標簽數更多,但經人工檢查發現,這些與實際標簽不一致的預測也有其合理性,部分例子如表3所示。
從表3中不難發現,機器多預測出的一些分類號其實無可厚非。例如《形式語言與自動機第2版》,其中論述的形式文法和自動機,既是程序語言編譯技術的重要理論基礎,可歸為工業技術類下轄的TP類(計算機、自動化技術);又是形式語言學、轉換生成語法等語言學流派的研究內容,也可歸為H語言文字類下轄的H087(數理語言學)類,宜按互見分類處理。經過人工檢查統計,這165例樣本中,至少有81%的預測有一定的合理性。這一方面表明基于BERT的粗粒度、多標簽分類已具有一定的實用性,可以初步預測圖書所屬的學科大類,并能夠補充一些圖書可能缺失的分類號,為圖書標引的工作者提供有益的推薦與參考;另一方面該分類任務也促使BERT通過微調(Fine-tuning)學習到更好的圖書表示,為后續的細粒度分類打下了基礎。
4 基于微調BERT與多標簽K近鄰的圖書細粒度分類實現
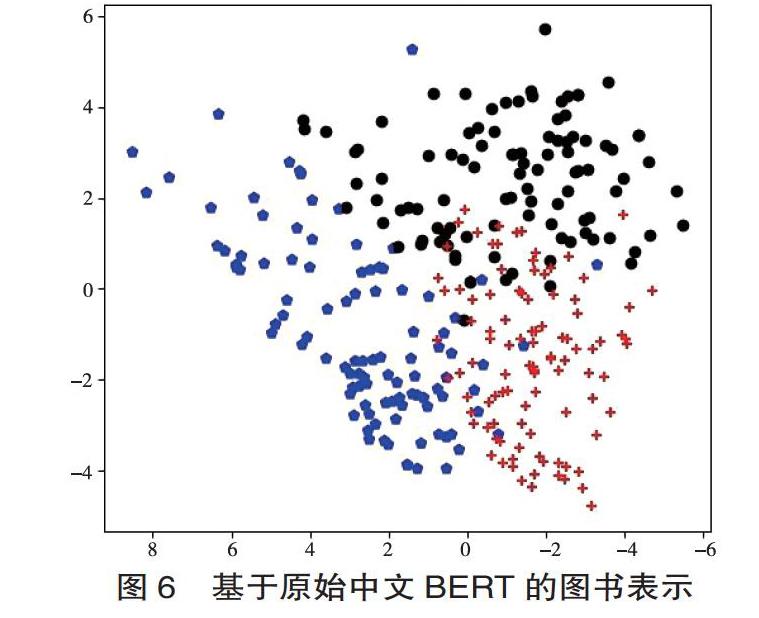
為驗證粗粒度分類任務對BERT模型圖書表示的影響,我們嘗試從不同階段的模型中提取768維的圖書向量,并通過主成分分析(Primary Component Analysis, PCA)技術降維可視化,分析圖書分布的變化。我們以圖書館學情報學(屬于G3與G2)、語言學(屬于H0)與計算機自動化技術(屬于TP)3類各100冊圖書為例,選取其書名、主題詞字段作為輸入詞,觀察它們的語義表示變遷,見圖6至圖9。
綜合圖6~圖9可以發現,從原始模型到增量訓練,再到單標簽分類、多標簽分類后,三類圖書的分布呈現出同類圖書集聚、類間圖書距離拉大的趨勢。而該趨勢在兩個分類任務后的模型上表現得尤為明顯。這反映出通過BERT在完成下游任務的同時,語言模型本身也發生了顯著變化,通過編碼圖書主題和粗粒度類別的信息,圖書語義表示比原始模型更加精準。
細粒度的多標簽分類以數據集圖書所屬的中圖法各二級學科作為類別,總計257類。訓練集為3.3節粗粒度多分類實驗中的訓練集與驗證集之和;測試集則保持不變。我們首先從粗粒度多標簽分類微調后的BERT模型中提取768維的圖書向量,然后采用基于K近鄰(K-Nearest Neighbor, KNN)的分類方法KNN-ML(KNN-Multi Label)。具體過程如下:
(1)對于測試集中的每一個樣本點yi,查找出訓練集中與之向量距離最近的k個近鄰樣本x1,x2,…,xk,記作集合U。
(2)統計集合U中,各樣本所屬的中圖法二級學科類別Ci及其出現頻次Fi。
(3)設置閾值L,當Fi >=L時,就將對應的Ci判定為測試樣本點yi所屬的二級學科。
基于KNN-ML的多標簽分類具有諸多優勢,首先,它是一種惰性學習方法,節省了顯性的訓練過程;其次,KNN-ML僅以近鄰范圍內樣本投票表決的方式進行預測,既實現了多標簽分類,也無須計算全部257類的概率;第三,圖書的向量表示直接從BERT模型中繼承而來,增量訓練、系統的后期維護也較為方便。
yi查找近鄰樣本時,KNN-ML利用球樹(Ball Tree)的數據結構來優化查找的過程。球樹使用超球面對樣本空間進行劃分,在查詢一個測試樣本的k近鄰時避免了蠻力計算;此外,球樹運用球心與半徑描述樣本點,樣本點占用的空間對維數不敏感,這彌補了矩形劃分在高維時存儲較大、查詢較慢的不足[18]。因此球樹適用于本次實驗向量維數較高的情況。
我們記原始的中文BERT模型為BERT-base-Chinese,在此基礎上,記進行粗粒度單標簽分類微調后的模型為BERT-single-clf,記粗粒度多標簽分類微調后的模型為BERT-multi-clf。經多次參數調優,KNN-ML設置近鄰數目k=10,觀察各模型在閾值L變化時的表現變化。如表4所示。
根據表4,首先,未經微調的BERT-base-Chinese在指標1、2上的表現均不及微調后的兩個模型。這證明BERT通過微調融入中圖法一級大類的信息后,也能提高二級類別分類的準確度。其次,BERT-single-clf模型的總體效果居于第二,在不同閾值L下的9項指標評測中,有2項取得最佳。由于它僅在單標簽分類任務上微調,缺乏對兼類圖書的語義編碼,因此BERT-single-clf至少正確預測出一個標簽的能力較強(指標1),但其準確預測出全部標簽的能力(指標2)略遜于BERT-multi-clf,且容易將非兼類的圖書預測為兼類(指標3)。最后,綜合3個指標,BERT-multi-clf模型的表現最佳,在9項指標中取得了6項最佳。當閾值L=4時,測試集中84.44%的圖書被正確預測了至少1個二級類別;有75.82%的圖書的分類號完全預測正確。這對于多達257個類別的細粒度多標簽分類任務來說,依然是良好的表現,且性能明顯優于原始BERT模型與單標簽粗粒度分類后的BERT-single-clf。在占比5.94%的多預測了標簽的圖書中,部分例子如表5所示。
可以發現,一些看似預測有誤的例子,實際上是對既有圖書標引的有益補充。例如根據《中國圖書館分類法第五版(簡本)》的設定,C8統計學和O1數學下轄的O212“數理統計”是互見類別[19]。而《定性數據統計分析》一書兼屬這兩個類別,這樣分類不僅是圖書管理中兩類書籍相互參證的需要,而且有利于提高圖書的查全率,促進學科的相互交流。
5 結語
文章著眼于中文圖書的細粒度多標簽分類工作,考慮到預訓練的BERT語言模型的微調(Fine-tuning)特性,提出一種先通過粗粒度分類微調語言模型,在此基礎上提取圖書表示,再采取惰性學習方法實現細粒度分類的策略。
首先,在面向21大類圖書表示學習的單標簽分類中,BERT模型在驗證集上取得了91.94%的正確率,在遮罩語言模型增量預訓練BERT后獲得進一步提升,明顯優于前人的LSTM與Fasttext模型。
其次,文章運用帶有sigmoid的二元交叉熵損失函數,實現21類圖書的粗粒度多標簽分類,有92.53%的圖書預測出至少1個分類號,有89.98%的圖書預測出全部分類號。
最后,文章在微調BERT模型的基礎上,采用KNN-ML的方法實現257類的細粒度圖書分類。實驗表明,經粗粒度分類微調的模型效果明顯優于未經微調的預訓練模型。在最佳情況下,有75.82%的圖書的類別全部預測正確,92.10%圖書至少被正確預測了一個類別。從應用角度看,本文提出的分類方法既可以用于圖書的自動預分類工作,大大減輕人工標引的負擔;也可用于分類號的校對補充,幫助標引者查漏補缺,促進不同學科的溝通與交融。在后續工作中,我們嘗試通過加權改進KNN-ML算法,使圖書分類系統進一步完善。
參考文獻:
出版商務周報.最新CIP大數據分析,2019圖書選題該做什么?[EB/OL]. (2019-2-28)[2020-04-15].http://www.yidianzixun.com/article/0LOGYM5G.
王昊,嚴明,蘇新寧.基于機器學習的中文書目自動分類研究[J].中國圖書館學報, 2010,36(6):28-39.
劉高軍,陳強強.基于極限學習機和混合特征的中文書目自動分類模型研究[J].北方工業大學學報,2018,30(5):99-104.
潘輝.基于極限學習機的自動化圖書信息分類技術[J].現代電子技術,2019,42(17):183-186.
鄧三鴻,傅余洋子,王昊.基于LSTM模型的中文圖書多標簽分類研究[J].數據分析與知識發現,2017,1(7):52-60.
陳志新.分類法研究的十五個問題:我國2009至2016年分類法研究綜述[J]. 情報科學,2018,36(6):149-155.
PETERS M E,NEUMANN M,IYYER M, et al.Deep contextualized word representations[J].arXiv e-prints,2018 :1802-5365.
DEVLIN J, CHANG M, LEE K, et al.BERT: pre-training of deep bidirectional transformers for language understanding[J].arXiv e-prints,2018:1810-4805.
VASWANI A, SHAZEER N, PARMAR N, et al.Attention?is all you need[J]. arXiv e-prints, 2017:1706-3762.
SUN C, QIU X, XU Y, et al. How to fine-tune BERT for text classification?[J].arXiv e-prints, 2019:1905-5583.
KINGMA D P, BA J. ADAM: a method for stochastic optimization[J].arXiv e-prints, 2014:1412-6980.
MATTHEW R B, JIEBO L, XIPENG S,et al. Learning multi-label scene classification[J]. Pattern Recognition: The Journal of the Pattern Recognition Society, 2004,37(9):1757-1771.
ZHANG M, ZHOU Z. ML-KNN: a lazy learning approachto multi-label learning[J]. Pattern Recognition, 2007,40(7):2038-2048.
FACEBOOK. Pytorch Docs :? Docs > Module code > torch> torch.nn.modules.loss[EB/OL](2019-4-25)[2020-04-15]. https://pytorch.org/docs/stable/_modules/torch/nn/modules/loss.html#BCEWithLogitsLoss.
ELISSEEFF A,WESTON J. A Kernel method for multi-labelled classification[C].In Advances in neural informationprocessing systems,2002:681-687.
ZHANG M L, ZHOU Z H. Multi-label learning by instance differentiation[C]. Proceedings of the 22nd Conference on Artificial Intelligence,2007: 669–674.
YANG P, SUN X, LI W, et al. SGM: sequence generationmodel for Multi-label classification[J]. arXiv e-prints,2018:1806-4822.
俞肇元,袁林旺,羅文,等.邊界約束的非相交球樹實體對象多維統一索引[J].軟件學報, 2012,23(10):2746-2759.
國家圖書館中國圖書館分類法編輯委員會.中國圖書館分類法簡本(第五版)[M].北京: 國家圖書館出版社,2012:14,107.
蔣彥廷 北京師范大學中文信息處理研究所碩士研究生。 北京海淀,100875。
胡韌奮 北京師范大學中文信息處理研究所碩士生導師。 北京海淀,100875。
(收稿日期:2019-11-02 編校:左靜遠,陳安琪)
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
