Insightface 結合Faiss 的高并發人臉識別技術研究
2020-10-28 06:19:20戴琳琳閻志遠
鐵路計算機應用 2020年10期
戴琳琳,閻志遠,景 輝
(中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081)
人臉識別是基于圖像處理、模式識別等技術,利用人的臉部信息特征,來進行身份驗證與鑒別的生物識別技術。人臉識別技術已在交通出行、手機解鎖、資質認證等領域得到廣泛應用。人臉識別過程一般分為人臉檢測與對齊、特征提取、特征匹配檢索3個階段,具體流程如圖1 所示。

圖1 人臉識別流程
人臉檢測與對齊方面,MTCNN[1]在人臉檢測的基準數據集FDDB 和WIDERFACE,以及人臉對齊的基準數據集AFLW 上都取得了較好的測試結果。特征提取方面,2015年,ResNet[2]殘差學習被提出后,網絡深度不再限制網絡性能,大部分特征提取網絡都以ResNet 為基礎做更新優化;DeepID[3]采用LeNet 結構對人臉多個關鍵區域分別做特征提取,將隱藏層特征拼接起來,降維得到最終特征,用于人臉描述和分類;Facenet[4]基于ResNet 網絡,結合Tripletloss 函數,利用歐式嵌入,解決人臉比對驗證的問題;SphereFace[5]首次關注特征的角度可分性,使得訓練出的卷積神經網絡(CNN,Convolutional Neural Networks)能學習具有角度判別力的特征;Insightface 算法[6]提出了附加角邊距損失函數,直接在角度空間中最大化分類界限。特征匹配檢索方面,kd-tree[7]是常用做特征點匹配的Sift[8]算法,Surf[9]算法和ORB[10]算法與SIFT 算法相比,特征點檢測匹配速度有較大提升,但這些算法的效率均不及GPU 環境下為稠密向量提供高效相似度搜索和聚類的Faiss算法。
目前,實名制進站核驗系統[11]的人臉識別率已達97%,旅客可以在5 s 內完成進站核驗,但這只針對票、證、人一致性核驗的1v1 場景。
綜上,本文沿用MTCNN,基于Insightface 對原有的ResNet 殘差單元進行優化,將Faiss 框架引入人臉的高維特征匹配過程,從算法的角度,對1vN 場景下的搜索匹配過程進行優化,提高模型的效率與適用性。
1 鐵路車站人臉識別算法
鐵路車站人流密度較大,環境場景復雜,有時需對場景下出現的所有人員進行識別監控。本文采用MTCNN 進行人臉檢測與對齊,定位出人臉區域,找到臉部基準點之后,用改進的特征提取網絡Insightface 結合損失函數優化進行人臉特征提取,并將Faiss 索引檢索引入特征匹配過程,完成人臉識別。
1.1 人臉檢測與對齊
1.1.1 MTCNN 流程
MTCNN 是一個深度級聯的多任務CNN 框架,具有3 階段深度卷積網絡。以從粗略到精細的方式來預測人臉以及人臉關鍵點位置,可以同時完成人臉分類、邊框回歸和面部關鍵點的定位任務。在訓練過程中采用困難樣本挖掘策略,可以在無需手動選擇樣本的情況下提高性能。該框架流程如圖2所示。
給定一張輸入圖片,將其縮放至不同比例,構建一個圖像金字塔,作為以下3個階段的網絡輸入:
(1)通過全卷積網絡P-Net(Proposal Network)來獲得候選邊框和邊框回歸參數,用回歸參數調整邊框位置,再用非極大值抑制(NMS,Non-Maximum Suppression)合并重疊率較高的候選框;
(2)將P-Net 輸出的候選框從輸入圖片對應位置剪裁出來,輸入到R-Net(Refine Network)。該網絡進一步過濾掉非人臉的候選框,同樣,采用回歸參數調整邊框位置,再用NMS 合并重疊率較高的候選框;

圖2 MTCNN 流程
(3)將R-Net 輸出的候選框從輸入圖片對應位置剪裁出來,輸入到O-Net(Output Network),找出面部的5個關鍵點,并輸出檢測到的人臉以及面部關鍵點的位置。
1.1.2 MTCNN 損失函數
訓練時,框架的每個階段都有3個輸出:人臉分類,邊框回歸,面部關鍵點定位。
(1)人臉分類:是一個二分類問題,損失函數采用交叉熵來表示。
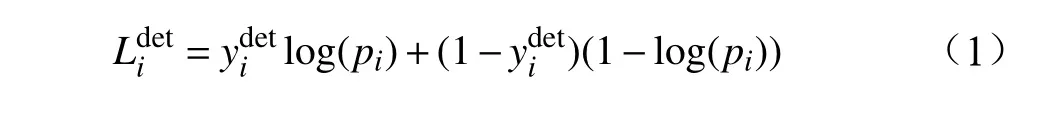
其中,pi表示第i個樣本預測為人臉的概率;表示第i個樣本的真實值。
(2)邊框回歸:對于每個候選框,預測其與最近標注框的偏移量,損失函數采用歐式距離損失進行計算。

(3)面部關鍵點定位:損失函數同樣采用歐式距離損失進行計算。

(4)總體損失函數如下:

其中,N表示樣本的數量, αj表示各層網絡的權重,某個網絡越重要則所對應的值越大,表示樣本的類型。
(5)困難樣本挖掘:本文在人臉分類的訓練過程中,采用在線困難樣本挖掘策略。將訓練集中一部分數據集的所有樣本,按前向傳播中產生的損失大小進行降序排列,取前70%作為困難樣本,在反向傳播中僅用這些樣本來更新參數。
1.2 人臉特征提取
1.2.1 特征值提取網絡
將人臉對齊關鍵點坐標結合改進后的ResNet 網絡進行深度特征提取。本文對網絡原有的殘差單元結構做了修改,將原ResNet 殘差單元(圖3a)中的第2個卷積層步長調整為2,并在每次卷積前后都增加批歸一化處理(BatchNorm),激活函數在ReLu的基礎上增加部分參數,修改小于0 的飽和區為非飽和區,稱之為PReLu(圖3b)。批歸一化利于網絡收斂,能更好地學習特征表達,非線性激活函數PReLu 相比ReLu,有更大范圍的非飽和區,有效避免了隨著網絡深度增加、梯度衰減,引起參數不更新的問題。

圖3 殘差單元修改前后
1.2.2 特征值提取損失函數
利用Insightface 算法根據全連接層的情況確定不同類別的分類邊界。在二分類場景下, θi(i=1,2)表示學習的特征向量和類Ci的權重向量之間的角度,假設有類別C1、C2,特征向量屬于C1分類的需要滿足余弦決策裕度cosθ1>cosθ2的要求,從而區分來自不同類的特性。同時,可通過在余弦空間中增加額外的邊緣來加強對習得特征的識別,進一步要求cosθ1>cosθ2+m,m表示決策邊界的邊距,來控制余弦決策裕度的大小,這個約束對于分類來說更加嚴格,具有更好的幾何解釋性,適用于類別較多的人臉分類場景。同時,分類的條件對于角度來說也變得更為苛刻,拉大了類間距離,能夠帶來更好的區分效果。設b為批尺寸;n為類別區分的具體數量;s表示比例縮放的超參數,改進后的損失函數為:

其中,對特征向量與權重都做了歸一化處理,在原本的余弦邊距中,cosθ1>cosθ2+m代表分類正確,現在要求當θ2∈[0,π?m]時,cosθ1>cos(θ2+m) 才是分類正確。相當于決策邊界由余弦空間延伸到了角度空間,增強了模型對人臉的表征能力。
1.3 人臉特征匹配
提取出的人臉圖片高維特征向量無論是分類還是比對驗證,都需要進行向量匹配搜索與相似度判斷。Faiss 是為稠密向量提供高效相似度搜索和聚類的框架,包含對任意大小向量集的搜索算法,可以擴展到單個服務器上主存儲器中的數十億個向量。Faiss 是圍繞索引展開的,不管運行搜索還是聚類,都要建立一個索引,其特點為:
(1)速度快,可存在內存和磁盤中;
(2)提供多種檢索方法;
(3)由 C++實現,提供了Python 封裝接口;(4)支持GPU。
2 實驗驗證
2.1 實驗環境
本地服務器測試工具為Jmeters,遠程服務器測試工具為wrk,兩者均為開源性能測試工具
特征提取對比實驗并發用戶數量為1 ~ 10,實例數量為1 ~ 40,以Face++提供的API 測試效果為參照,測試Insightface 在并發條件下的效率與精度;特征匹配對比實驗特征底庫大小為1萬,隨機搜索數量為1000,比較傳統的kd-tree 搜索和本文使用的Faiss 向量搜索的性能。
2.2 Insightface 特征提取實驗
2.2.1 Insightface 特征提取效率
遠程服務器區分為需要部署Nginx 的跳板機以及部署工程和多實例的主機。為消除網絡的影響,需要在跳板機上安裝wrk,進行性能測試。使用Gunicorn 單用戶不并發時,每秒事務處理量(TPS,Transaction Per Second)約為7.84個,如表1 所示。平均響應時間約為128 ms,比Face++的extract_with_detect 接口效率提高1 倍以上,如表2 所示。在多用戶并發情況下,受限于機器配置,同時啟用的實例數不宜過多,每個用戶的請求次數對TPS 沒有明顯影響,反而會增加延時。考慮到人臉識別核驗系統應用都是基于遠程重點人員特征庫,遠程特征提取的效率尤為重要。試驗證明以Gunicorn 調用flask 的方式構建Insightface 特征提取服務器,與單用戶請求相比性能沒有明顯損失。

表1 Insightface 性能測試情況

表2 Insightface 與Face++的特征提取效率對比
2.2.2 Insightface 特征提取精度
精度測試基于LFW(Labled Faces in the Wild)數據集,使用曠視Face++的API 接口做精度參照。1v1 測試按人物名取每相鄰2 張圖片特征組成一對,每張圖只組對一次,共6000 對。1vN 測試選取數據集中圖片數量在2 張以上的1680 人,共9064 張圖片,每人隨機抽取1 張作為后續對比圖,其余作為底庫特征集。測試結果如表3、表4 所示。
(1)1v1 比對測試
1v1 是指同一個特征底庫圖數量為1 的情況。Insightface 采取10 折交叉驗證得到1個比對精度,Face++根據提供的4個置信度參考閾值[55.013874,62.088215,67.57555,71.71891]得到1 組比對精度,如表3 所示。由測試結果可知,Insightface 1v1 算法精度優于Face++。

表3 1v1 情況下Insightface 與Face++測試結果對比
(2)1vN 比對測試
1vN 是指同一個人特征底庫圖數量為N 的情況。Insightface 提供了1 組10個特征的距離閾值,1vN 的比對精度最佳可達95.23%,與Face++檢索算法精度基本相同,如表4 所示。

表4 1vN 情況下Insightface 與Face++測試結果對比
2.2.3 Faiss 特征匹配
kd-ree 搜索將底庫圖片特征劃分為多個特征空間,構成二叉樹,然后將待對比圖片的特征向量傳入二叉樹進行搜索,返回距離小、相似度高的底庫標簽。Faiss 搜索以向量或矩陣的形式準備好底庫特征數據,然后構建底庫索引并將特征數據映射至索引中,再通過索引搜索得到標簽,兩者的搜索性能測試結果對比如表5 所示。
kd-tree 在底庫大小為1萬張圖片,隨機搜索1000張圖片的情況下,總耗時為8.35 s。Faiss 在相同情況下,總耗時為0.05 s。大部分人臉核驗系統都是基于公安機關的遠程重點人員特征庫,遠程特征匹配的效率尤為重要,本文以Gunicorn 調用flask 的方式構建Faiss 特征搜索服務,不僅在效率上提速了100 倍以上,且需要的CPU 資源更少。

表5 Faiss 與kd-tree 搜索性能對比測試
2.3 實驗結論
實驗結果表明:(1)以Gunicorn 調用flask 的方式構建Insightface 特征提取服務器,雖然在高并發、多實例的場景下,有較高的硬件資源要求,但是精度和效率都有所提高;(2)以Gunicorn 調用flask的方式構建Faiss 特征搜索服務器,相比傳統的kdtree 搜索,效率上提高了100 倍以上,而且需要占用的CPU 資源更少。
3 結束語
Insightface 結合Faiss 的高并發人臉識別,通過對實際應用場景的模擬,結合具體的軟硬件資源限制,優化了人臉識別特征提取和特征匹配流程的算法設計方案,為鐵路客運高并發情況下的人臉識別、核驗、搜索比對等安全保障業務提供了技術支撐。該方法在細粒度人臉檢測、更高效率的人臉特征提取、比對、搜索以及多種站場復雜條件下的適用性等方面,有進一步優化空間。未來可通過復雜場景下人臉圖片數據的積累,算法框架調優等方式,進一步提高適用性。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年15期)2019-08-27 01:12:00
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
計算機工程(2015年8期)2015-07-03 12:19:07
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
