基于加權極限學習機的貨車篷布識別技術探討
2020-11-05 16:33:14宋坤駿張萼輝中國鐵路上海局集團有限公司科研所
上海鐵道增刊 2020年2期
關鍵詞:特征
宋坤駿 張萼輝 中國鐵路上海局集團有限公司科研所
1 引言
為有效防止貨車篷布破損使貨物受潮或篷布繩網斷裂導致篷布脫落,目前上海局大型貨站每日需要人工檢查的高清篷布照片數在3萬張左右,工人長時間看圖容易導致視覺疲勞,不僅檢查效率低下還使得誤檢和漏檢層出不窮,存在安全事故隱患[1]。由此可見,研發一套機器視覺車頂照片自動判別系統可以有效降低人工支出,提升看圖效率和準確度,為上海鐵路局貨運建設提質增效提供基礎技術支撐。工人需要查看的貨車車頂樣例圖片如圖1和圖2所示,圖1和圖2分別是沒有篷布的貨車車頂原始照片和有篷布的敞車車頂的原始照片。

圖1 一張沒有篷布的貨車車頂樣例圖片
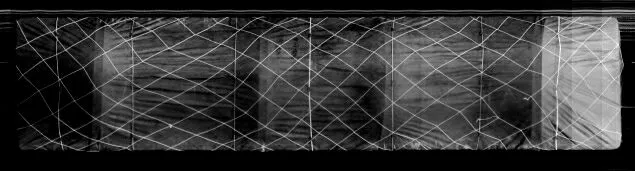
圖2 一張有篷布的敞車車頂樣例圖片
由樣例圖片可見,單憑人工過濾幾萬張圖片不僅成本高企,效率低下,不利于工人身心健康和工作積極性,也無法保證準確率。
2 算法描述
完整的篷布故障識別問題實際上是一個多分類問題,包括無篷布,正常篷布,問題篷布等類別,其中問題篷布又可以細分為篷布破洞,繩網斷線,篷布積水等類別。為了提升準確率起見,將此多分類問題轉化為多個二分類問題,即首先分辨是否有篷布,然后判斷篷布是否有故障。針對判斷篷布有無的問題,筆者曾嘗試過基于深度學習的圖像分類算法,然而深度學習準確率并不能達到較高水平如95%以上,并且對于硬件要求較高,訓練耗時長于本文提出的算法。因而,筆者抓住篷布獨有的交叉斜向網格繩網特點,建立了灰度圖的方向梯度直方圖(Histogram of Oriented Gradient,HOG)特征[2]。該特征的建立步驟如下:將圖像灰度化并Gamma校正后劃分為多個cells(例如16*16像素/cell),統計每個cell中像素點的梯度方向的直方圖,形成各個cell的HOG特征描述子,然后將各個cell組織成block(例如2*2個cell/block),block中所有cell的特征描述子串聯起來得到該block的HOG特征描述子。再把圖中所有block的特征描述子串聯起來就可以得到該圖的HOG特征向量了。由于HOG是在圖像的局部方格單元上操作,所以它對圖像幾何的和光學的形變都能保持很好的不變性,這兩種形變只會出現在更大的空間鄰域上。
完整的檢測篷布有無的算法步驟如下:
(1)將圖像灰度化以后用雙三次插值法統一縮放到高128,寬320的尺寸。
(2)以16×16像素的cell大小,2×2cells的block大小提取block無交疊的HOG特征,梯度方向統計范圍為-180度到180度之間均勻分布的9個區間。
(3)將各幅圖像的HOG特征向量排列成特征矩陣作為加權極限學習機的輸入進行訓練,其中權重為訓練集中每類樣本數的倒數。
(4)使用訓練好的加權極限學習機模型對測試樣本進行預測判斷篷布有無。
為了判斷篷布是否存在破洞,繩網斷線,積水等情況,HOG這種刻畫物體形狀的特征不適合描述。以樣本數最多的篷布積水情況為例,肉眼識別時主要依賴存在的反光現象,因此引入另一個描述灰度變化的紋理特征描述子LBP(Local Binary Pattern)來輔助篷布故障情況的判斷。某像素點LBP特征的計算原理是考慮一定采樣半徑的圓形鄰域內的鄰近像素點,假設采集P個采樣點,將這P個采樣點的灰度值同該中心點灰度值比較,若采樣點灰度值大于中心點灰度值,則該采樣點位置標記為1,否則為0,這樣P個采樣點可以形成P位二進制數,即為中心點的LBP值,可以反映該鄰域的紋理信息。該定義僅僅滿足灰度不變性,為了得到旋轉不變的特征,研究人員提出如下改進:不斷旋轉圓形鄰域得到一系列LBP值,取最小值作為鄰域的旋轉不變LBP特征。
除了HOG和LBP這些經典的特征,作者還提出了一種手工構造的特征,能夠較好的反映積水圖片的反光特點。該特征的構造方法為:首先將圖像的四周各裁去50像素以去除不含篷布網繩的無關部分。裁剪后的圖像轉為灰度圖,并用雙三次插值法縮放到高514,寬2400的尺寸。隨后將該灰度圖等分為48小塊,高度方向4等分,寬度方向12等分。對每一小塊,找出該小塊中灰度值最高的一個像素點,然后在該像素點的上下左右四個方向計算該像素點的灰度值同周圍像素點灰度值之差。其中每個方向都取同該像素點距離為10,15,20,25,30個像素的鄰近點計算灰度差值。若這些距離處的鄰近點越出邊界,則取為邊界點。
由此可以得到在蓋有篷布的貨車頂照片中識別故障篷布的完整算法如下:
(1)將圖像灰度化以后用雙三次插值法統一縮放到高614,寬1200的尺寸。
(2)在每一像素半徑為2像素的圓形鄰域內采集8個采樣點計算旋轉不變的LBP特征,計算鄰近采樣點時采用線性插值。
(3)再將圖片裁剪灰度化后縮放到高514,寬2400的尺寸提取上述手工特征。
(4)將LBP特征和手工特征排列成特征矩陣,并用MINMAX方法歸一化特征矩陣的每一列。
(5)特征矩陣作為加權極限學習機的輸入進行訓練,其中權重為訓練集中每類樣本數的倒數。
(6)使用訓練好的加權極限學習機模型將有篷布圖片分為正常或故障兩類。
以上算法中涉及的極限學習機的理論在文獻[4]中有較為詳細的介紹。考慮到苫蓋有篷布的敞車數量遠少于沒有篷布的其他貨車數量,訓練集樣本是不均衡的,因此采用了樣本加權的方式考慮不均衡性。所述加權正則化極限學習機的理論概要如下,設單隱層前饋神經網絡的輸出層和隱層神經元數分別為m和l,則關于輸入特征向量的第j維輸出表達式為:
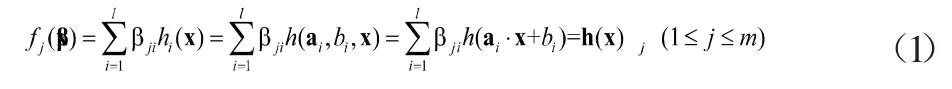
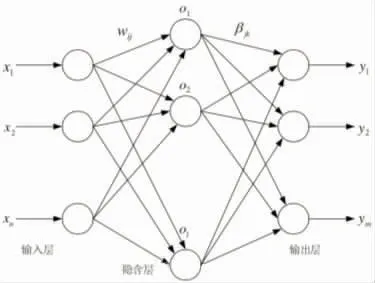
圖3 極限學習機神經網絡結構示意圖
加權正則化極限學習機采用的是逐樣本加權的方式,每個樣本的訓練權重等于訓練集中該類樣本的樣本數的倒數,可以證明這是最優的權重。所有樣本的權重排列成一個N×N對角矩陣W。其中N是訓練集樣本數。加權正則化極限學習機輸出層權值β的學習結果由如下公式給出:

上式中C是正則化參數,通過反復試驗,針對本問題正則化參數C取為30。W是樣本權重矩陣,H是隱層輸出矩陣,由如下公式給出:
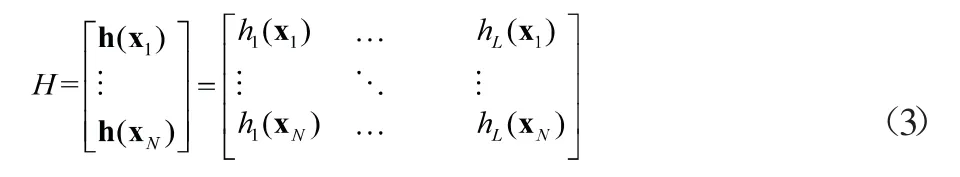
根據以上公式得出極限學習機的算法步驟如圖4所示:
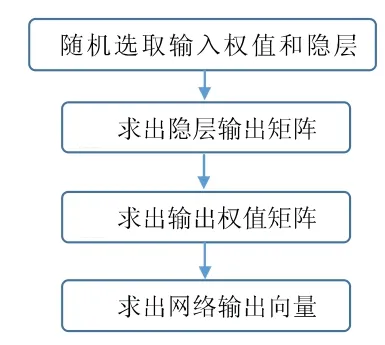
圖4 極限學習算法應用步驟
3 算法運行結果
以上兩個算法在數據集上的運行結果如下:
就區分有篷布的敞車和其他無篷布貨車的算法來說,訓練集包含2872張有篷布苫蓋車頂照片以及3088張無篷布車頂照片。測試集包含7197張有篷布苫蓋車頂照片和102099張無篷布車頂照片。所有圖片均為三通道彩色圖片。除極少數圖片外,各圖片高度統一為614像素,寬度大致分布在2000-3100像素間。算法在如上數據集上取得了99.98%的訓練集準確率以及96.40%的測試集準確率和99.61%的測試集召回率。
在另一套數據集中,訓練集包含3548張圖,其中有篷布苫蓋的圖有1739張。無篷布的圖有1809張。測試集包含115004張圖,其中無篷布的圖有106674張,有篷布的圖有8330張。區分篷布有無的算法取得了99.71%的測試集準確率,99.13%的測試集精確度和96.90%的測試集召回率。
就區分篷布是否有故障的算法而言,共有10069張有篷布車頂照片,正常苫蓋狀態篷布為一類,問題篷布為另一類,訓練集1739張圖片,測試集8330張圖片,訓練集和測試集中正常圖片,積水圖片,斷線和破洞圖片張數比例大致和10069張圖的數據全集相同。在這樣的訓練集和測試集條件下,該算法取得了99.88%的訓練集準確率以及95.94%的測試集召回率和69.94%的測試集準確率。
區分篷布是否有故障的算法,如果去掉LBP特征,單用筆者構造的手工特征可以起到提升準確率的效果。單用手工特征的加權極限學習分類器在935個訓練樣本上訓練后能夠在9134個樣本的測試集上取得87.83%的準確率。但是召回率僅有75.05%。原因在于,同上文以LBP和手工特征為特征的分類器相比,誤分類的負樣本數FN增加,而誤分類的正樣本數FP減少了。
本文介紹的算法訓練時對于硬件要求低,不需要GPU,速度能夠滿足實際工程要求。其次由于本算法準確率較高,因而其人工標定成本也較低。標定時可以先手工標定小量幾百張訓練圖片用算法預運行一趟得到全部圖片粗估分類值,然后再予以人工修正即可,大大減輕了手工標定數萬張圖的工作量。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
