《論語》多譯本平行語料庫的創建
2020-11-06 04:46:29楊曄王子涵
文存閱刊 2020年18期
楊曄?王子涵


摘要:《論語》被稱為東方哲學經典中的經典。一直以來為包括中國、日本等世界諸多國家久為研讀,并發揮著持久而深刻的影響力。本文選取在中華典籍文化海外傳播中發揮了重要影響力的漢學家譯注的《論語》譯本,創建漢日平行語料庫,以期推動《論語》語言特征等方面的實證研究。文中詳細介紹了包括語料清理、語料對齊、語料的分詞和標注、語料檢索在內的漢日平行語料庫的創建步驟。
關鍵詞:論語;多譯本;平行語料庫
一、概述
作為孔子教義權威記載和儒家思想的基礎文本,《論語》一直是中華文化的主流意識形態,也對亞洲乃至西方文明產生了重要影響[1]。它以語錄體和對話文體為主,記錄了孔子及其弟子言行,以及孔子與時人的問答。它是進行孔子研究的重要資料,書中集中體現了孔子的政治主張、倫理思想及教育思想等。從學而篇到堯曰篇,通行本《論語》共二十篇。
本文以《論語》現代漢語譯文及海外漢學家譯注的五個日譯本為語料,構建《論語》漢日平行語料庫,為《論語》的實證研究做基礎。
二、平行語料庫建設現狀
平行語料庫可分為通用語料庫和專門領域語料庫。通用語料庫以北京外國語大學研制的漢英、漢日對譯語料庫為代表,其特點是收錄內容覆蓋面廣,語料規模大,可應用于語言研究、翻譯研究、教學研究、詞典編纂等[2]。專門領域語料庫以文學類平行語料庫為主,法律、醫學、科技、旅游等非文學類平行語料庫的建設及研究也取得了進展。
專門領域語料庫的研究也取得一定進展。如:以教學應用為目創建英漢平行語料庫、《紅樓夢》中英平行語料庫、莎士比亞戲劇英漢平行語料庫、契訶夫小說俄漢平行語料庫等。學者基于自建平行語料庫對雙語文本進行一對一或一對多平行檢索,對翻譯策略、譯者風格和翻譯語言特征等方面進行研究。具體包括:從詞匯角度對隱喻翻譯策略的研究、對報道動詞的翻譯及顯化進行的研究;從句法角度對“忙XX”結構、“把”字句、敘事標記語進行的研究;以及從篇章角度對語篇難易度與語篇范化、譯者風格等內容進行實證研究。
通過對文獻的梳理可以看到,這些研究成果存在一定相同之處,即普遍使用句對齊,所用工具和軟件基本相同;標注過程中以詞性標注為主,使用自動標注輔以人工校對的模式。不同點有:①標注的內容呈現多樣性,在平行語料庫的建設過程中,標注雖然不是一個必須的步驟,但通過對句法或詞性的標注為后續深入研究提供了方便。除詞性標注外,學者基于不同的研究目的,對文化負載詞、對句子類型、有/無習語、諺語、有/無修辭等內容進行標注;②部分學者開發了網絡檢索功能;③建設方法多樣性,除常見的語料對齊軟件外,還有學者使用Trados、python、office中VBA語言、web進行語料庫建設。
目前,平行語料庫的建設以漢英雙語平行語料庫為主,非通用語種的語料庫建設尚存不足。部分自建的語料庫中收錄語料數目少,缺少一對多平行語料庫非通用語種平行語料庫建設成果較少。鑒于此,本文在中譯本之外,選取五個日譯本,構建漢日平行語料庫。
三、《論語》漢日平行語料庫的創建
一般而言,平行語料庫的創建步驟主要為:①語料的預處理;②語料加工;③語料的檢索。其中,語料預處理包括語料輸入與語料清理等工作;語料加工包括語料對齊與語料標注等工作。本文所建立的漢日平行語料庫是一文多譯,且在句子層面呈現對應關系的語料庫。通過對漢語或日語的關鍵詞進行檢索,可以提取出含有該關鍵詞的所有語句,并且能夠使原文與多個譯文同屏展示。同時為便于進一步深入研究日語譯本,對語料進行了分詞和詞性標注。《論語》漢日平行語料庫的加工過程如圖1所示。
1.語料預處理
如圖1所示,語料預處理包含語料輸入及語料清理兩個步驟。
《論語》漢日平行語料庫中共收錄兩個中文文本、五個日譯本。中文文本為朱熹撰《論語集注》、楊伯峻的《論語譯注》。日譯本均為日本漢學家譯注的現代日語版本(譯注者分別是:貝塚茂樹、宇野哲人、金谷治、宮崎市定、加地伸行)。
將收集到的紙質版語料,使用光學識別軟件電子化后,轉換為TXT格式,進而對語料進行清理和校對。語料清理一般包括文本格式的統一、字符替換、拼寫檢查和編碼轉換等。具體包括:①圖片及前言后記等無關信息的剔除;②文本格式、字體類型及大小的統一;③文本雜質的清除,多余空格、符號的刪除;④錯別字的修改等。漢學家譯注的《論語》為了便于讀者理解,在譯文之外,普遍添加了詞語注釋以及針對語義乃至語境的解釋,這些文字屬于注釋內容,不屬于翻譯內容。此外,為了讀懂漢文原典,日本人發明了“漢文訓讀法”,具體方法是在漢文原文旁邊加上一些符號,就可以閱讀中國古文。我們選取的日譯本中均有這種“訓讀文”,這些內容不屬于現代日語翻譯文本,所以在創建《論語》漢日平行語料庫時,將書中出現的“注釋”以及“訓讀文”未進行收錄,只保留了日文譯文。清理完畢后的語料規模在40萬字左右。
2.語料加工
首先是使用線上對齊工具實現句子層面的對齊。《論語》語言為古漢語,段落簡短,多以一句話為一個段落。由于日文版《論語》是日本譯注者根據朱熹、何晏等人的注釋,并結合自己的研究成果,進行譯注,所以不但在語義理解方面,存在與中國學者相異之處,在段落的劃分上也存在差異。本研究以朱熹撰《論語集注》為依據,將各譯本的段落劃分與此保持一致。同時,在句對齊方面,以中文原文中的句號、問號、分號、嘆號等為切分句子單位,將日語譯文及現代漢語版譯文與原文進行句對齊處理。
在此基礎之上,通過使用python對語料進行了分詞和詞性標注。并對分詞和標注的結果進行人工校對及修正。圖2為最終標注結果。日語中有“形容詞”和“形容動詞”之分,形容動詞是表示事物性質和狀態的詞語,在修飾名詞與可充當謂語等功能方面,與形容詞相同。但活用形式不同。下圖中第4行右側第3個詞“形狀詞”,即為形容動詞。此外,圖中詞性標注中有“助動詞”(如圖中第1行右側第1個詞),這是因為日語中詞性有“助詞”和“助動詞”之分。
3.語料檢索
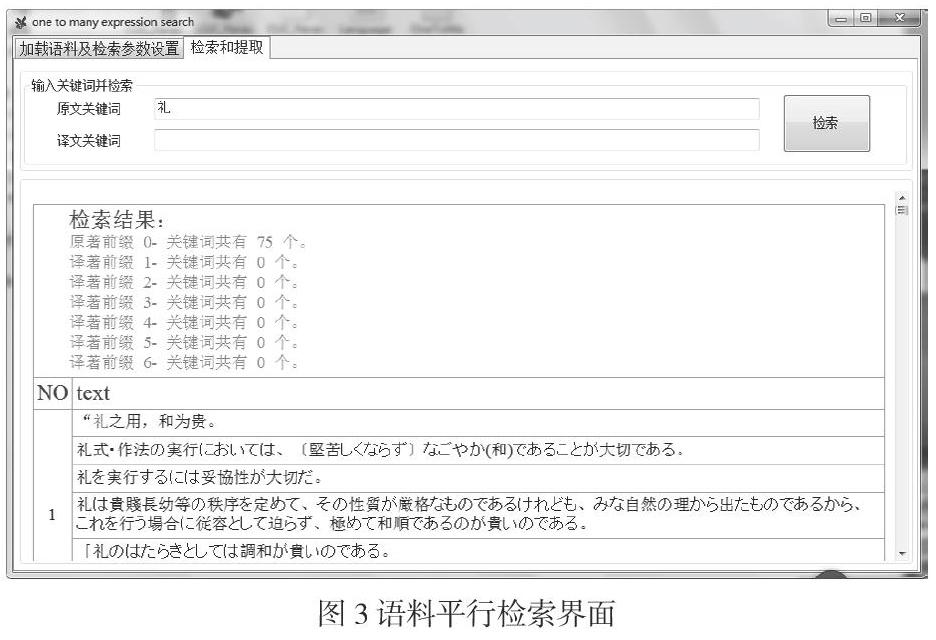
本研究使用CUC_Paraconc進行語料檢索。在CUC_Paraconc中載入語料,能夠實現中日語料的雙向檢索,通過設置載入語料的數量可以實現一對一或一對多的語料檢索。如圖3,在“原文關鍵詞”處輸入中文“禮”,下方的檢索結果中,就能獲得包含關鍵詞“禮”的中文以及對應譯文,同時還能看到該詞在中文原文出現的頻數,即75個。這里顯示的是在中文原文中出現的頻數,沒有顯示在日譯本中的出現頻數。如果想獲得該詞在日譯本中的出現頻數,就要在“譯文關鍵詞”處輸入相應日文關鍵詞。
經過分詞處理后的語料可以進行檢索分析。如圖4所示,如果想了解翻譯文本中哪些詞與“孔子”共同出現在一個句子中,可以將“孔子”設為索引詞。圖4所示是為了考察“孔子”一詞的右側有哪些詞高頻出現,搜索范圍設置為右側三個詞。從圖4可以看到,「がいわれ」與“孔子”一詞共現頻率最高,其次為「から」一詞。(圖中「孔子がいわれた」相當于漢語中的“子曰”;「孔子から聞いた」相當于漢語中的“子問”的意思)。
此外,還可以進行其他關于詞匯、搭配、句法方面的檢索;對分詞和詞性標注的語料,可以利用軟件的統計功能,進行類符、形符、詞頻、詞匯密度、詞匯搭配強度等參數的統計分析。
四、結束語
自建語料庫的優點在于能夠遵循自己的研究目的,有針對性地選取語料,做符合研究目的的標注。本文以《論語》原文及日譯文為研究文本,詳細介紹了從語料清理到語料檢索的語料庫建設過程,為多譯本漢日平行語料庫的建設及研究提供了經驗。目前市面上的語料庫工具多適用于英語,而對于非通用語種建庫,存在功能不健全不完善之處,這也給非通用語種的語料庫建設提出了挑戰。今后,將繼續對《論語》漢日平行語料庫進行完善。
參考文獻:
[1]楊平.《論語》核心概念“仁”的英譯分析[J].外語與外語教學,2008(02):61-63.
[2]王克非.新型雙語對應語料庫的設計與構建[J].中國翻譯,2004(06):75-77.
作者簡介:
楊曄(1971年-),女,副教授,哈爾濱理工大學
王子涵(1995年-),女,碩士研究生,哈爾濱理工大學
基金項目:
黑龍江省哲學社會科學研究規劃項目(批準號2019YYB067)的階段性成果。
