多人會話混合語音的說話人分割?
2020-10-09 02:47:20李艷妮張二華
計算機與數字工程 2020年7期
關鍵詞:檢測
李艷妮 張二華
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
在多人會話場景下,如會議錄音、采訪錄音、新聞廣播等,如何利用說話人信息自動管理海量混合語音是一個重要的科研問題。多人會話意味著多人交替會話,不涉及兩人或多人同時說話的情況,而說話人分割是指在多人會話混合語音中找到不同說話人語音的切換點,再將混合語音分割成若干語音段(含無聲段),使每段語音只屬于同一個說話人[1]。說話人分割是近年來語音信號處理領域的研究熱點之一,可以用于自適應語音識別、多說話人識別和說話人跟蹤等任務的前端處理[2]。
目前,常用的說話人分割算法分為基于距離的算法和基于模型的算法[3]。基于距離的說話人分割有兩種主流的算法,第一種算法是變窗長切換點檢測法,其窗長的改變是通過判斷貝葉斯信息判決(Bayesian Information Criterion,BIC)距離是否超過固定閾值[4]。第二種算法是固定窗長法,通過固定窗長以及滑動窗口計算BIC 距離曲線,依據曲線的局部極值進行說話人分割[5]。這兩種主流的算法都需要經驗知識來選擇窗長大小和分割閾值。
基于模型的算法則是利用語音庫訓練得到說話人模型,利用模型匹配說話人來找到不同說話人語音的切換點,從而進行說話人分割[6]。近年來還有許多研究者利用深度神經網絡提取混合語音中說話人的碼本信息進行說話人分割[7~8],但訓練多層深度神經網絡結構需要大量的數據、較長的訓練時間且計算量較大。
在真實場景的多人交替說話環境中,說話人的語音段可能很短,且目前針對短語音(小于3s)說話人分割的研究甚少,因此沒有相應的經驗知識來確定窗長大小和分割閾值。在多人會話場景中,說話人所在的搜索范圍一般是可以確定的,雖然無法獲取較長時間的單人語音,但獲取他們短時長的單人語音用來訓練模型是可行的。比如,在10 人規模的會議中,真實發音的說話人的身份和數目都是未知的,但參加會議的這10 人的身份是已知的,且他們短時長的單人語音是可獲取的。針對短語音條件下的多人會話場景,本文研究了一種基于高斯混合模型(Gaussian Mixture Model,GMM)和多尺度分析的說話人分割算法,在提高短語音說話人識別率的基礎上,以混合語音中連續的有聲段為線索,基于多尺度分析進行說話人分割,并通過分幀概率優化說話人分割效果。
2 短語音說話人識別
2.1 模型特征參數提取
2.1.1 說話人特征參數提取
梅爾頻率倒譜系數(Mel-Frequency Cepstral Coefficients,MFCC)模擬了人耳對語音信號的感知特性,是說話人識別系統中最常用的特征參數。MFCC是在Mel標度的頻率域上利用濾波器組提取出來的倒譜系數,但頻域特征只考慮了語音幀內的信息,而語音信號本身具有時變性,說話人特征幾乎不會停留在某一個固定值上,將會在一定范圍內波動。這一波動規律作為一種動態特征也反映了該說話人的個性特征。
因此,本文選取MFCC 及它的一階差分特征MFCC_D 作為模型訓練時所需的特征參數。其中,一階差分特征MFCC_D計算公式如下:
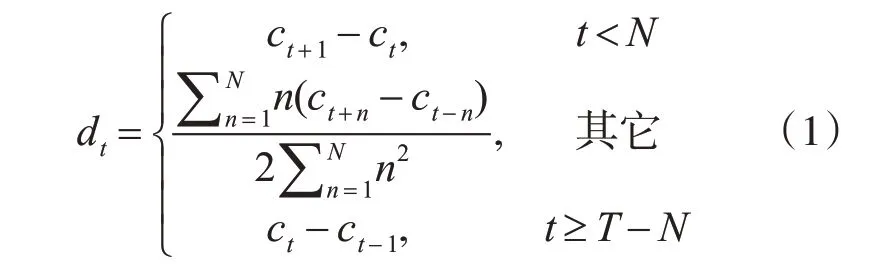
其中,ct表示第t 幀的MFCC,dt表示第t 幀的一階差分特征MFCC_D,T 表示MFCC 的總幀數,N 為一階導數的時間差,本文取2,1≤n≤N 。若將式(1)的結果再代入式(1)就可以得到二階差分參數[9]。
2.1.2 歸一化
對特征參數進行歸一化可以使數據的動態范圍接近一致,同時保持它們相對大小關系不變。此外,歸一化可以提高模型的收斂速度和精度。本文中,提取特征參數后,對它們進行min-max標準化,使其映射到[0,1]區間內,其轉換函數如式(2)所示:
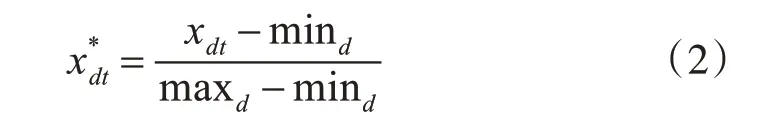
其中,xdt表示第d 維第t幀的特征參數表示其歸一化后的值,mind表示所有訓練語音幀中第d維特征參數的最小值,maxd表示所有訓練語音幀中第d維的最大值。
2.2 端點檢測
多人交替說話時,不同說話人的語音之間一般有停頓,因此一段連續的語音一般屬于同一個說話人。端點檢測可以檢測出語音信號中有聲段的起止位置,避免說話人分割時將一段連續的有聲段切分開,再通過“分段”將原始語音分成交替的有聲段和無聲段,避免低魯棒性的無聲段影響說話人識別率。
語音信號的兩個重要時域特征為:短時能量和短時過零率。傳統的雙門限端點檢測法依據這兩個特征,通過三個閾值:高能量閾值EH、低能量閾值EL和短時平均過零率閾值ZH進行有聲段判決。在實際應用中發現,在輔音段與元音段之間可能存在輔音逐漸減弱的現象,即輔音段開始較強,然后變弱,再過渡到元音段。對這種復雜的情況,傳統的雙門限端點檢測方法的性能受到明顯影響。2017 年王滿洪等[10]提出了一種適用于低信噪比環境的多閾值端點檢測。
2.2.1 多閾值端點檢測
相較于傳統的雙門限端點檢測法,多閾值端點檢測增加了輔音能量閾值EC和疑似輔音閾值ES,其有聲段判斷方法如表1所示。

表1 多閾值端點檢測有聲段判斷方法
其中,Z 為短時過零率;ZH為短時平均過零率閾值;E 為短時能量;EH為高能量閾值;EL為低能量閾值;EC為輔音能量閾值;ES為疑似輔音閾值。
若輔音逐漸減弱,傳統的雙門限端點檢測法會把這樣的輔音段與后面的元音段檢測為兩段。然而,在漢語里,輔音只有和元音在一起才能組成一個完整的音節,即輔音不能單獨存在,多閾值端點檢測會將這樣的輔音段和后面緊接著的元音段合并成一段。
2.2.2 分格
當多人交替說話時,一個人說話的最短語音為一個字。據統計,漢語的正常語速范圍為200~300字/分鐘[11],每個字平均0.2s~0.3s,所以本文最小可識別的語音時長選取0.25s,在語速較快時,該最小時長能包含一個漢字的語音段,當語速較慢時,由多個最小時長組成的較大時長也能包含一個漢字的語音段。
本文中說話人識別和多尺度分析都是以連續有聲段為線索,段內分格,同時為每格賦予段標記。將屬于同一連續有聲段的語音格賦予同一個段標記。連續有聲段的中間部分為穩定的語音段,而左右端點處通常為不穩定的過渡段,其語音特征變化較快,因此需要加強左右端點處語音片段的長度來提高識別的魯棒性。
分格時,最小可識別語音時長定為0.25s。假設某連續有聲段時長為xs,則該段對應的語音格數y為
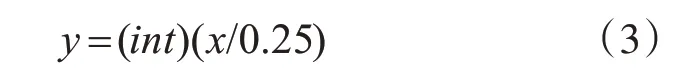
對中間的y-2 格,每格時長為0.25s,起止端兩個語音格的時長b如式(4)所示:
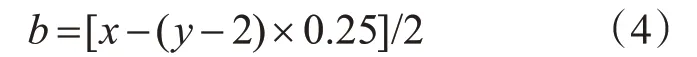
連續語音段內分格時,若某有聲段時長不夠2格,則只分為1格,如表2中第0格所示,時長0.46s;若某段時長不夠3格,則只分為2格,如表2中第1~2 格所示,總時長為0.74s,每格0.37s;若某段時長不夠4格,則只分為3格,如表2中第3~5格所示,總時長0.93s,中間格為0.25s,起止端兩格為0.34s。

表2 分格實例
2.3 說話人識別的GMM方法
在提取特征參數之后,說話人識別還需應用GMM 模型進行訓練和匹配判決。一個高斯混合模型就是多個高維概率密度函數的加權和,其階數是高維概率密度函數的個數,其維數是特征參數的個數。GMM 模型訓練就是對訓練樣本進行參數估計,常采用最大似然估計(Expectation Maximization,EM)來求解。GMM匹配判決的過程就是求說話人集合中每個說話人的特征參數在已訓練的模型中的后驗概率,其中最大后驗概率對應的說話人就是識別結果[12]。
3 說話人分割
3.1 多尺度掃描
分割前,某說話人發言的時長與起止時間點都未知,可用多尺度分析的方法對混合語音的時長和位置分別進行掃描,其中時長對應尺度,位置對應平移量。時窗內只包含一個說話人的信號時,該時窗最匹配的說話人的后驗概率最大,時窗中若摻雜了其他說話人的信號,則最匹配的說話人的后驗概率會下降。
3.1.1 時長劃分
進行多尺度掃描時,掃描的時長對應語音格的時長,對不同尺度層,語音格的時長是不同的,給每個尺度層的語音格設置一個標準時長,尺度從小到大,語音格標準時長依次為0.25s、0.5s、0.75s……,分別稱為第0 尺度層、第1 尺度層、第2 尺度層……,如第0 尺度層的每1 格對應的標準時長為0.25s。
3.1.2 平移量劃分
進行多尺度掃描時,在每一尺度層,平移量都為第0尺度層的1格,相鄰兩格之間有重合,重合量與尺度有關,尺度越大,重合量越多。
第0 尺度層,相鄰兩格之間無重合。第1 尺度層是第0 尺度層的每2 格合并而成,相鄰兩格間重合量為第0 尺度層的1 格。第2 尺度層是第0 尺度層的每3 格合并而成,相鄰兩格間重合量為第0 尺度層的2格。以此類推……
前3個尺度層對第0~2格進行多尺度掃描的示意圖如圖1所示。
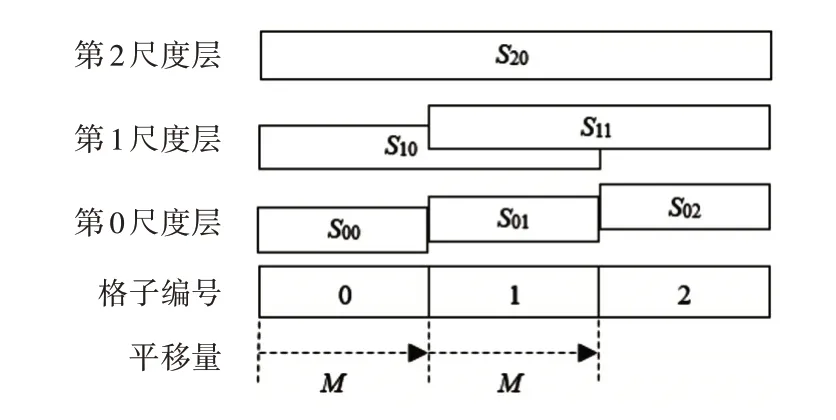
圖1 多尺度掃描示意圖
其中,Sij(i=0,1,2,…,h-1,j=0,1,2,…,m-1;h 為尺度層總數,m 為該尺度層的語音格總數)表示第i 尺度層的第j 格,如S10表示第1 尺度層第0格。從圖1 可以看出,同一尺度層相鄰的格子與它們相鄰尺度層的格子可以組成一個金字塔,如S00、S01和S10可以組成一個兩層金字塔,而S00、S01、S02、S10、S11和S20可以組成一個三層金字塔。
3.2 段內分裂與段間合并
多尺度分析中有兩個重要判斷準則:段內分裂和段間合并。在多人會話時,某些說話人切換點可能不明顯,比如兩個或多個說話人無時間間隔連續交替發音[13]。這種情況下,端點檢測時會將它們作為一個連續的語音段,該段包含了兩個或多個說話人,而段內分裂可以通過多尺度分析將該段分裂成兩個或多個說話人,在第0 尺度層標記為不同的說話人。段間合并是指多尺度分析之后,若相鄰兩個或多個有聲段的說話人標記相同,則將它們合并。
3.3 多尺度分析
多尺度分析是從小到大的識別,以及從大到小的回溯。從小尺度逐層向上合并成大尺度,再從大尺度逐層向下糾正小尺度的誤判。多尺度分析時,根據有聲段在第0 尺度層對應的語音格數,運用不同的規則:一是針對有聲段對應多個語音格的高層規則;另一個是針對有聲段只對應一個語音格的金字塔規則。
3.3.1 高層規則
已有研究表明,訓練時長一定時,測試時長越長,識別率越高,所以對于在第0 尺度層占有多格的有聲段而言,其最大尺度層的識別結果最為可靠,因為最大尺度層包含了此有聲段的總長。
高層規則是指:以有聲段對應的最大尺度層的識別結果為主,再用各次級尺度層的識別結果進行進一步確認,回溯的同時進行糾錯。但是,高層規則向下回溯時,若某段被賦予多個說話人標記,則需要進行段內分裂。
3.3.2 金字塔規則
通常說話人連續發音時,句子或詞語之間會有短暫的停頓,此時端點檢測可能把這種發音分成幾段,某些段時長可能不足0.5s,在第0尺度層只占用1格,稱為孤立格,對應的最大尺度層就是第0尺度層,所以需要利用有別于高層規則的金字塔規則來進行綜合分析。
金字塔規則為:通過比較孤立格的時長及和它有關語音格的說話人標記,來判斷該孤立格應該保留原始說話人標記還是應該被調整、糾正。若孤立格時長小于0.167s,即小于最小可識別語音時長的2/3時,該格不能被單獨分割,需要被糾正。若孤立格不在混合語音的起始格和結尾格,如圖1 中的S01,與該格有關的語音格為它左右兩側的兩個語音格S00和S02,以及第1 尺度層包含它的兩個語音格S10和S11。用金字塔規則分析孤立格S01的過程如圖2所示。
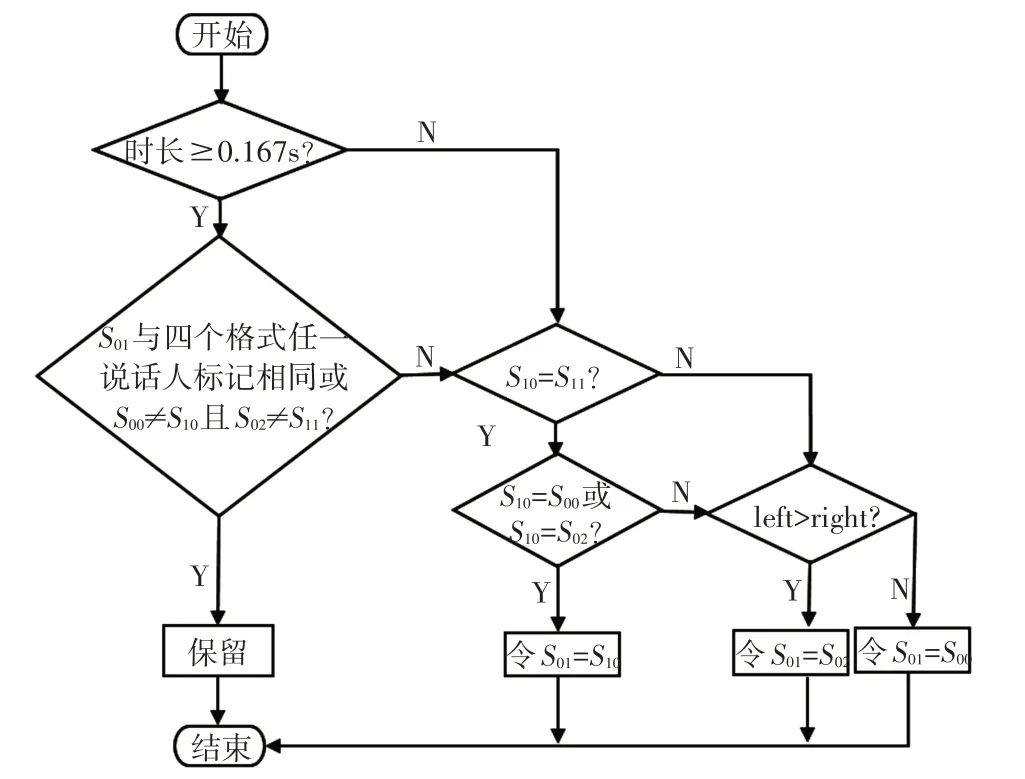
圖2 金字塔規則
其中,“=”表示說話人標記相同;“≠”表示說話人標記不同;left為S01與S00語音格之間無聲段的時長;right為S01與S02語音格之間無聲段的時長。
3.4 分割
多尺度分析后,若相鄰有聲段的說話人標記相同,則進行段間合并,從而得到說話人連續發言的起止點;若相鄰有聲段的說話人標記不同,則將相鄰有聲段之間的無聲段均分后分配給這兩個說話人,均分點就是該混合語音段的說話人切換點。最后根據所有的說話人切換點,將混合語音分割成若干語音段,每段語音只包含一個說話人。
3.5 分幀概率優化分割效果
若兩個說話人的發音間隔太短,會被端點檢測作為一個連續的有聲段。段內分裂可以將該段以語音格為單位分裂為兩個說話人,每格只標記為一個說話人,但若兩個說話人語音的切換點在某格內部,單靠多尺度分析的段內分裂無法找到準確的切換點。因為一個語音格包含多個語音幀,所以本文用分幀概率來優化分割效果,從而提高說話人分割正確率。分幀概率是用語音信號中每幀的特征參數,進行模型匹配得到的后驗概率,其最大后驗概率對應的是該幀最可能的說話人。
假設經過段內分裂后,段內編號為a、a+1、a+2和a+3的語音格標記的說話人編號依次為P1、P1、P2和P2,那么在該混合語音段,P1先于P2發言,且說話人切換點極大概率在a+1 和a+2 兩格所在的混合語音段內,但不排除說話人切換點在a 或a+3 語音格內的可能性。對這四個語音格包含的所有語音幀分別求說話人P1和P2的分幀概率,比較后可以發現,從某幀f開始,P2的分幀概率始終高于P1的分幀概率,由此可知,該幀f 的起點便是P1和P2之間的說話人切換點。
3.6 端點檢測與多尺度分析綜合使用
在多人會話混合語音的說話人分割中,端點檢測和多尺度分析必須綜合使用,缺一不可。根據端點檢測的結果,可將某有聲段單獨標記為說話人Pm,而標記說話人可能有誤,所以該段與相鄰的、標記為說話人Pn的有聲段是否屬于同一說話人,需要用多尺度分析來判斷。當某些說話人切換點不明顯時,端點檢測時會將它們分為一段,此時該段包含多個說話人,同樣需要用多尺度分析來區分這些說話人。而假設只進行多尺度分析,某些小尺度層的識別錯誤就難以糾正,但是可以根據端點檢測分格時賦予的段標記,找到該有聲段對應的最大尺度層,以最大尺度層的識別結果作為參考來糾正。
4 實驗
4.1 實驗語音庫
本文實驗數據來自南京理工大學NJUST603語音庫,該庫含有213 個女生和210 個男生,共423 人的語音。每人有三段數字錄音(N1,N2,N3),四段文本錄音(T1,T2,T3,T4),且同時采用了麥克風、固定電話和手機信道分別錄音。
本文中,語音采樣頻率為16000Hz,采樣精度為16 位,幀長為512 個采樣點(32ms),幀移為256個采樣點(16ms)。
4.2 短語音說話人識別
4.2.1 實驗數據
在NJUST603 語音庫中,隨機挑選50 個男生和50 個女生做短語音說話人識別實驗。因為多人會話場景使用麥克風較多,所以選擇麥克風信道。首先用這100 人的T4文本語音訓練模型,然后用他們的T3文本語音進行測試。按照NIST 的標準,若訓練語音和測試語音的時長都不大于10s,則為短語音說話人識別[14]。所以識別實驗的訓練時長設為10s和3s,測試時長設為5s、3s、2s、1s和0.5s。
4.2.2 評價標準
短語音說話人識別評價指標為識別率,計算公式為
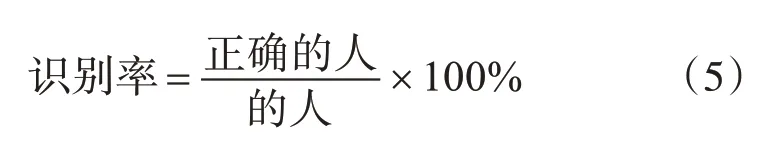
4.2.3 說話人識別實驗結果
本文的特征參數為24 維MFCC 及24 維一階差分特征參數MFCC_D,共48 維,階數為32。共做了2 組短語音說話人識別對比實驗:歸一化對識別率的影響;不同端點檢測方法對說話人識別率的影響。
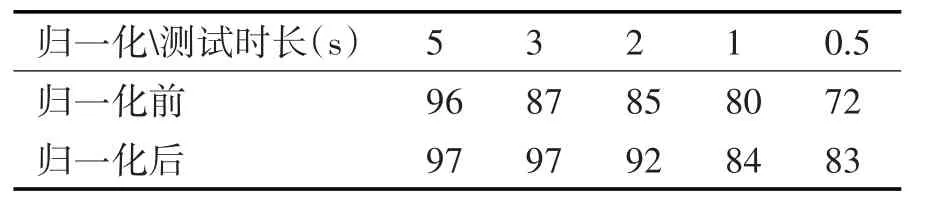
表3 訓練時長為10s時歸一化對識別率的影響(%)
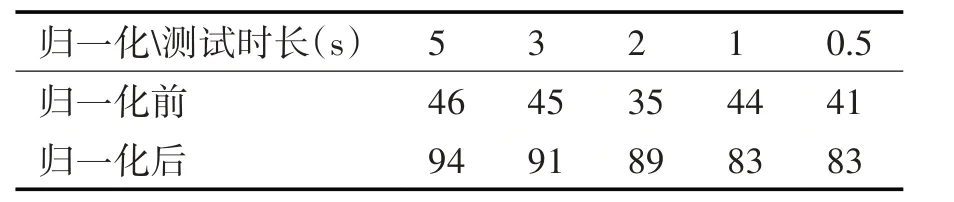
表4 訓練時長為3s時歸一化對識別率的影響(%)
從表3 和表4 可看出,歸一化可以提高說話人識別率,尤其對短訓練時長和短測試時長的識別率有明顯提高,所以在后續的端點檢測對比實驗中,在提取特征參數時對其進行歸一化。
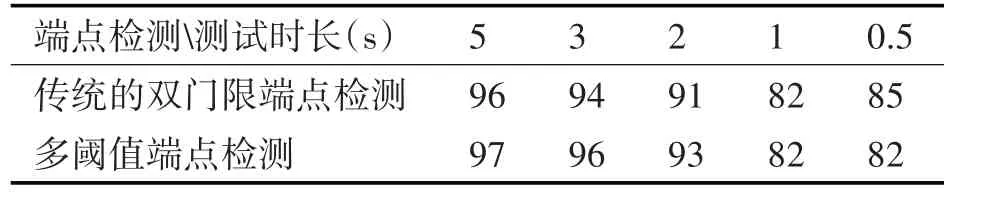
表5 訓練時長為10s時端點檢測方法對說話人識別率的影響(%)
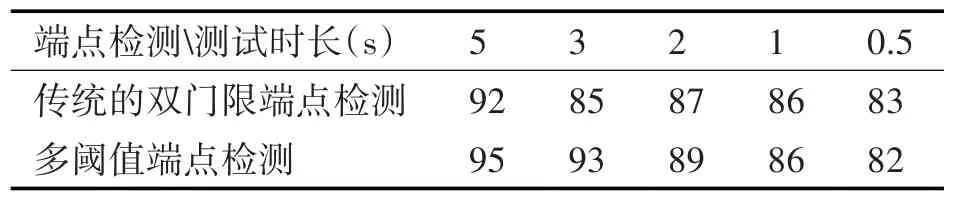
表6 訓練時長為3s時端點檢測方法對說話人識別率的影響(%)
從表5 和表6 的實驗結果可以看出,對于麥克風信道的短語音說話人識別,多閾值端點檢測后說話人識別率明顯高于傳統雙門限端點檢測。
4.3 多人會話混合語音的說話人分割
4.3.1 實驗數據
因為NJUST603 語音庫只有單人語音,為了模擬真實的多人對話場景,人工拼接成待分割的混合語音,又因為真實對話在說話人轉換時有一段停頓時間,所以拼接的語音段之間包含無聲段。
在語音庫中隨機選取40 個男生和40 個女生,分成兩組10人說話人庫A 和B,說話人標記范圍為1~10,和兩組30 人說話人庫C 和D,說話人標記范圍為1~30。四組說話人庫內的說話人無交叉、重疊,且男女比例均衡。每段混合語音的總時長都為60s,包含35到40個單人語音段,含4到8個不同的說話人,每段語音時長滿足0.5s≤time≤3s。
訓練語音為說話人庫內單人的T4語音文件,測試語音為T3語音文件。訓練時長為10s,特征參數為24 維MFCC 及24 維一階差分特征參數MFCC_D,階數為32,在提取特征參數時對其進行歸一化,并對輸入信號進行多閾值端點檢測。
4.3.2 評價指標
說話人分割的評價指標為說話人正確率(Speaker Accuracy Rate,SPKA),即正確分割的語音時長占混合語音總時長的比值,計算公式為
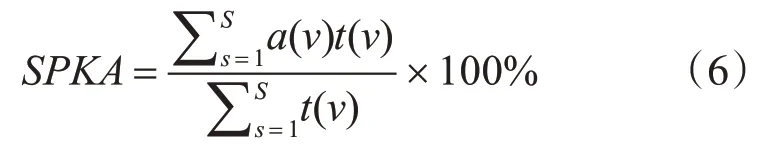
其中,S 是實際結果中說話人切換點和測試結果中說話人切換點對整個混合語音進行切分獲得的總語音段個數,a(v)表示語音段v 是否分割正確(若分割正確,a(v)=1,否則a(v)=0),t(v)是語音段v的時長[15]。
4.3.3 說話人分割實驗結果
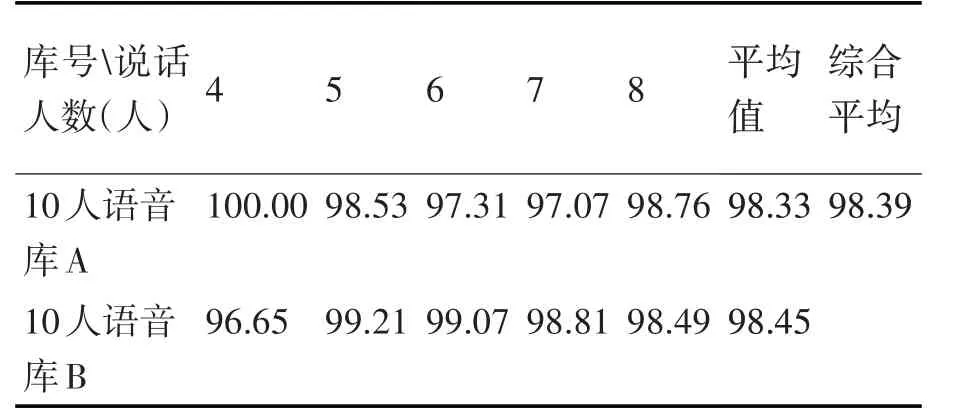
表7 10人說話人庫的SPKA(%)

表8 30人說話人庫的SPKA(%)
從表7 和表8 可以看出,10s 訓練時,基于多尺度分析的說話人分割的SPKA 可以達到97%以上,且與混合語音中包含的說話人數無關,但與說話人庫的規模有關,規模越大,SPKA越低。
部分說話人分割圖如圖3和圖4所示。
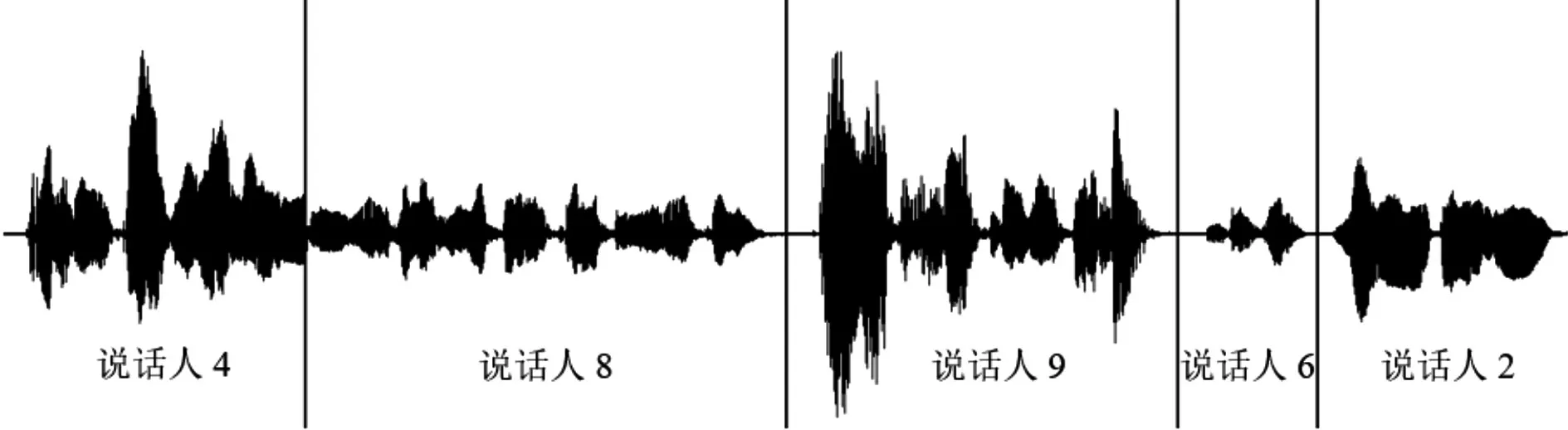
圖3 10人語音庫中某混合語音的分割圖
其中,豎線所在的時間點對應說話人切換點;豎線兩側的標記對應說話人編號。從圖3和圖4可看出,本文的說話人分割算法可以有效地分割短語音條件下的混合語音,并且從圖3 可知,即使多個說話人無時間間隔連續交替發音,本文算法也可以較正確地找到他們之間的說話人切換點。
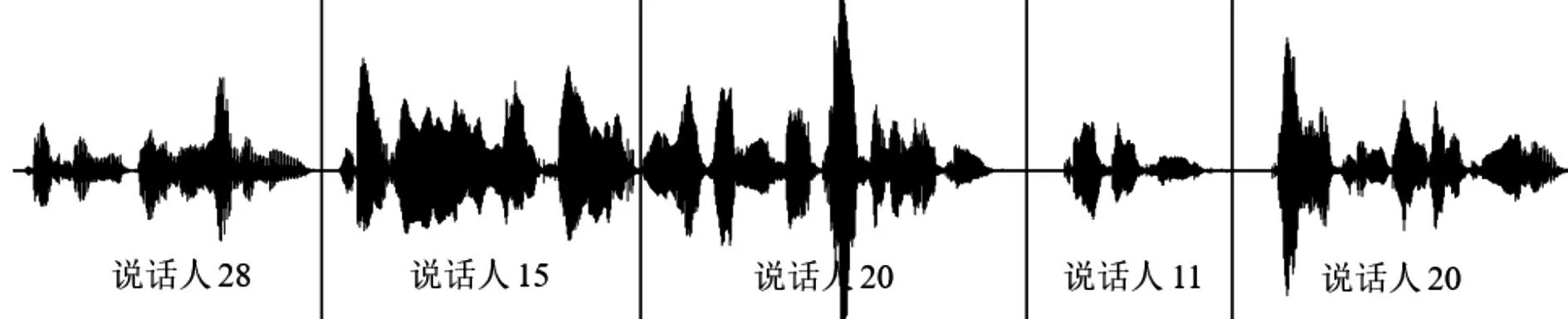
圖4 30人語音庫中某混合語音的分割圖
5 結語
在基于GMM 的短語音說話人識別中,基于MFCC 和MFCC_D 的特征參數組合,將特征參數歸一化有利于提高說話人識別率,而且多閾值端點檢測比傳統的雙門限的識別率更高。
本文在提高短語音說話人識別率的基礎上,綜合使用端點檢測和多尺度分析來實現說話人分割,并引入分幀概率來解決段內分裂時說話人切換點不精準的問題。實驗結果表明,本文提出的基于高斯混合模型和多尺度分析的說話人分割算法可以有效并較正確地分割短語音條件下的多人會話混合語音,而且,說話人正確率SPKA 與混合語音中包含的說話人數無關,但與說話人庫的規模有關,規模越大,SPKA越低。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
