融合二維姿態(tài)信息的相似多目標(biāo)跟蹤
2020-11-02 11:53:00雷景生李譽(yù)坤楊忠光
計(jì)算機(jī)工程與設(shè)計(jì) 2020年10期
雷景生,李譽(yù)坤,楊忠光
(上海電力大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,上海 200090)
0 引 言
近年來(lái),計(jì)算機(jī)視覺(jué)技術(shù)發(fā)展迅速,其中多目標(biāo)跟蹤算法的研究備受?chē)?guó)內(nèi)外學(xué)者的關(guān)注。在這些研究中,主要方式是用度量學(xué)習(xí)提取目標(biāo)核心特征,根據(jù)特征差異完成多目標(biāo)跟蹤,例如Person Re-ID[1];或者基于深度神經(jīng)網(wǎng)絡(luò)提取目標(biāo)特征并引入濾波器與匹配算法以此關(guān)聯(lián)相鄰幀的目標(biāo)身份信息實(shí)現(xiàn)多目標(biāo)跟蹤,如POI[2]、SORT[3]、Deep SORT[4]。上述主流的目標(biāo)跟蹤方式在道路、商場(chǎng)等大多數(shù)生活場(chǎng)景中都能完成精確度較高的實(shí)時(shí)移動(dòng)目標(biāo)跟蹤任務(wù),但在移動(dòng)目標(biāo)較為相似的工廠工作場(chǎng)景中,傳統(tǒng)的跟蹤算法大多不能發(fā)揮良好的效果,其算法局限性在于工廠工作環(huán)境下,工作人員被要求穿著統(tǒng)一的工作服,佩戴安全帽,這樣不同目標(biāo)間的特征不能明顯被區(qū)分,因此僅根據(jù)外觀特征無(wú)法完成正確的跟蹤任務(wù)。
為解決相似多目標(biāo)場(chǎng)景下的跟蹤難題,本文在傳統(tǒng)的跟蹤算法之上融入其它維度的信息輔助判定目標(biāo)身份完成跟蹤,其主體流程分為目標(biāo)檢測(cè)和跟蹤兩個(gè)階段,通過(guò)對(duì)比f(wàn)ast R-CNN[5]、faster-RCNN[6]、SSD[7]、YOLO V2[8]、YOLO v3[9]等算法選擇高效精確的目標(biāo)檢測(cè)器并對(duì)Deep SORT算法進(jìn)行改進(jìn),根據(jù)相鄰幀之中相同目標(biāo)的姿態(tài)相似,不同目標(biāo)的姿態(tài)特征區(qū)分度較高這一特性將目標(biāo)的人體姿態(tài)特征信息與跟蹤算法相融合,在姿態(tài)的維度放大目標(biāo)特征,消除相似目標(biāo)外觀特征區(qū)分度低造成的消極影響,提高多目標(biāo)跟蹤的準(zhǔn)確度。
本文以相關(guān)理論介紹、算法實(shí)現(xiàn)和實(shí)驗(yàn)分析對(duì)比3個(gè)方面闡述相似多目標(biāo)場(chǎng)景下的多目標(biāo)跟蹤方案,本文的主要貢獻(xiàn)包括:①對(duì)存在相似多目標(biāo)場(chǎng)景提出新穎的跟蹤方案。②在目標(biāo)跟蹤算法的目標(biāo)檢測(cè)階段,對(duì)比多種算法,篩選出最高效的檢測(cè)框架。③多目標(biāo)跟蹤過(guò)程中減少了目標(biāo)身份互換次數(shù),并解決目標(biāo)短暫遮擋后無(wú)法繼續(xù)跟蹤的問(wèn)題。
1 相關(guān)理論
1.1 二維人體姿態(tài)識(shí)別
本文中使用的人體姿態(tài)信息根據(jù)OpenPose[10]算法計(jì)算得出,該算法由美國(guó)卡耐基梅隆大學(xué)提出,并開(kāi)源為學(xué)者提供研究,OpenPose是首個(gè)基于深度學(xué)習(xí)實(shí)現(xiàn)的多人實(shí)時(shí)姿態(tài)識(shí)別算法,其主要做法是利用PAFs(part affinity fields)將人體圖像劃分為13個(gè)關(guān)鍵信息點(diǎn)并將其鏈接,從而進(jìn)行人體動(dòng)作、面部表情、手指運(yùn)動(dòng)等姿態(tài)估計(jì)。
OpenPose中采用的網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示,該網(wǎng)絡(luò)分上下兩個(gè)分支,每個(gè)分支都有t個(gè)階段,每個(gè)階段都會(huì)將feature maps進(jìn)行融合。
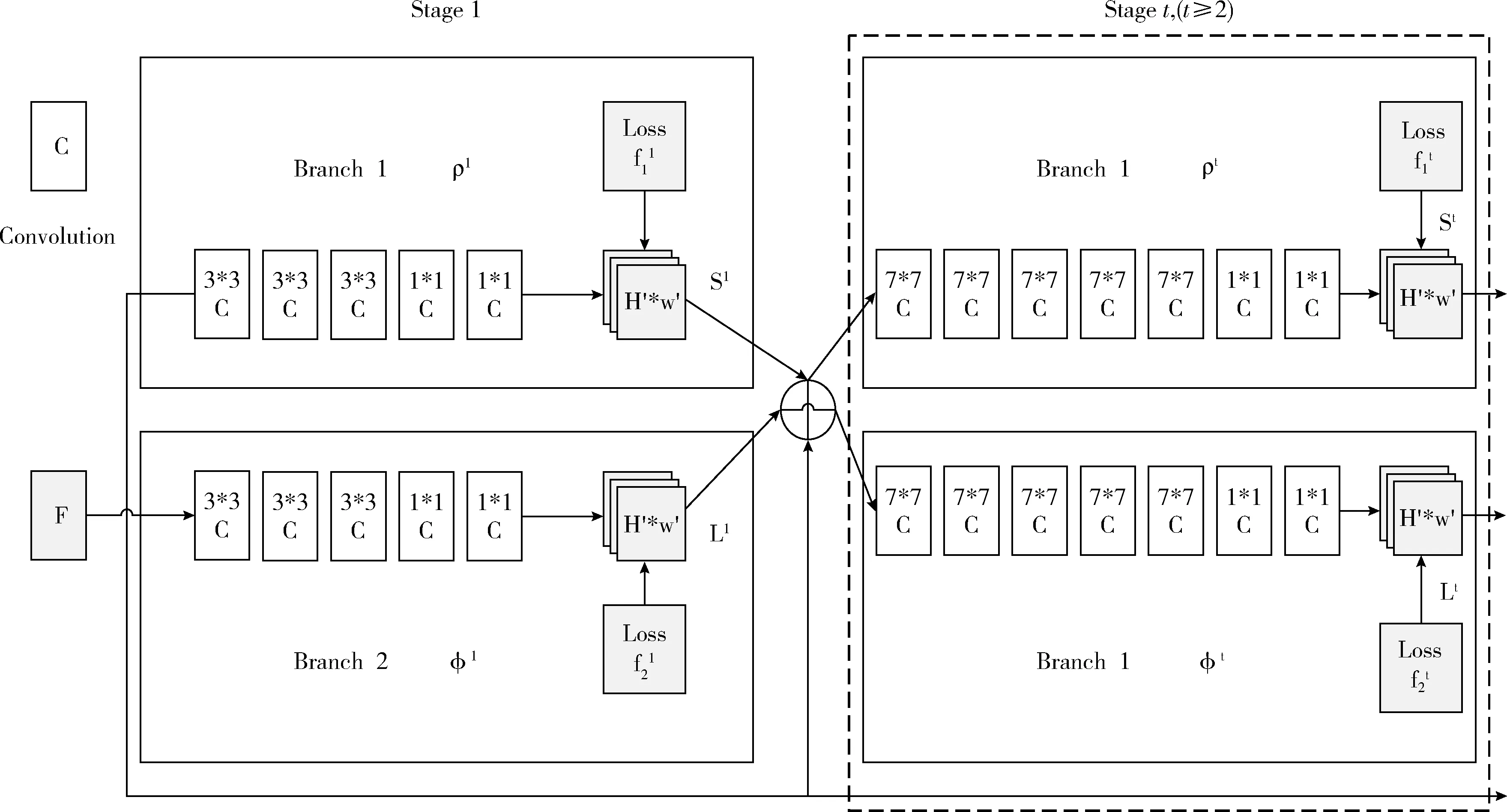
圖1 OpenPose網(wǎng)絡(luò)結(jié)構(gòu)
1.2 Deep SORT算法
Deep SORT算法采用傳統(tǒng)的單假設(shè)跟蹤方法,采用遞歸卡爾曼濾波和逐幀數(shù)據(jù)關(guān)聯(lián)來(lái)進(jìn)行多目標(biāo)的檢測(cè)跟蹤。系統(tǒng)核心組件如下:
軌道處理和狀態(tài)估計(jì):該算法使用一個(gè)標(biāo)準(zhǔn)的卡爾曼濾波器并采用線性觀測(cè)模型和勻速模型。算法的跟蹤場(chǎng)景定義在包含目標(biāo)狀態(tài)(u,v,γ,h,x,y,γ,h)的八維狀態(tài)空間上,其參數(shù)表示檢測(cè)框的中心位置信息、縱橫比信息、高度信息,以及速度信息。
目標(biāo)分配:用匈牙利算法求解卡爾曼預(yù)測(cè)狀態(tài)與測(cè)量值之間的分配問(wèn)題。算法通過(guò)結(jié)合兩個(gè)度量方式來(lái)整合運(yùn)動(dòng)和外觀信息。① 馬哈拉諾比斯距離簡(jiǎn)稱馬氏距離,表示數(shù)據(jù)的協(xié)方差距離,它能夠有效計(jì)算兩個(gè)不同維度不同特征樣本集間的相似度,馬氏距離度量的優(yōu)勢(shì)是它是可學(xué)習(xí)的,以數(shù)據(jù)為驅(qū)動(dòng),通過(guò)對(duì)樣本進(jìn)行訓(xùn)練,得到能夠滿足用戶給定的約束條件和反映樣本特性的距離度量矩陣。② 對(duì)于每個(gè)邊界框檢測(cè),計(jì)算目標(biāo)外觀特征與每個(gè)軌跡中目標(biāo)的外觀特征的最小余弦距離。③ 采用融合度量學(xué)習(xí)的方法,設(shè)置權(quán)重系數(shù),對(duì)兩種度量方式進(jìn)行加權(quán)平均,使用匈牙利算法對(duì)track和detect進(jìn)行最優(yōu)分配。最終算法結(jié)合兩種度量方式的優(yōu)勢(shì),及考慮到了目標(biāo)的運(yùn)動(dòng)信息又可將外觀信息加以輔助判斷。
級(jí)聯(lián)匹配:如果在跟蹤時(shí),目標(biāo)對(duì)應(yīng)的軌跡被遮擋了一段較長(zhǎng)的時(shí)間,卡爾曼濾波預(yù)測(cè)的不確定性就會(huì)增加。如果此時(shí)有多個(gè)追蹤器同時(shí)匹配同一個(gè)目標(biāo)的檢測(cè)結(jié)果,由于遮擋時(shí)間較長(zhǎng)的軌跡長(zhǎng)時(shí)間未更新位置信息,導(dǎo)致卡爾曼濾波預(yù)測(cè)的位置會(huì)出現(xiàn)比較大的偏差,使得檢測(cè)結(jié)果更可能和遮擋時(shí)間較長(zhǎng)的那條軌跡相關(guān)聯(lián),從而降低跟蹤算法的性能。本文采用關(guān)聯(lián)算法與優(yōu)先分配策略,首先從小到大匹配消失時(shí)間相同的軌跡,保障了最近出現(xiàn)目標(biāo)的優(yōu)先權(quán),其次將未匹配的軌跡更具IoU指標(biāo)進(jìn)行分配,最大程度緩解遮擋或者外觀信息突變?cè)斐傻牟涣加绊憽?/p>
深度外觀描述符:通過(guò)使用簡(jiǎn)單的最近鄰查詢而不需要額外的度量學(xué)習(xí)。算法使用卷積神經(jīng)網(wǎng)絡(luò)提取目標(biāo)外觀特征,構(gòu)建了wide ResNet,其中有兩個(gè)卷積層,后面是6個(gè)剩余塊。在全連接層10中計(jì)算出了尺寸為128的總體特征圖。
2 融合二維姿態(tài)信息的相似多目標(biāo)跟蹤框架與算法
本文提出融合二維姿態(tài)信息的相似多目標(biāo)跟蹤框架來(lái)解決相似多目標(biāo)跟蹤問(wèn)題,框架主要由目標(biāo)檢測(cè)器、姿態(tài)提取器和目標(biāo)跟蹤器組成,其中目標(biāo)檢測(cè)器包含基于YOLO v3的目標(biāo)檢測(cè)算法,姿態(tài)提取器包含二維人體姿態(tài)估計(jì)算法,目標(biāo)跟蹤器包含信息融合算法、目標(biāo)指派算法和級(jí)聯(lián)匹配算法。整體算法流程如圖2所示。
2.1 制作與準(zhǔn)備數(shù)據(jù)集
目標(biāo)檢測(cè)階段數(shù)據(jù)集:由于本文算法采用YOLO v3作為目標(biāo)檢測(cè)器,因此需要制作出相似目標(biāo)場(chǎng)景下的數(shù)據(jù)集,用于訓(xùn)練目標(biāo)權(quán)重模型。本文實(shí)驗(yàn)在訓(xùn)練模型時(shí)準(zhǔn)備了1000張工廠場(chǎng)景下的圖片,利用LabelImage標(biāo)注出圖像中的工作人員制作出VOC數(shù)據(jù)集用來(lái)訓(xùn)練。由于本文算法僅對(duì)相似的工作人員做跟蹤,所以在標(biāo)注階段僅僅只需對(duì)圖像中的工作人員以person類(lèi)進(jìn)行標(biāo)注。
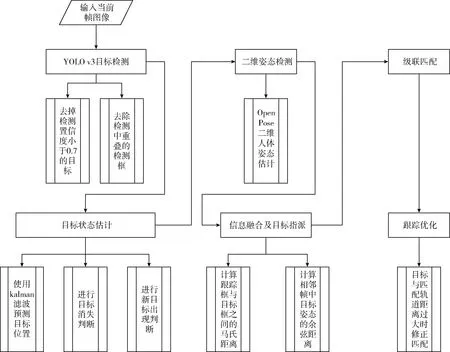
圖2 DeepSORT算法流程
多目標(biāo)跟蹤階段數(shù)據(jù)集:本文使用兩個(gè)數(shù)據(jù)集對(duì)算法進(jìn)行分別測(cè)試,本文用此數(shù)據(jù)集驗(yàn)證算法是否具有可靠的跟蹤能力。另一個(gè)測(cè)試集是包含相似多目標(biāo)的特殊場(chǎng)景數(shù)據(jù)集。此數(shù)據(jù)集是4320幀組成的視頻,該視頻中存在3個(gè)工作人員目標(biāo),并頻繁出現(xiàn)目標(biāo)交叉遮擋,以此數(shù)據(jù)集對(duì)比本文算法與其它跟蹤算法,討論本算法在特殊場(chǎng)景下的跟蹤優(yōu)勢(shì)。
2.2 目標(biāo)檢測(cè)算法的實(shí)現(xiàn)
使用Deep SORT進(jìn)行目標(biāo)需要先進(jìn)行目標(biāo)檢測(cè),目標(biāo)檢測(cè)的質(zhì)量對(duì)于后期的目標(biāo)跟蹤至關(guān)重要,因此需要選擇精確且高效的目標(biāo)檢測(cè)算法。本文在目標(biāo)檢測(cè)階段先制作了以存在相似目標(biāo)的工作環(huán)境為基礎(chǔ)的圖片數(shù)據(jù)集,然后在該數(shù)據(jù)集上對(duì)faster-RCNN、SSD、YOLO v3這3種目標(biāo)檢測(cè)框架進(jìn)行對(duì)比,對(duì)比結(jié)果見(jiàn)實(shí)驗(yàn)部分。最終確定了速度與精度俱佳的YOLO v3框架,YOLO v3是基于深度卷積神經(jīng)網(wǎng)絡(luò)的目標(biāo)識(shí)別和定位算法,整個(gè)網(wǎng)絡(luò)結(jié)構(gòu)只由卷積層組成,輸入的圖像僅僅經(jīng)過(guò)一次網(wǎng)絡(luò)就能完成目標(biāo)的分類(lèi)與定位,所以檢測(cè)速度比較快,能夠滿足變電站實(shí)時(shí)性要求。它創(chuàng)造性的將目標(biāo)候選區(qū)域選擇與識(shí)別這兩個(gè)階段任務(wù)合成一個(gè),僅僅使用一次特征提取,就能準(zhǔn)確地檢測(cè)出目標(biāo)并定位其位置。算法實(shí)現(xiàn)部分如下:
將數(shù)據(jù)集圖像70%作為訓(xùn)練集,30%作為驗(yàn)證集訓(xùn)練工作人員模型權(quán)重;首先對(duì)圖像進(jìn)行特征提取。
算法使用了darknet-53神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),如圖3所示,采用殘差網(wǎng)絡(luò)的思想,交替使用3×3與1×1卷積神經(jīng)網(wǎng)絡(luò),簡(jiǎn)化了resnet神經(jīng)網(wǎng)絡(luò),加快訓(xùn)練速度。
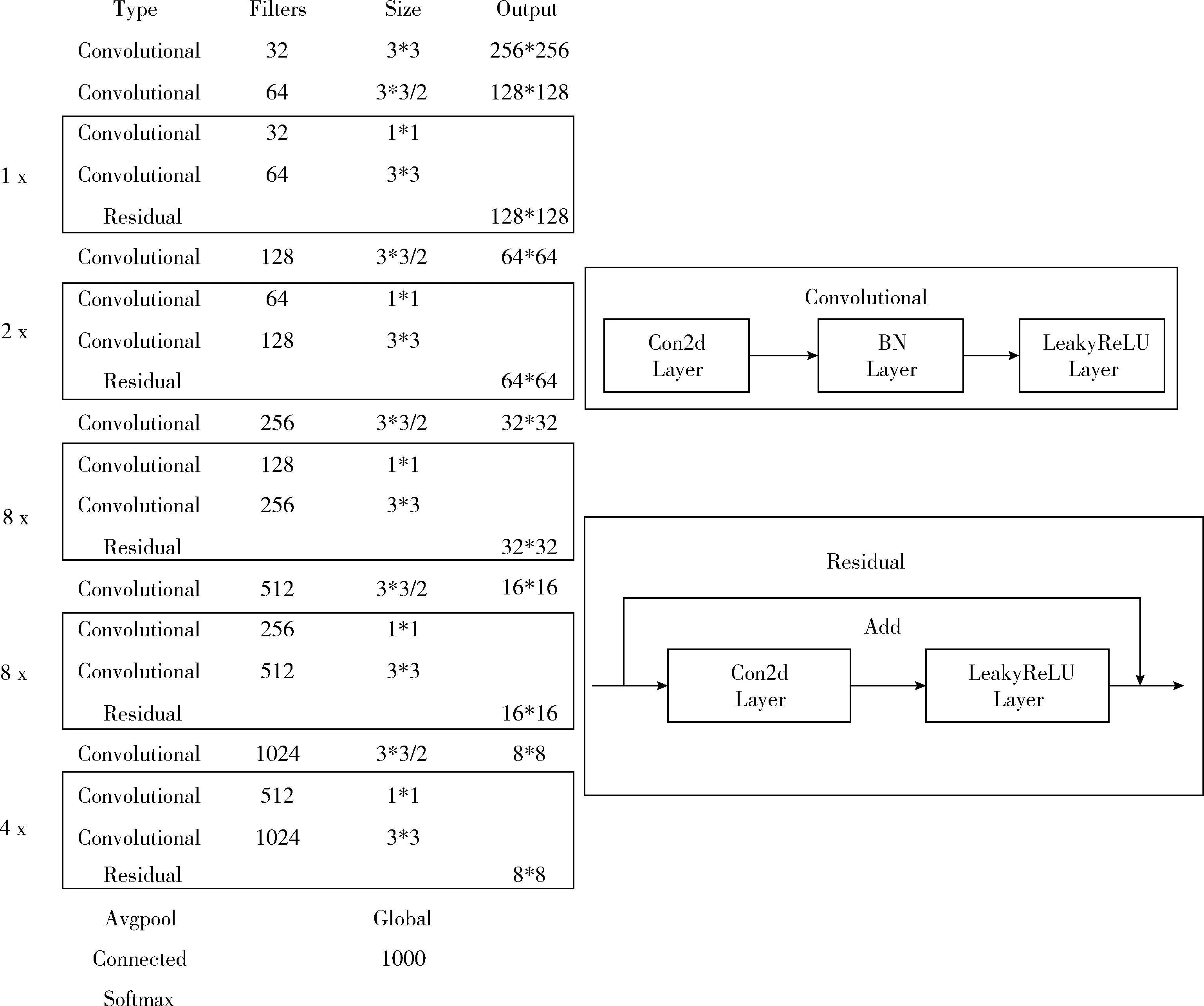
圖3 YOLO v3網(wǎng)絡(luò)結(jié)構(gòu)
由于只需對(duì)工作人員這一種類(lèi)別進(jìn)行檢測(cè),所以訓(xùn)練時(shí)需要把特征圖輸出張量深度設(shè)為18:每個(gè)網(wǎng)格單元預(yù)測(cè)3個(gè)檢測(cè)框,每個(gè)檢測(cè)框需要有5個(gè)基本參數(shù)和1個(gè)類(lèi)別的概率。所以3*(5+1)=18。
確定檢測(cè)框的方式是通過(guò)神經(jīng)網(wǎng)絡(luò)將圖像劃分為13×13的網(wǎng)格檢測(cè)目標(biāo),若目標(biāo)存在則每個(gè)網(wǎng)格生成3個(gè)檢測(cè)框并計(jì)算相應(yīng)的置信度,其中每個(gè)檢測(cè)框有5個(gè)預(yù)測(cè)值(X,Y,W,H,Conf),X與Y是預(yù)測(cè)框的中心相對(duì)于單元邊界的偏移,W和H是預(yù)測(cè)的框?qū)挾扰c整個(gè)圖像的比率,Conf表示檢測(cè)框的置信度。Pr(class|object)代表網(wǎng)格預(yù)測(cè)行人的條件概率。在檢測(cè)時(shí),將條件概率乘以不同檢測(cè)框置信度的預(yù)測(cè)值,以獲得每個(gè)檢測(cè)框工作人員類(lèi)別的置信度分?jǐn)?shù)。
整個(gè)訓(xùn)練過(guò)程中激活函數(shù)選用leaky ReLU;損失函數(shù)為坐標(biāo)誤差、IoU誤差和分類(lèi)誤差的總方誤差
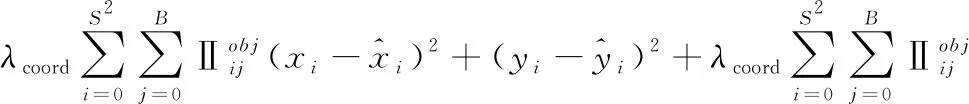
(1)
其中,i代表網(wǎng)格單元,最大值是S的平方,j為邊界框預(yù)測(cè)值,最大值為B,w和h是邊界框的寬度和高度,x和y代表邊界框中心坐標(biāo)。
其它參數(shù)選擇方面,本文通過(guò)實(shí)驗(yàn)結(jié)果對(duì)比進(jìn)行不斷調(diào)優(yōu),最終對(duì)比發(fā)現(xiàn)epoch為500時(shí)loss達(dá)到全局最優(yōu)值12.4。
2.3 二維人體姿態(tài)估計(jì)
執(zhí)行二維姿態(tài)估計(jì)模塊:本文將OpenPose算法進(jìn)行修改,對(duì)移動(dòng)目標(biāo)的姿態(tài)進(jìn)行識(shí)別,分析得出圖像中人體的二維姿態(tài)信息,并以18個(gè)人體關(guān)鍵點(diǎn)作為展示。具體算法流程如下:
(1)改進(jìn)原始網(wǎng)絡(luò):本文算法的核心是將二維姿態(tài)信息與跟蹤算法相結(jié)合,為提高算法的執(zhí)行效率需優(yōu)化姿態(tài)識(shí)別模塊的運(yùn)行速度。本文將原來(lái)的7*7的卷積替換成1*1,3*3,3*3的卷積級(jí)聯(lián)。為了讓這個(gè)級(jí)聯(lián)結(jié)構(gòu)與7×7的卷積核有同樣的感受野,使用dilation=2的空洞卷積。因?yàn)樵酱蟮木矸e核,計(jì)算量也就越大,就感受野的大小來(lái)看,3個(gè)3*3的卷積等價(jià)于一個(gè)7*7的卷積,但是計(jì)算量卻少了很多。卷積核替換如圖4所示。
(2)輸入原始圖像,圖像經(jīng)過(guò)構(gòu)造好的卷積神經(jīng)網(wǎng)絡(luò)生成一組特征映射集合F,網(wǎng)絡(luò)采用VGG pre-train network作為骨架,有兩個(gè)分支分別回歸L(p)和S(p)。每一個(gè)步驟算一次loss,之后為了區(qū)分左右結(jié)構(gòu),需要將L和S輸入連接層,繼續(xù)下一個(gè)步驟的深入訓(xùn)練。loss用的L2范數(shù),S和L的ground-truth需要從標(biāo)注的關(guān)鍵點(diǎn)生成,如果某個(gè)關(guān)鍵點(diǎn)在標(biāo)注中有缺失則不計(jì)算該點(diǎn),最終完成part confidence maps和part affinity fields的提取。
(3)得到上述兩個(gè)信息后,使用圖論中的偶匹配求出部件關(guān)聯(lián),將同一個(gè)人的關(guān)節(jié)點(diǎn)連接起來(lái),最終合并為一個(gè)人的整體框架。
(4)最后基于PAFs求解多人姿態(tài)檢測(cè)。
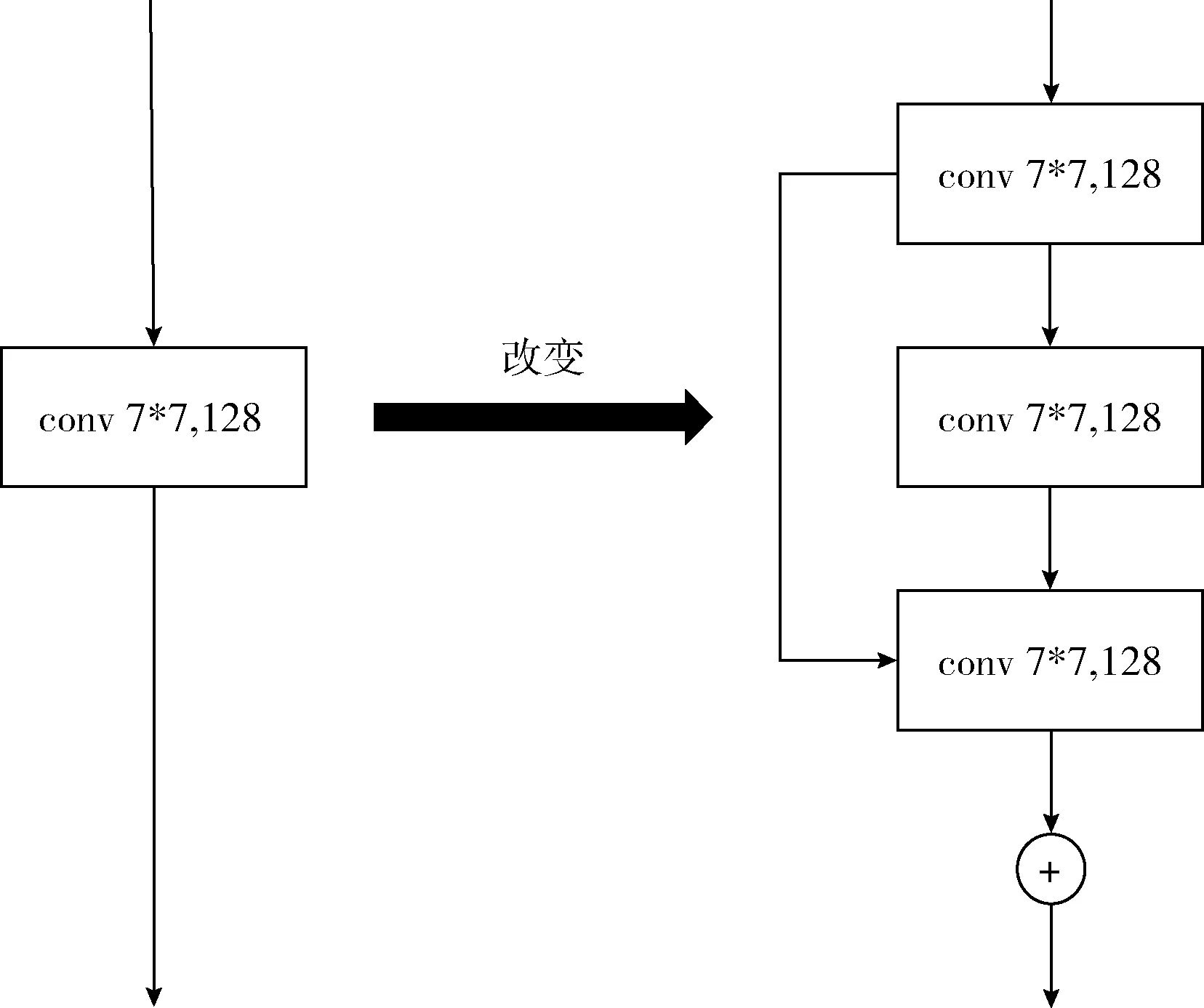
圖4 OpenPose卷積核替換
2.4 融合二維姿態(tài)信息的跟蹤算法
本文從人體姿態(tài)歸一化的行人重識(shí)別方法中獲得啟發(fā),將二維人體姿態(tài)信與Deep SORT跟蹤算法相結(jié)合并進(jìn)行改進(jìn),算法流程如圖4所示。
(1)執(zhí)行目標(biāo)檢測(cè):使用訓(xùn)練好的YOLO v3針對(duì)工作人員的目標(biāo)檢測(cè)模型作為Deep SORT算法的目標(biāo)檢測(cè)部分。
(2)做狀態(tài)估計(jì):將當(dāng)前幀檢測(cè)到的目標(biāo)坐標(biāo)信息存入detection集合中,將歷史檢測(cè)到的目標(biāo)坐標(biāo)信息存入track集合中,如果detection集合為空集,就將丟失幀計(jì)數(shù)加1,若丟失幀計(jì)數(shù)超過(guò)設(shè)定閾值時(shí),就認(rèn)為該目標(biāo)已消失,然后將該目標(biāo)的歷史坐標(biāo)信息從track中刪除,重新進(jìn)行檢測(cè)。如果detection集合不為空,將丟失幀數(shù)計(jì)數(shù)置為0,繼續(xù)下一步。此外使用一個(gè)基于勻速模型和線性觀測(cè)模型的標(biāo)準(zhǔn)卡爾曼濾波器對(duì)目標(biāo)的運(yùn)動(dòng)狀態(tài)進(jìn)行預(yù)測(cè),也即對(duì)track 集合進(jìn)行預(yù)測(cè)得到包含預(yù)測(cè)結(jié)果的track_pre集合;采用卡爾曼濾波方法來(lái)跟蹤目標(biāo)時(shí),過(guò)程為:首先對(duì)輸入視頻幀中的目標(biāo)采用YOLOv3 算法進(jìn)行檢測(cè),檢測(cè)得到目標(biāo)當(dāng)前時(shí)刻的狀態(tài),包括目標(biāo)的位置、寬高、速度加速度等信息,而后將這些參數(shù)作為卡爾曼濾波器的輸入,得到目標(biāo)下一時(shí)刻的狀態(tài)估計(jì);通過(guò)觀察得到下一時(shí)刻目標(biāo)的觀測(cè)值并且通過(guò)觀測(cè)值對(duì)目標(biāo)的跟蹤區(qū)域進(jìn)行確定,最后結(jié)合下一時(shí)刻目標(biāo)的觀測(cè)值與當(dāng)前時(shí)刻目標(biāo)的估計(jì)值,對(duì)當(dāng)前時(shí)刻目標(biāo)狀態(tài)的后驗(yàn)估計(jì)值、狀態(tài)矩陣及相關(guān)參數(shù)進(jìn)行更新。通過(guò)此過(guò)程對(duì)Kalman濾波器中的相關(guān)參數(shù)進(jìn)行反復(fù)的更新,使得Kalman濾波器的估計(jì)值與實(shí)際值間的誤差越來(lái)越小。經(jīng)過(guò)長(zhǎng)時(shí)間的處理,卡爾曼濾波器能夠很好預(yù)測(cè)出目標(biāo)的狀態(tài),從而最終預(yù)測(cè)出移動(dòng)目標(biāo)的軌跡。
(3)融合姿態(tài)維度信息進(jìn)行目標(biāo)指派:使用馬氏距離計(jì)算物體檢測(cè)框dj和物體跟蹤框yi之間的距離d,公式為
d(1)(i,j)=(dj-yi)TSi-1(dj-yi)
(2)
使用余弦距離來(lái)度量各個(gè)軌道的外觀特征r(128維)和檢測(cè)目標(biāo)外觀特征之間的距離,來(lái)更準(zhǔn)確地預(yù)測(cè)ID,公式為
di,j(2)(i,j)=min{1-rjTrk(i)|rk(i)∈Ri}
(3)
其中外觀使用的是當(dāng)前幀目標(biāo)的二維姿態(tài)信息;最后使用聯(lián)合距離來(lái)作為代價(jià)矩陣進(jìn)行度量各個(gè)軌道和檢測(cè)目標(biāo)之間的距離。在軌道處理方面,本文對(duì)傳統(tǒng)DeepSort算法進(jìn)行了改進(jìn),傳統(tǒng)方法認(rèn)為單獨(dú)使用馬氏距離最為匹配度度量會(huì)導(dǎo)致身份轉(zhuǎn)換等情形嚴(yán)重,因此計(jì)算檢測(cè)目標(biāo)和軌道的最新的100個(gè)目標(biāo)進(jìn)行計(jì)算最小余弦距離,選擇軌道中最近多個(gè)目標(biāo)是因?yàn)橥粋€(gè)軌道中存放的是同一個(gè)目標(biāo)的特征,而在本文實(shí)驗(yàn)中,姿態(tài)特征代替了外觀特征,相同目標(biāo)僅在相鄰幀中姿態(tài)特征相似,為此實(shí)驗(yàn)中將軌道中100個(gè)目標(biāo)更換成最新的1個(gè)目標(biāo),來(lái)計(jì)算姿態(tài)特征的余弦距離。
(4)進(jìn)行級(jí)聯(lián)匹配:物體被遮擋一段時(shí)間后,卡爾曼濾波預(yù)測(cè)的不確定性大大增加并且狀態(tài)空間上可觀察性變得很低,并且馬氏距離更傾向于不確定性更大的軌道,因此這里引入級(jí)聯(lián)匹配,優(yōu)先匹配檢測(cè)目標(biāo)與最近出現(xiàn)的軌道。
(5)進(jìn)行跟蹤優(yōu)化:實(shí)驗(yàn)發(fā)現(xiàn),相似多目標(biāo)跟蹤過(guò)程中常出現(xiàn)身份轉(zhuǎn)換問(wèn)題,此類(lèi)問(wèn)題的出現(xiàn)是因?yàn)闄z測(cè)目標(biāo)匹配了錯(cuò)誤的軌道,因此在算法中記錄每一個(gè)目標(biāo)上一幀的位置,在完成級(jí)聯(lián)匹配后計(jì)算檢測(cè)目標(biāo)與上一幀此身份目標(biāo)檢測(cè)框的歐氏距離,當(dāng)距離大于檢測(cè)框?qū)挾鹊?/4時(shí)認(rèn)定匹配錯(cuò)誤,進(jìn)行重新匹配身份。
經(jīng)過(guò)使用融合二維姿態(tài)信息的DeepSORT算法之后,可以完成在模擬存在相似目標(biāo)的工作場(chǎng)景監(jiān)控視頻下的多目標(biāo)跟蹤。
3 實(shí)驗(yàn)與分析
實(shí)驗(yàn)硬件環(huán)境:CPU:Intel Core i7-6700HQ,內(nèi)存:8 GB,GPU:RTX2080 8 GB顯存,操作系統(tǒng):Linux Ubuntu18.04,硬盤(pán)空間:80 GB。
軟件環(huán)境:pycharm集成開(kāi)發(fā)環(huán)境、anaconda 3.7、python 3.6、keras 2.0.8、opencv 4.0和tensorflow 1.12等。
數(shù)據(jù)集見(jiàn)表1,1000張存在工作人員的場(chǎng)景照片制作的VOC格式數(shù)據(jù)集訓(xùn)練YOLO模型,MOT16 CHALLENGE標(biāo)準(zhǔn)數(shù)據(jù)集,4320幀模擬存在相似移動(dòng)目標(biāo)的工作場(chǎng)景監(jiān)控視頻。
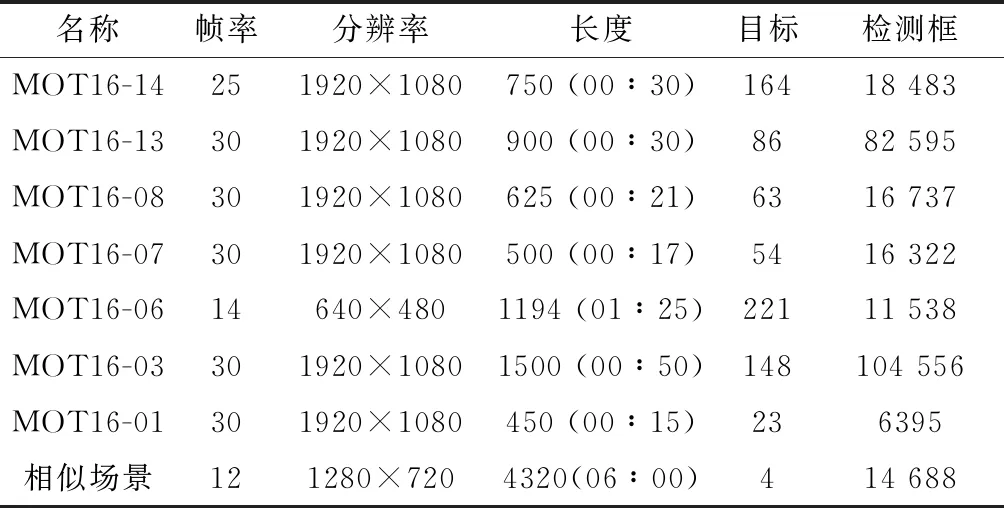
表1 測(cè)試數(shù)據(jù)集
3.1 檢測(cè)階段算法分析
本文算法在目標(biāo)檢測(cè)階段選用YOLO v3框架,用腳本文件生成損失函數(shù)的變化曲線與IoU變化曲線如圖5所示,其中l(wèi)oss隨訓(xùn)練次數(shù)的增加呈現(xiàn)梯度下降趨勢(shì),并在訓(xùn)練300次左右下降趨勢(shì)逐漸趨于平緩,500次達(dá)到局部最優(yōu)值12.4。IoU隨著訓(xùn)練次數(shù)增加不斷提高。詳細(xì)結(jié)果如圖5所示。
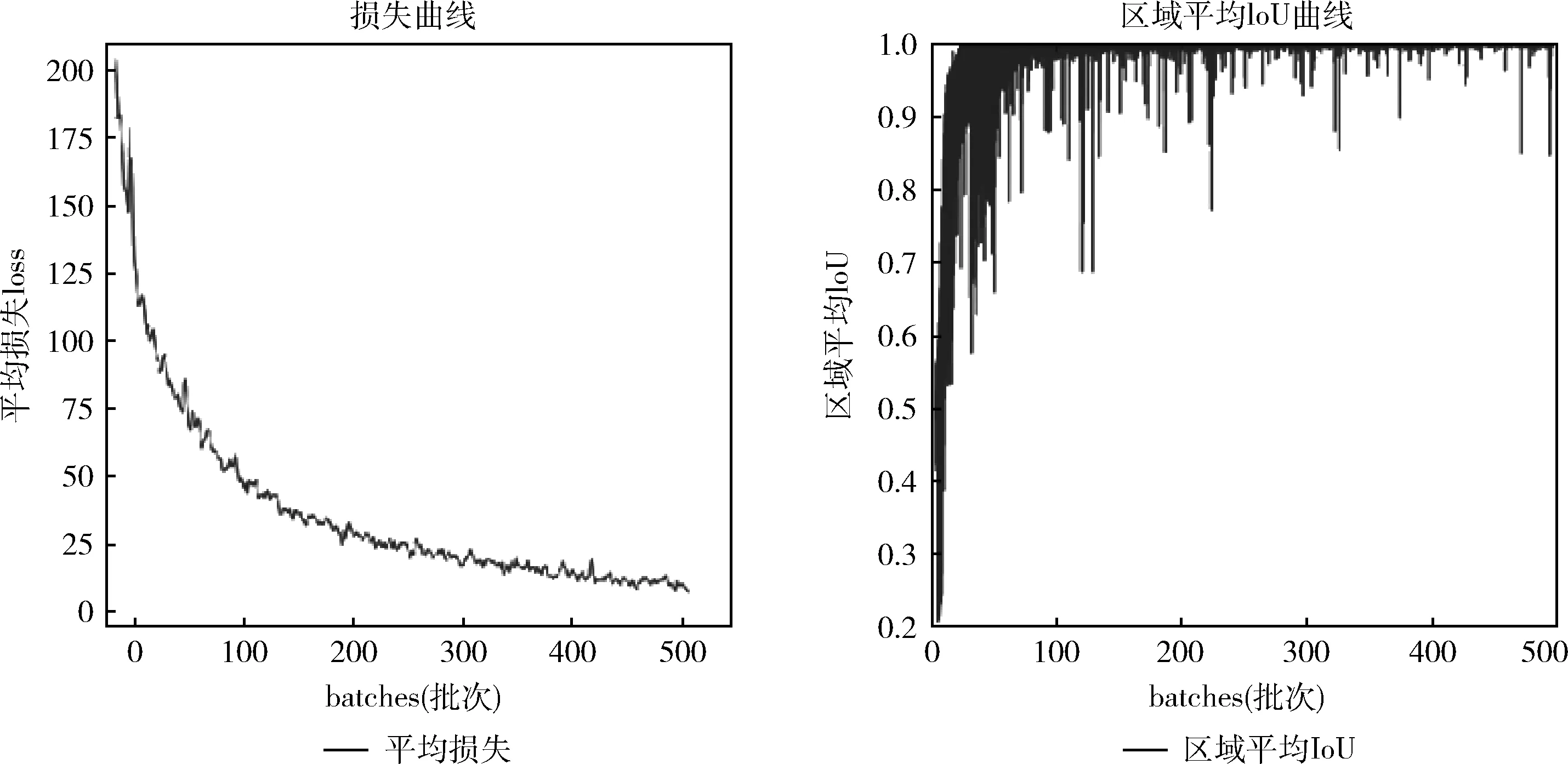
圖5 YOLO v3 損失函數(shù)變化與IoU變化曲線
本實(shí)驗(yàn)與YOLO V2檢測(cè)算法進(jìn)行對(duì)比,見(jiàn)表2,在精確度方面提升1.2%,召回率提高1.9%,IoU提高1.7%。
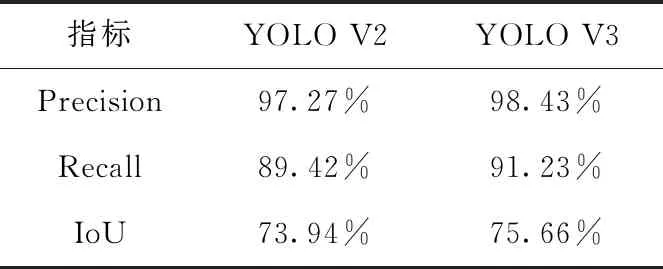
表2 YOLO v3與YOLO v2對(duì)比
本文還對(duì)比了在單目標(biāo)工作場(chǎng)景下,YOLO v3,YOLO v2,SSD這3種檢測(cè)算法作為DeepSort檢測(cè)器,檢測(cè)框中心點(diǎn)和實(shí)際目標(biāo)中心的歐式距離,其中實(shí)際目標(biāo)中心點(diǎn)為OpenPose人體姿態(tài)軀干的中心。繪制出的距離對(duì)比如圖6所示,其中折線圖斷點(diǎn)說(shuō)明檢測(cè)算法在該幀未檢測(cè)到目標(biāo);此圖反映出YOLO v3作為檢測(cè)器能夠更準(zhǔn)確檢測(cè)出目標(biāo)。
3.2 相似多目標(biāo)跟蹤實(shí)驗(yàn)結(jié)果分析
本文評(píng)估了跟蹤器在MOT16 CHALLENGE數(shù)據(jù)集上的效果,見(jiàn)表3,基準(zhǔn)測(cè)試包括由7個(gè)序列組成的訓(xùn)練和測(cè)試集,比較了其它已發(fā)表的方法,全表結(jié)果[11]可以在MOT16 CHALLENGE網(wǎng)站上找到。
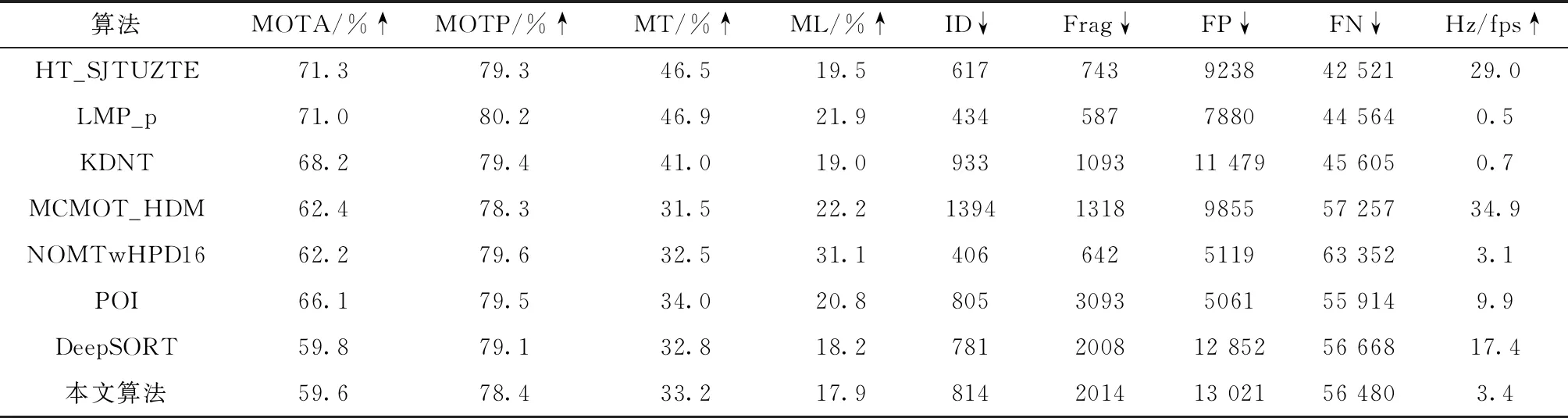
表3 MOT16 CHALLENGE數(shù)據(jù)集上測(cè)試結(jié)果對(duì)比
由于MOT16 CHALLENGE數(shù)據(jù)集上多目標(biāo)之間差異較大,每個(gè)行人都穿著不同服裝,這使得在此環(huán)境中外觀信息的作用大于二維姿態(tài)信息,故在跟蹤效果上略優(yōu)于本文算法;其次計(jì)算二維人體姿態(tài)估計(jì)算法計(jì)算量巨大,十分依賴GPU運(yùn)算性能,所以在處理頻率略慢,fps維持在3.4左右。實(shí)驗(yàn)結(jié)果表明本文算法在多目標(biāo)跟蹤的精確性(MOTP)和準(zhǔn)確度(MOTA)上與傳統(tǒng)的Deep SORT跟蹤算法相似,具備較為精確的目標(biāo)跟蹤能力。
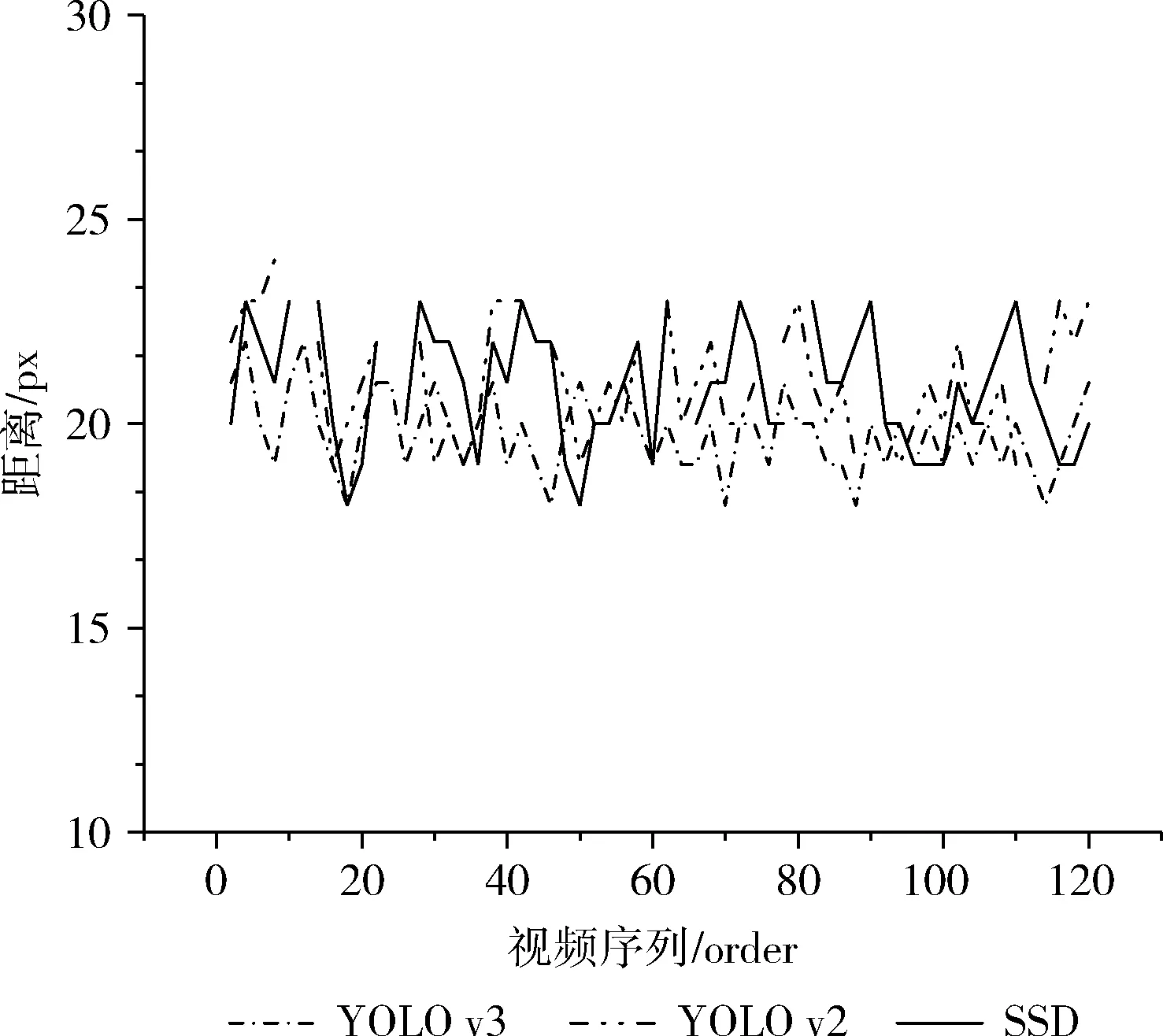
圖6 目標(biāo)檢測(cè)框中心與目標(biāo)中點(diǎn)距離
為突出本文算法在存在相似目標(biāo)環(huán)境中的跟蹤優(yōu)勢(shì),使用模擬存在相似目標(biāo)的視頻作為數(shù)據(jù)集,將本文算法和其它算法進(jìn)行了詳細(xì)對(duì)比,如圖7所示。由于本文實(shí)驗(yàn)在建立在DeepSORT跟蹤算法之上,并融合二維人體姿態(tài)信息進(jìn)行改進(jìn),所以對(duì)比算法選用Deep SORT。其中在Deep SORT跟蹤算法中,目標(biāo)檢測(cè)算法對(duì)跟蹤的精確度有著直接影響,所以本文將使用YOLO v3作檢測(cè)器并融合二維姿態(tài)的多目標(biāo)跟蹤算法與基于SSD、YOLO v2、YOLO v3作檢測(cè)器的傳統(tǒng)Deep SORT算法在MOTA(multiple object tracking accuracy)和MOTP(multiple object tracking precision)兩個(gè)指標(biāo)上進(jìn)行對(duì)比
(4)
(5)
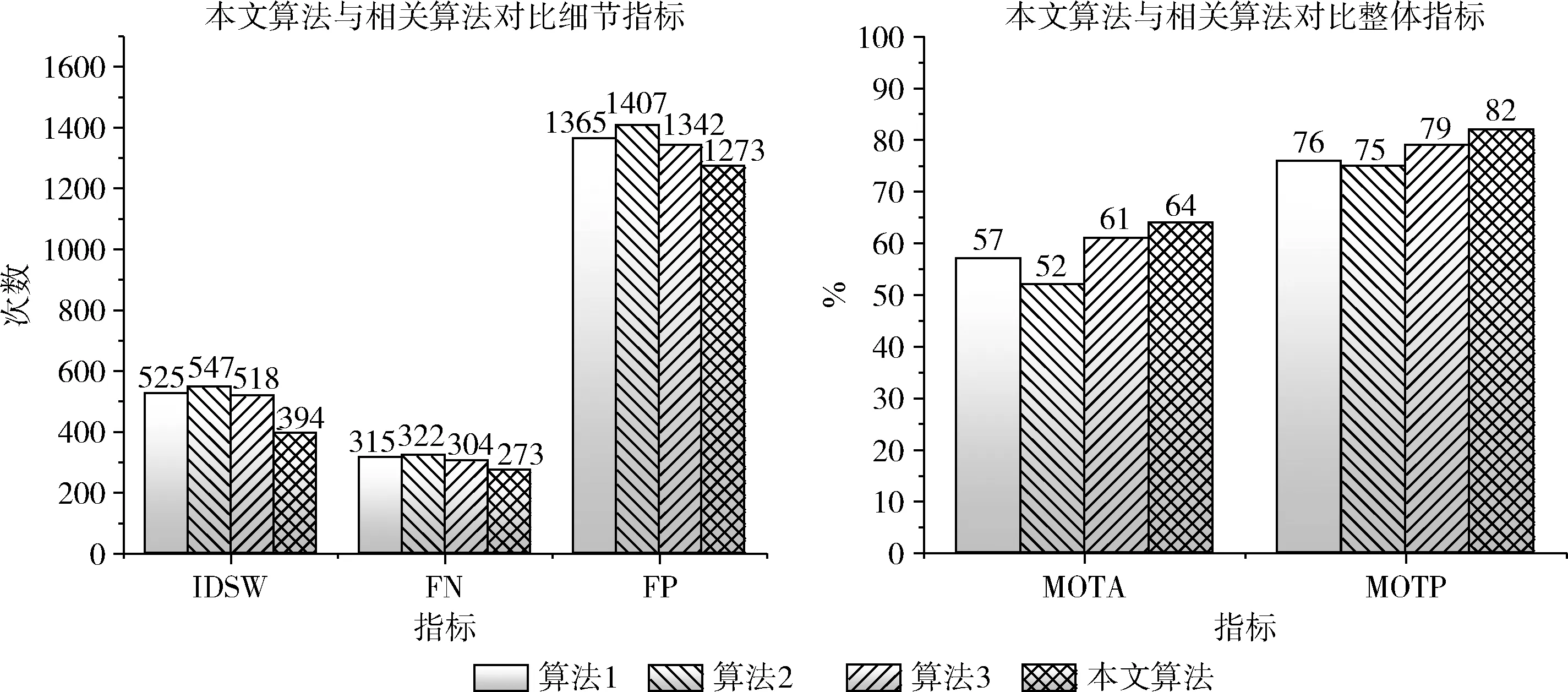
圖7 相關(guān)算法對(duì)比
當(dāng)前幀預(yù)測(cè)的軌道和檢測(cè)目標(biāo)沒(méi)有匹配上的這類(lèi)錯(cuò)誤預(yù)測(cè)軌道點(diǎn)稱為FP,未被匹配的Ground Truth點(diǎn)稱為FN,IDSW為Ground Truth所分配的ID發(fā)生變化的次數(shù),GT為Ground Truth目標(biāo)的數(shù)量。
本文采用模擬存在相似多目標(biāo)工作場(chǎng)景下的視頻進(jìn)行實(shí)驗(yàn),其中存在最多移動(dòng)目標(biāo)為4人,視頻共4320幀。算法1是SSD作檢測(cè)器的DeepSort算法;算法2是YOLO v2作檢測(cè)器的DeepSort算法;算法3是YOLO v3作檢測(cè)器的傳統(tǒng)DeepSort算法,本文算法是YOLO v3作檢測(cè)器融入姿態(tài)信息的改進(jìn)DeepSort算法。
實(shí)驗(yàn)結(jié)果表明,在模擬的存在相似多目標(biāo)的數(shù)據(jù)集中,本文算法與對(duì)比算法相比有著很大的優(yōu)勢(shì),這歸功于YOLO v3精確的目標(biāo)檢測(cè)和二維姿態(tài)信息的輔助跟蹤。實(shí)驗(yàn)中,以SSD和YOLO v2作為檢測(cè)器的Deep SORT算法一有嚴(yán)重的目標(biāo)丟失和目標(biāo)身份互換現(xiàn)象,在已檢測(cè)的目標(biāo)中,檢測(cè)框與實(shí)際目標(biāo)有一定的距離偏差,如圖8所示。而采用YOLO v3的Deep SORT算法中跟蹤目標(biāo)未匹配和錯(cuò)誤匹配的次數(shù)明顯降低,這反映出YOLO v3框架更適合作為跟蹤算法的檢測(cè)器;本文算法與同樣使用YOLO v3作檢測(cè)器的傳統(tǒng)算法相比MOTA與MOTP均有上升,約提升3%,也有更低的FP、FN、IDSW。隨著視頻時(shí)長(zhǎng)的增加,這一優(yōu)勢(shì)會(huì)更加明顯。

圖8 YOLO v2算法、SSD的算法缺陷
如以上實(shí)驗(yàn)結(jié)果所述:Deep SORT算法檢測(cè)階段的準(zhǔn)確度對(duì)跟蹤結(jié)果有著決定性的影響。在YOLO v2和SSD識(shí)別框架中,其準(zhǔn)確率的差距被放大,頻繁出現(xiàn)目標(biāo)丟失及目標(biāo)身份轉(zhuǎn)換等問(wèn)題,兩幀圖像中共有兩個(gè)移動(dòng)目標(biāo),第一張圖像右側(cè)目標(biāo)檢測(cè)框與目標(biāo)存在一定偏差,第二張圖像未能檢測(cè)到目標(biāo)。此外使用YOLO v2檢測(cè)器的跟蹤算法在未檢測(cè)到目標(biāo)之外還出現(xiàn)了誤檢測(cè)現(xiàn)象,檢測(cè)框內(nèi)沒(méi)有目標(biāo)。以上錯(cuò)誤均是因?yàn)闄z測(cè)器沒(méi)有準(zhǔn)確將移動(dòng)目標(biāo)識(shí)別,故濾波器不能獲取目標(biāo)正確位置,不能進(jìn)行預(yù)測(cè)后續(xù)目標(biāo)位置完成準(zhǔn)確跟蹤。
由于存在相似目標(biāo),傳統(tǒng)的DeepSORT算法的外觀信息沒(méi)能良好地發(fā)揮效能,因此在目標(biāo)重合再分離之后會(huì)出現(xiàn)身份交換問(wèn)題。對(duì)比實(shí)驗(yàn)結(jié)果表明,本文使用的融合了姿態(tài)信息的DeepSORT算法,在包含相似目標(biāo)的場(chǎng)景下均優(yōu)于對(duì)比實(shí)驗(yàn)中的3種算法,YOLO v3識(shí)別框架具有更高的識(shí)別精度,采用二維姿態(tài)信息代替外觀信息有效提高跟蹤算法的性能,改進(jìn)的跟蹤算法有效減少了目標(biāo)丟失概率且降低了身份互換次數(shù)如圖9所示。

圖9 本文算法最終跟蹤結(jié)果
4 結(jié)束語(yǔ)
本文針對(duì)傳統(tǒng)多目標(biāo)跟蹤算法在存在相似目標(biāo)的場(chǎng)景下精度不高、效率不足的問(wèn)題,提出了以DeepSORT算法為基礎(chǔ)融合二維姿態(tài)信息的相似多目標(biāo)跟蹤算法,并對(duì)算法進(jìn)行了實(shí)驗(yàn)。算法先進(jìn)性體現(xiàn)為:① 實(shí)驗(yàn)結(jié)果驗(yàn)證了本文算法在相似多目標(biāo)工作場(chǎng)景下跟蹤的準(zhǔn)確性;② 算法具有較高的魯棒性,在目標(biāo)出現(xiàn)短暫遮擋和消失時(shí)仍然能完成跟蹤;③ 與其它算法相比降低了目標(biāo)身份轉(zhuǎn)換的情況;但另一方面,本文算法的適應(yīng)性受場(chǎng)景中移動(dòng)目標(biāo)數(shù)量的影響,場(chǎng)景中存在的目標(biāo)越多,目標(biāo)間的遮擋越多,二維場(chǎng)景中的相似姿態(tài)多,跟蹤難度就越大。為此在未來(lái)的工作中,我們打算采取構(gòu)建三維模型,融合多視點(diǎn)信息進(jìn)行多目標(biāo)跟蹤的思路,致力于通過(guò)場(chǎng)景重建將二維姿態(tài)轉(zhuǎn)化為三維姿態(tài)信息,以全面提高算法準(zhǔn)確度與場(chǎng)景適應(yīng)性。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中外會(huì)展(2014年4期)2014-11-27 07:46:46
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
