基于神經(jīng)網(wǎng)絡(luò)的多注意屬性情感分析
2020-11-03 01:00:26陳閏雪
計(jì)算機(jī)工程與設(shè)計(jì) 2020年10期
陳閏雪,彭 龑?zhuān)?蓮
(四川輕化工大學(xué) 計(jì)算機(jī)學(xué)院,四川 自貢 643000)
0 引 言
情感分析又稱(chēng)意見(jiàn)挖掘,是對(duì)文本進(jìn)行處理、分析、抽取來(lái)挖掘文本的情感傾向。屬性情感分析屬于細(xì)粒度的情感分類(lèi)任務(wù),主要目的是識(shí)別上下文中某個(gè)屬性的情感極性,如積極、消極的情感。句子“the food is usually good but it certainly isn’t a relaxing place to go”中“food”屬性是積極的情感,而對(duì)于“place”是消極的情感,通過(guò)提取用戶(hù)對(duì)特定方面的反饋,反饋的信息有助于企業(yè)發(fā)現(xiàn)產(chǎn)品的具體缺陷,促使企業(yè)對(duì)產(chǎn)品的改進(jìn)。傳統(tǒng)的情感分類(lèi)算法難以從同一文本中不同方面提取不同的特征。由示例句子可知,距離目標(biāo)近的詞對(duì)目標(biāo)的影響較大,與目標(biāo)相關(guān)聯(lián)的意見(jiàn)表達(dá)以塊的結(jié)構(gòu)形式出現(xiàn)。當(dāng)句子中包含多個(gè)目標(biāo)時(shí),準(zhǔn)確的建模和提取這類(lèi)結(jié)構(gòu)信息是非常關(guān)鍵的。
1 相關(guān)工作
屬性情感分類(lèi)[1]需要同時(shí)考慮句子的上下文和目標(biāo)屬性的信息。傳統(tǒng)的機(jī)器學(xué)習(xí)方法是將情感分析作為一個(gè)文本分類(lèi)任務(wù),設(shè)計(jì)有效的特征提取方法訓(xùn)練分類(lèi)。Manek等[2]提出基于基尼系數(shù)的支持向量機(jī)特征選擇的情感分析方法,到達(dá)較好的效果。Vo等[3]設(shè)計(jì)具體的情感詞嵌入和情感詞匯來(lái)提取特征,最后進(jìn)行預(yù)測(cè)分析。這些方法依賴(lài)特征工程的有效性,易達(dá)到性能的瓶頸。
近幾年,基于神經(jīng)網(wǎng)絡(luò)的方法可直接將原始特征編碼為連續(xù)和低維向量,而不需要復(fù)雜的特征工程。Tang等[4]提出TD-LSTM模型,采用LSTM對(duì)方面的左上下文和右上下文進(jìn)行建模,最后將左右的輸出拼接起來(lái)作為最后的預(yù)測(cè)輸出。該方法沒(méi)有考慮目標(biāo)實(shí)體的屬性,當(dāng)句子中存在多個(gè)目標(biāo)實(shí)體時(shí),難以對(duì)其進(jìn)行精確的分類(lèi)。
Chen等[5]加入注意力機(jī)制來(lái)加強(qiáng)各目標(biāo)屬性對(duì)分類(lèi)的影響,關(guān)于注意力機(jī)制普遍采用求向量的均值來(lái)學(xué)習(xí)上下文的注意力權(quán)重。Ma等[6]在注意力機(jī)制的基礎(chǔ)上進(jìn)一步提出了雙向注意力機(jī)制,該機(jī)制額外學(xué)習(xí)注意力權(quán)重和上下文詞之間的關(guān)系。這類(lèi)方法沒(méi)考慮到目標(biāo)屬性,會(huì)導(dǎo)致一些目標(biāo)屬性和上下文關(guān)聯(lián)的信息丟失。
針對(duì)以上問(wèn)題,本文提出一種基于神經(jīng)網(wǎng)絡(luò)的多注意屬性情感分析模型。采用雙向長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)來(lái)提取上下文和目標(biāo)屬性的關(guān)聯(lián),加入了一種位置編碼機(jī)制來(lái)捕捉與目標(biāo)相鄰詞的重要信息,結(jié)合位置編碼和內(nèi)容注意力來(lái)更好提取上下文和目標(biāo)屬性的情感分類(lèi)。
2 情感分析模型
本文提出的模型結(jié)合了位置編碼和內(nèi)容注意力更加充分地學(xué)習(xí)不同屬性的情感特征信息。整體架構(gòu)如圖1所示,模型主要由輸入層、上下文層、多注意層和輸出層4部分組成。
2.1 任務(wù)定義
給出一個(gè)由n個(gè)詞組成的句子S={s1,s2,…,sn}和屬性方面列表A={a1,a2,…,ak}以及每個(gè)方面對(duì)應(yīng)的句子子序列ai={si1,si2,…,sim},m∈[1,n],多屬性情感分析是對(duì)句子中多個(gè)特定屬性進(jìn)行情感極性分析。
2.2 模 型
2.2.1 輸入層
輸入層將數(shù)據(jù)集中的單詞映射到低維、連續(xù)和實(shí)值的詞向量空間,所有的詞向量被堆疊到一個(gè)嵌入矩陣Lw∈Rd*|V|,其中d為詞向量的維數(shù),|V|為詞匯量。使用預(yù)先訓(xùn)練好的單詞向量“Glove”[7]來(lái)獲得每個(gè)單詞的固定嵌入。
2.2.2 上下文層
通過(guò)輸入層將單詞向量化,并將其作為上下文層的輸入。在上下文層使用雙向長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)[8](bidirectional long short-term memory,BiLSTM)來(lái)提取上下文和目標(biāo)的關(guān)聯(lián),標(biāo)準(zhǔn)的RNN會(huì)遇到梯度消失或爆炸的問(wèn)題,其中梯度可能在長(zhǎng)序列上呈指數(shù)增長(zhǎng)或衰減。所以用BiLSTM單元作為轉(zhuǎn)換函數(shù),可以更好模擬序列中的長(zhǎng)距離語(yǔ)義相關(guān)性。與標(biāo)準(zhǔn)的RNN相比,BiLSTM單元包含3個(gè)額外的神經(jīng)門(mén):輸入門(mén)、遺忘門(mén)和輸出門(mén)。這些門(mén)可以自適應(yīng)記住輸入向量,忘記以前的歷史,生成輸出向量。BiLSTM的更新過(guò)程如下
(1)
(2)
(3)
(4)
(5)
(6)
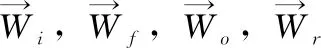
2.2.3 多注意層
注意機(jī)制[9]是捕捉上下文和目標(biāo)詞之間相互作用的一種常用方法,普遍采用粗粒度注意機(jī)制來(lái)學(xué)習(xí)上下文和目標(biāo)方面的注意權(quán)重,簡(jiǎn)單的求均值會(huì)帶來(lái)一些信息的損失,特別是對(duì)于多個(gè)目標(biāo)方面的句子。對(duì)此本文提出了一種細(xì)粒度的注意機(jī)制,通過(guò)BiLSTM網(wǎng)絡(luò)學(xué)習(xí)上下文和特征權(quán)重,結(jié)合位置權(quán)重來(lái)相互作用。實(shí)現(xiàn)步驟如下:
(1)上下文和目標(biāo)方面特征提取
對(duì)于輸入序列S={s1,s2,…,sn}通過(guò)BiLSTM提取目標(biāo)的上下文H∈2d*N和目標(biāo)屬性Q∈2d*M,如下所示
(7)
(8)
(2)上下文H更新
通過(guò)加入位置編碼機(jī)制對(duì)上下文H進(jìn)行更新,將式(7)聯(lián)合式(17)求出更新后的權(quán)重,捕捉位置信息和上下文之間的關(guān)聯(lián)
H=[H1*w1,H2*w2,…,HN*wN]
(9)
(3)求取上下文和目標(biāo)方面的交互矩陣
將BiLSTM提取的上下文和目標(biāo)方面的信息進(jìn)行矩陣的乘積,提取上下文目標(biāo)方面的關(guān)聯(lián)
I=H·QT
(10)
(4)對(duì)交互矩陣的行和列分別添加注意力分別得到α和β,然后在對(duì)它們求平均使其更加關(guān)注中心部分。計(jì)算公式如下所示
(11)
(12)
(13)
(14)
2.2.4 輸出層
將得到的注意力矩陣做內(nèi)積為m,然后將其輸入到一個(gè)確定情感極性的softmax層作為最終的輸出,計(jì)算如下所示
(15)
p=softmax(Wp*m+Bp)
(16)
其中,p∈C是目標(biāo)情感分類(lèi)的概率分布,Wp,Bp分別是權(quán)重矩陣和偏置矩陣。其中設(shè)置C=3,代表積極、中性和消極。
2.3 多注意機(jī)制
2.3.1 位置編碼機(jī)制
本文加入了位置編碼機(jī)制來(lái)模擬觀(guān)察,如上下文單詞的權(quán)重wt和目標(biāo)屬性方面的距離為l,lmax表示句子的實(shí)際長(zhǎng)度。計(jì)算公式如下
(17)
先將目標(biāo)屬性方面的單詞的權(quán)重設(shè)置為0,然后根據(jù)位置編碼機(jī)制[10]對(duì)上下文進(jìn)行初始化,這樣得到上下文輸出H=[H1*w1,H2*w2,…,HN*wN]。
2.3.2 強(qiáng)注意力機(jī)制
注意力機(jī)制主要是通過(guò)讓模型自動(dòng)的學(xué)習(xí)上下文和當(dāng)前屬性的關(guān)系,能夠挖掘出重要的特征屬性,為了更好學(xué)習(xí)上下文和目標(biāo)屬性的信息,本文提出一種強(qiáng)注意力機(jī)制。強(qiáng)注意力機(jī)制在注意力機(jī)制的基礎(chǔ)上再添加注意力,如式(11)~式(14)所示,分別再對(duì)行和列添加注意力機(jī)制,可以更加關(guān)注重要的部分。
2.4 模型訓(xùn)練
本文情感分析模型采用交叉熵?fù)p失函數(shù),使用L2正則化避免過(guò)擬合問(wèn)題。通過(guò)最小化損失函數(shù)來(lái)優(yōu)化模型對(duì)文本進(jìn)行屬性級(jí)情感分析任務(wù),如下所示
(18)
其中,λ是L2正則化參數(shù),θ是線(xiàn)性層和LSTM絡(luò)的權(quán)重矩陣,使用dropout以避免過(guò)度擬合。使用小批量隨機(jī)梯度下降算法來(lái)最小化模型中權(quán)重矩陣。
3 實(shí)驗(yàn)結(jié)果及分析
本文提出的模型在SemEval 2014數(shù)據(jù)集和twitter數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),通過(guò)引入預(yù)訓(xùn)練的Glove詞向量進(jìn)行詞嵌入,其中字典大小和訓(xùn)練的維度分別是1.9 MB和[25~300]維度。使用顯卡型號(hào)為T(mén)esla T4,驅(qū)動(dòng)版本SIM為410.79,CUDA版本為10.0,顯存為15 G,Linux系統(tǒng)服務(wù)器,深度神經(jīng)網(wǎng)絡(luò)框架為Pytorch 1.1.0。
3.1 實(shí)驗(yàn)數(shù)據(jù)和參數(shù)配置
laptop、restaurant和twitter數(shù)據(jù)集分為積極、中性和消極3類(lèi)標(biāo)記,按情緒極性分類(lèi)的分布情況見(jiàn)表1。
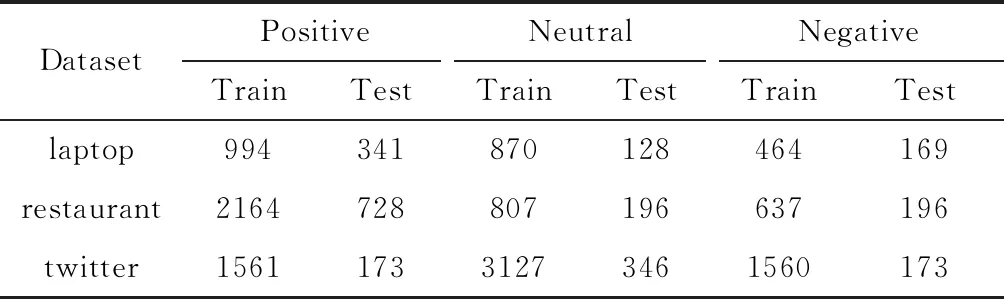
表1 實(shí)驗(yàn)數(shù)據(jù)集
參數(shù)配置:從均勻分布U(-e,e),e=0.0001隨機(jī)初始化權(quán)重矩陣,并將所有的偏置項(xiàng)設(shè)置為0,L2正則化系數(shù)設(shè)置為0.0001,dropout設(shè)置為0.2,將每個(gè)英文詞匯訓(xùn)練成25~300維的向量。
3.2 方法對(duì)比
將本文的算法和以下4種模型在SemEval 2014和twitter數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),主要用準(zhǔn)確率來(lái)度量性能。
(1)LSTM模型主要用LSTM網(wǎng)絡(luò)對(duì)句子進(jìn)行建模,將最后一個(gè)隱藏狀態(tài)作為句子的最終分類(lèi)。單一的LSTM模型對(duì)于一些特別的情感分類(lèi)可以達(dá)到一定的效果,但是沒(méi)有考慮到上下文和目標(biāo)信息的關(guān)聯(lián)。
(2)TD-LSTM[3]模型使用兩個(gè)LSTM網(wǎng)絡(luò)進(jìn)行建模,分別提取句子的方面和上下文。然后將兩個(gè)LSTM網(wǎng)絡(luò)的隱藏狀態(tài)連接起來(lái)預(yù)測(cè)情感極性。
(3)AT-LSTM[11]模型主要是通過(guò)注意力機(jī)制來(lái)獲取上下文信息,在LSTM模型中加入注意力機(jī)制進(jìn)行語(yǔ)義建模對(duì)情感進(jìn)行分類(lèi)。
(4)ATAE-LSTM[11]模型是AT-LSTM模型的擴(kuò)展,主要是在計(jì)算注意力權(quán)重的時(shí)候引入了特定目標(biāo)信息。
本文提出一種多注意神經(jīng)網(wǎng)絡(luò)模型,通過(guò)聯(lián)合注意力機(jī)制和位置編碼機(jī)制來(lái)挖掘上下文和目標(biāo)屬性的關(guān)聯(lián),使模型能對(duì)多個(gè)目標(biāo)進(jìn)行情感分類(lèi)。
3.3 實(shí)驗(yàn)結(jié)果分析
將本文提出的模型與4個(gè)基本模型(LSTM、TD-LSTM、AT-LSTM和ATAE-LSTM)進(jìn)行實(shí)驗(yàn)對(duì)比,將模型分別在SemEval 2014和twitter數(shù)據(jù)集上進(jìn)行訓(xùn)練和交叉驗(yàn)證。在本文的實(shí)驗(yàn)中,將文本映射成25~300維度詞向量,將SemEval 2014數(shù)據(jù)集(laptop和restaurant)和twitter數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果分別畫(huà)成柱狀圖如圖2~圖4所示,實(shí)驗(yàn)結(jié)果分別記錄見(jiàn)表2~表4。
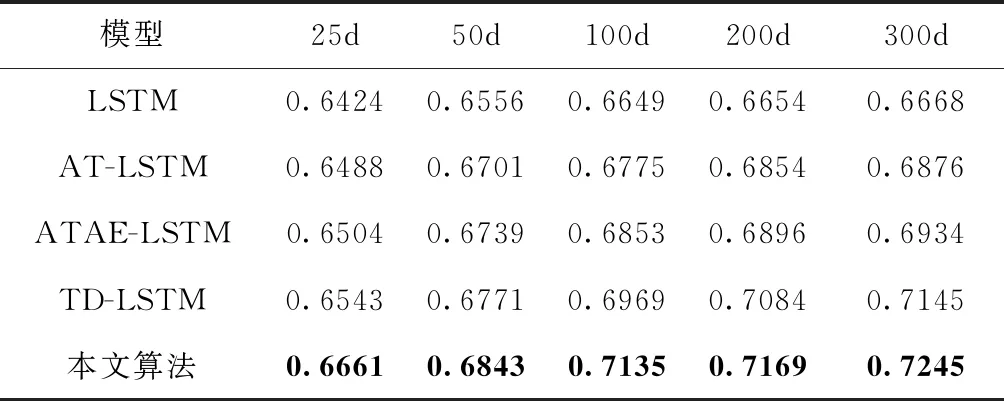
表2 laptop數(shù)據(jù)集上不同文本維度的準(zhǔn)確率
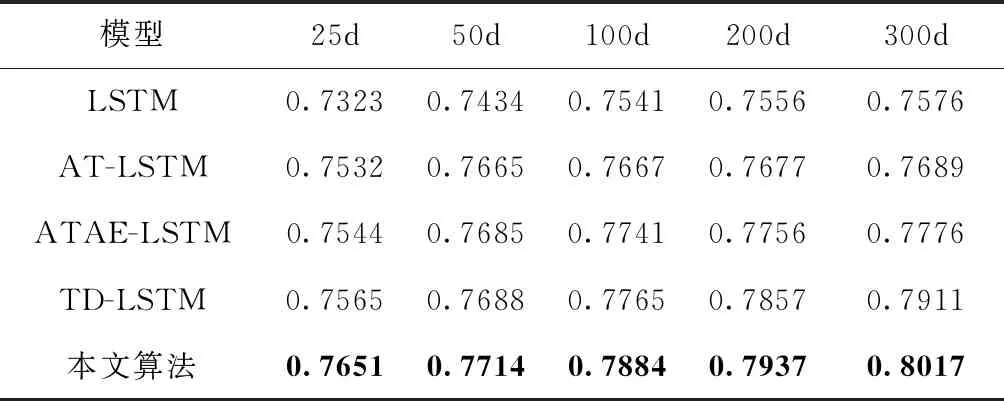
表3 restaurant數(shù)據(jù)集上不同文本維度的準(zhǔn)確率
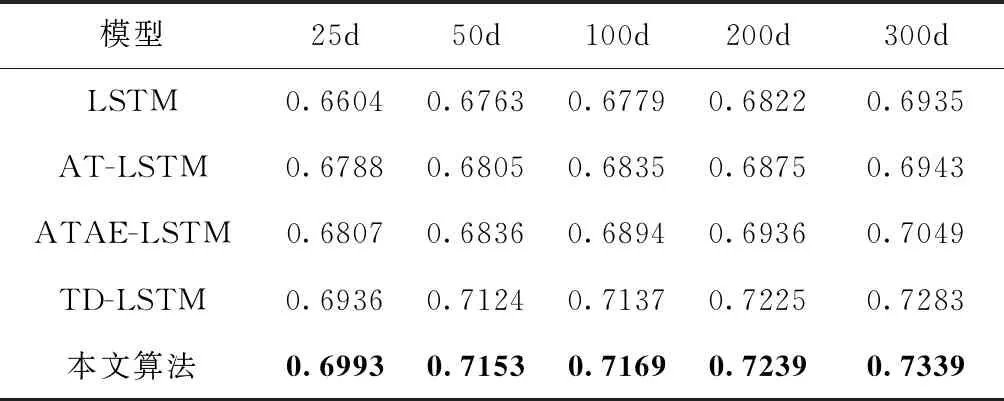
表4 twitter數(shù)據(jù)集上不同文本維度的準(zhǔn)確率
由圖2~圖4可知,本文提出的模型在SemEval 2014和twitter數(shù)據(jù)集上都取得了較好的效果。通過(guò)增加文本維度可以看出不同的算法呈線(xiàn)性增長(zhǎng),標(biāo)準(zhǔn)的LSTM算法在情感分類(lèi)中只是對(duì)一個(gè)句子進(jìn)行分類(lèi),隨著文本維度的增加LSTM的分類(lèi)準(zhǔn)確率沒(méi)有明顯的提升。相比LSTM算法,AT-LSTM和ATAE-LSTM算法都加入注意力機(jī)制,得到更好的分類(lèi)精度。對(duì)于TD-LSTM算法提取上下文和目標(biāo)之間的關(guān)聯(lián),可以挖掘出更多目標(biāo)的信息,從而得到更好的分類(lèi)精度。
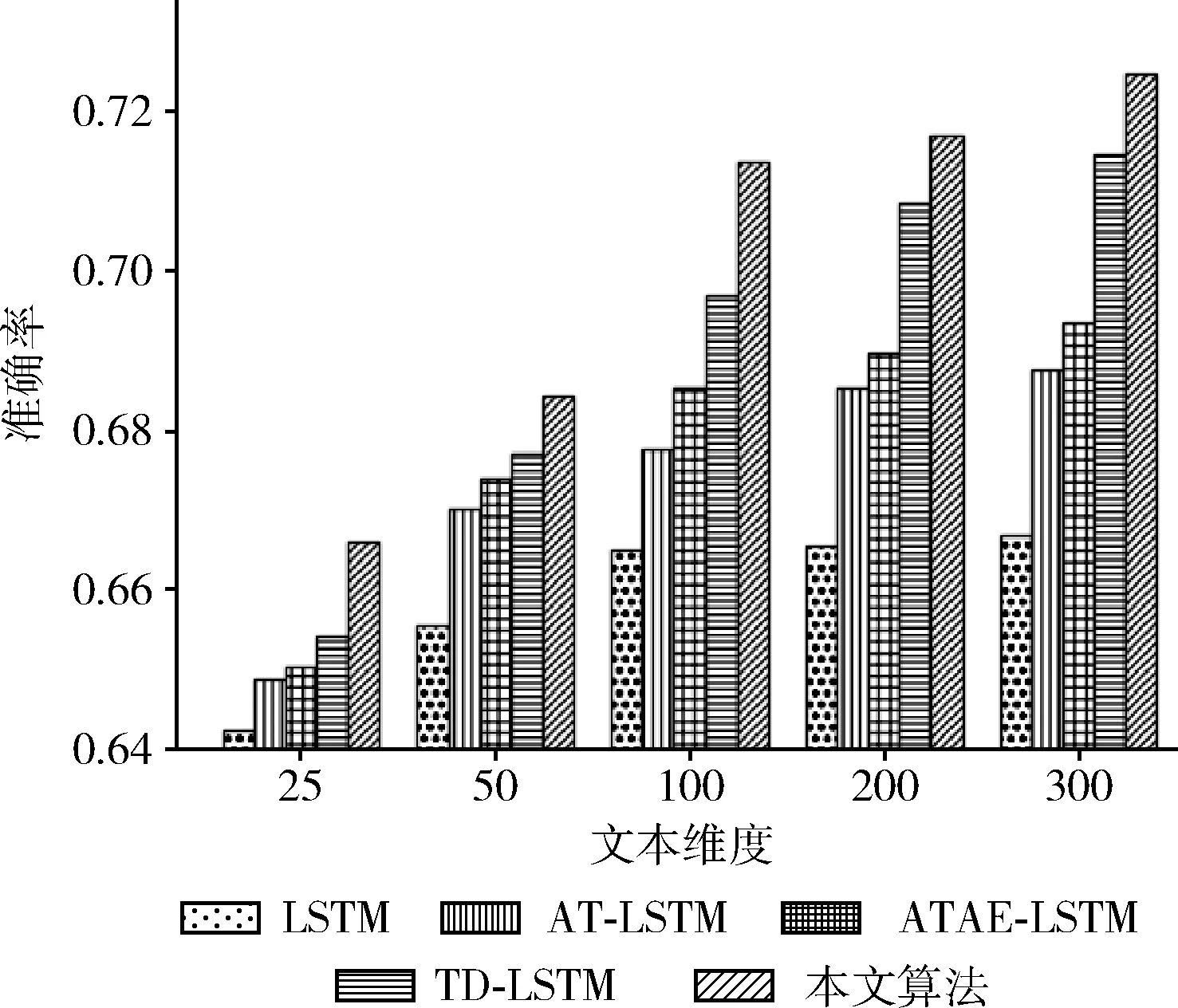
圖2 在laptop數(shù)據(jù)集上不同文本維度的準(zhǔn)確率
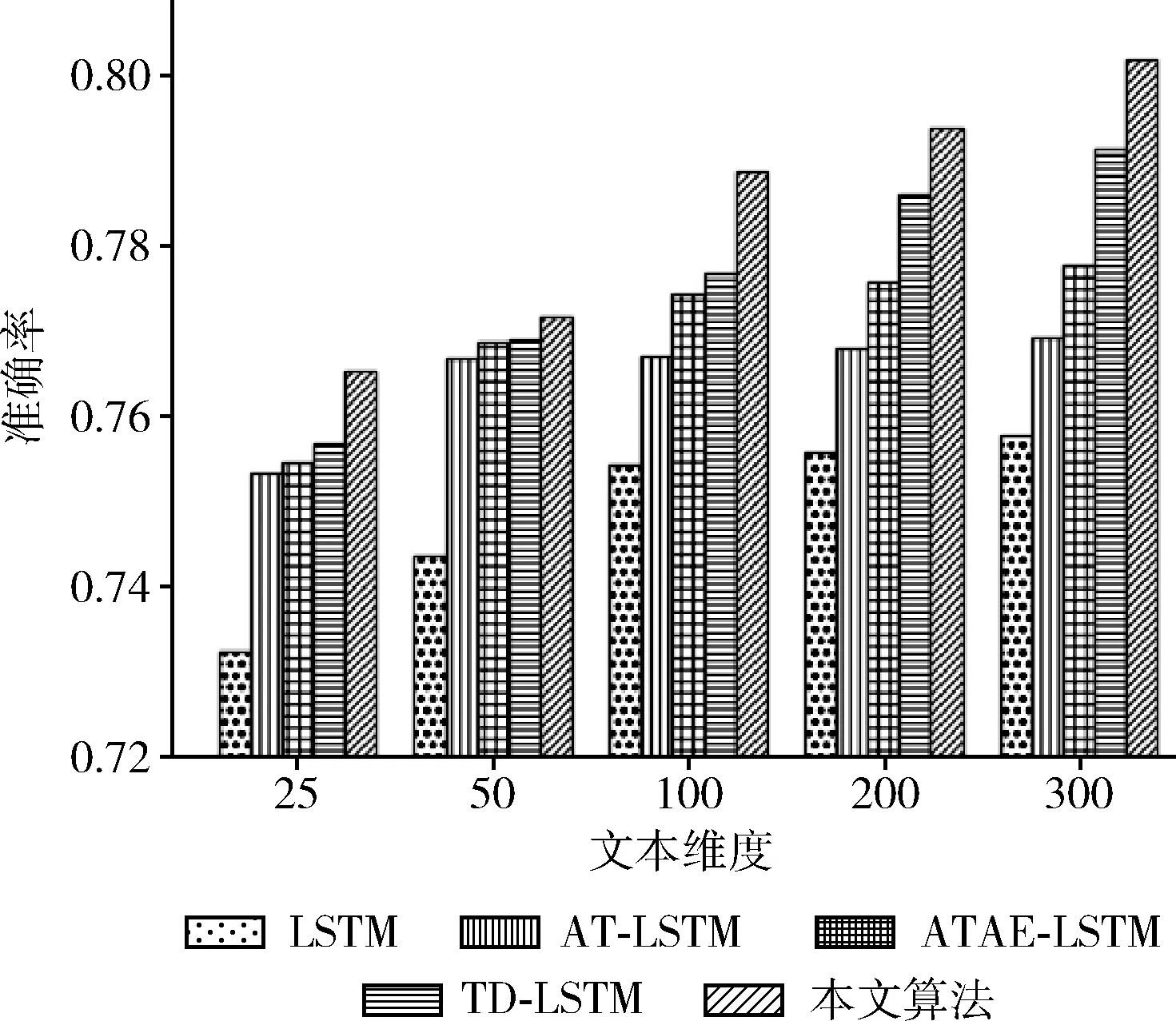
圖3 在restaurant數(shù)據(jù)集上不同文本維度上的準(zhǔn)確率
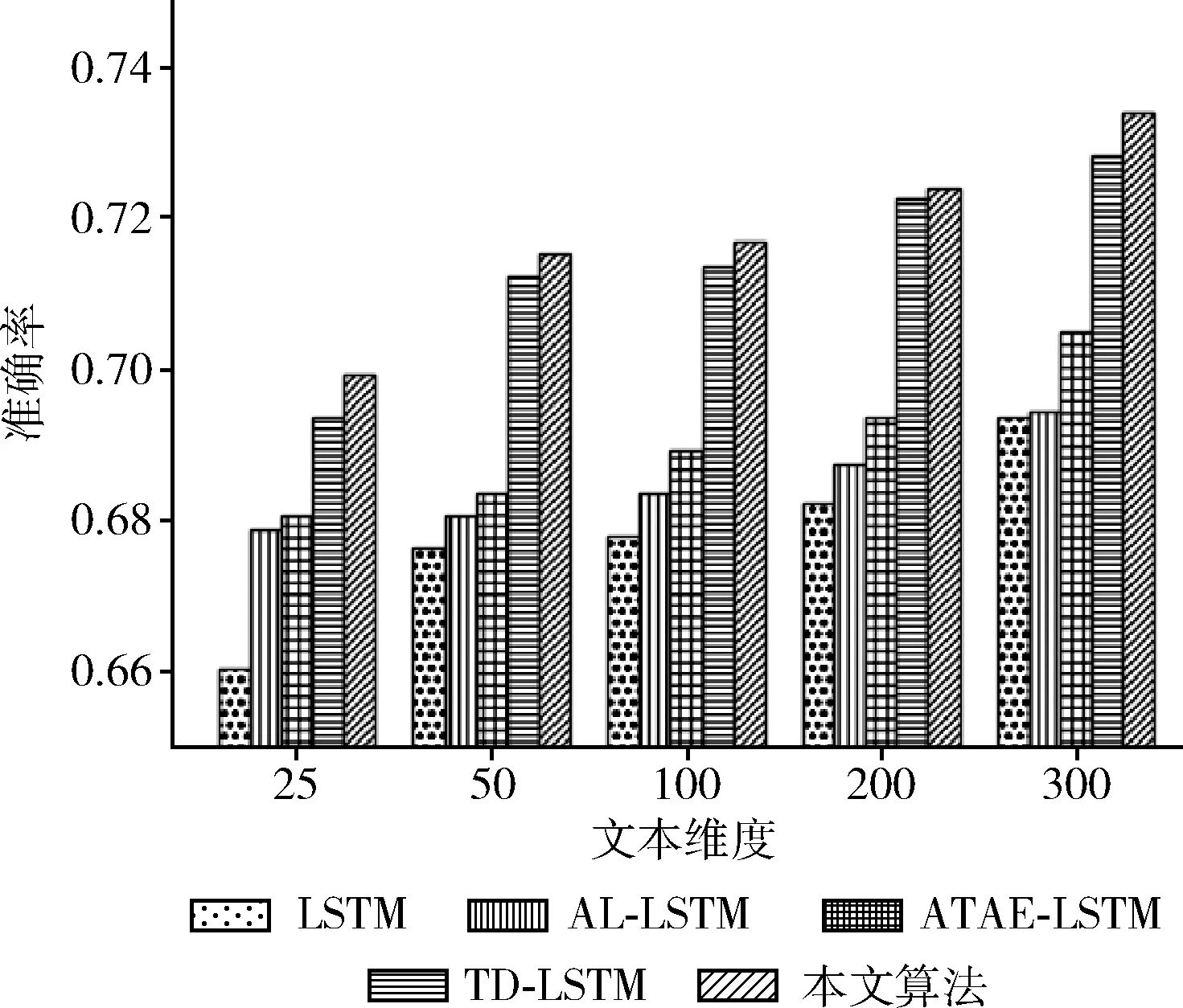
圖4 在twitter數(shù)據(jù)集上不同文本維度上的準(zhǔn)確率
本文的模型通過(guò)加入位置編碼機(jī)制和強(qiáng)注意力機(jī)制,使模型能夠更好捕捉上下文和目標(biāo)屬性方面的關(guān)聯(lián),并且還可以突出不同位置的單詞對(duì)屬性的影響程度。相對(duì)采用單向LSTM模型的ATAE-LSTM,本文采用的是雙向長(zhǎng)短時(shí)記憶模型,這樣可以更好提取上下文特征。在SemEval 2014數(shù)據(jù)集(laptop和restaurant)和twitter數(shù)據(jù)集不同領(lǐng)域的數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),分類(lèi)準(zhǔn)確率分別到達(dá)72.45%、80.17%和73.39%。
如圖5所示模型在25維度~300維度上,隨著維度的增加基本呈線(xiàn)性增長(zhǎng)。加入了注意力機(jī)制的AT-LSTM,ATAE-LSTM算法比LSTM算法在不同維度上分類(lèi)的準(zhǔn)確率都要高,加入注意力機(jī)制提高了對(duì)目標(biāo)信息的挖掘。相比AT-LSTM,ATAE-LSTM算法,ATAE-LSTM算法加入特定目標(biāo)的信息,得到更多的上下文和目標(biāo)的關(guān)聯(lián),增加了分類(lèi)的準(zhǔn)確率,但是對(duì)于多目標(biāo)分類(lèi)時(shí)準(zhǔn)確率較差。LSTM、AT-LSTM和ATAE-LSTM算法都使用單向LSTM,TD-LSTM使用雙向LSTM能夠更好提取上下文和目標(biāo)之間的關(guān)聯(lián),使情感分類(lèi)的準(zhǔn)確率更高。本文的算法使用雙向LSTM,添加注意力機(jī)制來(lái)挖掘上下文和目標(biāo)之間的關(guān)聯(lián),添加位置編碼機(jī)制,挖掘出相鄰詞匯的重要性。將注意力機(jī)制和位置編碼機(jī)制結(jié)合進(jìn)行建模,解決了對(duì)句子中多個(gè)目標(biāo)屬性作出比較好的情感分類(lèi)。
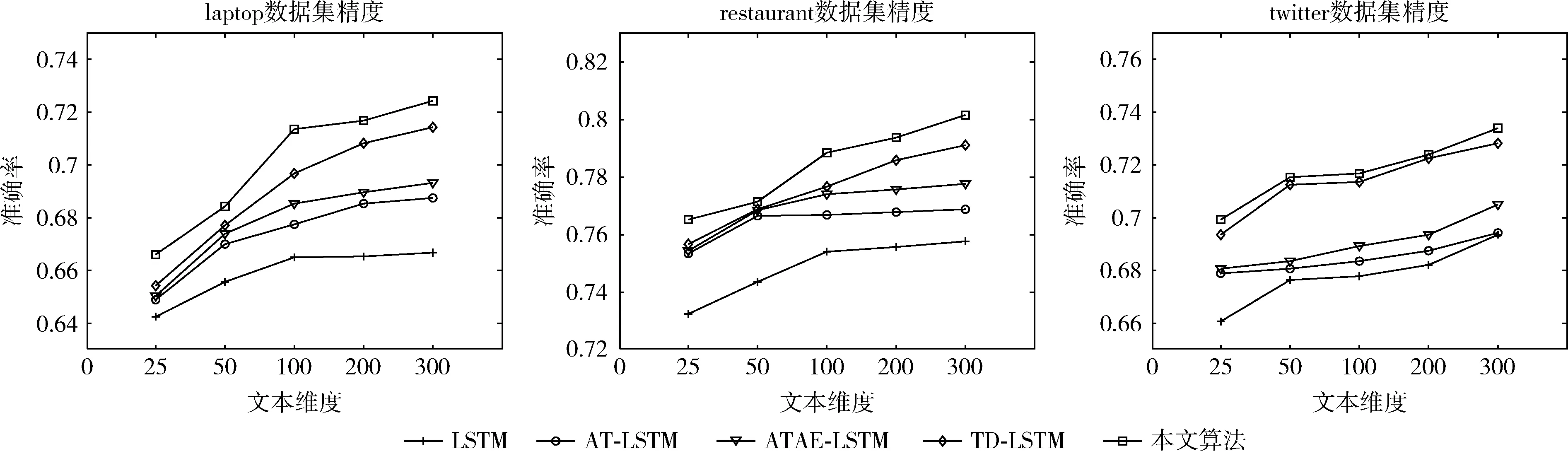
圖5 在laptop、restaurant和twitter數(shù)據(jù)集上準(zhǔn)確率對(duì)比
如圖6展示了本文算法在數(shù)據(jù)集laptop、restaurant和twitter上訓(xùn)練過(guò)程中損失函數(shù)的變化情況,從圖中可以看出模型迭代20 000次以后基本收斂,說(shuō)明算法的可行性。
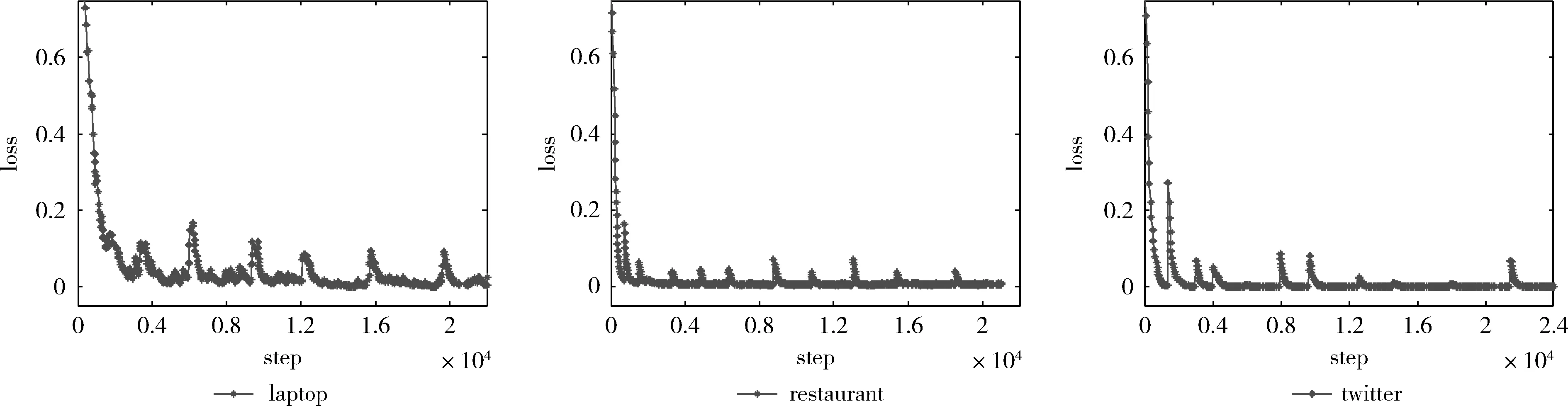
圖6 本文算法在laptop、restaurant和twitter數(shù)據(jù)集上訓(xùn)練的損失函數(shù)
3.4 可視化注意力機(jī)制
為了更好理解本文提出多屬性情感分類(lèi)的模型。通過(guò)對(duì)一句話(huà)進(jìn)行權(quán)重可視化,其中顏色越深代表權(quán)重越大,如圖7所示為測(cè)試集中的一條句子,其中有兩個(gè)方面“reso-lution”和“fonts”,每一個(gè)方面整個(gè)句子中其它詞的權(quán)重都是不一樣的。

圖7 可視化注意力權(quán)重
4 結(jié)束語(yǔ)
在處理序列的問(wèn)題上,循環(huán)神經(jīng)網(wǎng)絡(luò)有更好的效果,本文提出的模型加入了雙向長(zhǎng)短時(shí)記憶來(lái)挖掘上下文和目標(biāo)之間的關(guān)聯(lián),比單向的長(zhǎng)短時(shí)記憶有更好的效果,通過(guò)將強(qiáng)注意力機(jī)制和位置編碼機(jī)制相結(jié)合進(jìn)行建模,可以更好挖掘上下文、目標(biāo)屬性和目標(biāo)相鄰詞間的聯(lián)系,相比一般的模型有更好的分類(lèi)準(zhǔn)確率。
本文在注意力模型中加入了位置信息、上下文和文本內(nèi)容的關(guān)聯(lián)。使用深度模型(如BiLSTM)隱式地捕捉上下文和內(nèi)容之間的關(guān)聯(lián),再結(jié)合位置信息捕捉相鄰詞間的依賴(lài)關(guān)系,構(gòu)建出能夠?qū)Χ鄠€(gè)目標(biāo)對(duì)象進(jìn)行情感分析的模型。實(shí)驗(yàn)結(jié)果表明本文提出的模型在SemEval 2014數(shù)據(jù)集和twitter數(shù)據(jù)集效果較好。
本文的貢獻(xiàn):
(1)在模型中加入了位置編碼機(jī)制,挖掘出與目標(biāo)詞相鄰詞匯的重要信息。
(2)聯(lián)合強(qiáng)注意力機(jī)制和位置編碼機(jī)制進(jìn)行建模,提出一種基于神經(jīng)網(wǎng)絡(luò)的多注意屬性情感分析模型對(duì)多個(gè)目標(biāo)屬性進(jìn)行情感分析。
(3)在SemEval 2014(laptop和restaurant)和Twitter數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)得到了較好的分類(lèi)效果。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中國(guó)生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽(yáng)畫(huà)報(bào)(2019年10期)2019-11-04 02:57:59
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
文苑(2018年21期)2018-11-09 01:23:06
中國(guó)生殖健康(2018年5期)2018-11-06 07:15:40
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
中國(guó)衛(wèi)生(2015年9期)2015-11-10 03:11:12
