任意初始位置機器人領航跟隨型迭代學習編隊
2020-10-19 04:41:12卜旭輝
計算機工程與應用 2020年20期
關鍵詞:移動機器人
侯 銳,卜旭輝
河南理工大學 電氣工程與自動化學院,河南 焦作 454000
1 引言
由于單個機器人在各方面能力的限制,很難獨自完成某些工作任務,所以近年來多機器人系統協同工作成為行業研究的熱點。多移動機器人協同編隊在無人技術領域有著重要作用,例如聯合作業、群體偵察、協作運輸等領域,使得多移動機器人編隊控制問題成為重要的研究方向。多移動機器人協同編隊要求各個不同位置的移動機器人在執行任務時能夠自主協作形成一個期望的編隊隊形,同時保持期望編隊隊形沿著指定的航跡工作。根據實際工作的需要,多移動機器人的編隊隊形可以是三角形、正方形,也可以是直線型等形狀[1]。
從目前已有的文獻來看,多移動機器人編隊的控制方法主要有:虛擬結構法(Virtual-structure)、基于行為的方法(Behavior-based)、領航-跟隨型方法(Leader-Follower)等[2]。虛擬結構法將整個編隊視為一個單獨的虛擬結構,同時控制整個虛擬結構進行期望運動,雖然能夠很容易實現編隊并且描繪出虛擬結構中各個移動機器人的軌跡,但是會導致系統的靈活性和適應性不足;基于行為的方法通過多移動機器人的行為描述實現編隊和軌跡跟蹤,但是難以用數學方法進行分析,因此很難獲得精確的編隊效果。而領導-跟隨型編隊控制效果準確穩定且分析簡單,非常適用于小型多移動機器人編隊控制。在領航-跟隨型編隊控制方法中,一般選擇一個或多個領航者(Leader),其余均為跟隨者(Follower)。編隊過程中,領航者負責按照預先規劃好的航跡進行工作,而其他跟隨者利用領航者當前的信息調整自己的狀態,通過跟隨者的局部控制就能夠實現與領航者保持一定距離和角度。文獻[3]通過控制領航者與跟隨者的相對距離和相對角度實現多移動機器人的編隊。文獻[4]將編隊問題轉化為軌跡跟蹤問題,利用軌跡跟蹤的控制方法實現自主形成編隊隊形,同時確保編隊系統的穩定性。文獻[5]將Backstepping-based方法應用于多移動機器人的編隊,為各個移動機器人設計了控制律。文獻[6]將滑模變結構控制用于多移動機器人的編隊。文獻[7]采用模糊控制建立模糊集合對移動機器人進行編隊控制。
綜上所述,對于多移動機器人領航-跟隨型編隊控制,大多采用滑模控制、基于Backstepping-based方法以及基于Lyapunov 的方法來設計控制器,雖然有大量的研究解決編隊控制中編隊形成和編隊隊形保持問題,但是上述方法均是在時間域上實現的漸進跟蹤控制,控制精度較低,很難實現精確的編隊效果。迭代學習控制(Iterative Learning Control,ILC)作為一種具有“學習”性質的算法,通過對被控系統進行控制嘗試,能夠通過多次學習,利用過去學習獲得的信息,以輸出信號與給定目標修正不理想的控制信號,提高系統的跟蹤性能,高精度地跟蹤期望目標[8]。迭代學習控制[9-13]已經成功應用于具有較強非線性耦合、難以建模以及高精度跟蹤控制要求的系統上[14-16]。但傳統的迭代學習控制在研究中,要求每次迭代的初始位置需要和期望軌跡的初始位置相同[17],即在初始時刻已經形成期望編隊,這就限制了迭代學習控制在多機器人編隊控制方面的應用。
基于此,本文設計了一種在任意初始位置條件下基于領航-跟隨型的移動機器人迭代學習編隊控制算法,運用控制算法自主調節跟隨機器人的實時位姿,確保完成從任意初始位置到目標位置的多移動機器人編隊運動。相較于以上算法,本文設計的控制算法能夠實現:
(1)領航者和跟隨者經過多次迭代學習,能夠在期望航跡上進行工作。
(2)初始時刻在任意位置的跟隨者經過多次迭代學習,能夠和領航者一起形成期望的編隊隊形。不需要考慮編隊初始時刻各個機器人之間的位置關系是否與期望隊形相同。
2 問題描述
2.1 移動機器人運動學
考慮一組由多個移動機器人組成的隊列,首先建立每個移動機器人的運動學模型[18],如圖1所示,[x(t)y(t)θ(t)]為t時刻移動機器人的位姿向量,分別是移動機器人在二維坐標系中橫坐標、縱坐標以及前進方向與橫軸夾角。[v(t),w(t)] 表示移動機器人的角速度和線速度,即控制輸入向量。
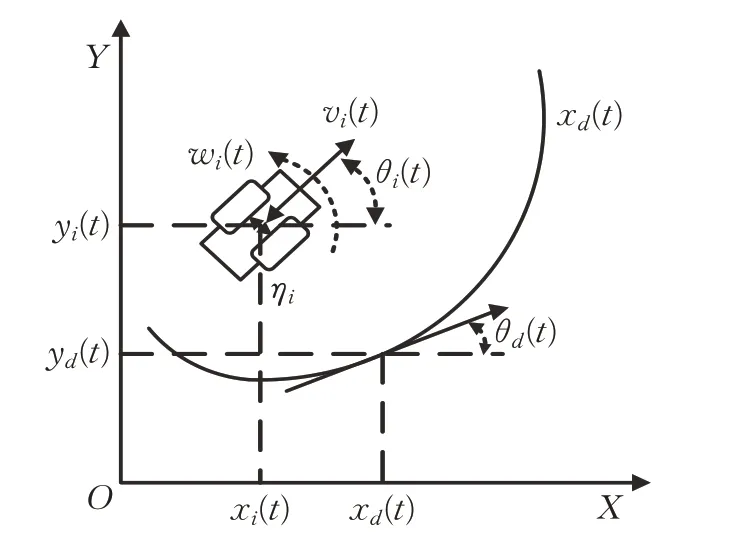
圖1 移動機器人運動學模型
移動機器人的運動學模型可表示為:
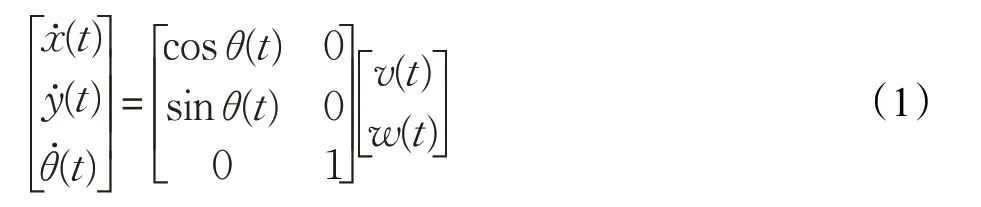
定義:

則運動學模型(1)可以表示為:

式中:
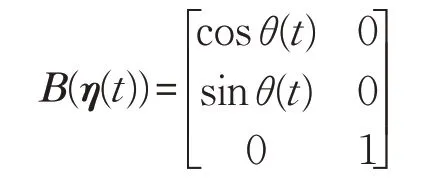
假設移動機器人的狀態都是可測的。
2.2 領航-跟隨型編隊控制
本文采用領航-跟隨型編隊控制,選定一個移動機器人i(i=1)作為整個系統的領航者,而其余機器人全部作為跟隨者j(j=1,2,…),建立領航-跟隨型編隊的運動學模型,如圖2 所示,給出了多移動機器人三角形編隊示意圖。領航者保持期望航跡航行,跟隨者跟蹤編隊軌跡,并利用領航者的信息調整自身的位姿狀態。
利用視距法,計算出跟隨者的期望位置:
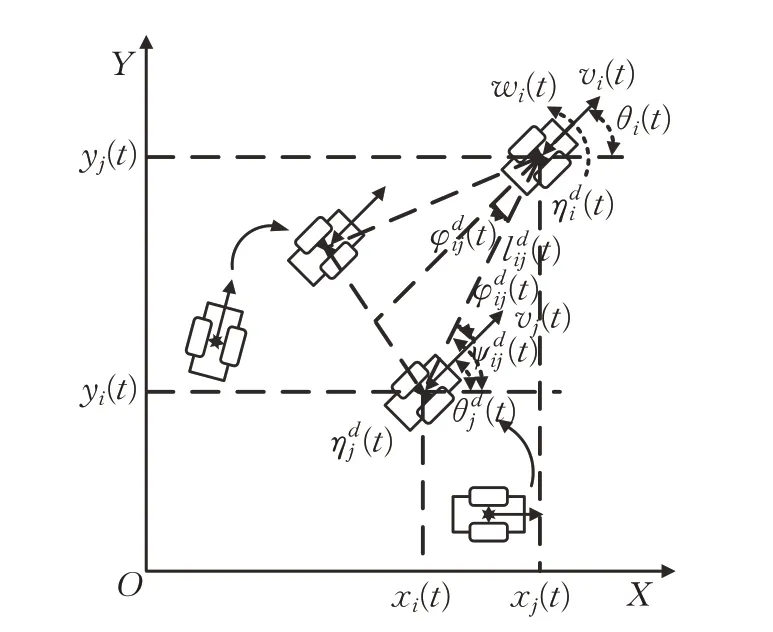
圖2 領航-跟隨型編隊示意圖

其中:
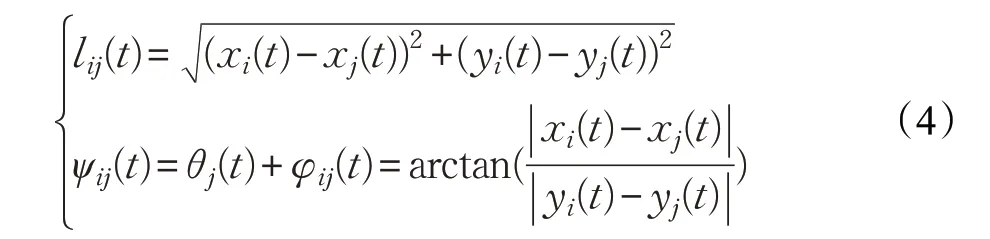
跟隨者與編隊期望位置之間的系統誤差表示為:

式中ej(t)=[xe(t)ye(t)θe(t)]T,t∈[0,T]。
本文目的是設計合適的控制器,實現多移動機器人的編隊問題,即為0或者一個極小值)。
3 控制器設計與收斂性分析
針對上述領航-跟隨型編隊控制中提出的問題,本章提出一種同時包含編隊初始位置的學習控制律和編隊形成的學習控制律。在學習過程中,假定一段時間范圍[0,T]內,當前的迭代進行到k次,則跟隨者j的運動學模型可由式(2)重新表示為:

式中:
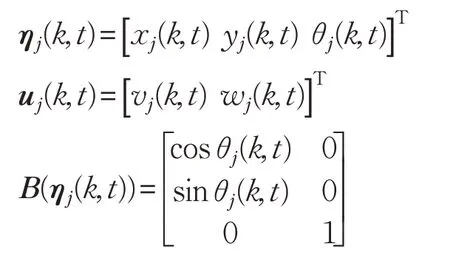
系統誤差可由式(5)重新表示為:

根據移動機器人的運動學模型和實際編隊特點,可以給出如下假設:
假設1矩陣B(ηj(k,t))對于ηj(k,t)滿足全局Lipschitz條件,即存在常數bA,使得下式成立:
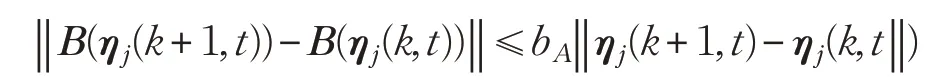
假設2矩陣B(ηj(k,t))有界,即其中bB為正常數。
假設3給定的期望位姿,存在控制輸入滿足,且期望控制輸入滿足為正常數。
注1由于矩陣函數B(ηj(k,t))中僅包含函數cosθj(k,t)、sinθj(k,t),因此,假設1的Lipschitz條件和假設2的有界性都是滿足的。假設3 是多次迭代后系統實現學習跟蹤的必須條件。
3.1 控制器設計
利用位姿誤差對跟隨者j分別設計如下速度分量學習控制器以及初始位置分量的學習控制器:
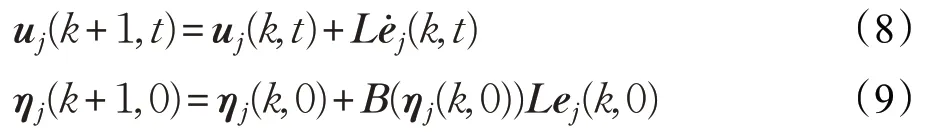
式中,t∈[0,T],k為迭代次數,L為學習增益矩陣。控制器(8)能夠實現多次迭代學習后領航者和跟隨者在期望航跡上進行工作。控制器(9)能夠實現通過每次迭代調整跟隨者j的初始位置。
3.2 收斂性分析
定義定義下列范數:
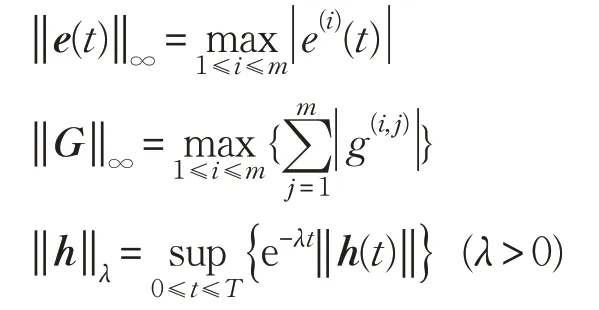
其中e(i)(t)是e(t)∈Rm中的第i個元素,g(i,j)是G∈Rm×m中的第i,j元素,可給出如下定理。
定理對于滿足假設1~3的系統式(6),采用式(8)、(9)的控制算法時,當學習增益矩陣對所有的k、t均滿足:
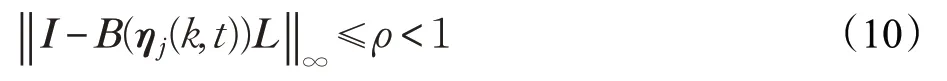
則系統的輸出收斂于期望輸出,即當k→∞時,有η(k,t)→ηd(k,t),t∈[0,T]。
證明由式(6)~(9)得:
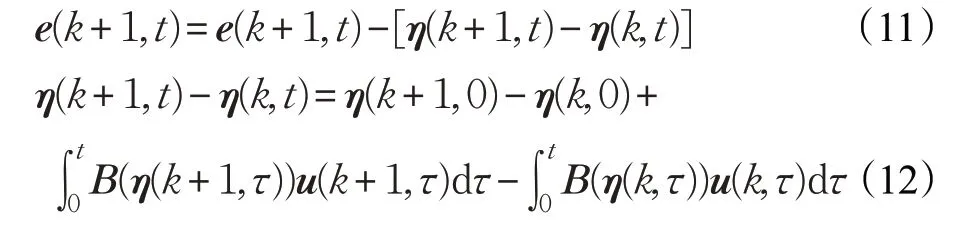
由假設2、假設3可得:
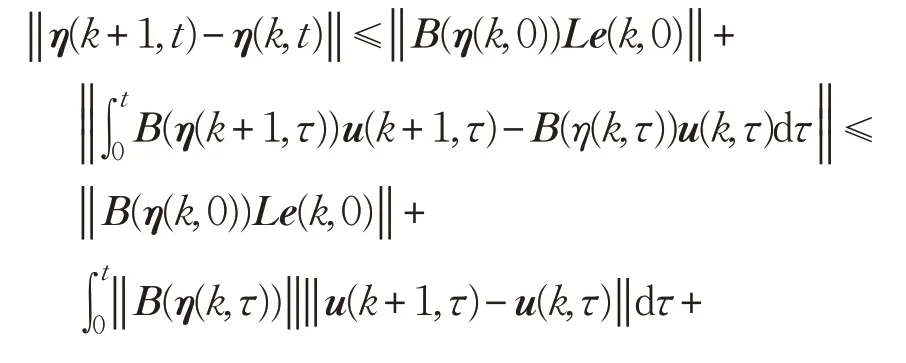
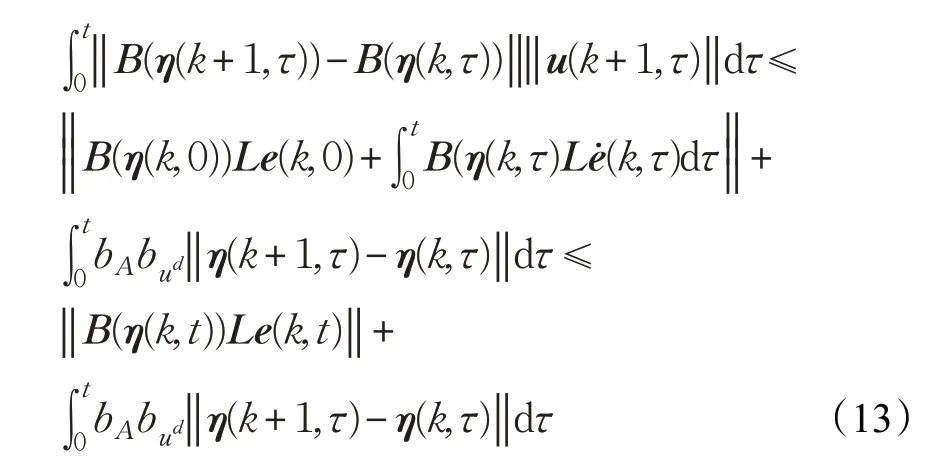
式(13)兩邊同時乘以 e-λt,并取范數,考慮假設1 中的Lipschitz條件得:
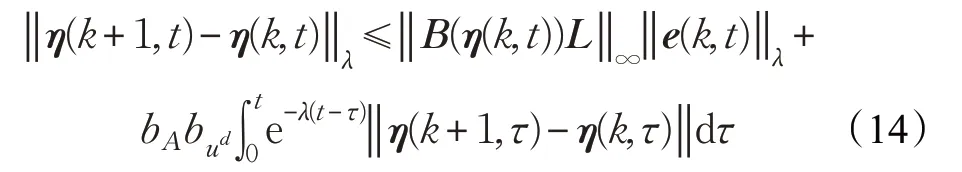
應用Bellman-Gromwall引理可得:
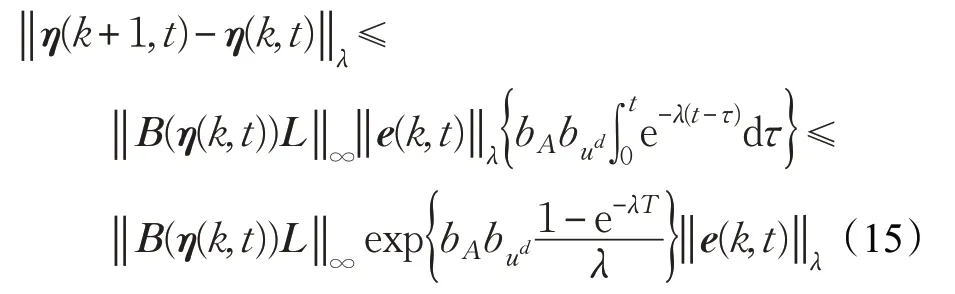
4 仿真研究
本章中,采用MATLAB 軟件進行仿真,選取3 個移動機器人進行編隊控制的仿真研究,分別作為領航者、跟隨者1、跟隨者2。采用本文設計的編隊算法(8)、(9)進行編隊,記錄跟隨者在不同初始位置情況下經過多次迭代后形成的編隊軌跡,若最終領航者和跟隨者能夠實現在預定航跡上以期望隊形工作,則證明本文設計的編隊控制算法有效。

即在二維平面內領航者期望軌跡的初始位置(20,0)。
設跟隨者1、跟隨者2 在二維平面內的初始位置分別為(15,2),(23,-2),即初始狀態:
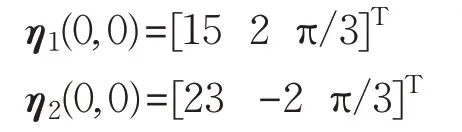
采用三角形編隊,設期望編隊隊形相對位置的期望向量分別為:
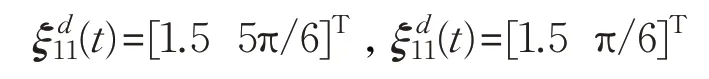
初始輸入速度信息分別為:
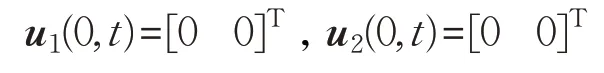
仿真過程中的采樣時間取0.001 s。仿真中跟隨者1和跟隨者2控制器的學習增益矩陣分別為:

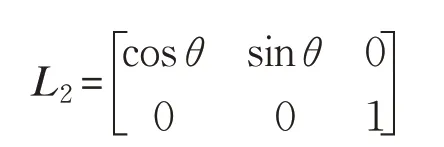
仿真結果如下,圖3(a)~(c)分別給出了領航者與跟隨者的期望編隊效果、迭代20次和迭代150次的編隊效果,其中x、y坐標均表示二維平面上的距離。可以看出,隨著迭代次數的增加,領航者和跟隨者能夠實現較為理想的編隊效果。圖4(a)、(b)反映跟隨者1 和跟隨者2的位姿誤差隨迭代次數的變化情況,可以看出經過一定次數的迭代優化,各個跟隨者的位姿跟蹤誤差逐漸收斂到0。
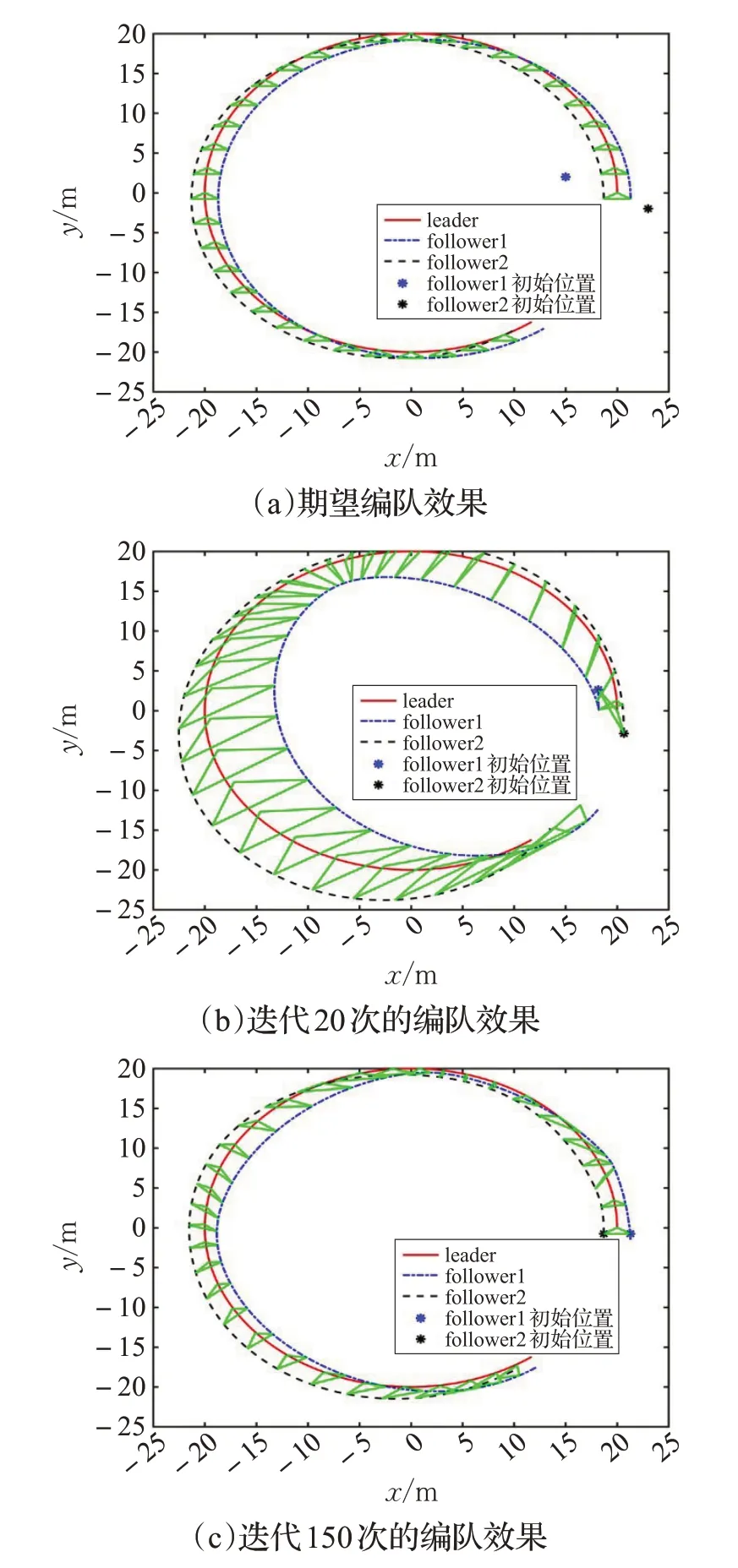
圖3 編隊效果
為了突出本文控制器不需要考慮機器人編隊初始位置的優點,圖5 給出了跟隨者1 和跟隨者2 初始位置在二維平面的變化。圖6(a)、(b)分別為跟隨者的初始位置在迭代軸上的變化。以上說明基于領航-跟隨型的迭代學習編隊算法,可以精確地實現編隊效果。
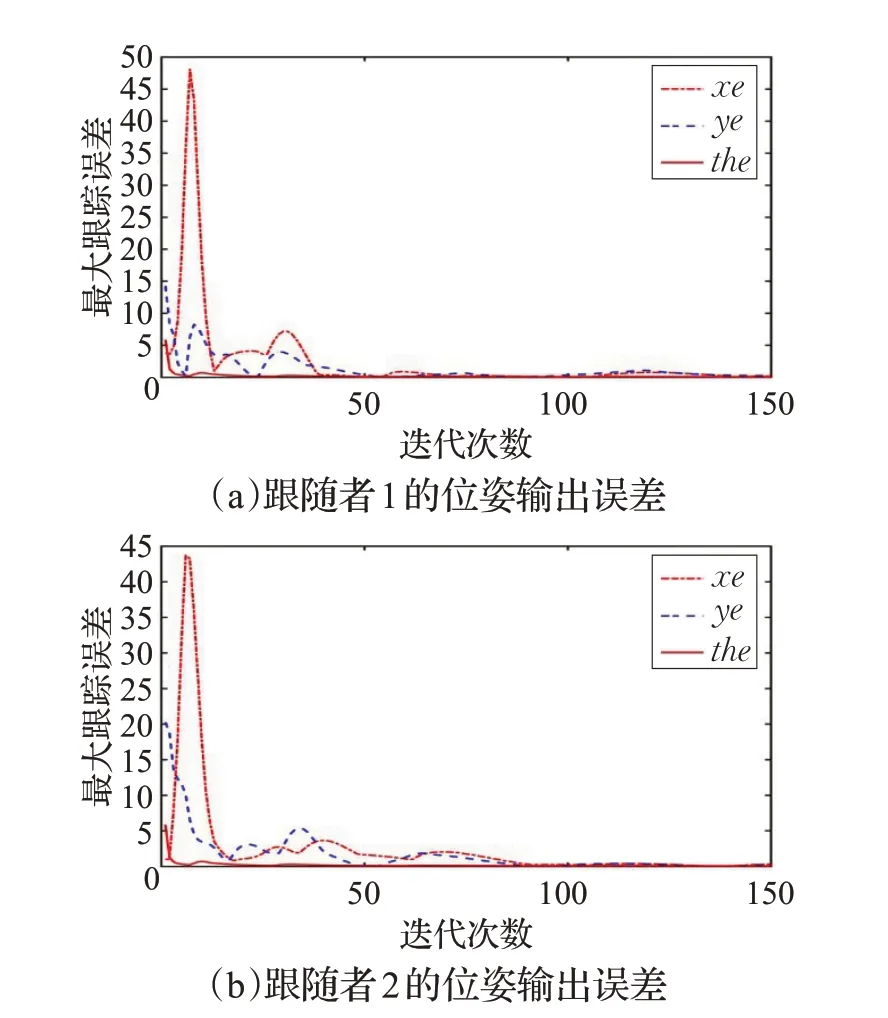
圖4 各個跟隨者輸出的最大位姿誤差對迭代次數的變化
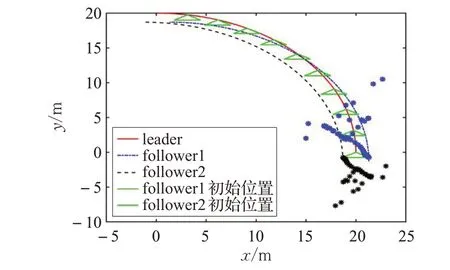
圖5 跟隨者初始位置在二維平面的迭代變化軌跡
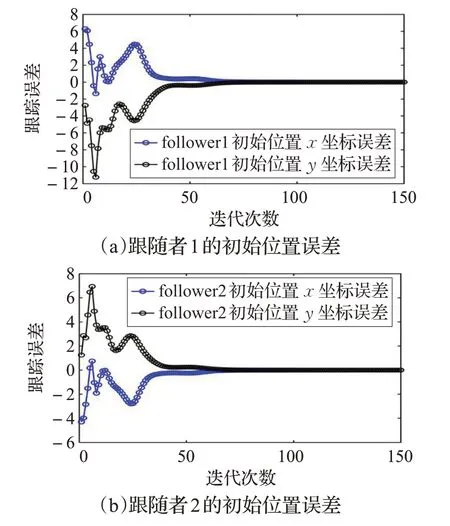
圖6 跟隨者初始位置誤差在迭代軸上的變化
在實際應用中,很難要求移動機器人在編隊的初始時刻就位于期望位置,而且每次對移動機器人重復定位操作往往會造成迭代初始位置相對期望位置的偏移。從圖5和圖6可以看出采用本文設計的控制器能夠很好地規避這一編隊難點。
為了驗證跟隨者任意初始位置對編隊效果的影響,改變跟隨者1、跟隨者2的初始位置,假設初始狀態分別為:
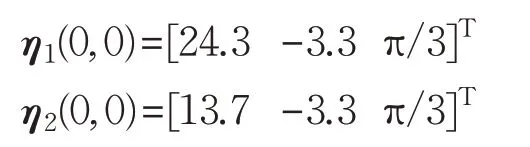
初始輸入不變:
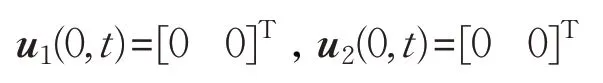
即在二維平面內的跟隨者1和跟隨者2的初始位置分別為(24.3,-3.3)和(13,7),與原先的初始位置完全不同,仍然選擇三角形編隊,期望編隊隊形相對位置的期望向量分別為,領航者與跟隨者按照相同的航跡進行編隊,仿真過程中的采樣時間仍取0.001 s,采用與上述仿真相同的控制算法(8)、(9)。
仿真結果如圖7,圖(a)、(b)分別給出了在新的初始位置條件下編隊的期望軌跡和迭代150次的編隊效果,可以看出,改變跟隨者的初始位置后,依然能夠利用本文設計的控制算法進行編隊。
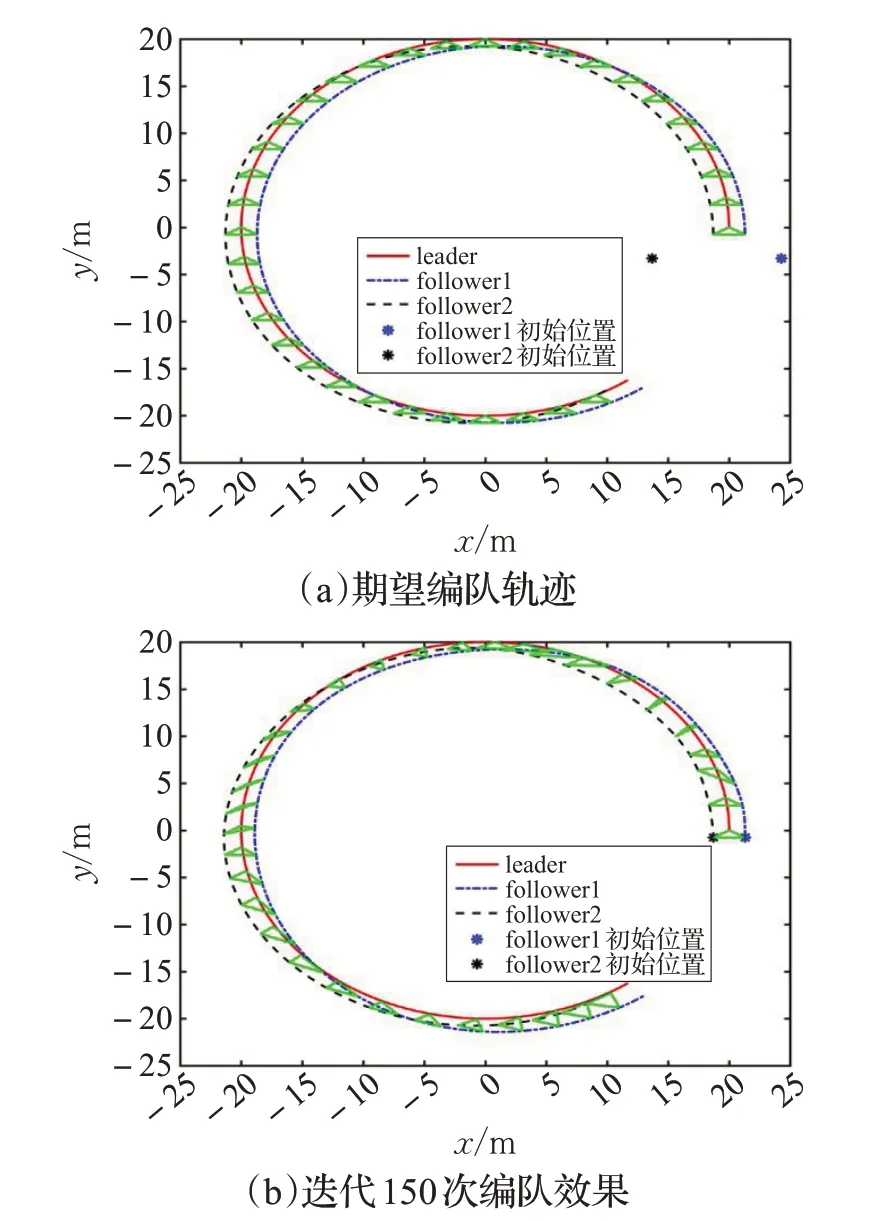
圖7 跟隨者不同初始位置時的編隊效果
由以上仿真結果可以看出,利用本文設計的基于領航-跟隨型迭代學習編隊算法,能夠有效地實現在任意初始位置條件下多移動機器人的編隊運動。
5 結束語
針對多移動機器人編隊運動中,以往的編隊方法都是在時間域上的漸進跟蹤控制,本文采用迭代學習控制算法來設計編隊控制器,同時,為解決傳統的迭代學習要求各個移動機器人的初始位置與期望軌跡初始位置相同這一要求,在算法中加入了對初始位置的學習,設計了一種在任意初始位置條件下基于領航-跟隨型的移動機器人迭代學習編隊控制算法,大大提高了迭代學習在編隊控制應用中的實用性和普遍性。理論方面基于壓縮映射方法給出了該算法的收斂性證明。并通過仿真驗證了所提算法的有效性。在系統仿真實驗中,發現編隊迭代次數過多,但本文主要目的是通過將迭代學習控制應用在多移動機器人協同編隊控制中,并驗證算法的有效性,還未考慮迭代學習收斂速度的問題,迭代過程時間長短對實際工程的影響很大,這也是后續需要進一步研究的問題之一。
猜你喜歡
北京航空航天大學學報(2022年6期)2022-07-02 01:59:12
四川輕化工大學學報(自然科學版)(2021年3期)2021-08-30 06:37:02
中國慣性技術學報(2019年3期)2019-10-15 07:21:02
電子測試(2018年15期)2018-09-26 06:01:34
制造技術與機床(2017年3期)2017-06-23 08:11:21
智能系統學報(2015年4期)2015-12-27 09:38:35
機電產品開發與創新(2014年5期)2014-03-11 16:42:32
鄭州大學學報(理學版)(2014年3期)2014-03-01 04:21:09
中國海洋大學學報(自然科學版)(2014年8期)2014-02-28 12:21:31
中國海洋大學學報(自然科學版)(2014年7期)2014-02-28 12:21:19
