基于知識圖譜構建5G協議知識庫
2020-10-27 09:46:56徐健
移動通信 2020年8期
徐健


【摘 ?要】
隨著5G技術的日趨成熟,運營商相關研究人員面臨著快速掌握5G相關知識的壓力,然而5G知識內容種類繁多,知識面廣,如何高效地從5G協議中查詢到亟需學習的知識點是當前亟待解決的問題,為了解決這一問題,本文基于知識圖譜及信息搜索方法構建5G協議知識庫。由于網優人員搜索相關知識一般只需得到與關鍵字相關的知識信息,而不必通曉全文,本文采用專業領域知識庫結合多種方法對信息進行抽取,建立術語的屬性、基本關系以及文本結構的關系,同時采用Neo4j圖數據庫對構建成的三元組進行存儲,極大地提高了搜索性能,本文將該知識圖譜運用到5G協議知識智能檢索中,并取得了很好的效果。
【關鍵詞】知識圖譜;Neo4j;搜索引擎;深度學習;知識抽取
[Abstract]
With the maturity of 5G technology, operator-related researchers face the pressure to quickly acquire 5G knowledge. However, there are various types of 5G knowledge content with a wide range, and how to efficiently extract the knowledge points from 5G protocol is an urgent issue to be solved. In order to solve it, this paper constructs a 5G protocol knowledge base using the methods of knowledge graph and information search. Since network optimization engineers usually need to get knowledge related to key words rather than being familiar with the full text when searching relevant knowledge, this paper adopts professional domain knowledge bases and combines multiple methods to extract information to establish term attributes, basic relationships and text structures. At the same time, the paper also uses the Neo4j graph database to store the construed triples, which greatly improves the search performance. This paper applies the knowledge graph to intelligent retrieval in 5G protocol knowledge and obtains a successful achievement.
[Key words]knowledge graph; Neo4j; search engine; deep learning; knowledge extraction
0 ? 引言
隨著網絡領域人工智能技術的發展,自然語言處理技術得到了進一步的發展,由于網優領域知識的大規模、非結構化等特點,這使網優人員獲取信息的難度加大,同時,知識圖譜的快速發展,又給網優知識整理提供了可能性,知識圖譜以其強大的語義處理能力和開放性組織能力,為網絡領域的知識整理和自動化應用打下了根基,許多領域面臨數據的不斷增長所帶來的許多挑戰,因此可以利用知識圖譜技術,針對不同的業務需求,實現通用領域和專用領域應用“遍地開花”的景象。
DBpedia是知識圖譜中很典型的例子,是從維基百科的結構化數據中提取出來的知識圖,這種提取的數據主要來源是維基百科信息框中的鍵值對,在一個眾包過程中,提取信息框中的內容作為實體,而相應的鍵值作為屬性,基于這些映射,可以提取知識圖[1]。和DBpedia一樣,YAGO也是從DBpedia中提取的,YAGO從維基百科的范疇系統和詞匯資源WordNet[2]中隱式構建分類,將信息框屬性手動映射到固定的屬性集,DBpedia為每個語言版本的Wikipedia創建不同的相互關聯的知識圖[3],YAGO的目標是利用不同的啟發式方法,將從不同語言版本中提取的知識自動融合起來[4]。無論用何種方法來構造知識圖譜,其結果都不會是完美的[5],作為現實世界的一個模型或它的一部分,形式化的知識不能合理地達到完全覆蓋,即不可能包含關于宇宙中每一個實體的信息,此外,特別是在應用啟發式方法時,知識圖不太可能是完全正確的,通常在覆蓋率和正確性之間存在權衡,這在每個知識圖中都有不同的解決方案。已有很多學者對知識圖譜相關技術進行了研究,Dong C, Zhang J等[6]通過使用神經網絡的變種形式雙向的LSTM-CRF進行命名實體識別,利用字符級等方法進行表示,并在沒有精心設計的特性的情況下獲得更好的性能。M Ganzha, L Maciaszek等[7]利用原始的PDF文件提取出句子和單詞,所提取的句子之間的關系以網絡圖的形式構建出來。Rajman等[8]提出了一種采用文本數據挖掘技術進行知識抽取的對策,他們提供了兩個可以從文本集合中提取信息的示例——關鍵字和原型文檔實例的概率關聯,同時,該文章表明了自然語言處理技術在知識抽取應用中至關重要。Alani等[9]按文檔檢索、實體識別和提取過程等步驟,利用預定義的本體從文檔中自動提取知識,在知識抽取過程中,采用了多種自然語言處理技術,句法分析、語義分析和關系抽取,而且已經得到了很好的結果。翟社平、段宏宇等人[10]通過采用一種基于RNN網絡的變種BiLSTM_CRF網絡結構實現了實體提取技術,在使用雙向短時記憶網絡BiLSTM提取文本信息時,又利用CRF技術對序列標注之間的關系進行表示,實驗表明該方法可以獲得很好的結果。Peter Clark和Phil Harrison等[11]通過創建“元組”數據庫來研究知識提取,從而捕獲簡單的單詞知識,然后用它來改進文本潛在的語義規則的語法分析和可信性評估。Parikh[12]提出了一種學習語義解析的方法,用于提取帶或不帶注釋文本的嵌套事件結構,此方法背后的思想是將注釋構建為潛在變量,并合并與事件語義解析匹配的先驗知識。
伴隨著“互聯網+5G”的蓬勃發展,人們的思想和生活理念會發生天翻地覆的變化,5G所影響的將是全產業、全鏈條的技術創新,不僅是日常生活到工業生產的變化,文化娛樂、智能駕駛、教育醫療都會發生深刻的變化,5G的影響將隨處可見。構建網優知識的知識圖譜對5G的發展起到極大的推動作用,對網優專家以及工程人員及時獲取5G相關的知識起到至關重要的作用。根據我們的設想,網優專業以及工程人員無需去閱讀所有的協議,只需要懂得查找并及時獲取相關的知識即可,所以要求知識圖譜抽取的知識是在有限的時間里提供給用戶簡潔且容易獲得的信息。
本文通過自然語言處理技術,對5G協議進行數據處理,通過自然語言處理相關技術構建網優領域的知識圖譜,通過智能搜索技術實現搜索引擎,查找相關的協議內容和知識,并且對比了深度學習實體提取算法的優劣,最后選擇了BiLSTM-CRF進行知識提取。此外,知識圖譜的構建方便了網優人員進行參數查詢和自主學習,并取得了令人滿意的結果。
1 ? 基于知識圖譜的5G協議檢索
目前,知識圖譜的構建形式,一般有兩種形式,其中,自頂向下方式需要通過構建好的知識庫進行提取出實體和關系的基本模式,然后再從新的數據源中抽取出正確的實體和屬性,合并到已定義好的概念體系當中[13-15],但這種構建知識圖譜的方式相對簡單。例如,Google在初期為了保證知識的準確性和高效性,很多數據都是從Freebase數據庫中獲取的;DBpedia則是基于維基百科大規模數據的基礎上構建完成的。然而,隨著深度學習等知識提取技術的快速發展,逐漸形成了以自底向上為主的構建形式,這種構建知識圖譜的方式,實體和關系抽取更高效,其構建的圖譜葉更加完善且豐富,Knowledge Vault[16]就是采用該深度學習的方式進行構建知識圖譜的典型例子,對現存的圖譜進行了填補和完善。
1.1 ?5G協議檢索架構設計
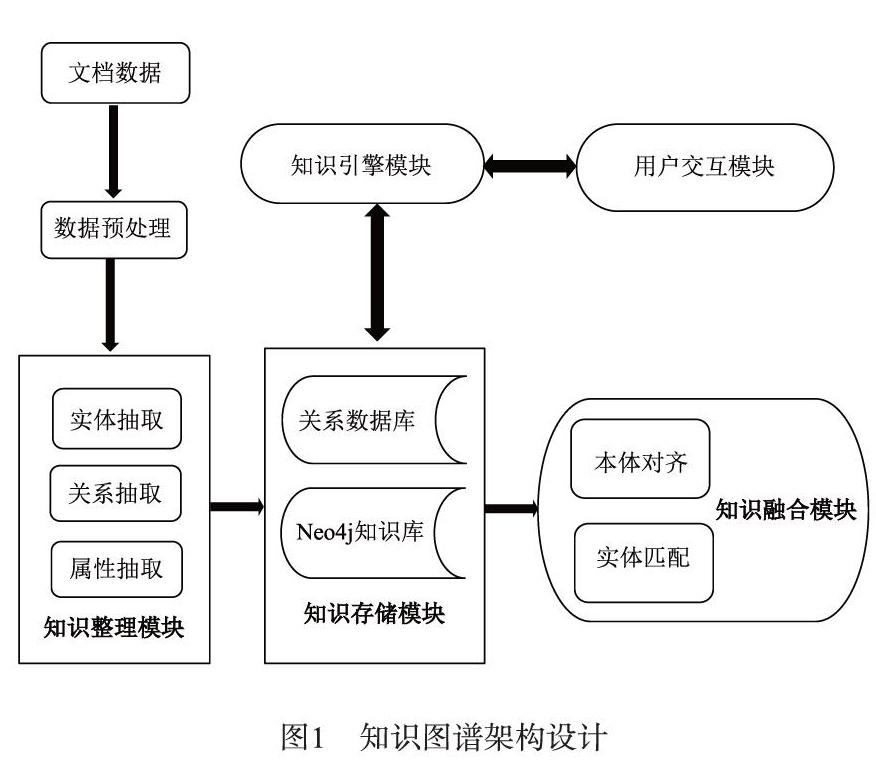
網優領域的知識圖譜是為了讓網優人員都能獲取專業領域的知識,因此,網優知識圖譜應針對網優領域的知識進行構建,而且領域中有組織有結構的數據更容易獲取準確的三元組。在研究分析網優領域的數據時可以發現,網優領域知識難度大,即使是工作多年的工程師也會存在技術短板,因此現有結構化數據十分缺失,收集較為困難,所以,可信度較高的5G協議知識作為基礎數據源,本文將采用多種方式來構建網優知識圖譜,本文的構建流程圖如圖1所示:
本節介紹系統的總體思路及架構,該架構主要由如下幾個部分組成:數據格式轉化、數據處理、知識整理模塊、數據庫存儲的轉化模塊、知識融合模塊、知識庫引擎模塊、前端用戶交互模塊等。
該流程首先通過文檔數據進行預處理,再進行知識圖譜的知識整理,包括實體提取,關系提取和屬性提取,然后再針對定義好的專業領域數據中的相關知識,經過知識融合的本體對齊和實體匹配等操作進行網優知識圖譜的構建,并用圖數據庫進行儲存。由于網優知識圖譜主要為網優工程人員提供服務,對圖譜中的實體和關系的準確性提了很高的要求,因此本文在分析5G協議數據源之后,考慮到網優領域知識的難度大等特點,通過對文本結構以及網優術語及其之間關系進行三元組構建,確定網優核心概念,構建網優領域的知識圖譜。
1.2 ?圖數據庫Neo4j實現知識搜索
表1為幾種不同的數據庫對比,經過對比,Neo4j圖數據庫有如下優點:高可用性,實時數據分析,輕松檢索,Neo4j不僅可以可視化顯示,而且還可以比較容易地實現檢索(遍歷/導航)其他數據庫中的連接數據,具有查詢速度快,代碼量少等優點,因此,該系統采用通用的圖數據庫Neo4j作為存儲數據庫,在數據經過處理后以三元組的形式表達的元素作為基本輸入構建知識圖譜。搜索引擎是知識圖譜最典型的應用之一,其目的是協助工程人員通過所輸入的關鍵字獲取所需要的信息,本文以Neo4j為知識搜索引擎,該系統主要實現以下查詢功能:實體查詢,顯示關系以及對應的實體;查篇名,顯示文檔的內容以及關系;查術語,顯示相關的關系以及對應的實體。
2 ? 構建5G協議檢索知識圖譜
2.1 ?基于知識圖譜的數據處理流程
該系統結合了自然語言數據處理技術和圖數據庫,也提供了結果的可視化功能,從數據上說,本文的方法是與數據處理和領域專家知識相結合的(如圖2),顯示了數據處理流程。
該模型包含了如下步驟:
(1)從數據文檔轉化為HTML格式文件;
(2)對HTML格式文件進行分析,分析HTML中需要提取出的內容;
(3)對數據進行前處理;
(4)抽取出標題,相關的內容以及術語的實體等;
(5)本體構建,建立三元組關系;
(6)對數據進行融合;
(7)存儲數據,并可視化數據。
本文所采取的數據來源于5G協議,針對5G現有的規范化協議,采用了1 500多份協議進行研究,這些協議是word.doc格式,所以不得不從doc文件格式中抽取信息,為了提取文本的結構,因此先將word.doc格式轉化為HTML格式進行處理,利用win32com庫實現文檔的自動轉化。
對數據進行前處理的過程中,先要對數據進行分析,并分析數據結構,觀察提取的內容所在位置以及標簽,本文采用BeautifulSoup進行HTML解析,預處理時需要對標簽等噪聲進行移除,因為部分標簽都是不需要的信息,并且還會引起干擾,容易形成噪聲,所以忽視相關的噪聲。
2.2 ?基于知識圖譜的實體提取
本文的實體抽取部分采用了兩種方式:一種是基于文本結構的實體提取方法,提取文章中的結構,以便更好的查詢文章以及內容,該方法相對較簡單,主要通過word轉化為HTML后的結構進行提取,HTML的結構都是帶有標簽,可以通過python提取標簽及內容進行提取。
第二種方式是基于深度學習的BILSTM+CRF方法進行實體提取,長短時記憶模型網絡被稱為LSTM,是一種變種的RNN,理論上,RNN可以利用任意長序列中的信息,但在實踐中,它們只能往回看幾個步驟。長短期記憶(LSTM)網絡是循環神經網絡的改進版本,它使記憶中更容易記住過去的數據,它不僅解決了RNN的消失梯度問題,而且非常適合于對未知時間滯后的時間序列進行分類、處理和預測。此外,LSTM的核心是使用隱藏狀態來保留通過的輸入信息,但一個LSTM只能從左到右獲取信息,而語義關系到上下文的信息,因此,雙向的循環神經網絡(Bi-LSTM)應運而生。在向后運行的LSTM中,保留了將來的信息,并且兩個隱藏狀態相結合能夠在任何時間點上保存過去和未來的信息,它們都適合非常復雜的問題,但是Bi-LSTM表現出了很好的結果是因為它可以更好地理解上下文,能夠通過同時考慮到上下文的語義信息。雙向LSTM正是基于這樣一種思想,即t時刻的輸出可能不僅取決于序列中先前的元素,還取決于未來的元素,例如,要預測一個序列中缺失的單詞,需要同時查看左右上下文,雙向網絡非常簡單,它們只是兩個重疊在一起的神經網絡,因此本文采用BiLSTM+CRF進行命名實體識別,并且采用了預先訓練好的詞向量模型,將文本映射到300維空間中,并且采用BIO進行數據標注。此外,本文也采用了BERT-BiLSTM-CRF進行了命名實體識別計算,但經過對比發現,BERT-BiLSTM-CRF與BiLSTM-CRF相差無幾,但是需要使用GPU進行訓練,消耗了大量的資源,而BiLSTM-CRF在CPU上即可訓練,所以BERT-BiLSTM-CRF并無太大的優勢,因此本文選擇使用BiLSTM-CRF進行訓練,采用準確率P(Precision)和召回率R(Recall)作為評價標準,計算公式分別為:
2.3 ?基于知識圖譜的關系提取
本體原來是指一個哲學概念,指的是對客觀機制的解釋和描述:一個決定名詞概念和物質關系的模型,本體的實體是一個類別,其所代表的節點就是類的一個例子,本體的關系是表現類型的關系,類型的關系類型遠比不上本體的關系類型,本體代表了許多具體的概念,如:實體、關系、對象節點、數據節點等。本體設計包含概念、關系以及實體的設計,概念是包含全部實體的統稱。該系統有標題概念,關鍵術語概念等,關系主要包括主次關系以及從屬關系,從屬關系包含父與子概念之間的關系和概念與實體之間的關系,實體是概念中的一個個體。例如,術語中的每個術語都是該概念的實體;本文主要構建兩種格式的三元組,一種是文章的結構,即標題和內容,每級標題之間的關系等,第二種是術語的屬性以及關系。表3列出了一部分知識圖譜三元組以及屬性和關系:
2.4 ?基于知識圖譜的數據融合
在數據預處理階段,初始數據的質量會直接影響到最終鏈接的結果,不同的協議數據集對同一實體的描述方式往往是不相同的,一個實體可能有多種不同的表示方式,他們只是對知識進行了不同的表述,基于實體屬性的實體對齊方法通過計算實體的名字屬性中字符串的相似度來判斷實體是否相同以及在相關的內容中進行判斷實體之間的相似性,相似度主要通過Cosine距離、Jaccard相關系數等方式進行計算:
3 ? 結果可視化
構建的網優知識圖譜是以5G協議作為基礎知識大綱,主要涉及一些網優術語以及相關的協議要求,知識圖譜就是將網優知識進行組織整理,整合的目的是使工程人員更容易理解,能更好地挖掘和呈現知識。本文基于圖數據庫Neo4j實現了搜索引擎功能,方便了工程人員進行知識搜索。本文采用Neo4j圖形數據庫對知識圖譜進行存儲,并對其可視化,圖3顯示了網優知識圖譜構建的部分示例。
此外,5G協議數據也是隨時更新版本,因此,知識圖譜也需要隨時更新,但5G協議通常會更新一部分協議,而另一部分未更新,所以,對更新版本的5G協議數據,對數據進行預處理并以三元組的JSON文件形式進行儲存,經過質量評估之后將三元組作為新增知識,并替換掉舊版本的5G協議數據,再依據Cypher語言進行實體和關系的建立,對已構建的網優知識圖譜進行更新或修正。
4 ? 結束語
本文利用數據進行轉化、預處理、信息抽取和實體融合、知識圖譜的更新迭代等方法,構建了網優領域知識庫,實現了5G協議的知識引擎搜索功能,構建了各種術語的概念、屬性以及相互之間的關系和協議文本結構間的關系,并實現了5G協議的知識引擎搜索功能,便于網優工作人員的查找和理解。本文所提出的模型適用于特殊領域因標注數據較少,文檔數據較難提取而導致無法構建知識圖譜的場景。此外,本文也可以推廣到網優其他領域進行知識圖譜構建,比如網優根因定位等問題,在下一步的研究計劃中,可以從兩方面對該系統進行改進,第一:建立5G協議術語之間更多的關系,補充知識圖譜,使知識圖譜更加準確和完整;第二:增加知識推理規則,能提高知識的精準度,而且利用規則建立更多的關系。
參考文獻:
[1] ? ?JENS LEHMANN, ROBERT ISELE, MAX JAKOB, et al. DBpedia-A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia[J]. Semantic Web Journal, 2015,6(2): 167-195.
[2] ? ?GEORGE A, MILLER. WordNet: a lexical database for English[J]. Communications of the ACM, 1995,38(11): 39-41.
[3] ? ? VOLHA BRYL, CHRISTIAN BIZER. Learning conflict resolution strategies for cross-language Wikipedia data fusion[C]//In Proceedings of the companion publication of the 23rd international conference on World wide web companion, International World Wide Web Conferences Steering Committee. Geneva, 2014: 1129-1134.
[4] ? FARZANEH MAHDISOLTANI, JOANNA BIEGA, FABIAN M, et al. YAGO3: A Knowledge Base from Multilingual Wikipedias[C]//The Semantic Web-ISWC 2016. Cham, 2016: 177-185.
[5] ? ANTOINE BORDES, EVGENIY GABRILOVICH. Constructing and Mining Web-scale Knowledge Graphs[C]//In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, 2014: 1967.
[6] ? ?DONG C, ZHANG J, ZONG C, et al. Character-based LSTM-CRF with Radical-level Features for Chinese Name Entity Recognition[J]. Natural Language Understanding and Intelligent Applications, 2016: 239-250.
[7] ? M GANZHA, L MACIASZEK, M PAPRZYCKI. Semantic Knowledge Extraction from Research Documents[C]//In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems. Gdańsk, 2016: 439-445.
[8] ? ?MARTIN RAJMAN, ROMARIC BESANCON. Text mining-Knowledge extraction from unstructured textual data[C]//In Proceedings of the 6th Conference of the International Federation of Classification Societies. Roma, 1998: 473-480.
[9] ? ?ALANI, HARITH, KIM, et al. Automatic Extraction of Knowledge from Web Documents[C]//In 2nd International Semantic Web Conference Workshop on Human Language Technology for the Semantic Web and Web Services. Florida, 2003: 634-640.
[10] ?翟社平,段宏宇,李兆兆. 基于BILSTM_CRF的知識圖譜實體抽取方法[J]. 計算機應用與軟件, 2019,36(5): 275-280.
[11] PETER CLARK, PHIL HARRISON. Large-Scale Extraction and Use of Knowledge from Text[C]//In Proceedings of the fifth international conference on Knowledge capture. USA, 2019: 153-160.
[12] ?ANKUR P PARIKH, HOIFUNG POON, KRISTINA TOUTANOVA. Grounded Semantic Parsing for Complex Knowledge Extraction[C]//In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Denver, 2015: 756-766.
[13] ? 劉嶠,李楊. 知識圖譜構建技術綜述[J]. 計算機研究與發展, 2016,53(3): 582-600.
[14] ? WANG C, GAO M, HE X, et al. Challenges in Chinese knowledge graph construction[C]//IEEE 2015 31st IEEE International Conference on Data Engineering Workshops. South Korea, 2015: 59-61.
[15] ?WANG Y, YOU W, ZHANG W, et al. Knowledge graph construction method and device[J]. US Patent Application, 2019,16(34): 799.
[16] DONG X, GABRILOVICH E, HEITZ G, et a1. Knowledge vault: a web-scale approach to probabilistic knowledge fusion[C]//Proc of the 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York, 2014: 601-610.
猜你喜歡
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
中國衛生(2015年12期)2015-11-10 05:13:38
警察技術(2015年3期)2015-02-27 15:37:09
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
