基于EPOLL 編程模型的全路車流徑路服務的開發與應用
2020-10-28 06:19:20鄧桂星李世春劉耀宗
鐵路計算機應用 2020年10期
鄧桂星,張 銳,李世春,劉耀宗,王 瑜
(中國鐵路蘭州局集團有限公司 信息技術所,蘭州 730000)
車流徑路是當前我國鐵路優化運輸組織、合理分配運力資源、提升路網整體通過能力的重要技術手段,為鐵路貨運編組計劃制定、運到時限考核、車流推算、違規車流判定、計費徑路調整等業務提供必要的數據支持。先前開發的“可視化鐵路網貨流、車流公共信息平臺”[1]解決了全路車流徑路判定的問題,廣泛應用于貨運、運輸[2]、調度和統計等業務信息系統[3]。但這些應用采用本地計算模式,依賴于最新下載的車流徑路數據,若未及時更新徑路數據,會造成計算結果與運輸實際情況的差異,不利于運輸組織和經營考核。
為解決上述問題,在64 bit Linux 操作系統上,利用 Eclipse 開發工具和I/O 編程模型EPOLL,開發全路車流徑路服務,實現全路車流徑路數據的集中計算與分布應用。
WebLogic 與Tomcat 服務均基于Java 語言,而先前開發的車流徑路算法程序基于C++語言,跨語言代碼調用需借助JNA,會顯著降低系統運行效率。且傳統網絡通訊SELECT 編程模型已不能滿足目前訪問車流徑路數據的大量客戶端連接和高速數據傳輸需求。EPOLL 編程模型是Linux 內核為處理大批量文件描述符而改進的POLL,是Linux 操作系統上多路復用I/O 接口-SELECT/POLL 的增強版本,在大量并發連接中只有部分連接活躍的情況下,可顯著提高系統CPU 利用率[4]。經過與Windows 操作系統上的SELECT 編程模型和IOCP 編程模型的實驗對比,發現在Linux 操作系統上采用EPOLL 編程模型開發應用服務,代碼維護簡潔、并發處理能力強、讀寫效率高,能夠滿足訪問車流徑路數據的大量客戶端連接及高速數據傳輸的需求。
1 EPOLL 編程模型
EPOLL 編程模型與SELECT/POLL 類似,均是基于TCP/IP 網絡傳輸協議的套接字編程模型,但EPOLL 模型可承載更多并發客戶端連接,采用內存映射等技術,且系統調用時只處理活躍連接,執行效率更高[4],其工作流程如圖1 所示。

圖1 EPOLL 編程模型的工作流程
1.1 3個核心函數
(1)INT EPOLL_CREATE(INT SIZE),用于生成一個EPOLL 專用的文件描述符,即申請一段內存空間來存放被關注的套接字上發生的事件;參數SIZE 是系統連接的最大客戶端數量,可被省略(此時取系統最大值)[5]。
(2)INT EPOLL_CTL(···,STRUCT EPOLL_EVENT *EV),用于控制被關注的文件描述符上發生的事件:注冊、修改、刪除;參數EV 用于通知操作系統需要監聽何種事件。
(3)INT EPOLL_WAIT(···, STRUCT EPOLL_EVENT *EVENTS,···),用于獲取有觸發事件的文件描述符;函數調用過程中使用內存映射(MMAP)技術,免去復制文件描述符的開銷[4]。
1.2 工作方式的選擇
水平觸發方式(LT,Level Triggered):操作系統會通知文件描述符是否就緒;若已就緒,程序可讀寫就緒的套接字;若程序未做任何操作,操作系統會繼續發出通知;水平觸發方式編程出錯的可能性小,但處理速度慢[5]。
邊沿觸發方式(ET,Edge Triggered):是一種高速工作方式,只支持非阻塞,比水平觸發效率高;當一個事件發生時,可調用EPOLL_WAIT 獲取該事件,若系統尚未處理完該事件對應的套接字緩沖區,而這個套接字中沒有新的事件發生時,不能再通過EPOLL_WAIT 調用獲得該事件[5]。
水平觸發方式下,開發EPOLL 服務簡單且不易出錯;邊沿觸發方式下,程序運算速度快,但代碼略微復雜。
車流徑路服務的開發采用邊沿觸發方式。
2 基于EPOLL 編程模型的車流徑路服務的開發
基于EPOLL 編程模型的車流徑路服務的開發包括車流徑路系統[6]的移植與EPOLL 服務的設計與實現。
2.1 車流徑路系統的移植
先前開發的車流徑路系統是在Win32 操作系統上采用標準C++語言開發的。而車流徑路系統的移植利用Linux 版Eclipse 作為開發工具[7],需解決從32 bit 操作系統移植到64 bit 操作系統的相關問題。在32 bit 操作系統上,long 和pointer 變量的長度為4 byte[8],在64 bit 操作系統上則為8 byte,移植后會造成內存空間大小的變化以及讀取二進制文件錯位等問題。為此,采用宏定義統一變量長度,編譯生成.SO 文件(動態鏈接庫),供EPOLL 模型調用。
64 bit 操作系統的尋址能力更強,可顯著提高運行效率。經實驗對比發現,在Win32 操作系統的單進程模式下,每秒鐘能計算7萬條車流徑路數據,Linux64 操作系統下則可達10萬條左右。
2.2 車流徑路服務的設計與實現
基于EPOLL 模型的服務采用多線程技術來提高訪問效率;主線程負責收集已經發生的客戶端事件、徑路計算和數據傳輸,監聽線程負責處理新的客戶端連接。
如圖2 所示,車流徑路服務的建立過程如下:
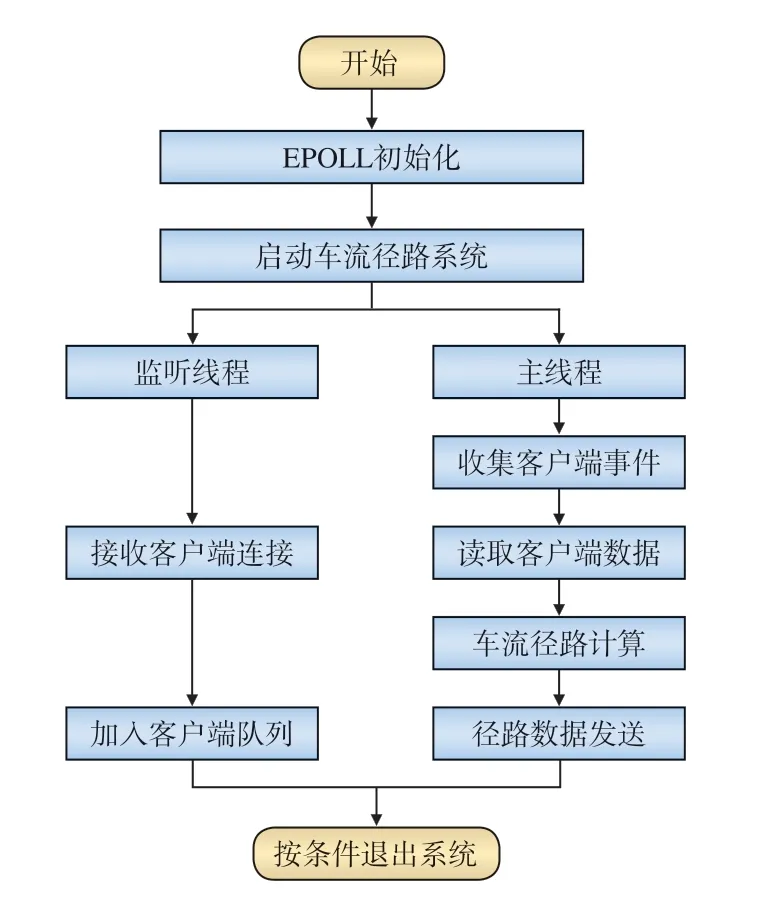
圖2 車流徑路服務的建立過程
(1)調用EPOLL_CREATE()生成一個EPOLL 專用的文件描述符,并啟動車流徑路系統;
(2)在主線程中調用EPOLL_WAIT()收集已經發生的客戶端事件,并進行車流徑路計算和數據傳輸;
(3)啟動監聽線程,專門處理新的客戶端連接,管理客戶端隊列;
(4)卸載車流徑路數據,清空客戶端隊列,關閉EPOLL 專用文件描述符,退出服務。
3 測試及應用效果
在實驗環境下,采取多線程技術[9]模擬客戶端的并發訪問,進行壓力測試。在創建10000個并發線程時,基于EPOLL 編程模型的車流徑路服務的連接、運算和傳輸都較為穩定,CPU 利用率和內存占用率均在正常范圍內。與Tomcat 服務、SELECT 和IOCP 編程模型相比,基于EPOLL 編程模型的車流徑路服務在編程復雜度、傳輸效率和穩定性方面均有明顯優勢。目前,該服務已為全路車流徑路的實時查詢、貨物運到時限預警、承運清算以及鐵路局的其它特色應用提供支持,每日計算量在10萬次以上,高峰訪問并發量約1000個用戶。經過一年的運行監測,該服務運行穩定,未發現異常狀況。
4 結束語
Linux 操作系統及EPOLL 編程模型具有高并發、高效率和高穩定性,滿足國產化應用的開發需求,使應用系統開發擺脫了對商業中間件的依賴。利用Linux 操作系統內核的高并發處理機制,較好地解決了車流徑路共享難題,實現全路車流徑路數據的集中運算和分布應用。
今后,還將采用二進制流方式進行數據傳輸,以提高數據的安全性和傳輸效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
光學精密工程(2016年6期)2016-11-07 09:07:19
