一種基于密度和距離的K-means聚類算法
2020-10-23 09:11:12羅軍鋒洪丹丹
軟件工程 2020年10期
羅軍鋒 洪丹丹


摘 ?要:針對K-means算法中對初始聚類中心和孤立點敏感的缺點,我們通過從密度和距離兩個方面的改進,提出新的改進K-means算法。該算法引入特征權(quán)重,從近鄰密度出發(fā),去除孤立點對算法的影響,同時確定初始聚類中心,在距離計算過程中,引入集成簇內(nèi)與簇間距離的計算方法,以提升聚類的效果。實驗結(jié)果表明,該算法比傳統(tǒng)聚類算法能夠提升10%以上的聚類效果。
關(guān)鍵詞:聚類;K-means;特征加權(quán);近鄰密度;孤立點
中圖分類號:TP311 ? ? 文獻標(biāo)識碼:A
A K-means Clustering Algorithm based on Density and Distance
LUO Junfeng, HONG Dandan
(Network Information Center, Xi'an Jiaotong University, Xi'an 710049, China)
luojf@xjtu.edu.cn; ddhong@xjtu.edu.cn
Abstract: In order to improve the sensitivity of initial clustering centers and outliers of K-means algorithm, an improved K-means algorithm is proposed based on density and distance. In this algorithm, feature weight is introduced to remove the influence of outliers on the algorithm from the neighborhood density. At the same time, the initial clustering center is determined. In the process of distance calculation, the distance calculation method within and between clusters is introduced to improve the clustering effect. The experimental results show that this algorithm improves the clustering effect by more than 10%, compared with the traditional clustering algorithm.
Keywords: clustering; K-means; feature weighting; neighbor density; isolated points
1 ? 引言(Introduction)
K-means[1]算法是數(shù)據(jù)挖掘算法中一種流行的、簡單的、實用的聚類算法,其特點就是思想原理簡單、聚類效果較佳。當(dāng)然,作為算法,傳統(tǒng)的K-means聚類算法存在著諸如初始聚類中心隨機選擇、K值需要事先確定、容易陷入局部最優(yōu)、對孤立點特別敏感等等缺點或者不足。
長期以來針對這些缺點或不足,許多科研人員提出了不同的改進方法和策略,形成了較完善的聚類策略。文獻[2]用在初始聚類中心的選擇中,通過引入神經(jīng)網(wǎng)絡(luò)算法改進算法,得到了很好的聚類效果;文獻[3]則引入了比較新穎的蟻群算法,將蟻群算法的核心思想和K-means算法的核心思想進行融合,同樣也達到改進聚類結(jié)果質(zhì)量這一目標(biāo)。文獻[4]首先對聚類對象進行抽樣,利用抽樣后的數(shù)據(jù)樣本的分布來確定初始聚類中心。文獻[5]提出一種基于平均密度優(yōu)化初始聚類中心的算法。文獻[6]中提出的通過使用近似加權(quán)核函數(shù)優(yōu)化目標(biāo)函數(shù)。針對孤立點的處理一般都是利用聚類數(shù)據(jù)點與聚類核心的距離超過目標(biāo)函數(shù)的閾值從而定義為孤立點,文獻[7]則通過距離公式的不同定義來將孤立點數(shù)據(jù)剔除。文獻[8]則通過集成簇內(nèi)與簇間距離的加權(quán)算法來改進算法的距離計算公式,以提升聚類的效果。
本文借鑒文獻[8]的距離計算方法,提出了一種基于密度和距離的K-means優(yōu)化算法,該算法首先計算數(shù)據(jù)對象的局部密度,以此為算法的出發(fā)點,首先去除孤立點以減少孤立點對算法結(jié)果的影響,再按照距離最遠的原則來確定初始聚類中心,隨后引入集成簇內(nèi)與簇間距離的距離計算方法進行聚類,著力提升K-means算法的性能,取得了不錯的聚類效果。
2 ?傳統(tǒng)K-means算法(Traditional K-means algorithm)
傳統(tǒng)K-means算法的基本思想是:首先從數(shù)據(jù)對象集D中隨機選擇k個對象作為初始聚類中心;接著計算每個對象到這些初始聚類中心的距離,并根據(jù)最小距離原則進行劃分,劃給聚類最近的簇;然后重新計算每個聚類簇的均值,直到計算收斂函數(shù),滿足函數(shù)收斂的要求,算法就終止,否則,重復(fù)上述過程。
傳統(tǒng)算法中由于初始聚類中心是隨機任意選取的,根據(jù)選取的初始聚類中心的不同,容易陷入局部最優(yōu),最為重要的是孤立點的存在,對平均值會產(chǎn)生很大的影響。本文因此為出發(fā)點,先著手解決如何選取初始聚類中心,消除鼓勵點,然后才根據(jù)新的距離公式進行聚類。
3 ?基于密度和距離的K-means算法(K-means algorithm based on density and distance)
針對傳統(tǒng)K-means的缺點,本算法改進包括:首先,引入近鄰密度,目的有兩個:其一,剔除聚類過程中的初始孤立點,因為孤立點對聚類的結(jié)果影響很大;其二,是用近鄰密度選擇高密度對象,并從中選擇初始聚類中心,以解決傳統(tǒng)K-means算法初始聚類中心選擇隨機造成的問題。然后利用文獻[8]的聚類方法和思想進行聚類,這樣處理的原因就是大大減輕了孤立點對聚類結(jié)果的影響,由于初始聚類中心不是隨機形成的,大大提升了文獻[8]算法的效率和效果。下面從算法的基本概念、思想、步驟等分別加以描述。
3.1 ? 近鄰密度的概念
定義1 ?k距離
在數(shù)據(jù)集D中,數(shù)據(jù)對象o距離數(shù)據(jù)對象p之間的距離,我們記為:d(p,o)。對于任意一個正整數(shù)k,我們將數(shù)據(jù)對象p 的k距離記作k-dist(p)。
當(dāng)以下兩個條件同時滿足時,我們認(rèn)為k-dist(p)=d(p,o):
(1)至多存在k-1個數(shù)據(jù)對象滿足: ? ? ?。
(2)至少存在k個數(shù)據(jù)對象滿足:;
定義2 ?k近鄰鄰居
首先,根據(jù)定義1中得到數(shù)據(jù)對象p的k距離,那么對象p的k近鄰鄰居為這樣一個集合,其中滿足:數(shù)據(jù)集中所有數(shù)據(jù)對象到p的距離小于等于k的數(shù)據(jù)對象。具體記為:。
定義3 近鄰距離
不失一般性,d(p,o)表示數(shù)據(jù)對象d和數(shù)據(jù)對象o之間的距離,那么對象p關(guān)于對象o的近鄰距離為數(shù)據(jù)對象p的k距離與數(shù)據(jù)對象o之間距離的最大值,表示為:
定義4 近鄰密度
給定任意數(shù)據(jù)集合D,數(shù)據(jù)對象p的近鄰密度定義為:
在定義4中,首先計算數(shù)據(jù)集中所考察對象p的k近鄰所有鄰居對象到對象p的近鄰距離之和。如果數(shù)據(jù)對象近鄰密度取值小,就說明它的k近鄰鄰居所涵蓋的范圍就非常小,這個區(qū)域就是個高密度區(qū)域。
3.2 ? 算法目標(biāo)函數(shù)
設(shè)為一個包含n個數(shù)據(jù)對象的數(shù)據(jù)集合,其中第i個數(shù)據(jù)對象表示為,m為數(shù)據(jù)對象屬性的數(shù)目。由D生成的k近鄰密度矩陣為
,依據(jù)公式(1)進行計算。數(shù)據(jù)對象分配矩陣U是的0-1矩陣,=1表示第i個屬性被分到第P個簇。為k個簇中心向量,其中為第p個簇中心。為k個權(quán)重向量,其中代表第p個簇的特征權(quán)重,為第p個簇中第j個特征的權(quán)重。通過結(jié)合簇間距離與簇內(nèi)距離的信息,本算法目標(biāo)函數(shù)為:
其中:
文獻[8]已經(jīng)證明了如何計算,,,這里就不在多做敘述。
3.3 ? 算法步驟與描述
針對文獻[8]改進后的新算法分三大步驟:
首先,根據(jù)預(yù)先設(shè)定的特定權(quán)重W來計算各個對象的k近鄰密度矩陣;預(yù)先設(shè)定一個閾值,這個值的設(shè)定關(guān)系到聚類的效果,其主要目的是用來剔除孤立點,然后將剩余的所有數(shù)據(jù)對象重新組合成新的數(shù)據(jù)對象,重新對新的數(shù)據(jù)對象集進行聚類,構(gòu)造新的k近鄰密度矩陣和特征權(quán)重W。
然后,對構(gòu)造出來的進行從小到大的排序,將排在前列的2k個數(shù)據(jù)對象選擇出來,將作為初始的聚類中心候選集。在這個候選集中首選選取前兩個數(shù)據(jù)對象作為初始聚類中心,在候選集中剩余的數(shù)據(jù)對象中選取距離這兩個初始聚類中心最遠的一個數(shù)據(jù)對象加入初始聚類中心集中,以此類推,直到最終k個數(shù)據(jù)中心Z形成。
最后,根據(jù)文獻[8]中的算法進行聚類。
算法詳細(xì)描述如下:
輸入:d維數(shù)據(jù)集D、預(yù)先設(shè)定的特征權(quán)重W、k近鄰離群閾值
輸出:滿足準(zhǔn)則函數(shù)最小的k個族類
(1)用設(shè)定的特征權(quán)重W和距離公式來計算各個數(shù)據(jù)對象之間的加權(quán)距離,得到各數(shù)據(jù)對象的K-dist近鄰矩陣,并一并形成構(gòu)造K-dist近鄰鄰居矩陣和近鄰密度NND矩陣。
(2)根據(jù)近鄰密度矩陣,判斷所有對象的NND是否大于離群閾值,如果是大于,則將該數(shù)據(jù)對象作為孤立點去除;如果不是,則保留該數(shù)據(jù)對象;同時選擇NND最小的2k個對象作為準(zhǔn)初始聚類中心集待用。
(3)在步驟2中形成的矩陣中選取最下的2k個數(shù)據(jù)對象作為候選初始聚類中心,然后首先從中選取距離最遠的兩個數(shù)據(jù)對象和,將其作為初始的2個聚類中心,同時在候選初始聚類中心集中刪除這兩個對象,依次類推,直到找到k個初始聚類中心。
(4)從上個步驟中得到的這k個初始聚類中心為聚類中心,利用文獻[8]的算法KICIC循環(huán)反復(fù),直到P(W,U,Z)收斂或U不再改變。
3.4 ? 性能分析
根據(jù)上面的算法描述可以看出,改進后的聚類算法(簡稱NKICIC)的時間復(fù)雜度與傳統(tǒng)K-means聚類算法的區(qū)別主要體現(xiàn)在形成初始聚類中心的時候,本算法在形成初始聚類中心的時間復(fù)雜度為:
由于算法在計算每一個數(shù)據(jù)對象的距離矩陣后也會將其自身的距離矩陣保存起來以方便后續(xù)使用。這里,通過以空間換時間,算法的時間復(fù)雜度會大大降低,當(dāng)然,其空間開銷也會很巨大,經(jīng)過測算,增加的空間規(guī)模為的空間開銷。實驗表面,這種方法至少提高10倍以上的時間效率。
4 ? 實驗及結(jié)果分析(Experiments and results analysis)
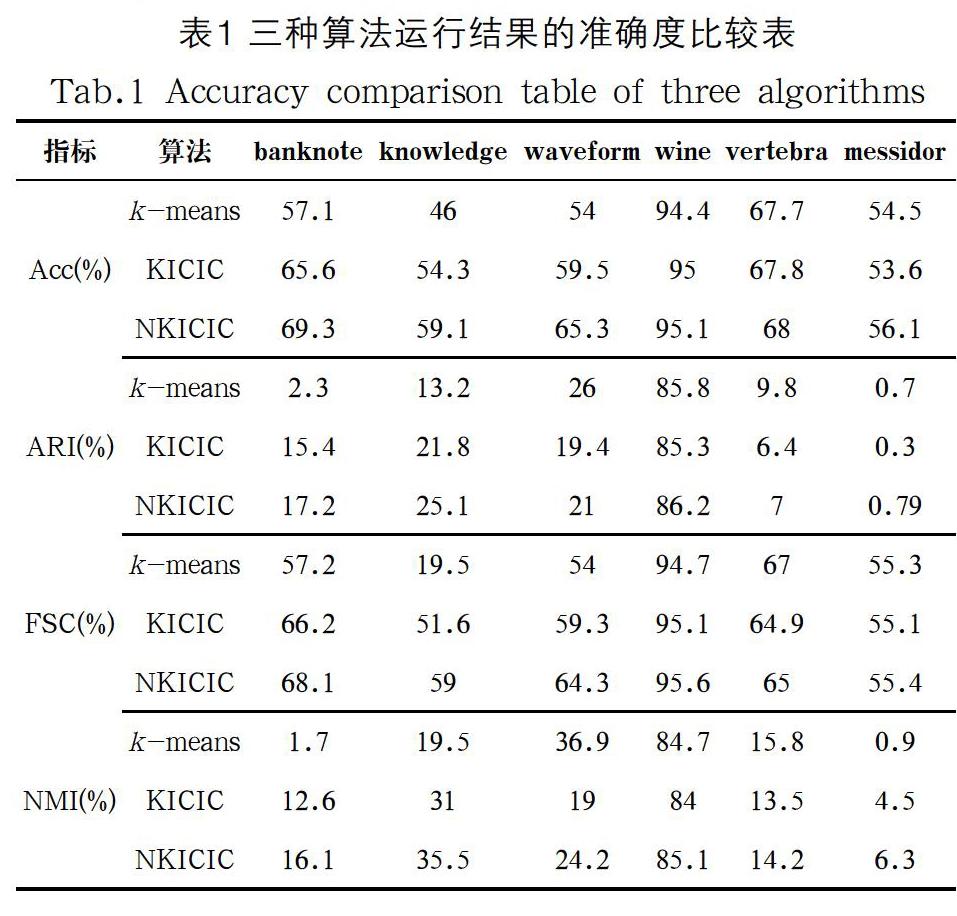
為了便于和文獻[8]的算法KICIC進行對比,我們同樣從網(wǎng)站上下載了六個數(shù)據(jù)集,算法所用的幾個參數(shù)采用了文獻[8]的結(jié)果,以同樣的評價指標(biāo)主要分析了傳統(tǒng)K-means、KICIC算法與改進后的NKICIC算法。
實驗結(jié)果:根據(jù)表1的結(jié)果分析,NKICIC總體上優(yōu)于原KICIC算法,遠優(yōu)于傳統(tǒng)K-means算法。主要原因是由于原算法KICIC中沒有消除孤立點,加上對初始聚類中心的敏感原因?qū)е戮垲惤Y(jié)果不穩(wěn)定。
根據(jù)表1中的數(shù)據(jù)可以得出,從各項指標(biāo)來看,改進后的K-means算法的綜合聚類效果提高了不少。
算法的時間性能方面,實驗結(jié)果如圖1所示。
從圖1中可以看到,改進后的算法雖然增加了三個矩陣的計算時間消耗,但由于三個矩陣為后期刪除了孤立點、確定了初始聚類中心,大大減少了后期聚類算法的收斂時間,兩者抵消,所以總的時間消耗沒有增加太多。
5 ? 結(jié)論(Conclusion)
本文在傳統(tǒng)距離公式中加入特征屬性的權(quán)重,并據(jù)此計算每個數(shù)據(jù)對象的近鄰矩陣,通過定義一定的距離閾值來減輕數(shù)據(jù)孤立點對聚類算法執(zhí)行結(jié)果的影響,同時有針對行的選擇形成初始聚類中心,隨后根據(jù)集成族內(nèi)與族間的距離來進行聚類。實驗結(jié)果顯示,新的聚類算法在性能基本沒有損耗的情況下提升了原算法的準(zhǔn)確度和聚類效果。
參考文獻(References)
[1] James MacQueen. Some methods for classification and analysis of multivariate observations[C]. Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability, University of California Press, 1967: 281-297.
[2] Wang Huai-bin, Yang Hong-liang, Xu Zhi-jian. A clustering algorithm use SOM and K-Means in Intrusion Detection[C]. 2010 International Conference on E-Business and E-Government, Guangzhou, 2010: 1281-1284.
[3] 莫錦萍,陳琴,馬琳,等.一種新的K-Means蟻群聚類算法[J].廣西科學(xué)院學(xué)報,2008,24(4):284-286.
[4] 曹志宇,張忠林,李元韜.快速查找初始聚類中心的k-means算法[J].蘭州交通大學(xué)學(xué)報,2009,28(6):15-18.
[5] 邢長征,谷浩.基于平均密度優(yōu)化初始聚類中心的k-means算法[J].計算機工程與應(yīng)用,2014,50(20):135-138.
[6] Jia H,Ding S,Du M,et al.Approximate normalized cuts without eigen-decomposition[J].Information Sciences,2016(374):135-150.
[7] 張建民.一種改進的K-means聚類算法[J].微計算機信息,2010(9):233-234.
[8] 黃曉輝,王成,熊李艷,等.一種集成簇內(nèi)和簇間距離的加權(quán)k-means聚類方法[J].計算機學(xué)報,2019,59(42):1-15.
作者簡介:
羅軍鋒(1976-),男,碩士,高級工程師.研究領(lǐng)域:數(shù)據(jù)挖掘,區(qū)塊鏈.
洪丹丹(1981-),女,碩士,高級工程師.研究領(lǐng)域:主數(shù)據(jù)工程,高校信息化.
