基于YOLOv3目標(biāo)檢測的秧苗列中心線提取方法
2020-08-27 08:22:40王家輝
農(nóng)業(yè)機械學(xué)報 2020年8期
張 勤 王家輝 李 彬
(1.華南理工大學(xué)機械與汽車工程學(xué)院, 廣州 510641; 2.華南理工大學(xué)自動化科學(xué)與工程學(xué)院, 廣州 510641)
0 引言
在復(fù)雜的農(nóng)田環(huán)境中,實時、準(zhǔn)確提取機器人的導(dǎo)航線是實現(xiàn)機器人自主導(dǎo)航的重要保證[1-4]。由于作物個體差異、作物生長變化、葉片相互遮擋、光照不確定性等因素,經(jīng)常導(dǎo)致圖像中存在噪聲和干擾,降低作物列中心線檢測的準(zhǔn)確率。在水田環(huán)境下,還經(jīng)常會伴有大風(fēng)、藍(lán)藻、浮萍、秧苗倒影、水面反射、光照不均等環(huán)境因素的干擾,這些進(jìn)一步增大了圖像處理的難度,使水田秧苗列中心線的實時檢測更為復(fù)雜,從而嚴(yán)重影響水田除草機器人自主導(dǎo)航的精度和效率。
為了解決這些問題,國內(nèi)外學(xué)者做了大量研究工作,并取得了一定的成果。針對農(nóng)田環(huán)境下自然光照變化對作物列中心線提取的影響,文獻(xiàn)[5-7]選用不同的彩色模型,通過提取作物的顏色特征,有效地降低了光照變化對農(nóng)作物圖像分割的影響。考慮作物生長過程中形態(tài)變化造成的影響,文獻(xiàn)[8]通過8鄰域結(jié)構(gòu)因子,對二值化后作物圖像中的斑塊噪聲進(jìn)行標(biāo)記,剔除了作物由于生長變化形成的葉子尖端大面積噪聲;文獻(xiàn)[9]利用水稻秧苗的形態(tài)特征識別秧苗列的中心線,該方法對不同生長周期的秧苗具有較好的識別效果,解決了秧苗生長過程中葉片交叉遮擋問題;文獻(xiàn)[10]提出一種改進(jìn)遺傳算法的作物行識別方式,從圖像的頂部和底部隨機選擇2個點組成的直線編碼為染色體,通過多次遺傳進(jìn)化,選擇適應(yīng)度最高的染色體作為作物的中心線,較好地提取到不同生長階段的作物列中心線;文獻(xiàn)[11]提出一種作物特征點提取方法,將作物圖像分割成不同高度的12個子帶,設(shè)置與子帶等高度的窗口,對二值化后的白色作物像素進(jìn)行跟蹤,并求窗口內(nèi)作物像素質(zhì)心點,即為擬合作物線的特征點,該方法提取的特征點能較好地表征不同生長階段的作物中心位置。在減小環(huán)境噪聲的影響方面,文獻(xiàn)[12]通過匹配水田中作物的紅外圖像和R分量圖像,對其進(jìn)行相減和二值化處理,減小了水面反射噪聲對作物列中心線檢測的干擾;文獻(xiàn)[13]通過對農(nóng)田圖像灰度化,再利用小面積法進(jìn)行圖像濾波,去除了農(nóng)田中土塊等引起的顆粒狀噪聲;文獻(xiàn)[14]采用雙閾值的Otsu方法進(jìn)行圖像分割,成功剔除了作物田間的雜草噪聲。
目前,針對南方復(fù)雜惡劣水田環(huán)境下的秧苗中心線提取,國內(nèi)外相關(guān)研究文獻(xiàn)很少。為了解決這個問題,文獻(xiàn)[15-17]提出基于彩色模型和近鄰法聚類的水田秧苗列中心線檢測方法、基于SUSAN角點的秧苗列中心線提取算法,這些方法在圖像中存在浮萍、藍(lán)藻和秧苗倒影的情況下具有較高的魯棒性,能夠滿足視覺導(dǎo)航的實時性要求,但對環(huán)境變化的適用性還有待進(jìn)一步研究。
近年來,深度學(xué)習(xí)在農(nóng)業(yè)領(lǐng)域的應(yīng)用日益廣泛,深度學(xué)習(xí)方法具有檢測精度高、適應(yīng)性強的特點[18-19]。基于深度學(xué)習(xí)的方法主要分為兩類:一類是通過提取候選區(qū)域,并對區(qū)域進(jìn)行以深度學(xué)習(xí)為主的分類方案,稱為two-stage(兩階段)檢測算法,典型的如RCNN[20]、Fast RCNN[21]、Faster RCNN[22]等。另一類則是基于回歸的方法,直接通過單個卷積深度神經(jīng)網(wǎng)絡(luò)遍歷圖像,回歸出目標(biāo)的類別和位置,稱為one-stage(一階段)檢測算法,典型算法如YOLO[23]、YOLOv2[24]、YOLOv3[25]、SSD[26]。相對于two-stage檢測算法, one-stage檢測算法檢測速度更快,YOLOv3深度神經(jīng)網(wǎng)絡(luò)還通過借鑒殘差網(wǎng)絡(luò)結(jié)構(gòu)(ResNet)[27]和SSD中的多尺度預(yù)測,提升了模型的表現(xiàn),在保證一定模型精度的同時,提升了檢測速度。
本文提出基于YOLOv3目標(biāo)檢測的秧苗列中心線提取方法,采用YOLOv3模型對視頻中感興趣區(qū)域(Region of interest,ROI)內(nèi)的秧苗進(jìn)行識別定位,輸出秧苗的檢測框,然后在檢測框區(qū)域內(nèi)進(jìn)行秧苗的特征提取和中心線的擬合。
1 材料與方法
1.1 算法概述
基于YOLOv3檢測框區(qū)域的水田秧苗列中心線提取算法主要分為目標(biāo)檢測定位和中心線提取兩部分,整體流程如圖1所示。
(1)YOLOv3目標(biāo)檢測:首先對于采集到的水田秧苗RGB圖像,根據(jù)攝像頭俯仰角與秧苗成像關(guān)系分析,構(gòu)建圖像中的ROI,然后對ROI區(qū)域內(nèi)的秧苗進(jìn)行分段標(biāo)注后,構(gòu)建YOLOv3的訓(xùn)練數(shù)據(jù)集,尋找訓(xùn)練結(jié)束后最優(yōu)的YOLOv3檢測模型,利用模型定位秧苗并輸出其檢測框。
(2)基于同列秧苗檢測框區(qū)域內(nèi)的秧苗列中心線提取:對YOLOv3模型檢測并輸出的同列秧苗檢測框進(jìn)行自適應(yīng)聚類;再基于歸一化的ExG(Excess green index)算子進(jìn)行圖像分割;在同類檢測框區(qū)域內(nèi)進(jìn)行秧苗SUSAN角點的提取,最后利用最小二乘法對秧苗特征點進(jìn)行中心線擬合。
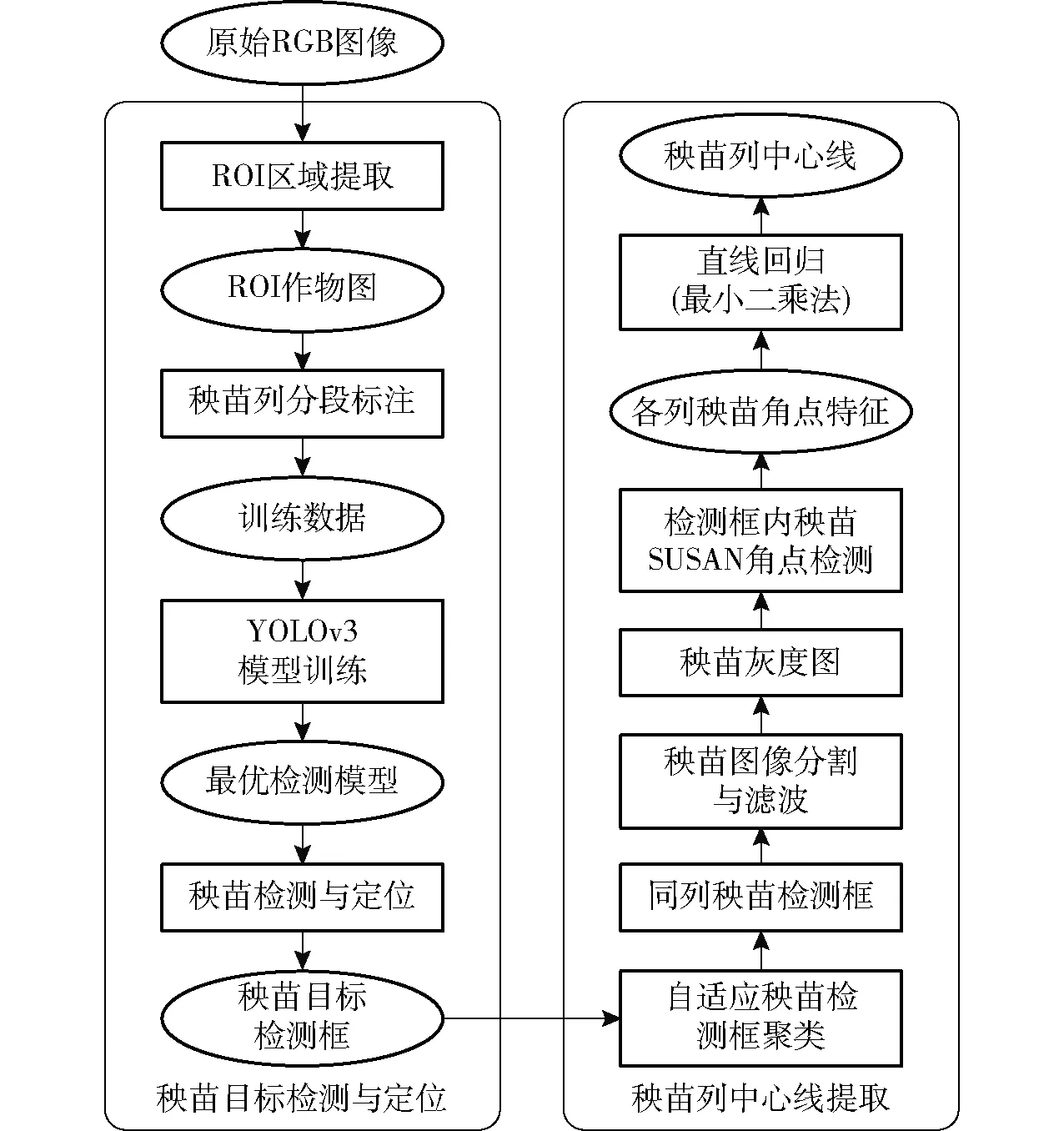
圖1 基于YOLOv3目標(biāo)檢測的秧苗列中心線提取 方法流程圖Fig.1 Flow chart of extraction method of seedling row centerline based on YOLOv3 target detection
1.2 數(shù)據(jù)采集

圖2 YOLOv3模型結(jié)構(gòu)圖Fig.2 YOLOv3 model architecture
試驗所用的圖像均拍攝于華南農(nóng)業(yè)大學(xué)國家優(yōu)質(zhì)稻新品種擴(kuò)繁基地。圖像分辨率為1 280像素×960像素。拍攝過程中攝像頭距離地面1 m,攝像頭光軸與水平線夾角為45°~60°。若小于45°則圖像中拍攝的秧苗列數(shù)過多,導(dǎo)致秧苗列在成像時距離過于密集,不利于后續(xù)導(dǎo)航線的檢測,而如果大于60°,則會使得拍攝到的秧苗列在圖像中的長度過短,提取到的導(dǎo)航線與實際秧苗列中心線誤差較大。從秧苗的4個生長階段各采集了500幅圖像,共采集到2 000幅圖像,其中包括5種復(fù)雜場景(大風(fēng)、藍(lán)藻、浮萍和秧苗倒影、水面強光反射、暗光線)下的圖像樣本各200幅。從采集到的4個生長階段的秧苗圖像樣本中隨機選取各400幅圖像用于制作訓(xùn)練集(1 200幅)、驗證集(200幅)和測試集(200幅),其中驗證集只用于評估訓(xùn)練時模型的表現(xiàn)。
2 基于YOLOv3的秧苗目標(biāo)檢測和定位
2.1 YOLOv3模型框架
YOLOv3將目標(biāo)檢測轉(zhuǎn)換為回歸問題,基于一個端到端的網(wǎng)絡(luò),實現(xiàn)從原始秧苗圖像的輸入到最后秧苗檢測框的輸出。YOLOv3模型先把秧苗輸入圖像統(tǒng)一為416像素×416像素,然后再劃分成13像素×13像素的網(wǎng)格,每個網(wǎng)格負(fù)責(zé)檢測B個邊界框及其置信度,以及C個類別的概率。所以,每個邊界框都包含了5個預(yù)測量:x、y、w、h、Confidience,其中(x,y)是秧苗檢測框的左上角坐標(biāo),w、h是秧苗檢測框的寬、高,Confidience是秧苗的置信度。整個步驟通過輸入秧苗圖像經(jīng)過一次YOLO網(wǎng)絡(luò),可以得到圖像中秧苗的位置及其相應(yīng)的置信概率。
YOLOv3模型結(jié)構(gòu)如圖2所示,考慮到水田環(huán)境的復(fù)雜和多變?nèi)菀讓?dǎo)致秧苗識別困難,本文使用含有53個卷積層的Darknet-53作為特征提取網(wǎng)絡(luò)來提取水田秧苗的特征。如圖2所示,輸入網(wǎng)絡(luò)的圖像,經(jīng)過Darknet-53后輸出52像素×52像素(尺度3)、26像素×26像素(尺度2)、13像素×13像素(尺度1)共3種尺度的特征圖,每個特征圖分配3種不同尺寸的錨點(Anchor)進(jìn)行邊界框預(yù)測,最后對3個輸出張量進(jìn)行合并處理,獲得秧苗的預(yù)測信息。由于在秧苗識別過程中需要檢測的目標(biāo)只有秧苗這一類,所以通過修改YOLOv3的輸出類別數(shù)目為1,減少了網(wǎng)絡(luò)的運算量,最終網(wǎng)絡(luò)預(yù)測張量的長度為18(即3(錨點)×(4(邊框坐標(biāo))+1(邊框置信度)+1(對象類別數(shù)))),如圖2中的輸出張量所示。
2.2 基于透視投影計算的秧苗圖像ROI提取
在機器人實際導(dǎo)航過程中,機器人的行進(jìn)列(一般是圖像中部的秧苗列),以及距離機器人行進(jìn)列最近的左右兩側(cè)秧苗列直接影響機器人導(dǎo)航的準(zhǔn)確度。因此可以在圖像中事先篩選出ROI區(qū)域,這樣可以減少圖像數(shù)據(jù)處理量,同時也減少圖像邊緣作物列的干擾,使得后續(xù)的圖像處理步驟更加高效[28-30]。因此需要在訓(xùn)練YOLOv3網(wǎng)絡(luò)前,構(gòu)建秧苗圖像的ROI。然后通過標(biāo)注后再對YOLOv3網(wǎng)絡(luò)進(jìn)行訓(xùn)練。
為了確定圖像中秧苗列的ROI,將圖像在透視投影下簡化為成像模型如圖3所示,NM為圖像中部秧苗列中心線,EF、PQ為左、右側(cè)秧苗列中心線,四邊形ACDB內(nèi)為ROI區(qū)域。
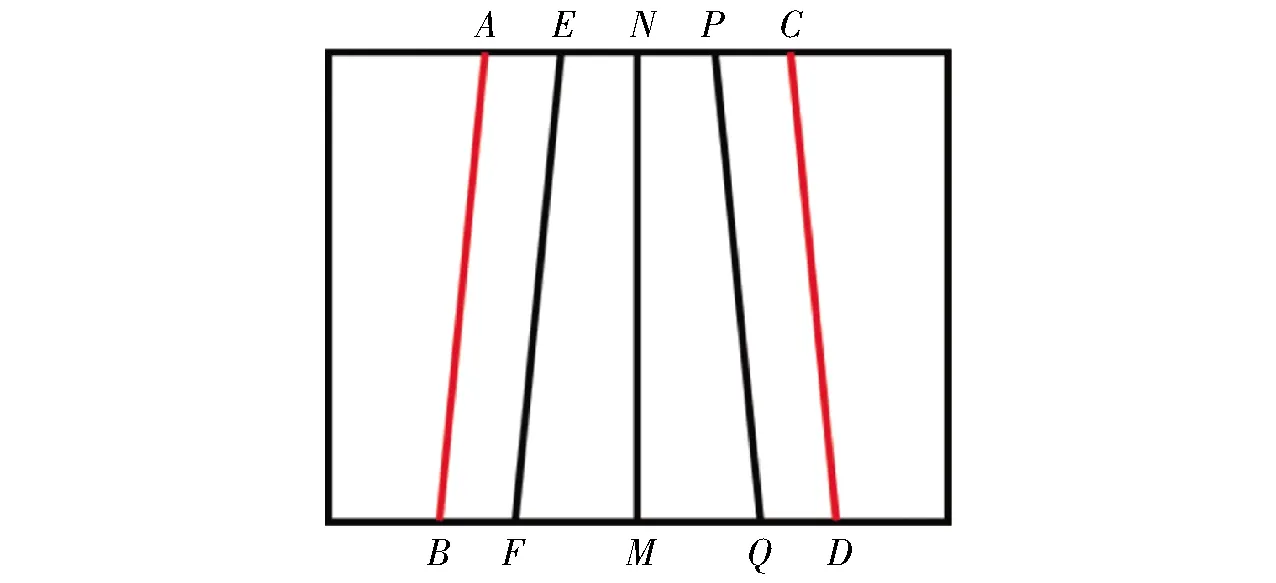
圖3 透視現(xiàn)象下的秧苗列成像模型Fig.3 Image model of rice seedlings rows under perspective
ROI具體確定流程如下:
(1)在透視投影下,秧苗列中心線上下兩端的像素距離DNP與DMQ有如下關(guān)系[31]
(1)
式中Gp——DNP與DMQ的比值
θ——相機光軸與水平線夾角,45°~60°
α——相機的垂直視場角,(°)
(2)由攝像頭成像[32]可得M點與Q點之間的像素距離為
(2)
式中d——秧苗列間的平均距離,mm
f——攝像頭焦距,mm
H——攝像頭光心離地高度,mm
k——圖像中單個像素點的物理尺寸,mm
(3)在相機俯角最大(θ=60°)時,點M與點Q的像素距離DMQ最大,把θ=60°代入式(1)、(2)可求得DMQ、DNP。以此時的DMQ、DNP作為參考值,設(shè)置四邊形ABDC內(nèi)的區(qū)域為ROI,對圖像非ROI的部分進(jìn)行遮罩填充。其中DMD=DMB=cDMQ,DNC=DNA=cDNP,c為裕度系數(shù)(c=1.2)。圖4a的ROI提取效果如圖4b所示。
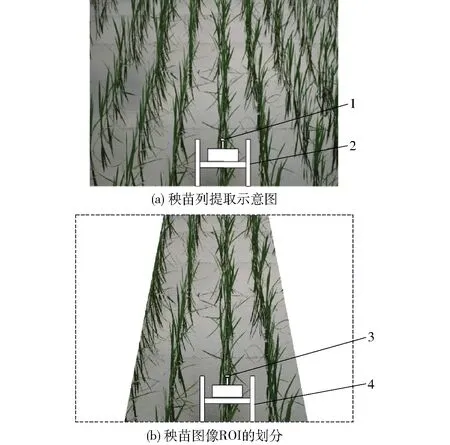
圖4 ROI內(nèi)的秧苗列Fig.4 Rice seedlings rows in ROI1、3.攝像頭 2、4.除草機器人
2.3 秧苗圖像數(shù)據(jù)集的建立

圖5 ROI內(nèi)的秧苗分段標(biāo)注Fig.5 Segmental labeling of rice seedlings rows in ROI
在劃分了秧苗圖像的ROI后,再對ROI內(nèi)的秧苗進(jìn)行標(biāo)注。由于在透視現(xiàn)象下,除了圖像中部的秧苗列外,其他秧苗列成像時均呈現(xiàn)較大傾斜程度。此時在進(jìn)行圖像標(biāo)注時,如果對這些傾斜程度較大的秧苗列進(jìn)行整列標(biāo)注,則會使得標(biāo)注框內(nèi)背景區(qū)域較多,不利于后續(xù)針對檢測框區(qū)域進(jìn)行秧苗中心線的提取。因此在保證背景區(qū)域較小的前提下,采用分段標(biāo)注秧苗的方式,使得YOLOv3網(wǎng)絡(luò)能更準(zhǔn)確地識別與定位出秧苗列,有利于后續(xù)圖像處理過程中減少背景噪聲的干擾。標(biāo)注方式如圖5所示,即在標(biāo)注框所含背景區(qū)域較少的情況下,標(biāo)注出秧苗的主干部分即可,由圖5b可以看出標(biāo)注框與秧苗主體較為緊湊。
標(biāo)注后的圖像采用YOLO數(shù)據(jù)集的格式保存為txt文件用于網(wǎng)絡(luò)訓(xùn)練。每個txt文件內(nèi)包含秧苗的類別數(shù)量(C)和標(biāo)注秧苗邊界框的左上角坐標(biāo)信息(x,y)以及框的寬與高(w,h),在本文中只需要檢測秧苗這一類目標(biāo),所以本文類別總數(shù)C取1。
2.4 模型參數(shù)的設(shè)置與訓(xùn)練
訓(xùn)練時一輪迭代(Iteration)處理64個樣本,圖像訓(xùn)練前被降采樣到640像素×480像素,使用BN(Batch normalization)在每次權(quán)值更新時進(jìn)行正則化,權(quán)值衰減(Decay)設(shè)置為0.000 5,動量衰減(Momentum)設(shè)置為0.9,初始學(xué)習(xí)率(Learning rate)設(shè)置為0.001,并在迭代4 000、6 000次時衰減10倍,為了在初始迭代階段使得模型迭代較為穩(wěn)定,設(shè)置一個學(xué)習(xí)率變化點burn_in的值為1 200,在前1 200輪迭代過程中,學(xué)習(xí)率計算式為
(3)
式中l(wèi)rate——學(xué)習(xí)率
iteration——迭代次數(shù)
?——賦值運算符
在訓(xùn)練前通過K-means聚類算出訓(xùn)練集中錨點的初始值,本文中設(shè)置9個錨點分別應(yīng)用于3個尺度的特征圖,9個錨點的尺寸分別為35×104、35×174、49×181、39×244、51×266、62×221、70×290、46×456、67×461。
對于深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練所需的數(shù)據(jù)量而言,1200幅圖像遠(yuǎn)遠(yuǎn)不足。所以本文在訓(xùn)練的時候采用數(shù)據(jù)增強方法,通過改變圖像的色調(diào)(變化范圍1~1.5倍)、曝光度 (變化范圍1~1.5倍)、色量化(變化范圍0.8~1.1倍),設(shè)置數(shù)據(jù)抖動值,即隨機改變輸入圖像尺寸和寬高比值(變化范圍為[0.4, 1.6])來擴(kuò)充訓(xùn)練集。在每一輪迭代過程中,隨機使用上述一種方法應(yīng)用于64幅圖像樣本。
最終模型共訓(xùn)練9 000次,使用了576 000幅圖像,其損失值變化如圖6所示。
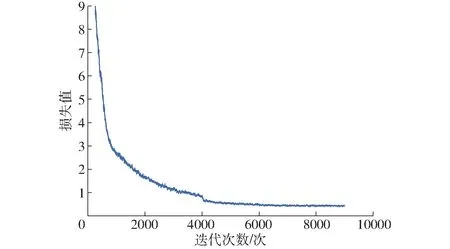
圖6 損失值隨迭代次數(shù)的變化曲線Fig.6 Changing curve of loss value with iterations
從圖6可以看出,在最初的1 200次迭代中擬合速度較快,在達(dá)到4 000次迭代時由于此時學(xué)習(xí)率衰減10倍,模型的訓(xùn)練步長減小,擬合能力上升,損失值進(jìn)一步下降。在6 000次迭代時學(xué)習(xí)率再衰減10倍后,由于此時模型逐漸穩(wěn)定,所以損失值振蕩較小,最終損失值穩(wěn)定在0.42。
2.5 最優(yōu)模型的選擇
在9 000次訓(xùn)練迭代過程中,從burn_in值(1 200)后每隔100次迭代輸出一次權(quán)值(Weight),最終共得到78個模型,而模型并不是隨著迭代次數(shù)越多而表現(xiàn)越好,過多的迭代次數(shù)可能會導(dǎo)致模型過擬合,為了后續(xù)更好地執(zhí)行檢測任務(wù),需要對模型進(jìn)行評估,尋找出最優(yōu)的檢測模型。模型的評價指標(biāo)有準(zhǔn)確率(Precision)、召回率(Recall)、平均精度均值(Mean average precision,mAP)、交并比(Intersection over union,IOU)、F1值。
(4)
(5)
(6)
(7)
(8)
式中TP——被正確劃分為正樣本的數(shù)量
FP——被錯誤劃分為正樣本的數(shù)量
FN——被錯誤劃分為負(fù)樣本的數(shù)量
P——準(zhǔn)確率F1——F1值
R0——召回率i——識別序號
Soverlap——預(yù)測的邊界框與真實的邊界框之間的交集區(qū)域
Sunion——預(yù)測的邊界框與真實的邊界框之間的并集區(qū)域
IOU——交并比
mAP——平均精度均值
本文使用mAP來評估模型的整體性能。計算所得的每個模型的mAP值如圖7所示。由圖7可以看到,當(dāng)?shù)螖?shù)達(dá)到6 000次時mAP值已經(jīng)穩(wěn)定。因此最優(yōu)模型的選取從迭代區(qū)間6 000~9 000當(dāng)中選擇,其中mAP在迭代次數(shù)為6 800時達(dá)到最大值91.47%,因此選擇此模型作為最優(yōu)模型。

圖7 平均精度均值隨迭代次數(shù)的變化曲線Fig.7 Changing curve of mean average precision with iterations
3 基于檢測框區(qū)域的秧苗列中心線提取
3.1 自適應(yīng)同列秧苗檢測框聚類
由于采用了分段標(biāo)注秧苗的方式,在使用訓(xùn)練好的YOLOv3模型進(jìn)行檢測時,定位輸出秧苗列的檢測框也是分段的,因此需要對同列秧苗的檢測框進(jìn)行聚類,后續(xù)再基于同類檢測框區(qū)域進(jìn)行秧苗列中心線提取。
自適應(yīng)檢測框聚類算法流程如下:
(1)定義網(wǎng)絡(luò)輸出的檢測框結(jié)構(gòu)體box={x,y,w,h}。
(2)創(chuàng)建兩個一維向量vector〈rightbox〉,vector〈leftbox〉。如果box.x (3)根據(jù)box的y坐標(biāo)最小原則,找出所有一維向量中離圖像上邊界最近的初始聚類檢測框box0={x0,y0,w0,h0}。 (4)找到初始聚類檢測框后,按照如下準(zhǔn)則在圖像中從上往下聚類下一層鄰近檢測框(定義為box1={x1,y1,w1,h1})。如果0≤|x0-x1| (5)把box1設(shè)為新的初始聚類框box0,繼續(xù)依照步驟(4)中的條件判斷往下查找鄰近的同列秧苗檢測框,直至完成同列秧苗的檢測框聚類為止。 同列秧苗的檢測框聚類完成后,同顏色的檢測框即為同一類(即屬于同列秧苗)。 由于水田背景噪聲的多變和秧苗的生長形態(tài)不同,需要從復(fù)雜背景中提取出秧苗特征。利用ExG算子,其能從背景中較好地分割出綠色作物。在進(jìn)行灰度化前,先對圖像中的顏色分量R、G、B進(jìn)行歸一化,以減小光照變化對圖像帶來的影響,計算公式為 (9) 式中R、G、B——圖像的紅、綠、藍(lán)3個顏色通道的數(shù)值 r、g、b——歸一化后的紅、綠、藍(lán)數(shù)值 (10) 式中I(x,y) ——坐標(biāo)(x,y)處的灰度 經(jīng)過灰度化處理后的圖像,除去了大部分圖像的背景噪聲,但是存在藍(lán)藻或者浮萍的情況下,會產(chǎn)生很強的椒鹽噪聲。使用中值濾波去除背景的椒鹽噪聲,對比均值濾波和高斯濾波,中值濾波在很好地保護(hù)圖像細(xì)節(jié)的同時,抑制圖像中大部分的椒鹽噪聲,再通過7×7的類圓形USAN模板對灰度化后的圖像中的檢測框區(qū)域提取秧苗SUSAN[35]角點特征,最后使用5×5的正方形模板進(jìn)行非極大值抑制,以剔除偽角點。 由于基于YOLOv3的秧苗預(yù)測的方法,可以預(yù)先定位秧苗列區(qū)域的大致位置,所以在基于檢測框區(qū)域?qū)ρ砻绲奶卣魈崛r,避免了在圖像全局區(qū)域進(jìn)行秧苗的特征掃描提取,能較大程度避免背景噪聲對特征提取的干擾,而同時圖像經(jīng)過中值濾波后,抑制了大部分水田中的浮萍和藍(lán)藻帶來的椒鹽噪聲,所以本文在中心線的提取上,采用擬合效果較理想的、計算速度較快的最小二乘法。 本文訓(xùn)練和測試均在同一臺計算機進(jìn)行,計算機主要配置為AMD Ryzen 5 CPU,主頻3.20 GHz、11 GB的GPU GeForce GTX 1080Ti和16 GB的運行內(nèi)存。開發(fā)環(huán)境為Windows 10(64位)系統(tǒng),VS2015,開發(fā)語言為C++。 T1和T2分別為屬于同列秧苗的上下相鄰檢測框之間的橫向距離閾值與縱向距離閾值。T1和T2閾值的選擇會影響檢測框聚類的準(zhǔn)確性,而聚類的效果只能依靠聚類處理后的圖像進(jìn)行判斷,沒有定量的指標(biāo)來衡量其效果。本文通過從秧苗4個生長階段圖像集中隨機均勻選取100幅圖像進(jìn)行試驗,得出:當(dāng)T1的取值在圖像寬度W的1/64~1/8之間時,T2的取值在圖像高度H的1/24~1/12之間,均能得到較好的聚類效果。 通過試驗發(fā)現(xiàn),由于不同秧苗列間的檢測框存在一定的橫向距離,同列秧苗列的相鄰(上下相鄰)檢測框存在較小的橫向距離,T1的取值應(yīng)不大于圖像寬度W的1/8,過大則容易使得屬于不同列的秧苗檢測框誤聚類;T1的取值如果小于圖像寬度W的1/64,則容易使得屬于同列的相鄰(上下相鄰)檢測框聚類失敗。另一方面T2在大于圖像高度H的1/12時,在秧苗列較為密集的情況下,不同列間的檢測框距離較小,容易產(chǎn)生誤聚類;當(dāng)T2小于圖像高度H的1/24時,則容易產(chǎn)生屬于同列的且有重疊部分(或者非重疊、有一定縱向距離)的相鄰(上下相鄰)檢測框聚類失敗。因此在初定T1∈[W/64,W/8]、T2∈[H/24,H/12]后,本文選取T1取值范圍內(nèi)的4個典型值W/64、W/32、W/16、W/8,T2的3個典型值H/24、H/16、H/12,兩者進(jìn)行組合,對所選的圖像進(jìn)行秧苗檢測框聚類,并進(jìn)行聚類準(zhǔn)確性的統(tǒng)計,如表1所示。由表1可以看出,T1與T2取(W/64,H/16)時,各階段秧苗圖像的檢測框聚類準(zhǔn)確率均達(dá)到最大值,平均準(zhǔn)確率為95%,在秧苗生長的初期,秧苗列稀疏,間距較大,網(wǎng)絡(luò)輸出的不同秧苗列間的檢測框區(qū)分度較大,不易產(chǎn)生誤聚類的情況,因此聚類的準(zhǔn)確率較高。而在秧苗生長的中后期,由于生長形態(tài)發(fā)生變化,導(dǎo)致不同秧苗列間的檢測框間距較小,增加了聚類的難度,導(dǎo)致聚類準(zhǔn)確率下降。 表1 T1與T2不同取值下檢測框聚類的準(zhǔn)確率Tab.1 Accuracy of clustering bounding boxes with different values of T1 and T2 % 為了進(jìn)一步檢測本文算法在南方復(fù)雜水田環(huán)境中的性能,將本文提出的算法與文獻(xiàn)[16]中的在相同應(yīng)用環(huán)境下的算法在運行速度和識別誤差上進(jìn)行對比。在4.1節(jié)中所述的硬件平臺上,檢測1幅640像素×480像素的彩色圖像,文獻(xiàn)[16]中的算法平均耗時為256 ms,本文算法平均耗時82.6 ms。對于2種算法的檢測誤差比較,本文通過3人手動繪制水田秧苗圖像ROI范圍內(nèi)的秧苗列中心線,并取其平均值代表秧苗列的參考中心線,計算實際檢測出來的直線與手動繪制直線的夾角,夾角越大,則提取的直線誤差越大。經(jīng)過對測試集中200幅圖像進(jìn)行試驗,文獻(xiàn)[16]算法提取中心線的平均夾角誤差為3.50°,標(biāo)準(zhǔn)差為3.28°,本文算法的平均夾角誤差為0.97°,標(biāo)準(zhǔn)差為0.73°。可見,本文提出的算法不僅計算速度得到提高,而且還具有較高的識別精度。 從采集到的圖像中隨機選取秧苗每個生長階段各50幅圖像,使用本文算法和文獻(xiàn)[16]算法分別進(jìn)行秧苗中心線提取,2種算法的對比效果如圖8所示。由圖8可以看出,在秧苗生長前期(第1、2周內(nèi)),由于此時水田背景噪聲較少,水田環(huán)境相對簡單,兩種方法提取中心線的效果大體相當(dāng)。當(dāng)在插秧第3周時,由于秧苗生長導(dǎo)致形態(tài)發(fā)生變化,開始出現(xiàn)秧苗側(cè)偏、葉片相互遮擋,而在插秧第4周時情況更加明顯,此時水田中還伴有藍(lán)藻、浮萍等背景噪聲的影響,由于文獻(xiàn)[16]中基于滑動窗口聚類的方法受背景噪聲、秧苗生長形態(tài)的影響較大,所以在提取中心線的過程中均出現(xiàn)了明顯偏差。而本文算法基于秧苗檢測框區(qū)域進(jìn)行秧苗特征提取,避免對整幅圖像進(jìn)行基于窗口掃描的特征提取,較大程度地避免了背景噪聲的干擾。另一方面YOLOv3模型檢測定位出的是秧苗的主干部分,減少了秧苗生長過程中由于形態(tài)變化所造成秧苗特征提取容易偏離作物中心的影響。 圖8 2種算法對于不同生長狀態(tài)下的秧苗列中心線提取效果Fig.8 Two algorithms for extracting centerlines of rice seedlings under different growth stages 2種算法的試驗統(tǒng)計結(jié)果如表2所示。對于秧苗的4個生長階段,本文算法所提取的秧苗列中心線角度誤差均小于文獻(xiàn)[16]算法,本文算法提取的秧苗中心線平均角度誤差為0.93°,文獻(xiàn)[16]算法提取的秧苗中心線平均角度誤差為2.92°。由此可見本文算法對于不同生長階段的秧苗適應(yīng)性更好,精度更高。 對于一些較為復(fù)雜的水田環(huán)境,如大風(fēng)、藍(lán)藻、浮萍和秧苗倒影、水面強光反射、暗光線的特殊場景,秧苗列中心線提取效果對比如圖9所示。由圖9可以看到在這些特殊場景下,由于環(huán)境變化使得秧苗角點特征分布更加分散,此時文獻(xiàn)[16]算法所提取的中心線誤差較大。 表2 2種算法對不同生長階段下秧苗列中心線提取 角度誤差對比Tab.2 Error comparison of extracting centerlines of rice seedlings in different growth stages by two algorithms (°) 而本文基于同列秧苗檢測框區(qū)域的中心線提取算法,較大減少了環(huán)境變化對中心線提取的干擾。基于YOLOv3算法能較好檢測到秧苗列的主體部分,基于檢測框區(qū)域所提取的角點特征能很好地表征秧苗列的中心位置,使得擬合的直線更加接近秧苗列的中心線。 對采集到的圖像中隨機選取大風(fēng)、藍(lán)藻、浮萍和秧苗倒影、水面強光反射、暗光線的特殊環(huán)境下各50幅圖像分別使用本文算法和文獻(xiàn)[16]算法進(jìn)行秧苗中心線提取,誤差對比如表3所示。在大風(fēng)、藍(lán)藻、浮萍和秧苗倒影、水面強光反射、暗光線的復(fù)雜水田環(huán)境下,本文提取的秧苗列中心線角度誤差均小于文獻(xiàn)[16]算法,本文算法提取的秧苗中心線平均角度誤差為0.92°,文獻(xiàn)[16] 算法提取的秧苗中心線平均角度誤差為3.11°,由此可見本文算法面對復(fù)雜的水田環(huán)境時的魯棒性更強,精度更高。 (1)針對我國南方復(fù)雜的水田環(huán)境,提出了基于YOLOv3目標(biāo)檢測的水田秧苗列中心線提取算法。構(gòu)建圖像的ROI區(qū)域,以減小圖像邊緣作物列對后續(xù)圖像處理的干擾;構(gòu)建秧苗識別深度神經(jīng)網(wǎng)絡(luò),提高了復(fù)雜場景下提取秧苗列中心線的精度;基于同列秧苗檢測框聚類和檢測框內(nèi)的秧苗特征進(jìn)行提取,避免針對圖像全局的特征提取,減小了圖像處理的數(shù)據(jù)量和環(huán)境噪聲的干擾。研究和試驗表明,所提出的方法適用于秧苗的不同生長階段和復(fù)雜的水田環(huán)境,如大風(fēng)、藍(lán)藻、浮萍與秧苗倒影、水面強光反射、暗光線等。 (2)采用本文算法提取的秧苗列中心線平均角度誤差為0.97°,YOLOv3模型的平均精度為91.47%,單幅圖像(分辨率640像素×480像素)在GPU下的平均處理時間為82.6 ms。與相同應(yīng)用背景下的文獻(xiàn)[16]算法相比,本文算法在復(fù)雜的水田環(huán)境下魯棒性更好、檢測速度更快、精度更高,提高了機器人視覺導(dǎo)航的實時性。3.2 基于歸一化ExG算子的秧苗圖像分割
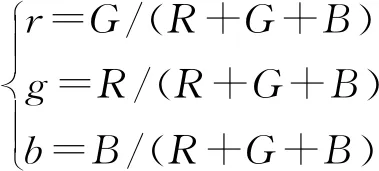
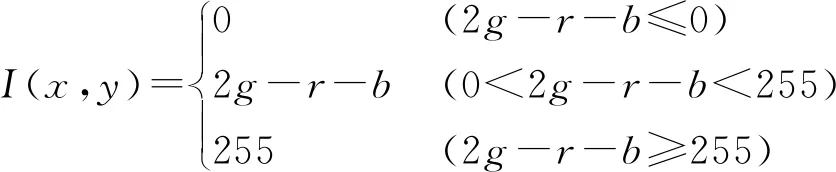
3.3 基于檢測框區(qū)域內(nèi)的SUSAN角點特征提取
3.4 基于最小二乘法的秧苗列中心線擬合
4 結(jié)果與分析
4.1 試驗平臺
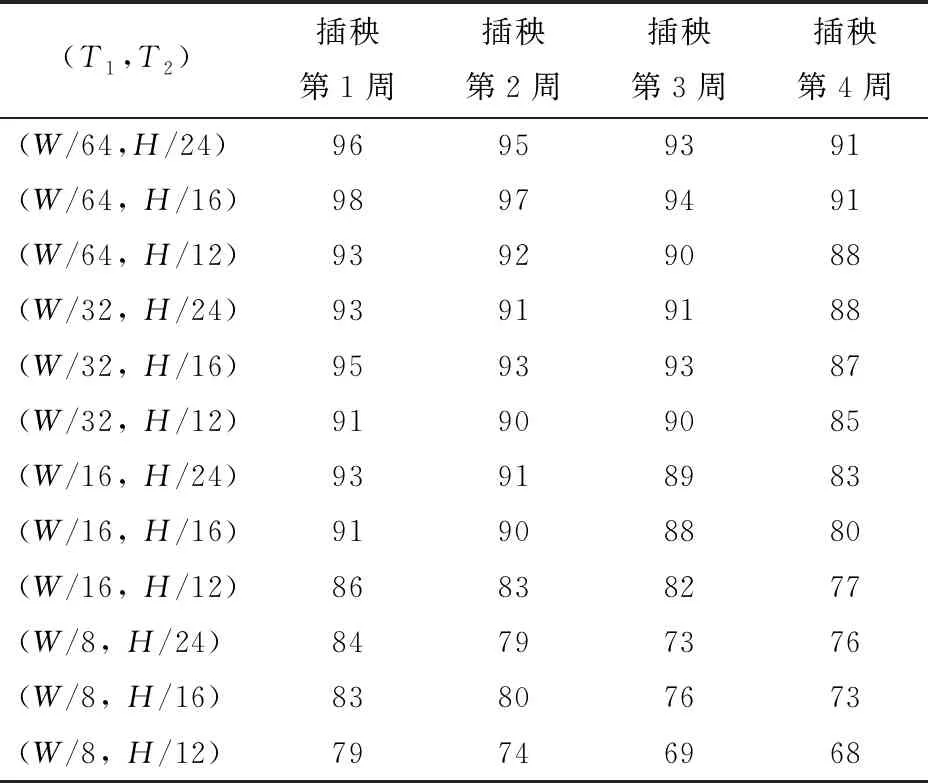
4.2 檢測框聚類的距離閾值確定
4.3 算法性能分析
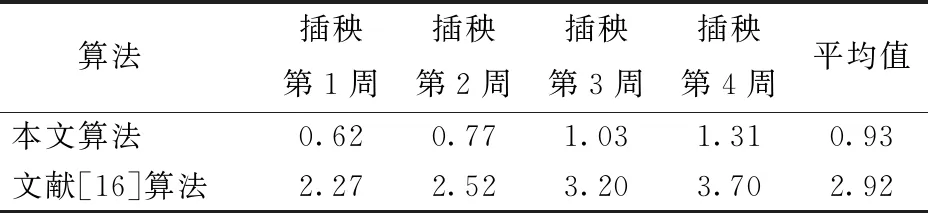
4.4 不同生長階段秧苗列中心線提取對比試驗

4.5 復(fù)雜水田環(huán)境下秧苗列中心線提取對比試驗
5 結(jié)論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24光學(xué)精密工程(2016年6期)2016-11-07 09:07:19海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
