集成學習之隨機森林分類算法的研究與應用
2020-08-21 17:21:37吳興惠周玉萍邢海花
電腦知識與技術 2020年21期
吳興惠 周玉萍 邢海花
摘要:集成學習是多分類器學習系統。而隨機森林是一個包含多個決策樹的分類器,是一種基于Bagging的集成學習方法。隨機森林具有預測準確率、不容易出現過擬合的特點,在很多領域都有所應用。本文主要利用隨機森林算法對心臟病數據集建立了分類預測模型,實驗結果表明,隨機森林算法在預測性能上超過了決策樹和邏輯回歸分類算法,并通過繪制ROC曲線對四種模型進行了對比。
關鍵詞:集成學習;隨機森林;預測
中圖分類號:TP181 文獻標識碼:A
文章編號:1009-3044(2020)21-0026-02
開放科學(資源服務)標識碼(OSID):
數據挖掘的一個重要領域是數據分類,對數據進行分類和預測是當前比較熱門的研究。機器學習中的分類算法屬于有監督學習,常用的分類算法有決策樹、貝葉斯、神經網絡、支持向量機、隨機森林等。集成學習是多分類器學習系統。而隨機森林是一個包含多個決策樹的分類器,是一種基于Bagging的集成學習方法。它包含多個決策樹,并且它的輸出類別由所有樹輸出的類別的眾數而定。由于它具有預測準確率、不容易出現過擬合的特點,在很多領域都有所應用。隨機森林在醫學領域、經濟學、刑偵領域和模式識別領域取得了較好的效果。本文基于一個心臟病數據集,利用隨機森林算法建立分類模型,并將建立的模型與決策樹和邏輯回歸模型進行對比,并通過數據繪制了各自模型的ROC曲線。結果表明,在對數據分類效果上看,隨機森林在預測性能上的效果要比決策樹和邏輯回歸模型的效果要強些。
1 隨機森林算法
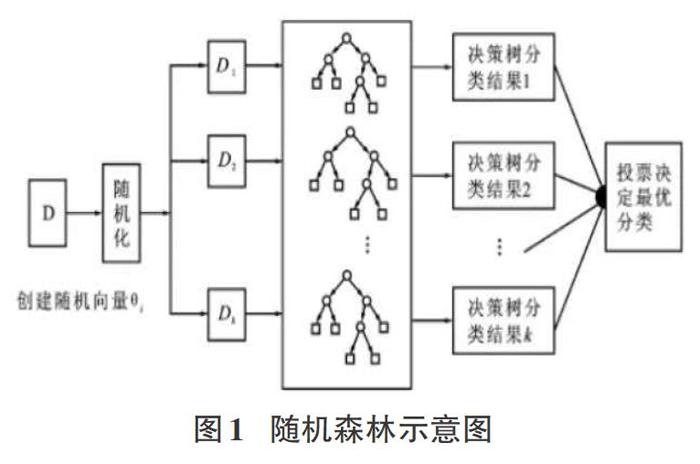
隨機森林[1]是一種組合方法,由許多的決策樹組成,對于每一顆決策樹,隨機森林采用的是有放回的對N個樣本分N次隨機取出N個樣本,即這些決策樹的形成采用了隨機的方法,因此也叫作隨機決策樹。隨機森林中的樹之間是沒有關聯的。當測試數據進入隨機森林時,其實就是讓每一顆決策樹分別進行分類,最后取所有決策樹中分類多的那類為最終的結果。隨機森林算法如圖1所示。
1.1集成學習
集成學習也稱為多分類器學習系統,它是結合多個分類學習器來完成學習任務來構建的。弱模型以得到一個預測效果好的強模型。對于分類問題就是指采用多個分類器對數據集進行它的一般結構是將多個個體學習器結合起來,共同發揮作用。個體學習器是通過現有的學習算法來訓練數據產生。集成學習方法可分為二種,一是個體學習器間存在強依賴關系,如AdaBoost算法。而另一種是個體學習器之間不存在強依賴關系,可以同時生成個體學習器的并行方法,如隨機森林算法。
1.2 隨機森林算法原理
隨機森林算法,包含分類和回歸問題,其算法流程如下:
1)假如有N個樣本,則有回放的隨機選擇N個樣本(每次隨機選擇一個樣本,然后返回繼續選擇)。這選擇好了的N個樣本用來訓練一個決策樹,作為決策樹根節點處的樣本。
2)當每個樣本有M個屬性時,在決策樹的每個節點需要分裂時,隨機從這M個屬性中選取出m個屬性,滿足條件m<
3)決策樹形成過程中,每個節點都要按照步驟2來分裂(很容易理解,如果下一次該節點選出來的那一個屬性是剛剛父節點分裂時用過的屬性,則該節點已經達到了葉子節點,無須繼續分裂)。一直到不能再分裂為止,注意整個決策樹形成過程中沒有剪枝。
4)按步驟1-3建立大量決策樹,如此形成隨機森林。
從上邊的步驟可以看出,隨機森林每棵樹的訓練樣本是隨機的,數中每個節點的分類屬性也是隨機選擇的,這2個隨機的選擇過程,保證了隨機森林不會產生過擬合現象。
2 數據處理
本文使用python語言實現了隨機森林算法的整個流程,數據集采用的是UCI數據集上心臟病數據,為了在此數據集上驗證隨機森林算法的有效性,使用隨機森林算法對該數據集進行預測研究。
2.1 數據預處理
首先對本實驗中用到的心臟病數據集進行預處理,對數據集中數據變量名、數值分布和缺失值情況等等有初步了解。本數據集有14個特征。對數據集中類別變量不是數值型的數據需要將類別型變量轉換為數值型變量。本文采用獨熱編碼為每個獨立值創建一個啞變量[2]。對特征中非連續型數值胸痛類型(cp)運動高峰的坡度(slope),血液疾病(thal)三個分類型特征進行啞變量處理。采用的是pandas對one-hot編碼的函數pd.get_dummies0。然后對數據集進行分割,把數據切分為訓練集和驗證集,使用train_test_split0函數,將25%的數據用于驗證。
X_train, X_test, y_train, y_test= train_test_split(X,y, test_sizr=0.25,trandom_state=6),并對切分后的數據用函數standardScaler.transform0進行歸一化處理。
2.2 特征選擇
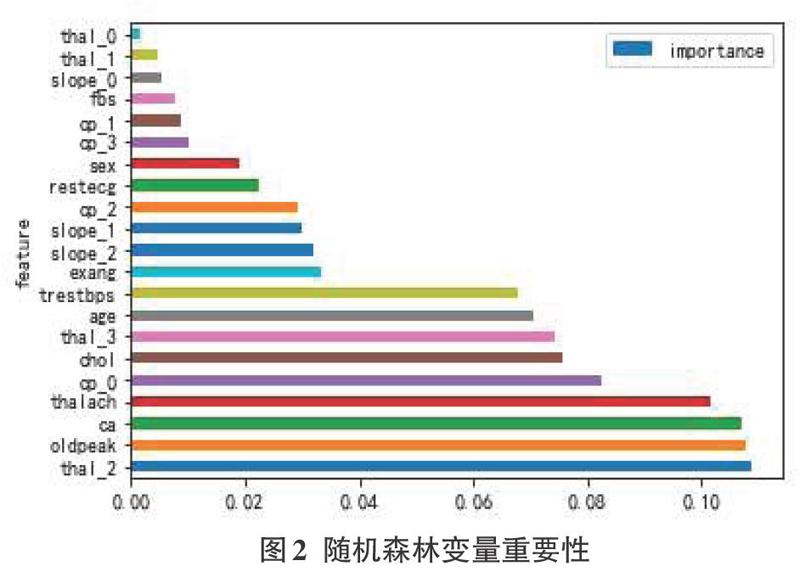
特征選擇是為了構建模型而選擇相關特征(即屬性、指標)子集的過程。指從數據集中已有的M個特征中選擇N個特征(M>N),也就是從原始特征中選擇出一些最有效特征以降低數據集維度的過程,最后使系統的指標最優化。本文使用隨機森林算法得到的特征變量重要性,通過特征變量比較圖對特征進行排序,可以剔除不重要的特征。
由圖2可得出,thal_2(地中海貧血的血液疾病)、oldpeak(相對于休息的運動引起的ST值)與ca(血管數)這三個特征比其他特征重要性高。可以使用此方法來提取對模型重要的特征,剔除不重要的特征來提高模型的預測效果。
3 模型創建與評估
本實驗采用的是隨機森林算法對數據進行建模,采用py-thon語言平臺Anaconda3實現。在模型訓練中,對模型效果的驗證尋找合適的參數主要有K折交叉驗證、參數網格搜索以及訓練集、驗證集和測試集的引入等方法。這里采用的是參數網格搜索法為模型尋找更優的參數。在參數搜索過程中,主要使用的函數為GridSearchCVO。通過此方法,可以得到隨機森林如下的最優參數:
n_estimators=500, max_leaf_nodes=16, random_state=666.oob_score=True,n_jobs=-l
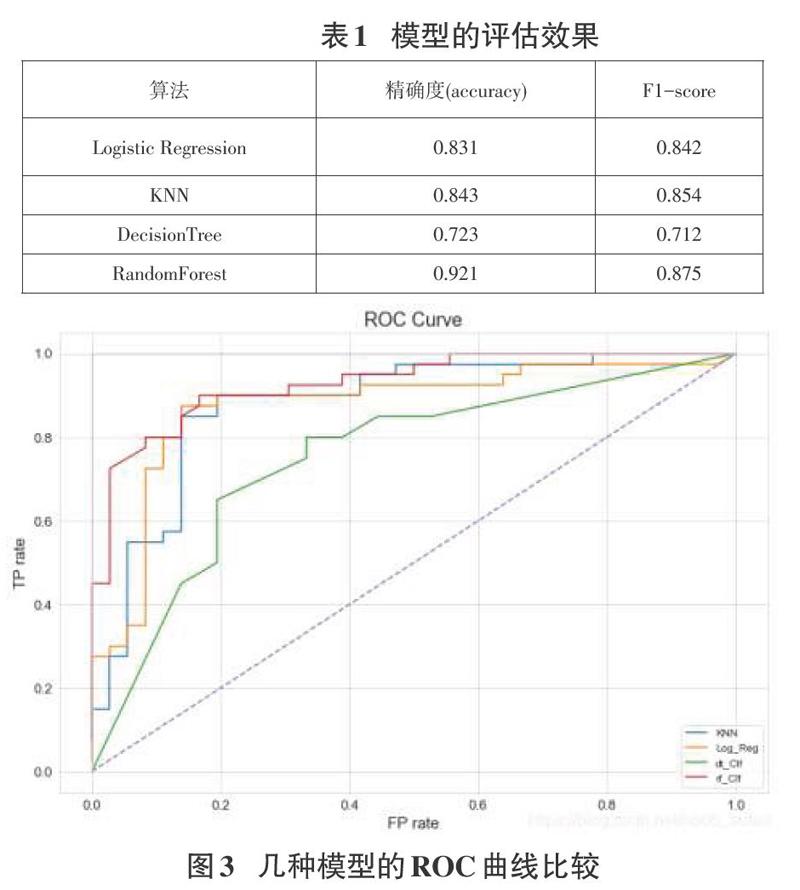
為了更好地驗證隨機森林的模型性能,本文將邏輯回歸,KNN,決策樹作為對比模型,并通過F1指標,混淆矩陣,精準率和召回率曲線,繪制每個模型的ROC曲線進行對比,用對比圖來對各個模型的效果進行評估。采用ROC曲線下的面積(area un-dercurve.AUC)作為模型性能指標,以下是實驗得到的精確度、F1-score及ROC曲線圖。
通過圖3中的幾種模型的ROC曲線比較中,可以得到,Lo-gistic Regression算法下的AUC值這0.8785,KNN下的AUC值為0.8739.DecisionTree算法下的AUC值為0.7527,RandomForest算法下的AUC值為0.9356。對于UCI心臟病數據集的分類效果來看,隨機森林的分類的效果更高些。
5 結論
本文對隨機森林算法在分類問題上的應用進行了研究,并且對UCI數據集上心臟病數據進行預測,通過實驗驗證證明此算法有著很好的分類作用。下一步的研究工作是針對隨機森林算法的超參數調優尋找更好的方法。
參考文獻:
[1]馬驪,隨機森林算法的優化改進研究[D].廣州:暨南大學,2016:43-49.
[2]李河,麥勁壯,肖敏,等.啞變量在Logistic回歸模型中的應用[J].循證醫學,2008,8(1): 42 - 45.
[3]李毓,張春霞.基于out-of-bag樣本的隨機森林算法的超參數估計[J].系統工程學報,201 1,26(4):566-572.
[4]曹正鳳.隨機森林算法優化研究[D].北京:首都經濟貿易大學。2014:29-34.
[5]王日升.基于Spark的一種改進的隨機森林算法研究[D].太原:太原理工大學,2017:39-47.
[6]夏濤,徐輝煌,鄭建立.基于機器學習的冠心病住院費用預測研究[J].智能計算機與應用,2019,9(5):35-39.
[6]馮曉榮,瞿國慶,基于深度學習與隨機森林的高維數據特征選擇[J].計算機工程與設計,2019,40(9):2494-2501.
[7]楊長春,徐筱,宦娟,等,基于隨機森林的學生畫像特征選擇方法[J].計算機工程與設計,2019,40(10):2827-2834.
[8]呂紅燕,馮倩.隨機森林算法研究綜述[J].河北省科學院學報,2019,36(3):37-41.
[9]梁瓊芳,莎仁.基于隨機森林的數學試題難易度分類研究[J].軟件導刊,2020,19(2):122-126.
【通聯編輯:唐一東】
收稿日期:2020-03-15
基金項目:海南省教育科學規劃課題:基于一種自學習分類算法的學生成績評價研究( QJY20181071);海南省高等學校教育教學改革研究項目(Hnjg2020-31);海南省自然科學基金項目(2019RC182)
作者簡介:吳興惠(1975-),女,海南儋州人,海南師范大學副教授,碩士,機器學習;通訊作者:邢海花(1976-),女,海南文昌人,海南師范大學教授,博士,智能空間信息處理。
