遷移學習技術及其在醫療領域中的應用
2020-10-12 01:32:44吳騁秦嬰逸李冬冬王志勇
中國醫療設備 2020年9期
吳騁,秦嬰逸,李冬冬,王志勇
1. 海軍軍醫大學 軍隊衛生統計學教研室,上海 200433;2. 海軍軍醫大學第一附屬醫院 信息科,上海 200433
引言
近年來,隨著科技發展,大量機器學習和深度學習技術已被成功應用到各個領域,如情感分析、推薦系統和人臉識別等,醫療領域也是其重要的研究與應用方向之一。為了保證機器學習和深度學習模型的性能,通常對數據有一些要求:訓練數據和測試數據需來自同樣的特征空間且具有相同分布[1]。然而,醫療領域的數據具有多而雜、非結構化數據占比大、專業性強等特點,對醫療記錄的標注需要熟悉診療過程的醫學專業人員的指導,使得標注任務繁重且周期較長。因此,如果可以將其他領域中的知識遷移到醫療場景中,將帶來極大的便利。遷移學習就是為了解決此類問題而提出的一種機器學習技術[2-4],根據分類方法主要包括三個方面:① 學習情境:歸納式遷移學習、直推式遷移學習、無監督遷移學習;② 特征空間:同構遷移學習、異構遷移學習;③ 學習方式:基于實例的遷移學習、基于特征的遷移學習、基于模型的遷移學習、基于關系的遷移學習。
1 遷移學習方法
1.1 基于實例的遷移學習
基于實例的遷移學習是遷移學習中較為簡單的一種,主要通過權重重復利用源域和目標域中的樣本,實現知識的遷移。它的基本假設是源域和目標域中有一部分樣本特征相同。TrAdaboost 是基于樣本遷移學習的典型方法,在2007 年由Dai 等[5]率先提出,其主要思想是提高有利于目標任務性能的樣本權重,降低不利于目標任務性能的樣本權重,最終得到一個在目標域中性能更好的模型。Yao 等[6]考慮了多個源域的知識,對TrAdaboost 進行了改進,提出多源域TrAdaboost(Multi-Source TrAdaboost,MTrA),選擇與目標域最相關的源域知識進行遷移,有效避免了只有一個源域而造成的負遷移問題。Cheng 等[7]在2013 年又對MTrA 進行了改進,提出了加權多源域TrAdaboost,將多個源域的知識進行加權求和,進一步提升了模型的性能。
1.2 基于特征的遷移學習
基于特征的遷移學習方法是遷移學習中熱門的研究領域,主要是利用源域和目標域中共享的特征表示,減少源域和目標域的差距,從而提高模型在目標域任務上的性能。根據對特征的不同處理方法,可以將其分為基于特征選擇的遷移學習方法和基于特征映射的遷移學習方法,前者是從源域和目標域中選擇出一些共有的特征,利用這些共有特征完成知識遷移;后者一般是將源域和目標域數據映射到同一低維空間,在這個低維空間中源域和目標域特征接近或數據分布趨于一致,從而完成知識遷移的過程。
Uguroglu 等[8]在2011 年提出一個基于特征選擇的遷移學習方法,并將其成功的運用在了領域自適應方面,該方法主要是結合最大均值差異(Maximum Mean Discrepancy,MMD)這一統計量,尋找對源域和目標域距離貢獻較大的一些特征。MMD 的計算如公式(1)所示,其中,F表示映射函數域,X={x1,x2…xm}和Y={y1,y2…ym}分別表示源域和目標域中的數據。作者實驗結果表明,使用特征選擇的方法建立的模型較使用所有特征建立的模型預測準確率提高了30%。
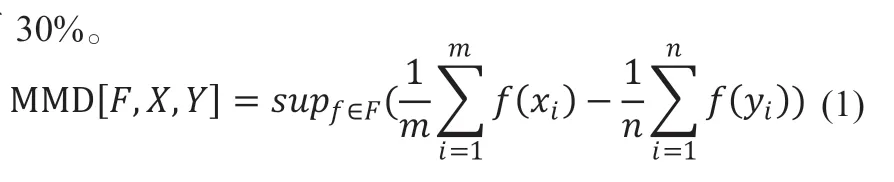
Persello 等提出一種基于核的域不變特征選擇方法,該方法主要關注輸入變量X和輸出變量Y之間的特征相關性R和源域、目標域數據集之間的偏移Θ,將使得目標函數最小的特征作為最終的優化目標,如公式(2)所示,其中,F表示特征,l表示最終特征子集的大小。
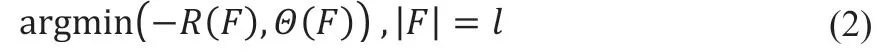
Pan 等[10]提出一種基于特征映射遷移學習的降維方法,該方法首先通過最大均值差異嵌入學習一個低維潛在空間,在該空間中源域和目標域的分布接近,然后再使用低維空間中的數據訓練一個傳統的機器學習模型,在文本分類等任務中該方法都獲得了顯著的性能提升。Dai 等[11]使用馬爾可夫鏈和最小化風險的方法建立了名為TLRisk 的“翻譯學習”方法,該方法使用語言模型連接源域中數據特征和數據標簽,然后將這種關系“翻譯”到目標域中。在文本輔助圖像的分類任務和跨語言分類任務中(英語語料作為源域數據,德語語料作為目標域數據),TLRisk 都獲得了不錯的成績。
1.3 基于模型的遷移學習
基于模型的遷移學習一般將從源域中訓練好的模型整體或者一部分遷移到目標域中使用,基本假設是源域和目標域共享模型的參數,因此又被稱為基于參數的遷移學習。近年來,神經網絡和深度學習領域發展迅速,出現了很多性能優良的深度學習模型,因此很多基于模型的遷移學習方法都與深度學習技術相結合。2014 年,Yosinski 等[12]基于卷積神經網絡(Convolutional Neural Network,CNN)模型進行了深度學習模型的可遷移性研究,利用AlexNet 網絡結構逐層遷移并微調對比研究,結果證明基于模型的遷移學習方法是有效的,并且深度學習模型中前幾層學習到的為普遍特征,對前幾層進行遷移的效果比較好。此后,神經網絡和遷移學習相結合的遷移學習方法受到越來越多研究者的關注。Gretton 等[13]對MMD 進行了改進,提出了多核MMD(Multiple-kernel MMD,MK-MMD),為后續的許多研究工作提供了基礎。Long 等[14]將MK-MMD與CNN 結合,提出了深度適應性網絡(Deep Adaptation Network,DAN)。實驗證明,多核方法相比于單核方法具有更強的適應性,DAN 可以得到無偏的深度特征。DAN的基本結構如圖1 所示。固定了AlexNet 網絡中前兩個卷積層不動,對第三、四和五個卷積層進行了微調,同時在最后的三個全連接層中增加了MK-MMD 算法來降低源域和目標域的差異。Long 等[15]在2017 年提出將聯合MMD 與神經網絡算法相結合的聯合適應網絡算法,在CNN 的特定任務相關層使用聯合分布來學習深度特征,提升模型性能。
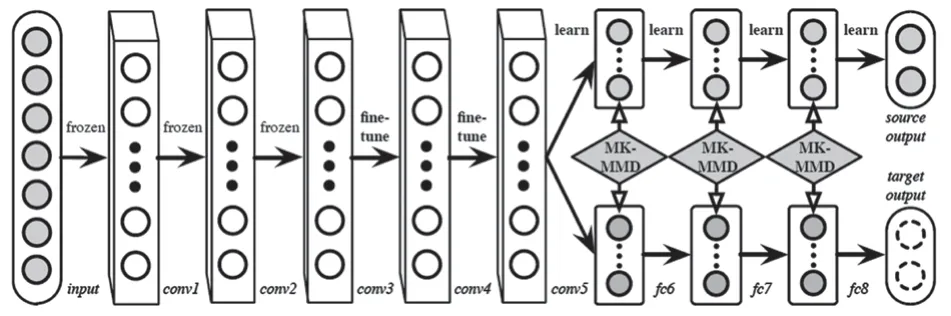
圖1 DAN結構圖
1.4 基于關系的遷移學習
基于關系的遷移學習方法的基本假設是源域和目標域共享某種邏輯網絡關系,目前基于關系的遷移學習方法研究較少,多數為基于馬爾可夫網絡的模型。Davis 等[16]基于二階馬爾可夫邏輯方法,建立了一個深度遷移學習模型,該模型用帶謂詞變量的馬爾可夫邏輯公式發現源域中的結構規則,再用目標域中的謂詞實例化這些公式,從而完成關系的遷移過程。
2 遷移學習技術在醫療領域中的應用
醫療領域中的數據量非常龐大、數據類型多樣,多數為非結構化數據,且具有較強的專業性,因此標注醫療數據作為訓練語料需要耗費大量的精力。而使用遷移學習方法將其他領域中的相關知識遷移到醫療場景中,有助于解決這一問題。
2.1 遷移學習技術在醫療文本數據預處理中的應用
醫療文本數據為非結構化數據,不利于分析研究,遷移學習技術已被用于文本信息抽取、醫療命名實體識別等研究領域,提高醫療文本預處理的效率和性能,為醫療文本數據的后續分析利用奠定良好的基礎。
Wankhade 等[17]提出一種基于二等分K 均值聚類算法的無監督遷移學習技術,用于將患者非結構化的病理化驗報告中的信息抽取出來,進而進行疾病預測。該研究首先將一些疾病名稱、結構化的疾病檢查數據,包括一些參考值范圍等,輸入到二等分K 均值算法中進行聚類;之后將學到的知識遷移到對非結構化病理化驗報告的處理中,最終可以判斷患者的疾病類型。Wang 等[18]提出了一種標簽感知的跨專業遷移學習(Label-aware Double Transfer Learning,La-DTL))命名實體識別框架,La-DTL 結合雙向長短記憶網絡和條件隨機場對源域和目標域數據進行標注,使用MMD 的改進方法——標簽感知MMD 減小兩個領域中相同標簽特征間的差距,同時使用KL 散度上限來尋找源域和目標域中可貢獻的參數。Newman 等[19]使用不同領域數據訓練得到的詞向量作為基于循環神經網絡命名實體識別模型的初始化向量值,從而進行遷移學習,結果顯示,使用聯合和預初始化[20]等遷移學習方法使模型獲得了最佳的F1 值。
2.2 遷移學習技術在基于文本的疾病診斷中的應用
基于文本數據進行疾病診斷預測模型的構建是醫療領域中的熱門研究領域。遷移學習技術在已被用于基于文本數據對白血病、輕度認知障礙、阿爾茲海默癥等疾病的診斷中。
2.2.1 遷移學習技術在白血病診斷中的應用案例
白血病是一種嚴重的血液疾病,常導致患者出現一些嚴重的癥狀甚至導致患者死亡[21]。Vogado 等[22]提出一種基于CNN 和支持向量機(Support Vector Machines,SVM)的白血病診斷系統,系統將已訓練好的CNN 如AlexNet[23]、Vgg-f[24]和CaffeNet[25]遷移到白血病診斷任務中來提取患者病歷血片中的信息,然后使用信息增益比算法來做特征選擇,最終將信息輸入到SVM 中來進行白血病的診斷,結果顯示該方法的準確率達到99%。
2.2.2 遷移學習技術在輕度認知障礙診斷中的應用案例
阿爾茲海默癥是一種老年人常患的神經系統退行性疾病,又稱為老年癡呆,早期診斷和治療可以有效地延緩阿爾茲海默癥的發生[26]。輕度認知障礙往往是阿爾茲海默癥的前驅階段[27],輕度認知障礙患者很有可能發生阿爾茲海默癥。Cheng 等[28]在2013 年利用基于特征映射的遷移學習方法將阿爾茲海默癥患者和正常參照組的信息遷移到輕度認知障礙的診斷問題上,提出一種領域遷移支持向量機算法(Domain Transfer Support Vector Machines,DTSVMs),該算法主要包含兩個部分:一是跨領域核函數遷移源域的知識,二是跨領域知識融合的適應性SVM 構建,最終該算法在測試集上的AUC 值為0.736,超過了SVMs和LapSVMs 的AUC 值,分別為0.683 和0.626。
2.2.3 遷移學習技術在阿爾茲海默癥診斷中的應用案例
Cheng 等[29]又利用基于特征選擇的遷移學習方法,將多個源域的知識遷移到阿爾茲海默癥的早期診斷問題上,提出了多領域遷移學習框架(Multi-Domain Transfer Learning,MDTL)。作者對比了MDTL 與MTFS[30],M2TFS[31]和Lasso 算法在阿爾茲海默癥診斷問題上的效果,結果顯示MDTL 的準確率可達0.947,超過了M2TFS 的0.915、MTFS 的0.907,以及Lasso 的0.879。
2.3 遷移學習技術在基于圖像的疾病診斷中的應用
醫療圖像中包含了豐富的信息,可幫助臨床醫生對就診者的健康或疾病狀況做出判斷。近年來,遷移學習技術已被用于基于圖像對乳糜瀉、青光眼等疾病的診斷中。
Wimmer 等[32]將在圖像分類數據集ImageNet 上訓練好的CNN 模型遷移到乳糜瀉的診斷上面,對比了只將CNN作為圖像特征提取器而不做微調、微調CNN 的全連接層和微調整個CNN 模型等三種模型的預測效果,結果顯示微調整個CNN 模型,使用SVM 和CNN 的SoftMax 層作為最后的分類器均能取得最佳效果。Asaoka 等[33]基于光學黃斑斷層掃描眼底圖像建立了一個青光眼早期診斷的遷移學習模型。該方法首先使用一個規模較大的眼底圖像數據集預訓練了一個CNN 模型,之后使用小型的訓練集對其進行微調,最終該模型的AUC 值達到了0.937,超過了直接使用兩個數據集訓練得到的AUC 值0.782。
2.4 遷移學習技術在基于語音的疾病診斷中的應用
通過語音進行疾病診斷目前在醫療領域中的研究較少,隨著其他領域語音分析研究的發展,也為遷移學習在醫療領域的應用提供了一個未來可關注的研究方向。
Banerjee 等[34]將深度信念網絡(Deep Belief Network,DBN)和遷移學習策略相結合,提出了一個基于語音信號的創傷后應激障礙(Post-Traumatic Stress Disorder,PTSD)診斷模型。該模型首先使用一個大型的語音識別數據庫訓練DBN 模型,再將其遷移到PTSD 的診斷任務中,結果顯示遷移學習方法可以將DBN 模型的PTSD 診斷準確率從61.53%提上到74.99%,超過目前最優的SVM 的準確率57.68%。
3 結語
遷移學習是一種可以將源域中的知識遷移到目標域任務上的機器學習方法,可以較好地適應醫療領域缺乏足夠的有標簽訓練樣本的狀況。本文按照遷移學習方式的分類,分別介紹了基于實例的遷移學習、基于特征的遷移學習、基于模型的遷移學習和基于關系的遷移學習方法及其特點,回顧了近年來的研究進展,并重點介紹了遷移學習技術在醫療領域中的應用,為后續醫療領域中遷移學習的研究提供了參考。醫療領域的數據專業性較強,目前針對醫療領域的遷移學習理論方面的研究相對缺乏,應針對醫療數據特點與擬研究問題開發更加高效的遷移學習方法,開展大規模前瞻性研究評價遷移學習在處理醫療問題中的實際效果。隨著基于神經網絡的深度學習技術的發展與應用,遷移學習和神經網絡相結合的方法已經受到越來越多的關注,其在醫療領域也將發揮越來越重要的作用。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
