云計算環境中HDFS數據塊存儲策略研究
2020-11-02 02:36:18袁愛平陶志勇鄧河陳為滿
電腦知識與技術 2020年26期
袁愛平 陶志勇 鄧河 陳為滿

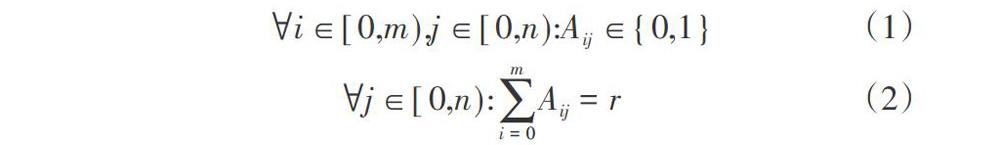
摘要:HDFS(Hadoop Distributed File System)以流式數據訪問模式存儲超大文件,具有高可靠性、高擴展性、低成本等特性,已廣泛運行于商用硬件集群中。但在云計算系統中,由于采用了虛擬化技術,文件存儲時如采用HDFS默認的存儲策略,將帶來數據可靠性的下降。本文通過對HDFS存儲方法的改進,提出了一種充分考慮云環境中虛擬機存儲位置的數據塊存儲策略,避免了多個數據塊副本存儲在同一臺物理機器上。實驗結果證明,該方法均衡了數據塊在物理節點中的存儲,提高了系統的可靠性。
關鍵詞:云計算;HDFS;位置感知;數據存儲
中圖分類號:TP301 文獻標識碼:A
文章編號:1009-3044(2020)26-0033-03
Abstract: HDFS (Hadoop Distributed File System), which stores large files in streaming data access mode, has the characteristics of high reliability, high scalability and low cost, and has been widely used in commercial hardware clusters. However, in the cloud computing system, due to the virtualization technology, if the default storage strategy of HDFS is used in file storage, the data reliability will be reduced. Through the improvement of HDFS storage method, this paper proposes a data block storage strategy that fully considers the storage location of virtual machine in cloud environment, avoiding multiple data block copies stored on the same physical machine. Experimental result shows that this method balances the placement of data blocks in physical nodes and improves the reliability of the system.
Key words: cloud computing; HDFS; location awareness; data storage
隨著信息技術的快速發展,各種應用系統正在以前所未有的速度產生出大量的數據,怎樣對這些數據進行高效處理已成為人們迫切關注的問題。Google公司研究提出了MapReduce并行計算模型和方法,以簡單方便地完成大規模數據的編程和計算處理。受到Google公司MapReduce思想的影響,開源系統Hadoop也在內部實現了MapReduce計算框架,以一種可靠、高效、可伸縮的方式處理海量數據。Hadoop不要求集群中的機器高配置,大部分普通商用服務器就可以滿足要求,它通過提供多個副本和容錯機制來提高集群的可靠性。為了滿足大數據應用對資源的動態需求,將大數據系統部署到云計算平臺中已成為目前的一種趨勢。云計算平臺資源分配靈活,能夠實現“按需獲取”,方便了廣大中小型企業或者個人對大數據應用的使用。
1 HDFS存儲系統
HDFS是一個以分布式方式存儲的文件系統,主要負責數據的存儲與讀取,它運行于商用硬件集群上,單個 HDFS 集群可以擴展至幾千甚至上萬個節點[1]。HDFS集群是一個主/從結構的分布式文件系統,有一個NameNode節點和多個DataNode節點。NameNode節點管理文件系統的元數據和控制著外部客戶機的訪問,DataNode節點則是文件系統的工作節點,它是真正存儲數據的地方。為了安全起見,在集群中通常還有一個Secondary NameNode節點,用于備份NameNode中的數據。HDFS和磁盤一樣,以數據塊作為數據讀/寫的最小單位,默認為64MB,這樣做的目的是最小化尋址開銷。用戶存儲在HDFS中的文件被劃分成幾個數據塊,分布式地存儲在DataNode節點上。
HDFS存儲數據塊的副本時,它會盡量使副本放置在不同機架下面的DataNode節點中,以保證數據的可靠性。當副本數是3時,HDFS的默認存儲策略是把第1個副本放在客戶端機器上,第2個副本放在與第1個副本不同機架下的節點中,第3個副本放在與第2個副本相同機架下且隨機選擇的一個節點中。當副本數超過3時,其他副本則會放在集群中隨機選擇的節點上,不過系統會盡量避免在相同的機架上放太多副本。一旦選定副本的放置位置,就會根據網絡拓撲創建一個管線。總的來說,這一方法不僅提供很好的穩定性并實現了負載均衡,包括寫入帶寬、讀取性能和集群中塊的均勻分布。
對于同構環境的物理集群,HDFS的默認數據塊存儲策略能夠保證數據的可靠性,而在基于虛擬技術的云計算平臺中,同一個物理機器里面會共存多個虛擬機,此時如把虛擬機節點當作物理機節點對待來存儲數據,將帶來數據可靠性的下降。
2 云中HDFS數據塊存儲設計
2.1 云中HDFS數據塊存儲研究現狀分析
針對同構環境的數據放置策略不一定適合異構的云計算環境,學者們開展了廣泛的研究。Zaharia等人[2]通過對集群計算框架中異常任務的檢測優化,提高任務的備份成功率,從而提高云計算環境中數據的可靠性。針對云計算環境中網絡資源的共享和競爭等問題,Lei[3] 針對數據塊副本分發問題,提出了一種發現虛擬機內聚性的機制,并設計了一種新的基于聚類的虛擬環境副本排列和組合重執行調度技術,減少了任務的響應時間,降低了數據傳輸成本,而針對云中的節點異構性特點,Geng等人[4]從理論上分析了虛擬環境中的數據分配問題,設計了一種文件塊分配策略,實現了更好的數據冗余和負載平衡,提高了應用程序的執行性能。與此同時,在地域異構的云數據中心,Chen等人[5] 建立了最優數據放置問題,提出了一種拓撲感知的啟發式算法,構造了抽象樹結構的副本平衡分布樹和細節樹結構的副本相似度分布樹,有效地降低全局數據訪問成本,減少了意外的遠程數據訪問,提高了MapReduce在云數據中心的性能。通過總結可以發現,由于云計算環境的虛擬機節點失效常態化、異構性和虛擬網絡拓撲結構多樣性等特點,現有的數據存儲策略具有一定的局限性。
2.2 感知虛擬機位置的數據塊存儲策略
HDFS默認采用機架感知的策略分配數據塊的存儲位置,它支持樹形的層次網絡拓撲結構,如圖1,其中D表示數據中心,R表示機架交換機,H表示數據存儲節點。一個集群可能跨越多個數據中心,而每個數據中心又包含有多個機架交換機,各個物理機器節點位于機架交換機下面。通常情況下,同一個機架交換機的網絡傳輸帶寬比跨越不同機架交換機的數據交換帶寬要高,即將同一個數據塊的多個副本放置到同一個機架交換機內部時,能夠減少數據寫入和讀取的時間,但是,若機架交換機發生故障,則將導致整個交換機內的物理機器不能與外通信,使得機架內部的數據不能被訪問[6]。
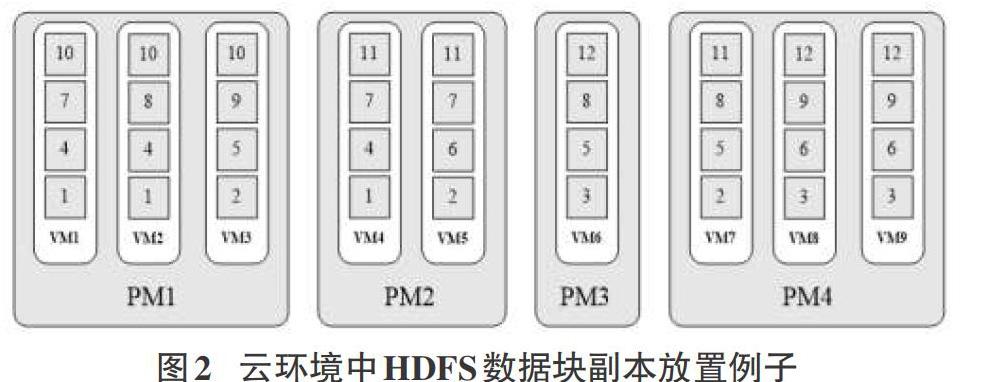
在云環境中,由于一個物理機器中包含多個虛擬機,當某個物理主機發生故障時,主機中的虛擬機節點都將不可用,也就意味著位于虛擬機中的同一個數據塊的兩個甚至多個副本會同時丟失。以圖2為例,當物理機節點PM1發生故障時,位于PM1中的數據塊10的所有副本都會丟失,導致文件存儲的可靠性降低。
為了避免虛擬機共存對數據可靠性的影響,可以充分利用虛擬節點在物理宿主機中的位置信息來實現更好的數據塊分配。定義任意兩臺虛擬機之間的網絡距離如下:
在云環境中,一個Hadoop集群往往含有多個機架交換機,在交換機下面又包括多個物理服務器。假設有m個虛擬機節點存在物理服務器中,表示為(vm1, vm2, ..., vmm)。我們定義一個距離矩陣D標識不同虛擬機之間的網絡距離,矩陣大小為m*m,Dij則對應了節點vmi和vmj的網絡距離,它們之間的網絡距離值如上定義。當客戶端向集群寫入數據塊時,假設文件包含的數據塊個數為n,副本的個數為r,則集群需要為每個數據塊尋找r個節點位置,總共的位置個數為n*r。對于每個數據塊,有可能放置到m個虛擬機節點中的任一個,則n個數據塊可能放置的位置個數為n*m。我們定義一個數據塊分布矩陣A,其中Aij表示數據塊j是否被放置到了虛擬機節點vmi。為了加強數據塊可靠性,定義如下的限制條件。
公式(1)限制了每個數據塊至多只能有一個副本放置在同一個虛擬機節點中,公式(2)則限制了在m個虛擬機節點中,每個數據塊應該有r個不同的副本。
當為某個數據塊尋找副本存儲位置時,需要查找距離矩陣D,從中找出滿足數據可靠性限制條件的節點,作為該數據塊的副本存儲位置,處理流程如圖3所示。
3 實驗與結果分析
我們在基于OpenStack的私有云計算平臺中構建了一個Hadoop集群環境,Hadoop版本為2.6.4。集群中包括1個NameNode節點和9個DataNode節點,所有節點均被配置為3個虛擬計算核,4GB的內存和50GB的磁盤空間。我們配置了2個千兆機架交換機,一個交換機下配置了3臺物理機器,另一個交換機下配置了2臺物理機器。我們使用RandomWriter工具生成4GB、8GB和16GB三個不同大小的數據集,并且使用不同的策略(HDFS默認策略和本文提出的優化策略)將它們寫入HDFS集群中。在實驗中數據塊的大小被設置為64MB,副本因子為3。隨后我們對不同數據集的數據可靠性指標進行了統計,結果顯示采用HDFS的默認放置策略,幾乎只有70%的數據塊能夠實現分配到不同的物理機節點之中,而基于本文提出的存儲優化策略,100%的數據塊都能被分配到不同的物理機節點中,意味著它們能達到與同構物理環境相同的可靠性,統計結果如表1。
4 結束語
本文通過對HDFS的數據存儲和云計算環境中虛擬機資源調度的研究,分析了云環境中影響數據可靠性存儲的因素,設計了一種基于位置感知的數據塊存儲策略,實現了不同副本的隔離放置。最后在OpenStack私有云計算平臺通過實驗進行了驗證,結果表明與HDFS默認的數據塊副本放置策略相比,本文提出的優化放置方法能夠很好地把數據塊副本分配到不同的物理機節點之中,提高了數據的可靠性。
參考文獻:
[1] Konstantin S, Hairong K, Sanjay R, Robert C. The Hadoop Distributed File System[M]. In: Proc. of MSST. 2010: 1-10.
[2] Zaharia M, Chowdhury M, Franklin M. J, et al. Spark: cluster computing with working sets[C]//Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, 2010: 10.
[3] Lei L. Towards a high performance virtual hadoop cIuster[J]. Journal of Convergence Information Technology, 2018, 7(6): 292-303.
[4] Geng Y, Chen S, Wu Y, et al. Location-aware mapreduce in virtual cloud[C]//Parallel Processing(ICPP), 2018 International Conference[S.1.]:IEEE, 2018:275-284.
[5] Chen W, Paik I, Li Z. Tology-aware optimal data placement algorithm for network traffic optimization[J]. IEEE Transactions on Computers, 2016, 65(8): 2603-2617.
[6] 徐華. 基于云的大數據處理系統性能優化問題研究[D]. 合肥:中國科學技術大學,2018:55-59.
【通聯編輯:梁書】
猜你喜歡
辦公室業務(2016年11期)2017-01-09 18:02:44
中國科技博覽(2016年24期)2016-12-28 23:25:48
電子技術與軟件工程(2016年20期)2016-12-21 11:11:51
電腦知識與技術(2016年28期)2016-12-21 10:13:14
電腦知識與技術(2016年27期)2016-12-15 20:33:05
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
