云制造資源文本信息的特征提取與關聯分析方法
2020-10-10 01:02:16王珊珊高新勤魏鋒濤
制造業自動化 2020年9期
王珊珊,高新勤,張 輝,魏鋒濤
(西安理工大學 機械與精密儀器工程學院,西安 710048)
0 引言
隨著云計算、物聯網等新興技術的不斷發展,一種面向服務的網絡化制造新模式—云制造應運而生[1]。在云制造模式下,制造企業通過云平臺,形成一個覆蓋面極廣的網絡資源服務體系[2]。云制造資源是云平臺管理的主要對象,是用于產品制造全生命周期中的各種要素,包括硬資源、軟資源、計算資源和人力資源等[3]。資源提供方將這些閑置的制造資源上傳到云平臺,供資源需求方搜索選擇。由于云制造資源量大類多,具有分布性、多樣性、異構性等特點,若不對云制造資源信息進行任何預處理,會造成存儲空間龐大、查詢效率低下、與用戶期望不匹配等問題[4,5]。因此,如何對云制造資源信息進行統一化描述,已經成為云制造模式落地應用的關鍵問題[6,7]。
目前,關于云制造資源信息主要有基于語義、基于本體以及基于資源屬性的描述方法等。湯華茂等構造了制造資源的分布式語義描述模型,在信息表示的更高層次實現了制造資源粒子的虛擬化描述[8]。汪衛星將制造資源描述問題轉化為Web語義描述問題,提出了一種通用的制造資源描述框架[9]。陳友玲等針對云制造環境下資源難以統一描述、資源云池內可用資源更新滯后等問題,提出了一種顯形表達資源動態變化的層次環境視頻語義模型[10]。李孝斌等研究了元數據本體表示方法,構建了一種基于語義服務建模本體的機床裝備資源描述框架[11]。許峰等提出了一種基于云制造平臺的“框架建立—框架獲取—資源描述”三階段的資源語義描述,建立了資源服務與服務請求的本體描述模型[12]。程臻等提出了基于本體的資源描述及虛擬化方法,建立了制造資源本體模型[13]。高新勤等建立了云模式下加工設備的制造屬性描述模型,提出了基于相似度的加工設備云服務聚類方法[14]。周際鋒等以制造軟件資源為研究對象,在面向服務的構架下,建立了軟件資源屬性的描述模型[15]。耿超等將云制造資源描述模型通過映射函數轉化成文本信息處理中的形式化模型,提出了一種基于文本信息處理的云制造資源發現方法[16]。Hao等考慮了服務的演化特性,通過添加服務組合,提出了一種面向時間的可重構服務描述方法(T-TRSD)[17]。
已有研究對云制造資源信息的描述、存儲、查找等進行了探索,但大多數以字段的形式將云制造資源信息存儲于數據庫中,對以文本形式存在的云制造資源信息的描述涉及較少。實際上,以段落文本形式存在的資源信息在云制造模式中占有很大比例。本文提出一種針對云制造資源文本信息的特征提取和關聯分析方法,為實現云平臺上云制造資源的供需準確匹配提供支持。
1 特征提取和關聯分析方法
在云制造模式下,不同制造企業在共享資源、尋找服務的過程中,會產生大量紛繁復雜的信息,以段落文本存在的云制造資源描述信息就是其中之一。為了滿足用戶的使用需求,準確地對文本類資源信息進行描述,并根據存儲索引實現快速查找與匹配,云平臺服務方需要預先對上傳的云制造資源文本信息進行處理,獲取其以關鍵字為代表的關鍵特征和不同資源信息之間的共性聯系,建立關聯規則。
圖1所示為針對云制造資源文本信息提出的預處理方法,即特征提取和關聯分析方法。該方法主要包括兩大步驟,第一步是以各個云制造資源描述文本為輸入,采用TF-IDF(Term Frequency-Inverse Document Frequency,詞頻-逆向文本頻率)算法,獲取它們的關鍵字,并計算權重值。第二步是對各個云制造資源描述文本進行關聯分析,采用基于Apriori算法改進的FPgrowth(Frequent Pattern,頻繁模式)算法,對不同云制造資源描述文本之間的關聯關系進行分析,獲得關聯規則,為后續建立云制造資源文本信息的存儲索引以及實現云平臺上云制造資源的供需準確匹配奠定基礎。

圖1 云制造資源本文信息的特征提取和關聯分析方法
2 制造資源配置評價函數構造
在云制造模式下,以段落文本存在的云制造資源描述信息通常都比較冗長,如果不對其關鍵字等特征信息進行提取而隨意存儲,勢必造成存儲空間龐大且雜亂無序,影響云制造資源供需匹配的效率和準確性。本文以各個云制造資源描述文本為輸入,采用TF-IDF算法,獲取關鍵字,并計算其權重值。
TF-IDF是一種信息檢索與文本挖掘的統計方法和加權技術,用以評估一個詞條對于一個文本集或一個語料庫中的其中一份文本的重要程度[18]。詞條的重要性隨著它在文本中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。
在第j個云制造資源描述文本dj中,詞頻(Term Frequency,TF)是第i個詞條ti在描述文本dj中出現的頻率,用tfi,j表示,計算公式為:
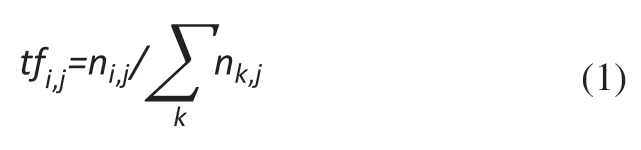
式中:ni,j為詞條ti在描述文本dj中出現的次數;∑knk,j為描述文本dj中所有詞條出現的次數總和。
逆向文本頻率(Inverse Document Frequency,IDF)是衡量詞條ti是否為常用詞的權重調整參數,表達詞條的類別區分能力,用idfi表示,計算公式為:
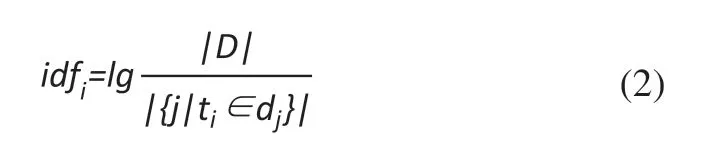
式中:|D|為一個語料庫中文本的總數;|{j|ti∈dj}|為包含詞條ti的文本數量。
如果某一云制造資源描述文本中的高頻詞條,在所有云制造資源描述文本中呈現低頻率,那么該詞條可以產生出高權重的TF-IDF。TF-IDF旨在濾除區分度低的高頻常見詞,保留區分度高的低頻詞,用tfi,j表示,計算公式為。
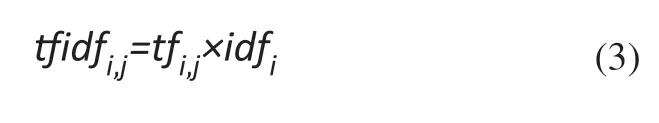
采用TF-IDF算法對云制造資源文本信息提取關鍵詞、計算權重值的流程如圖2所示。基于已知語料庫和結巴分詞工具[19],對云制造資源文本信息進行分詞處理。在此基礎上,執行TF-IDF算法,獲取云制造資源文本信息的關鍵字及權重值,主要步驟如下:
Step 1:文本預處理:利用結巴分詞工具對文本信息進行分詞;
Step 2:權重值計算:計算詞頻(tfi,j)、逆向文本頻率(idfi)以及權重值(tfidfi,j);
Step 3:提取關鍵詞:濾除常用詞,獲得有效關鍵詞;
Step 4:關鍵詞輸出:按照權重值排序,輸出關鍵字及其對應的權重值。
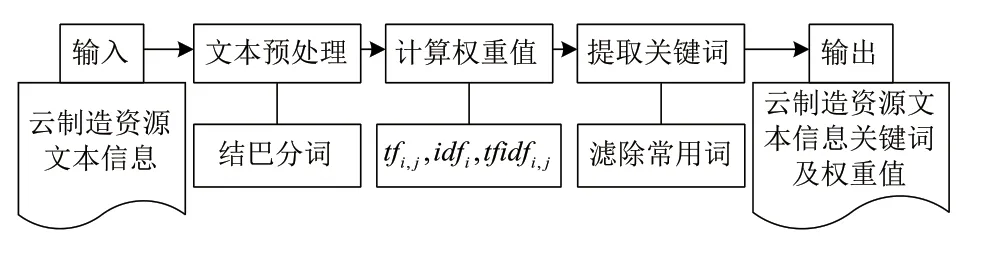
圖2 云制造資源文本信息關鍵詞獲取及權重值計算流程
3 文本信息的關聯規則構建
云模式下的制造資源由不同的制造企業提供,但它們不是孤立的,相互之間存在著千絲萬縷的關聯。分析這種關聯關系并用于建立存儲索引,對于實現云制造資源文本信息的分類存儲以及云制造資源的供需快速、準確匹配具有重要的意義。
關聯分析是一種簡單、實用的分析技術,旨在發現存在于大量數據集中的關聯性,其概念和Apriori算法率先由Agrawal等人提出[20]。Apriori算法應用頻繁項集性質的先驗知識,逐層迭代搜索,用k-項集搜索(k+1)-項集,直到不能找到更高一維頻繁項集為止。在Apriori算法的執行過程中,需要多次掃描數據集,且生成大量的候選項集,導致該算法的執行效率低下,時間和空間復雜性提高[21,22]。針對Apriori算法的缺點,Han等在2000年提出了FP-Growth(Frequent Pattern-growth)關聯分析算法[23],將提供頻繁項集的數據庫壓縮到一棵頻繁模式樹(FP-tree),但仍保留項集關聯信息。
把云制造資源文本信息的關鍵字及權重值組成的數據集,作為FP-Growth算法的輸入事務數據庫,經過兩次搜索,得到每個事務所包含的頻繁項,按其支持度降序排列后壓縮存儲到FP-tree中。在后續搜索頻繁模式的過程中,不需要再掃描事務數據庫,在FP-Tree中進行查找即可,不再產出候選模式。
根據頻繁項集產生既滿足最小支持度又滿足最小置信度的強關聯規則,置信度的計算公式為:
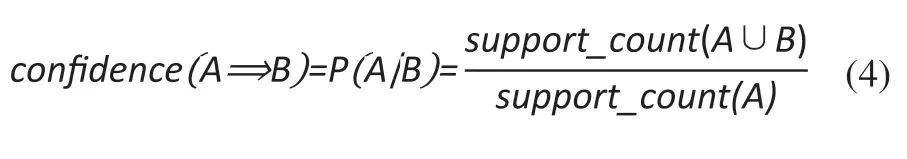
式中:support_count(A∪B)表示包含項集(A∪B)的記錄條數,support_count(A)表示包含項集A的記錄條數。
采用FP-growth算法從云制造資源文本信息中獲得頻繁項集的流程如圖3所示,主要步驟如下:
Step 1:設置最小支持度minsup;
Step 2:掃描數據庫,得到頻繁項集和每個頻繁項的支持度;
Step 3:將頻繁項集按照支持度降序排列得到頻繁項集L(刪去支持度小于minsup的頻繁項);
Step 4:對于每個頻繁項,構造它的條件投影數據庫和投影FP-tree;
Step 5:對每個新構建的FP-tree重復Step 4,直到構造的新FP-tree為空,或者只包含一條路徑;
Step 6:當構造的FP-tree為空時,其前綴即為頻繁模式;當只包含一條路徑時,通過枚舉所有可能組合并與此樹的前綴連接即可得到頻繁模式。
最后,計算云制造資源文本信息中頻繁項集所對應的置信度值,根據置信度值大小產生關聯規則。
4 實例分析
4.1 云制造資源文本信息
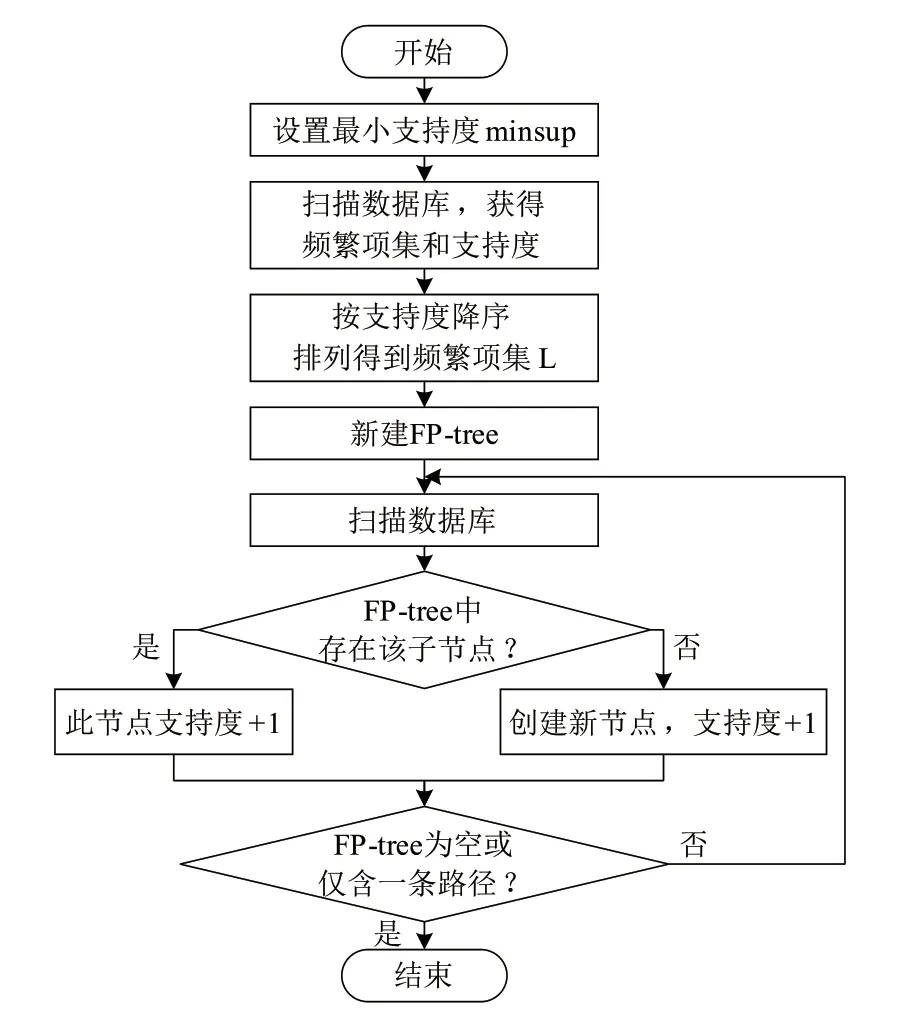
圖3 云制造資源文本信息的頻繁項集獲取流程
在云制造模式下,云制造資源的文本信息通常由資源提供方上傳到云平臺,然后由云平臺服務方對其進行特征提取和關聯分析的基礎上,按索引分類存儲后供資源需求方搜索、選擇和使用。如圖4所示,以硬制造、軟制造以及計算等三類云制造資源的文本信息為例,驗證本文所提理論和方法的可行性。其中,硬制造資源為數控加工中心、數控磨床和數控銑床,軟制造資源為AutoCAD、SolidWorks和UG,計算資源為中央處理器、輸入輸出設備和華為云。

圖4 云制造資源文本信息
4.2 獲取關鍵字及權重值
利用Eclipse軟件,基于Java語言編寫TF-IDF算法程序,以三類云制造資源文本信息為輸入,提取關鍵字,計算權重值并按大小進行排序。程序運行結果如圖5所示,三類云制造資源文本信息的關鍵字及權重值如表1、表2和表3所示。
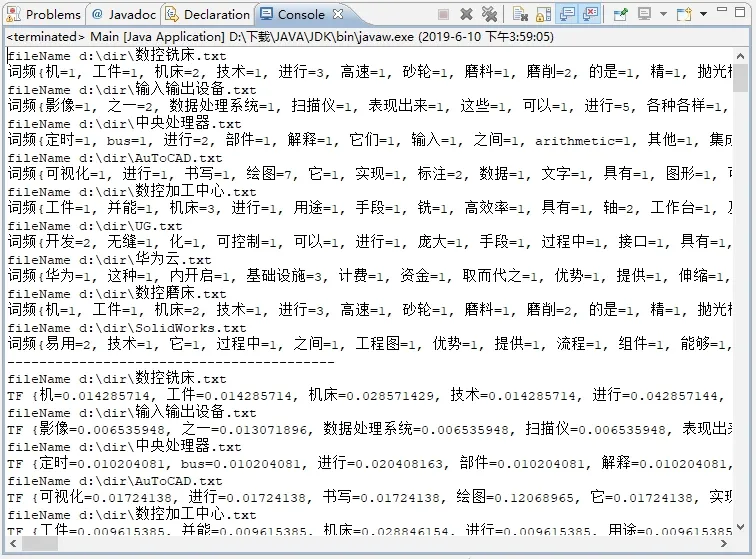
圖5 關鍵詞及權重提取結果

表1 硬制造資源文本信息的關鍵字及權重值
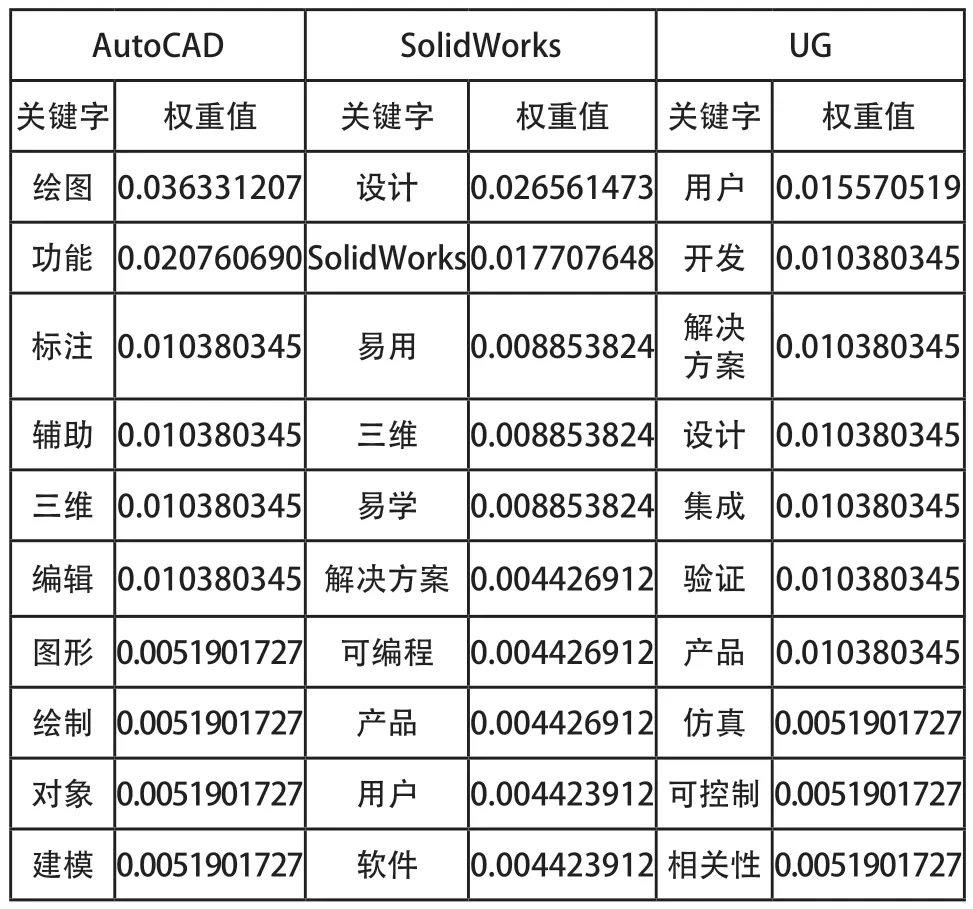
表2 軟制造資源文本信息的關鍵字及權重值

表3 計算資源文本信息的關鍵字及權重值
4.3 構建關聯規則
利用Eclipse軟件,基于Java語言編寫FP-Growth算法程序,挖掘三類云制造資源文本信息關鍵字的頻繁項集。設置最小支持度minsup=2,以硬制造資源文本信息為例,程序運行結果如圖6所示,頻繁項集以及置信度如表4所示。

圖6 硬制造資源文本信息頻繁項集獲取結果
基于計算所得的置信度對所有頻繁項集進行分析,硬制造資源組“機床-數控-加工”之間具有強關聯規則。軟制造資源組和計算資源組的強關聯規則分別是“設計-產品-解決方案-用戶”與“計算機-數據-操作”,具體過程不再贅述。云平臺服務方可根據關聯規則分類存儲云制造資源文本信息,資源需求方可按照關鍵字搜索、選擇和使用云制造資源。
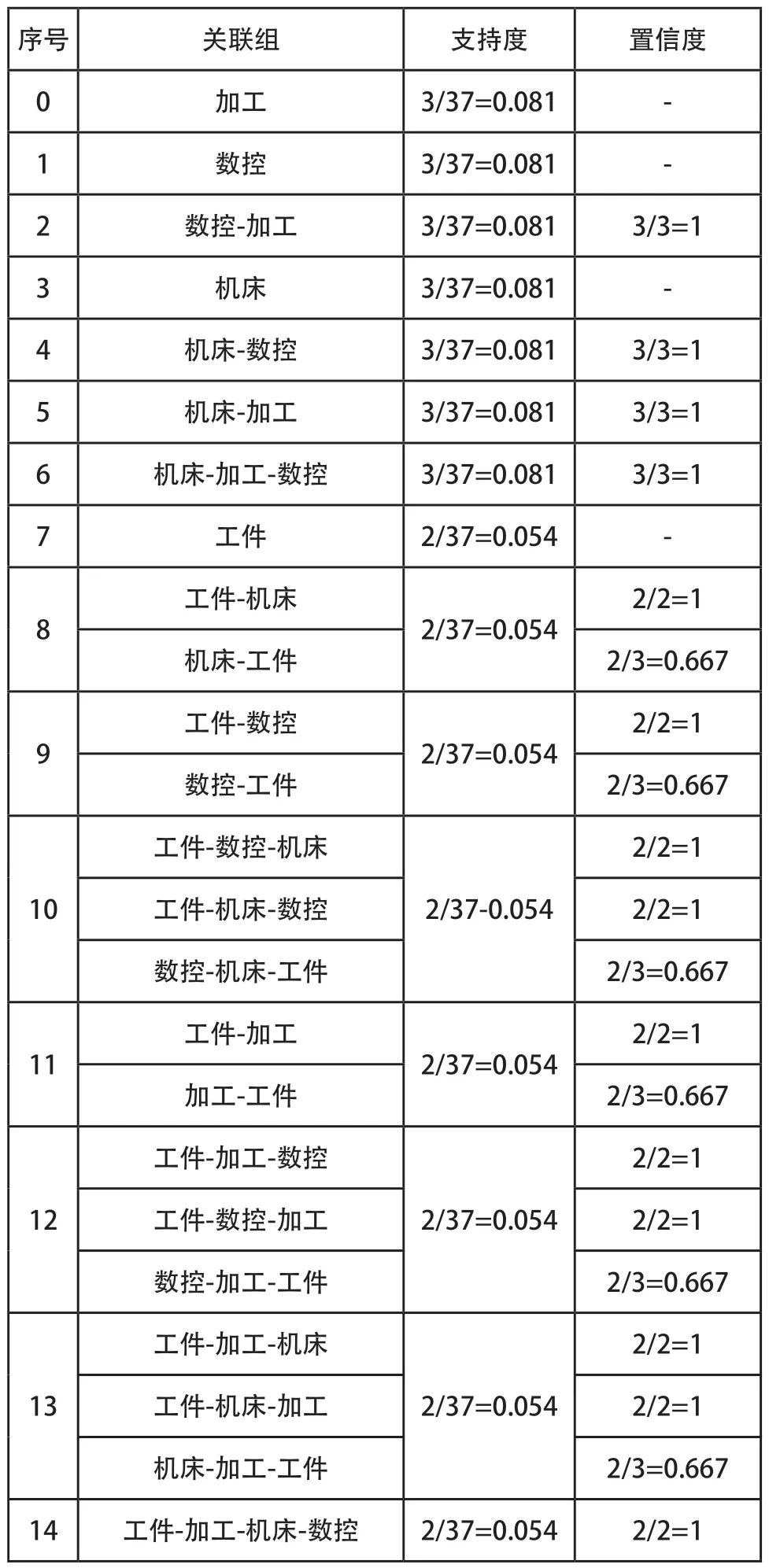
表4 硬制造資源文本信息的關聯規則
5 結語
隨著先進制造技術與信息技術的深度融合,云制造成為了智能制造發展的新模式。在云制造模式下,存在著大量的云制造資源信息,對它們進行統一化描述,直接關系到云制造資源的存儲與匹配,是云制造模式落地應用的關鍵所在。本文針對以文本形式存在的云制造資源信息,提出了一種特征提取和關聯分析方法。對云制造資源的文本信息執行TF-IDF算法和FP-Growth算法,獲得關鍵字及其權重值,在頻繁項集挖掘與置信度分析的基礎上構建了云制造資源文本信息的關聯規則,最后通過實例驗證了本文所提理論和方法的可行性。隨著云制造資源文本信息的增多,關聯規則將得到不斷豐富。本研究為云制造資源的分類存儲、按關鍵字快速匹配提供了有力支持,后續將進一步完善權重值的計算方法,確保云制造資源文本信息的特征提取與關聯分析更加高效。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
當代陜西(2021年17期)2021-11-06 03:21:36
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
制造技術與機床(2019年10期)2019-10-26 02:48:08
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
電子制作(2018年18期)2018-11-14 01:48:06
學苑創造·A版(2018年11期)2018-02-01 06:29:20
資源再生(2017年3期)2017-06-01 12:20:59
讀者(2017年5期)2017-02-15 18:04:18
小學教學參考(2015年20期)2016-01-15 08:44:38
